
这本书非常值得一读,对我来讲,主要有两点:
- 系统性:之前都是在各个点上去深入理解,这本书描述了一个 N 维的结构,串起来这些点,理论认知更全面。之后拿理论再去套新的系统,效率更高,直觉也更准确。
- 不断地思考和解惑:需要进一步思考,同时继续看下去,又不断的佐证/推翻自己的想法。例如之前了解了 raft,仍然不清楚客户端如何知道哪个是 leader?quorum 机制,当 w + r > n,一定会读到一个最新的数据,但是怎么找到这个数据?书里逐渐给出了演变的历史和答案。
这篇笔记记录“第一部分-数据系统基础”的心得,这一部分主要解决了:
- 系统设计的目标是什么
- 数据逻辑上应该怎么存,怎么查
- 数据物理上应该怎么存,怎么查
- 数据物理上的字节应该怎么编码
1. 可靠、可扩展与可维护的应用系统
1.1. 可靠性
每次提到可靠性,第一时间想到的总是 Jeff Dean 的 stanford-295-talk 的 page4:
The Joys of Real Hardware
Typical first year for a new cluster:
~0.5 overheating (power down most machines in <5 mins, ~1-2 days to recover)
~1 PDU failure (~500-1000 machines suddenly disappear, ~6 hours to come back)
~1 rack-move (plenty of warning, ~500-1000 machines powered down, ~6 hours)
~1 network rewiring (rolling ~5% of machines down over 2-day span)
~20 rack failures (40-80 machines instantly disappear, 1-6 hours to get back)
~5 racks go wonky (40-80 machines see 50% packetloss)
~8 network maintenances (4 might cause ~30-minute random connectivity losses)
~12 router reloads (takes out DNS and external vips for a couple minutes)
~3 router failures (have to immediately pull traffic for an hour)
~dozens of minor 30-second blips for dns
~1000 individual machine failures
~thousands of hard drive failures
slow disks, bad memory, misconfigured machines, flaky machines, etc.
作为架构,应该牢记这几个数字。
可靠性的难点,来自于上述问题。
可靠性的保证,除了上述问题,还需要考虑:规范的上线流程、测试/沙盒环境、监控/报警/日志系统。
1.2. 可扩展性
作者举了一个 Twitter 的经典场景:“当用户查看时间线时,首先查找所有的关注对象,列出这些人的所有tweet,最后以时间为序来排序合并。”
有两种思路来设计这套系统:
- 读更新:
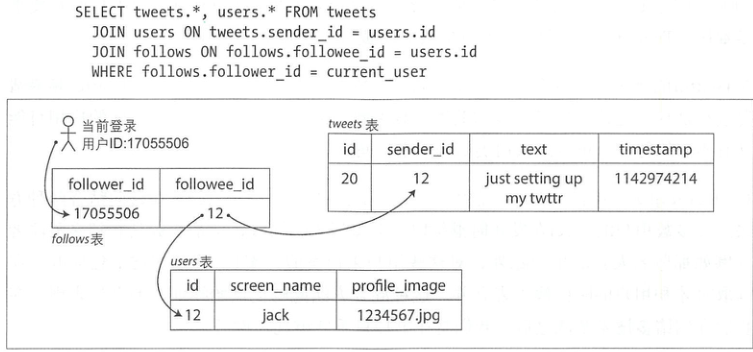
- 写更新:
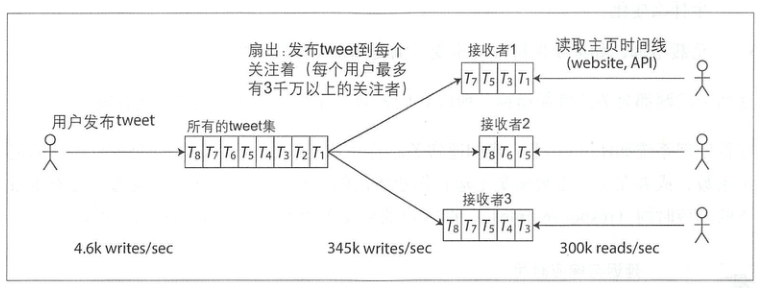
方案取决于实际压力数值(现在以及预估未来),核心交互有两处:
- 发布 tweet 消息:4.6k qps, 峰值 12k qps
- 主页时间线(Hometimeline)浏览:300k qps
单独看 qps 不大,不过这里的挑战在于“巨大的扇出(fan-out)”(每个用户会关注很多人,也会被很多人圈粉),假定每个人平均有 75 个 follower. 上述两个主要场景,反馈到存储层,压力又高了一个数量级。
我们比较 push 和 pull 的优缺点:
- push: 写触发,每发布一次,更新到所有订阅者各自的 recipient 中。优点是每个 recipient 独立,缺点是写入压力随 follower 个数放大,以及无效写入(很久才会被读取,或者不会读取)
- pull: 读触发,每浏览一次,执行一次复杂的查询和排序。优点是数据流简单,没有无效计算,缺点则是读取压力随 followee 个数放大
Twitter 的实际做法是混合了 push && pull: 普通用户发布 push,大 v 发布 pull,用户浏览时做 merge.
这类实际问题的答案值得进一步思考,我在看书时临时想到的:
- 读 cache: 每个用户读取后最终排序的内容都是不一样的,所以读 cache 只能加到 tweets 表
- 隔离: push 的好处在于方便隔离,recipient 挂了也只会影响部分而不是全部用户;那 pull 能否做到这点?比如将大V 和普通用户分开存储,感觉理论上也是可行的,但是成本相比 push 要大?
- push&&pull 或者隔离引入的另一个问题是大V的判断依据,以及如何动态生效
可扩展性要做出假设,不能任意维度扩展。比如任务调度系统,假设后续需求都会围绕着任务类型、数据源、调度性能这些能力,因此就需要在这些维度可扩展。
1.3. 可维护性
空
2. 数据模型与查询语言
2.1. 关系模型与文档模型
数据模型是为了解决如何最佳的表示数据关系
历史上的探索有几种:
- 层次模型:一棵大树,每个记录只有一个父结点,表达多对多、join 非常困难,不得不手动维护多条重复记录。
- 网状模型:一个记录可能有多个父结点,使用时需要手动选择访问路径。
- 关系模型:数据被组织成关系(relations),在SQL中称为表(table),其中每个关系都是元组(tuples)的无序集合(在SQL中称为行)。这种模型目前最为人们接受,就像面向对象的思想一样,天然符合我们的认知。
- 文档模型:数据采用 1 对多的方式存储,我觉得比较像是层次模型。书里典型的例子是存储简历,整个数据就像是一个大的 json.
1 2 现在已经逐渐看不到了,在当时则是更多的为了适应硬件的限制条件。
3-SQL 非常成功
但是实际场景也有一些关系数据库满足不了的诉求:
- 比关系数据库更好的扩展性需求,包括支持超大数据集或超高写入吞吐量(我实际使用时最强的诉求)
- 普遍偏爱免费和开源软件而不是商业数据库产品
- 关系模型不能很好地支持一些特定的查询操作
- 对关系模式一些限制性感到沮丧,渴望更具动态和表达力的数据模型
以至于后来很多数据库给自己贴上了 NOSQL 的标签,作者直言不讳的说道:
它其实并不代表具体的某些技术,它最初只是作为一个吸引人眼球的Twitter标签频频出现在2009年的开源、分布式以及非关系数据库的见面会上
我很喜欢作者这种一阵见血的表达,使得我们不被迷惑在数据库厂商、云厂商兜售的各种名词里(湖仓一体、流批一体、LakeHouse/LakeWareHouse/DataLake/DeltaLake etc.)
回到 NOSQL 概念本身,4-文档模型典型的诸如 MongoDB
对比关系模型和文档模型:
| 关系模型 | 文档模型 | |
|---|---|---|
| 应用代码 | 1. 使用多个表表示一对多的关系 2. 支持 join(多对多的关系) |
1. 天然表达了一对多的关系,比如简历,name-positions-education-contact_info 2. 在引用嵌套类上要复杂一些,比如“指定 name 的 education 的第 2 项 ” 3. 需要应用程序发起多次请求后自行在内存里实现 join |
| 模式灵活性 | 写入时强校验,数据规范有保障 | 读取时解释,使用方便、自然 |
| 查询数据局部性 | 内容存储在多个表,读取全部需要花费更多的磁盘 IO 和时间 | 文档的全部内容都存储在一块,读取方便;但是只读取部分、更新时不方便 |
在最近蒋晓伟大佬分享的分布式 Data Warebase - 让数据涌现智能也引用了这个观点:

数据模型是表达信息的语言,有了这种语言后,数据就从比特升级为了表记录或者文档
我的理解:模型关注的是如何表达实体之间的关系,但是又会影响到实现方案,即使当前 PostgreSQL、MySQL 都对 JSON 文档提供了相应支持,但实现方案上差别很大。同时,像 Redis、HBase、ElasticSearch 这些,似乎又不属于上述的模型,或许数据库都在朝着 multi-model 的方向演进。
使用单一的模型,也无法表达所有的场景。
2.2. 数据查询语言
SQL 遵循了关系代数的结构,这点在Calcite-2:关系代数、架构与处理流程笔记里介绍过。
Elasticsearch 作为文档模型,也支持了 SQL 语法:
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"gender": "F"}},
{"match": {"age": 28}}
]
}
}
}
GET _xpack/sql
{
"query": "select * from online_trace_2021_02_20 where datatype='U' limit 1"
}
作者对比了声明式查询和命令式查询,我觉得声明式的更优,尽量复用通用的解析器、优化器生成物理执行方案,业务研发可以专注在如何用好数据库上。
在大数据领域,HiveSQL/SparkSQL 可以表达 Spark/MapReduce 任务,FlinkSQL 也可以实现实时任务。
当然 SQL 的表达能力是有限的,实际可能混用最为普遍。
用一张 flink 的图能够比较清楚的说明数据查询语言的层级,层级越高,表达越简洁,能够表达的含义也越来越少:

2.3. 图状数据模型
空
3. 数据存储与检索
3.1. 数据库核心:数据结构
看一个最简单的数据库例子:
#!/bin/bash
db_set() {
echo "$1,$2" >> database
}
db_get() {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
看到这个时心里一乐🤪,在写leveldb笔记开篇这篇笔记时,也想过一个类似的开头。
Bitcask(Riak中的默认存储引擎)所采用的核心做法是哈希索引:内存中存储 HashMap,key的语义不变,value 为文件对应的 offset.这种方式听上去过于简单,但是确实可行。缺点则是内存要求高、磁盘随机读、无法支持 range 查询等。
更加推荐的是两种索引结构:LSM-Tree 和 B-Tree.
LSM-Tree: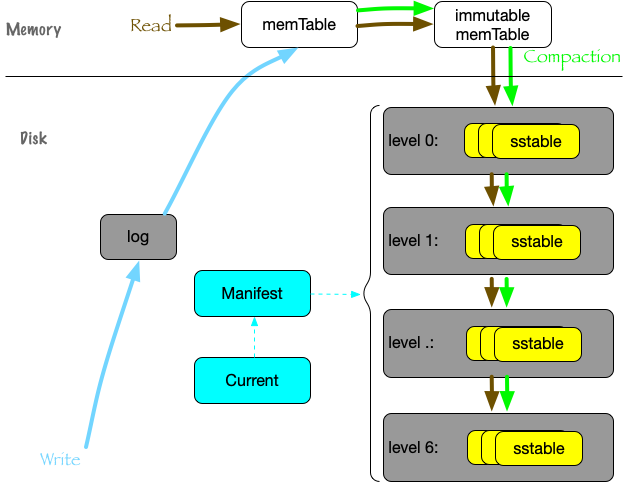
典型应用如 leveldb,SSTable 排序数据,LSM-Tree 管理 MemTable 和 SSTable,充分利用了磁盘的顺序写,适用于读最近写入数据的场景。当查询不存在的 key 时,会查询到最后一层,因此还使用了 BloomFilter 提前过滤。
B-Tree: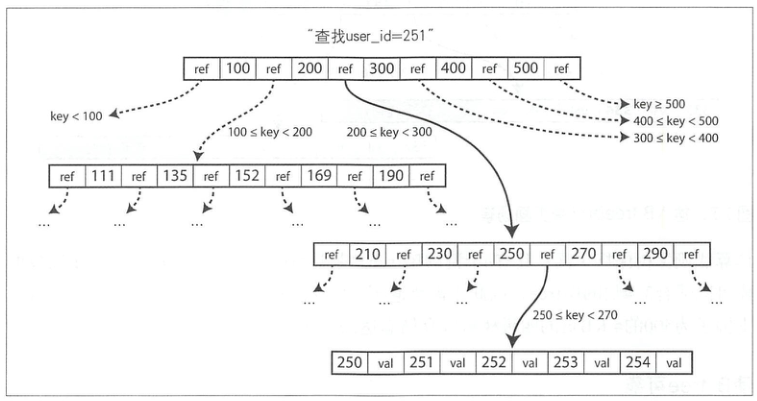
B-tree底层的基本写操作是使用新数据覆盖磁盘上的旧页,即原地修改。它假设覆盖不会改变页的磁盘存储位置,也就是说,当页被覆盖时,对该页的所有引用保持不变。这点跟 leveldb 的追加写是个鲜明的对比。
B-tree中一个页所包含的子页引用数量称为分支因子,例如图里分支因子为 6. 大多数数据库可以适合3~4层的B-tree,因此不需要遍历非常深的页面层次即可找到所需的页(分支因子为500的4KB页的四级树可以存储高达256TB:(500 + 500**2 + 500**3 + 500**4)*4/(10**9))
LSM-Tree 和 B-Tree 的对比:
| 对比项 | LSM-Tree | B-Tree |
|---|---|---|
| 写压力 | 没有随机写,写压力更小 但是 compaction 会导致严重的写放大 WAL(书里好像忽略了) |
WAL(顺序写)+写入页(随机写) |
| 压缩 | merge 后整体压缩方便 | 碎片多,预留固定页大小,压缩困难 |
| 事务语义 | 不支持 | 支持 |
LSM-Tree 和 B-Tree 是非常经典的两种索引结构。
二级索引、全文索引、模糊索引,则是在 KV 索引的基础上进一步复杂化。
同时注意数据结构是紧随着硬件性能演进的。
3.2. 事务处理与分析处理
数据存储,大致有两种用途:
- 后端交互:例如博客的评论、交易的订单等
- 业务分析:例如评论的来源城市分类、今天的交易量等
前者称为 OLTP(Transaction),后者称为 OLAP(Analytic).两者的比较:
| 属性 | OLTP | OLAP |
|---|---|---|
| 主要读特征 | 基于键,每次查询返回少量的记录 | 对大量记录进行汇总 |
| 主要写特征 | 随机访问,低延迟写入用户的输入 | 批量导入(ETL)或事件流 |
| 典型使用场景 | 终端用户,通过网络应用程序 | 内部分析师,为决策提供支持 |
| 数据表征 | 最新的数据状态(当前时间点) | 随着时间而变化的所有事件历史 |
| 数据规模 | GB到TB | TB到PB |
最初数据库是同时支持了 OLTP 和 OLAP 的场景的,但是随着查询越来越复杂,比如:
- 需要 join 不同 mysql 实例的数据,或者 join 不同存储类型(比如mysql, tidb),来分析数据
- 直接查询线上 mysql 实例压力过大,查询从库/备库也会因为扫描大量数据存在性能问题
- 日志类数据没有写入 mysql,但是同样需要数据分析
- 历史数据的对比,比如对比今天和昨天的数据,而数据库不支持 snapshot
- routine 的分析,最好是每天固定生成一次数据,而不是每次分析都要现执行 SQL
- 。。。
基于上述众多的原因,逐渐形成了数据仓库这个分支,专门用于业务分析。
而数据仓库也因为时效性的要求区别(天级、小时级、分钟级、秒级等),衍生出不同搭建方案和 OLAP 的选型,典型的如 Hive 和 ClickHouse。 因此从时效性的角度,OLTP 是 online,OLAP 则是混合了 near-online、offline 多种场景。之所以会产生这两个名词,本质上还是写入和分析的不同诉求。
3.3. 列式存储
在大多数OLTP数据库中,存储以面向行的方式布局:来自表的一行的所有值彼此相邻存储。文档数据库也是类似,整个文档通常被存储为一个连续的字节序列。
提出列存储的概念来自于一个观察:大部分情况,我们读取的都是该行少量字段而不是全部字段。
而基于列存而不是行存,存储上也有优势:
- 读取部分列而不是整行,降低了 IO 压力
- 同一列的数据类型相同,排序后前缀大多相同,压缩率高
- 如果该列的值可枚举,使用位图统一表达在存储和计算上都具有很大优势,其中位图个数=枚举值个数,位图 bit 数=行数
不只是在存储引擎,大数据在文件格式上也偏爱列存储,之前尝试整理过一篇入门笔记:大数据列存储文件格式。
在列存储的基础上,又进一步引入了向量化的概念。由于相同列相邻存储且格式相同,因此可以充分利用 CPU 的 SIMD 指令集加速计算,目前 SparkSQL/Presto 等都在逐步支持(Gluten、Velox),发展很快。我对这块很感兴趣,可惜受限于人手一直没能实践。
4. 数据编码与演化
为什么会需要数据编码格式?内存里的数据,保存在对象、结构体、列表、数组、哈希表和树等结构,不相邻的数据,使用指针指向。
但是当写入磁盘、网络发送时,就需要一段连续的字节,也就有了编码/解码,即序列化/反序列化。
- 编码应当是语言无关的
- JSON/XML/CSV 作为文本格式,可读性好,适用于部分场景(比如我负责的任务调度系统,产出数据默认用 csv/txt 提供,而 DolphinScheduler 原生则使用了 json);但是文本格式也有缺点:体积大、效率低、不支持二进制
- Thrift/Protobuf 作为二进制格式,使用广泛。其中作者提到的一些 Map、required 等特性,在 PB3 里都做了改进,有段时间我对 PB 的编码和接口设计很着迷,总结过几篇笔记
- Avro 没太看懂,似乎是在文件里包含了编码格式,因此是“自解释”的;同时由于应用于 hdfs,因此文件里多一些格式相关的字节,大小上完全可以忽略
为什么会需要数据流?本质上就是完成数据交换。
数据流有几种形式:
- 基于数据库:数据写入数据库,再由自身/其他程序读出
- 基于服务(REST RPC)
- 基于消息传递
基于服务的话,要明确使用 REST 还是 RPC. RPC 框架主要侧重于同一组织内多项服务之间的请求,通常发生在同一数据中心内。组织内服务之间,我也倾向于使用 RPC 而不是 REST,同时尝试过统一组内的 proto,但是阻力很大。注意虽然叫做 RPC,但区别是调用本地进程只会有两种结果:成功 或者 失败,而 RPC 一旦发生 Timeout,一切都是未知的。
基于消息传递的优点很多:
- 缓冲区
- 接收方崩溃不会丢数据
- 一条消息发给多个接收方,订阅即可
- 发送/接收隔离
适合于仅发送而不是数据交换的场景。
文本、二进制的数据编码分别适用于不同的场景。
二进制编码需要做到紧凑、性能高,以及向前向后的兼容性。
比如protobuf 里 unknown 字段的处理:假定 A -> B -> C 三个模块,即使 A C 使用 v2,B 使用 v1 版本,也一样能够保证数据不丢。
大数据则发展出了 Avro 格式用于写 hdfs 文件的场景。
数据交流可以基于数据库、REST or RPC、消息。基于消息的方式,让我想到大数据里的实时数仓架构,Event-Driven 组成一条条 pipeline.