
这篇笔记记录“第二部分-分布式数据系统”的心得。
分布式数据系统有 shared-memory、shared-disk、shared-nothing 三种。书里主要专注在第三种 shared-nothing 模式上。
1. 数据复制
1.1. 主节点与从节点
数据复制是为了做到高可用,但是也衍生出来了两个好处:
- 低延迟:选择地理位置更接近请求的副本
- 高吞吐:多个副本同时提供服务
mysql 的主从复制最为经典,也容易理解:
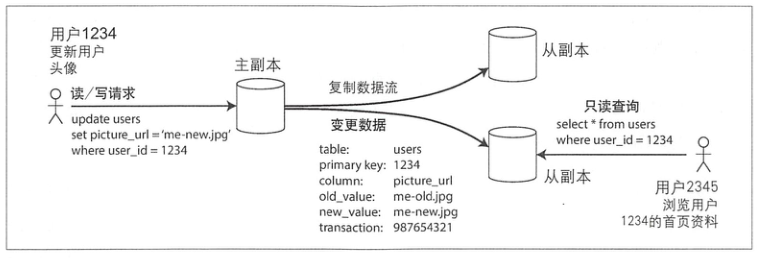
实际应用时,往往还会在用户和 mysql 实例间架一层 proxy,以实现连接复用、代理、SQL 语句路由等
kafka 的做法是提供了 ack1 配置让用户选择: 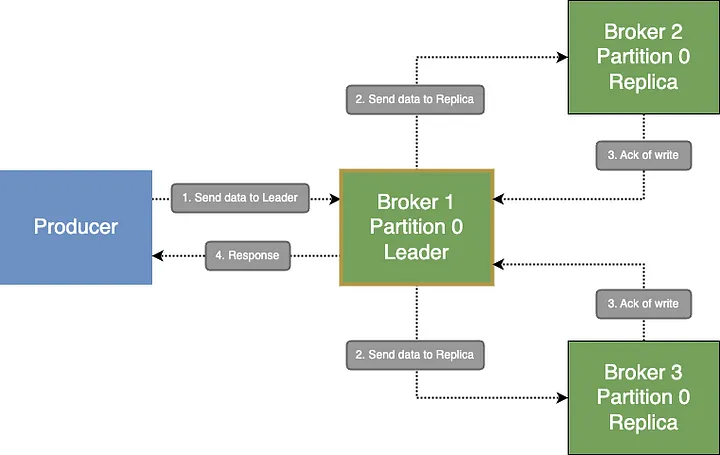
回到高可用的目的,主从复制要处理两类节点异常:
- 从节点异常:先从全量 t1 恢复,然后顺序订阅 t2(t2 < t1即可)的日志,直到数据完全追赶上。即全量初始化+增量同步,这个过程跟大数据里实时指标上线很像。
- 主节点异常
主节点异常处理要复杂很多,首先要确认节点异常,大多数据系统都会采用类似节点心跳的方式来确认异常,但是不那么靠谱,而且没有万无一失的方案。
举两个我实际遇到的例子:
apache dolphinscheduler 是这么判断 master 异常的:
Optional<Date> masterStartupTimeOptional =
getServerStartupTime(registryClient.getServerList(RegistryNodeType.MASTER),
masterHost);
registryClient可以简单理解为 zk,如果获取不到该 master 的启动时间,之后的代码则认为 master 异常,需要接管该 master 的任务。
而 master 自身在连接 zk 失效后会主动 stop:
public class MasterConnectionStateListener implements ConnectionListener {
public void onUpdate(ConnectionState state) {
switch (state) {
case CONNECTED:
logger.info("registry connection state is {}", state);
break;
case SUSPENDED:
logger.warn("registry connection state is {}, ready to retry connection", state);
break;
case RECONNECTED:
logger.info("registry connection state is {}, clean the node info", state);
registryClient.remove(masterNodePath);
registryClient.persistEphemeral(masterNodePath, "");
break;
case DISCONNECTED:
logger.warn("registry connection state is {}, ready to stop myself", state);
registryClient.getStoppable().stop("registry connection state is DISCONNECTED, stop myself");
break;
default:
}
}
}
这是个非常好的设计,异常 master 主动退出,正常 master 接管对应的任务。但是存在一个问题,就是如果 zk 抖动时,只会触发SUSPENDED而不会触发DISCONNECTED,master 不会 stop. 而上一段代码则已经认为该 master 已经宕机,尝试接管该 master 的任务。
这是典型的判断条件无法达成一致导致误判节点异常的例子。
硬件角度,同样很难判断 master 是否异常。举一个我在做主备 YARN 集群时的思考:
Yarn 本身的 ResourceManager 已经通过 ZK 实现了 HA2:
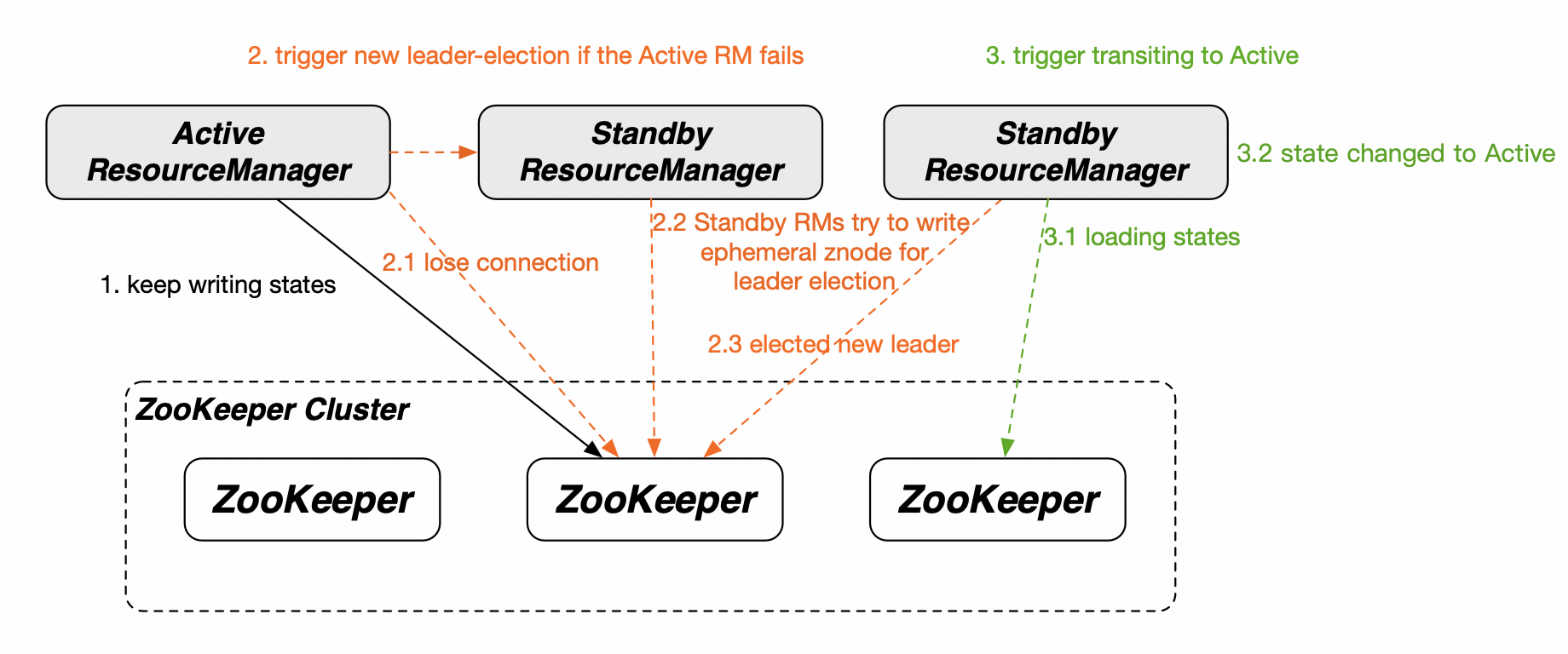
如果要启动 Yarn 备集群,第一个问题就是如何判断 Yarn 主集群已经宕机?基于上图里的架构,抛几个问题:
- 如何判断 Active 和 Standby 的 ResourceManager 都已经异常,而不是集群自身在主备切换
- 如果无法访问 Yarn 主集群,怎么判断是集群确实异常,还是客户端网络孤岛了
- YARN 自身为了防止网络抖动,ResourceManager 异常时,NodeManager 上的 application 仍然会等待阈值时间才会退出
- YARN 的高可用设计:ResourceManager 恢复时,会重新恢复之前的任务
仔细思考的话,会发现这里同样是防止误判、防止脑裂、最大程度确保(application/data)不丢不重的问题。
这里没有简单的解决方案,以至于有些运维团队宁愿使用手动方式来控制切换,就跟单云故障切换到其他云一样。
关于复制方案还需要考虑:
- 主从复制采用同步还是异步,更多是在数据可靠性和写入延迟折衷
- 复制日志不适合采用语句(random、自增列、存储过程等),适合采用 WAL/行 日志传输
数据复制是为了提高可用性设计的,衍生的效果则是低延迟和高吞吐。
主从模式最为直观,但是在如何判断主上,容易出问题。
数据复制不能承诺 100% 的可靠性。
1.2. 复制滞后问题
复制滞后导致的典型问题:
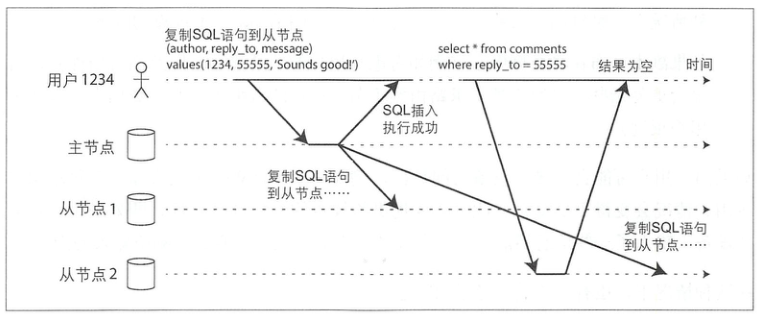
这种场景在读写 redis 时也非常常见,即写到主,数据没来得及同步到从,而随后的读落在从上。解决方案为通过请求来源、时间等强制读主。
此外针对主从复制滞后,从之间进度不一致的问题,提出了两种 case 及对应的解决方案:
- 单调读:避免读取不同副本带来的不一致,是比强一致性弱、最终一致性强的保证
- 前缀读:对于一系列有顺序的写请求,避免只读到了部分
1.3. 多主节点复制/无主节点复制
主要是冲突解决,以及收敛于一致状态,了解不多。
- 系统复杂性明显变高了,往往只能提供弱一致性。亚马逊的 Dynamo 系统采用了无主节点复制的方案,Cassandra 则提供了 ONE QUORUM ALL 等一致性的配置,交给用户决定。
- 使用 quorum 仲裁:如果有n个副本,写入需要w个节点确认,读取必须至少查询r个节点,则只要 w+r>n,读取的节点中一定会包含最新值。接着借助版本筛选出这个值。
2. 数据分区
2.1. 数据分区与数据复制
单机存储量的瓶颈靠分区解决,单机可用性的瓶颈靠复制解决:
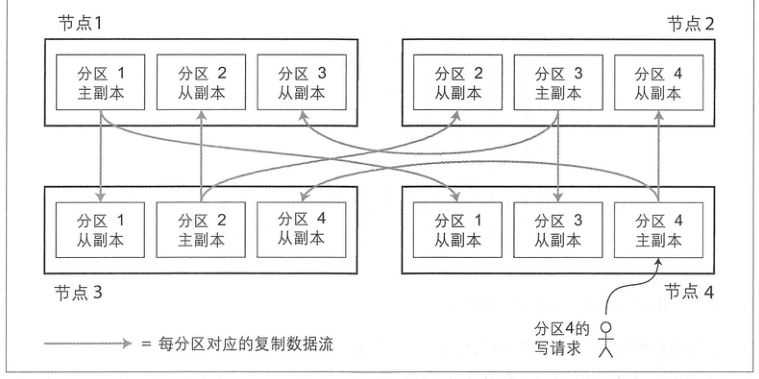
2.2. 键-值数据的分区
- 基于关键字区间分区: 比如字典的 a-z 排序,基于 LSM-Tree 的存储例如 hbase,习惯上称作基于 range 分区.
- 基于关键字哈希值分区: Cassandra 和MongoDB 使用 MD5, Voldemort 使用 Fowler-Noll-Vo 函数,不支持分区查询。Cassandra 也支持在这两种方案中做折衷。
在读热点问题上,比如访问大 V 的评论,分区同样显得无能为力,这种情况更适合在应用层减轻热点。
实时计算领域,Flink KeyGroup 的做法,则更像是 merge 了上述两种方案3。
2.3. 分区与二级索引
二级索引在分布式数据系统上的支持更加复杂
- 索引文件是全局还是分区的,分区的话查询是一个 scatter&&gather 的过程
- 更新索引和更新数据的先后顺序
- 索引的更改
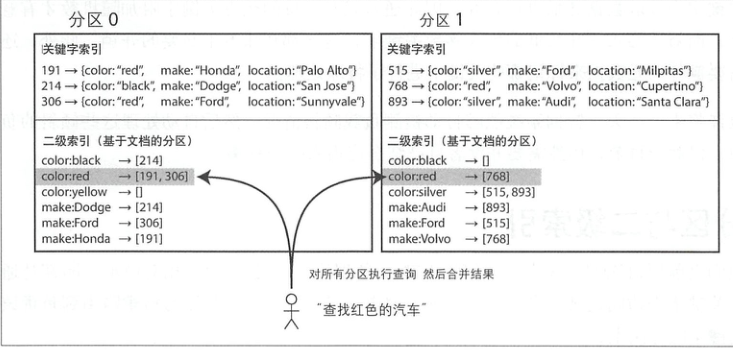
索引的更改相比数据更加复杂,我之前在设计系统时,特意忽略了该场景,转而在应用层兼容:
key = 191 , color 从 red 修改为 black,此时不仅更新 index=color:black 的值(增加 191),还需要更新 index=color:red 的值(删除 191)。即同时需要变化前后的值,来判断索引如何修改,此时就需要在 qps 压力和一致性间做出取舍。
2.4. 分区再平衡
- 固定数量分区:Riak、Elasticsearch、Couchbase 和 Voldemort 都支持这种动态平衡方法
- 动态分区:即写分裂的做法,典型如 HBase 和 RethinkDB
- 按节点比例分区:Cassandra 和 Ketama 采用,使分区数与集群节点数成正比关系
之前我在使用公司内部自研的 bigdata 时,往往需要预热数据以及手动拆分 tablet 以实现分区平衡,避免热点问题。
2.5. 请求路由
分区之后,需要进一步考虑请求路由的问题。
当客户端需要发送请求时,如何知道应该连接哪个节点?如果发生了分区再平衡,分区与节点的对应关系随之还会变化
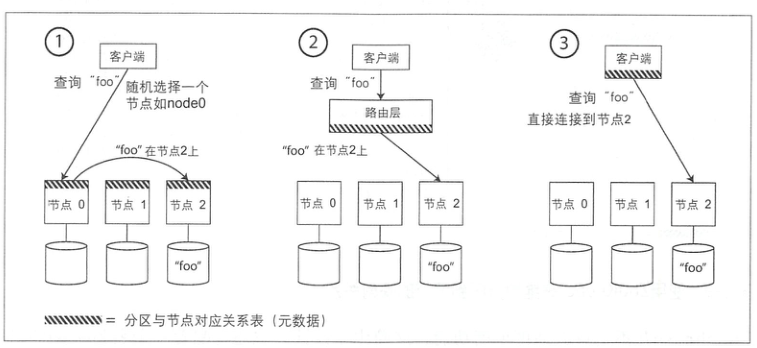
这里又演变成了一个参与者如何达成共识的问题,常见的有 Zookeeper、gossip 协议。
但是实际实现里为了避免压力,客户端往往缓存了映射关系;以及如果发送到了错误的 tablet-server,如何转发以及时序性的保证,就是更复杂的话题了。
除了如何确定请求路由,选择不同的技术方案,系统的落地设计也会不同:
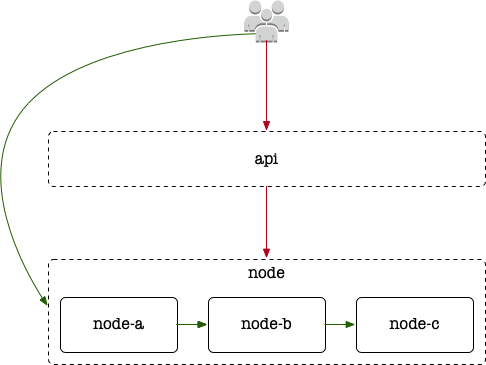
对于复杂系统,我更倾向于增加一层 api 的设计,以应对 node 间可能存在网络不可达的问题,模块功能上也能更加聚焦。
简单系统,如果有 sdk 可以采用方案 3;如果没有(比如仅通过 http 协议),则采用方案 2,好处就是实际维护的模块少。
3. 事务
事务的定义:
事务将应用程序的多个读、写操作捆绑在一起成为一个逻辑操作单元。即事务中的所有读写是一个执行的整体,整个事务要么成功(提交)、要么失败(中止或回滚)。如果失败,应用程序可以安全地重试。这样,由于不需要担心部分失败的情况(无论出于何种原因),应用层的错误处理就变得简单很多。
3.1. 深入理解事务
事务所提供的安全保证即大家所熟知的ACID,分别代表原子性(Atomicity),一致性(Consistency),隔离性(Isolation)与持久性(Durability),但是各个数据库的理解和实现并不相同。想法总是美好,细节方见真章。
而后来数据库又提出了 BASE 这个名词,基本可用性(Basically Available),软状态(Soft state)和最终一致性(Eventualconsistency),则唯一可以确定的是“它不是ACID”,此外它几乎没有承诺任何东西。
所以面对各类名词时,要多去思考而不是全盘接受
原子性:多个操作请求,要么都成功,要么都失败。
隔离性:其他事务的多条更新,在当前事务,要么看到的是全部完成的结果,要么就是一个都没完成的结果。
一致性:应用程序可能借助数据库提供的原子性和隔离性,以达到一致性,但一致性本身并不源于数据库。因此,字母C其实并不应该属于ACID.
持久性:承诺一旦事务提交成功,即使存在硬件故障或数据库崩溃,事务所写入的任何数据也不会消失。但我们知道并不存在 100% 的持久性,我们所说的 log,也只是为了更快的返回“对业务端承诺写入成功”,我们所说的数据复制,也只是为了让数字尽量接近于 100%.
3.2. 弱隔离级别
脏读:假定某个事务已经完成部分数据写入,但事务尚未提交(或中止),此时另一个事务是否可以看到尚未提交的数据? 如果是的话,那就是脏读。
举个例子,假设 tasks 表存储了多个 task: id 表示其索引,status 表示其状态,初始值为 0. 多个进程获取其状态:
mysql> select * from tasks where id = 1;
+----+--------+
| id | status |
+----+--------+
| 1 | 0 |
+----+--------+
1 row in set (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update tasks set status = 1 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
commit之前,在另一个进程里是观查不到该状态变化的:
mysql> select * from executors where id = 1;
+----+--------+
| id | status |
+----+--------+
| 1 | 0 |
+----+--------+
mysql> SELECT @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+
可以看到这里通过REPEATABLE-READ隔离级别防止了脏读,了解隔离性也有助于应用层的程序设计。
写倾斜: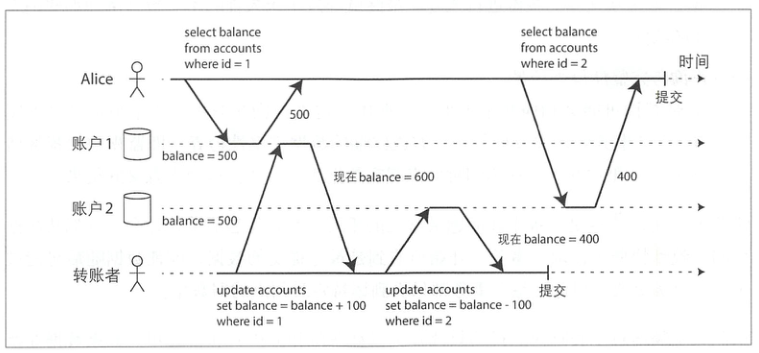
假设Alice在银行有1000美元的存款,分为两个账户,每个500美元。现在有这样一笔转账交易从账户1转100美元到账户2。如果在她提交转账请求之后而银行数据库系统执行转账的过程中间,来查看两个账户的余额,她有可能会看到账号2在收到转账之前的余额(500美元),和账户1在完成转账之后的余额(400美元)。对于Alice来说,貌似她的账户总共只有900美元,有100美元消失了。这种异常现象被称为不可重复读取(nonrepeatable read)或读倾斜(read skew)。如果Alice在交易结束时再次读取账户1的余额,她将看到不同的值(600美元)。
不可重复读似乎不是一个很严重的问题,上述场景,在 Alice 重新刷新页面后,数据就是一致的了。
但是有的场景却不能容忍:
- 备份场景: 备份可能需要数小时,镜像里可能包含部分旧版本数据和部分新版本数据。如果从这样的备份进行恢复,最终就导致了永久性的不一致。
- 分析查询与完整性检查场景: 扫描多条记录也会发现这个不一致的现象。
快照级别隔离是阶级上述问题最常见的手段,实现上则采用了 MVCC: 每个事务都有一个唯一、单调递增的事务ID(txid)
上述问题会记录删除的数据,以确保同一个事务 id 读到的数据是一致的:
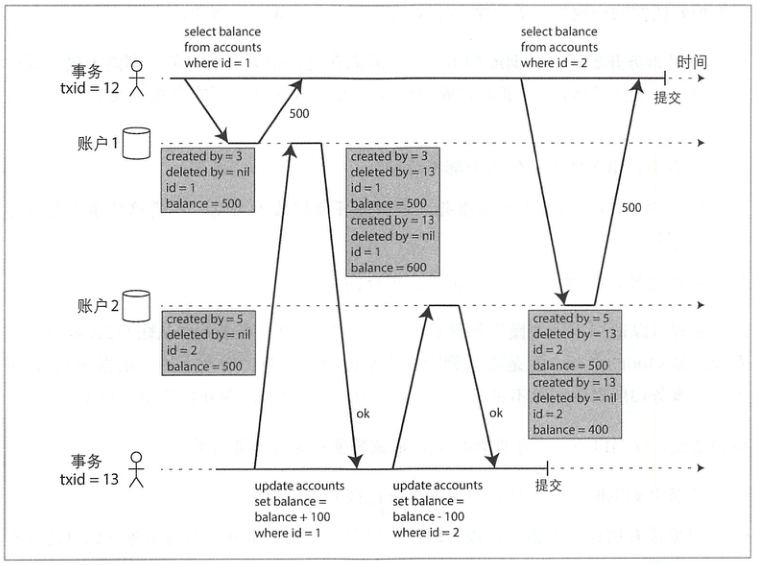
图中,事务13从账户2中扣除100美元,余额从500美元减为400美元。accounts表里会出现两行账户2:一个余额为$500但标记为删除的行(由事务13删除),另一个余额为$400,由事务13创建。
写倾斜: 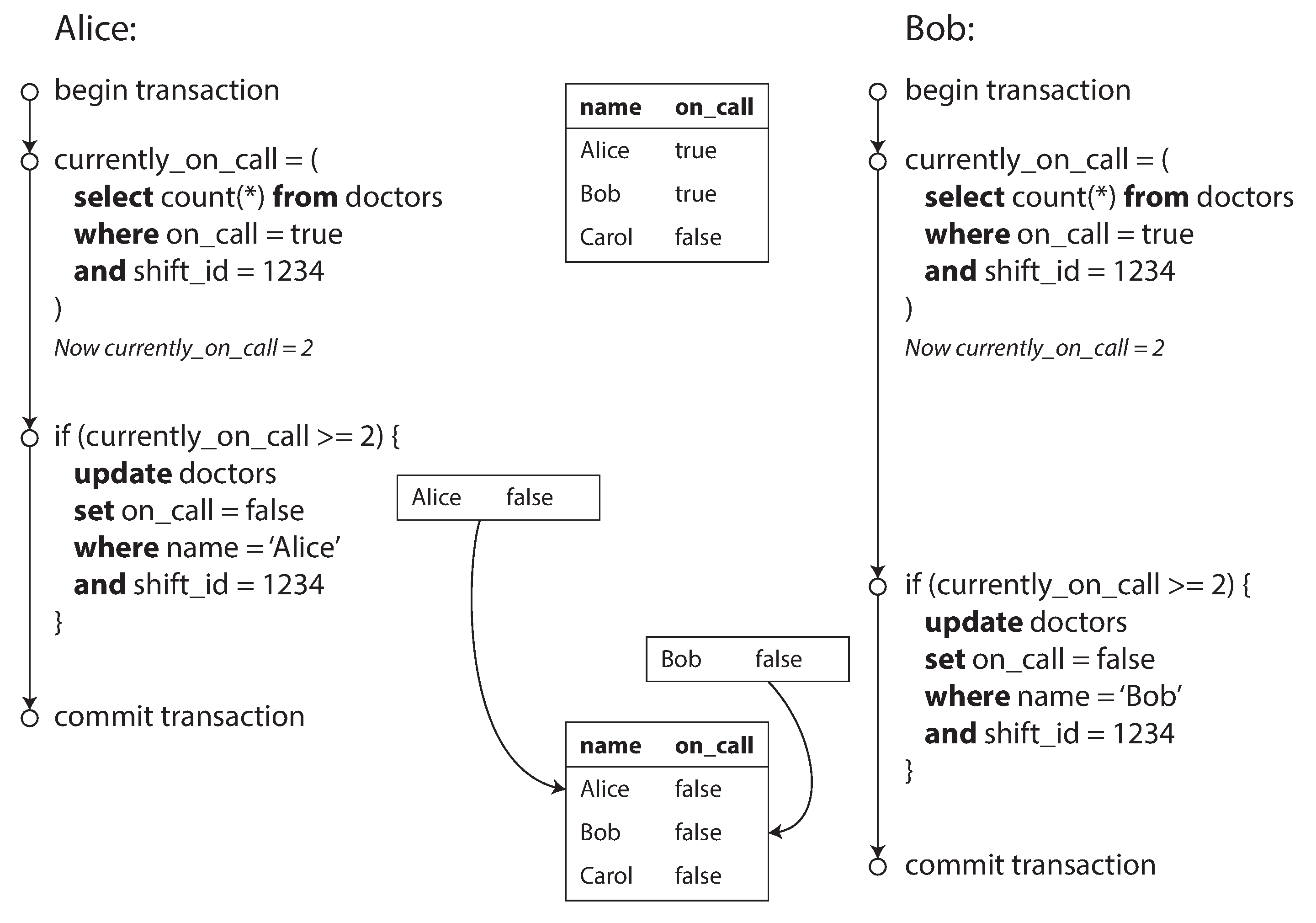
如图,每笔事务都会检查currently_on_call >= 2,是的话,则设置自身的on_call = false.
通过SELECT FOR UPDATE、实体化(单独建一个用于加锁的表)等方式可以解决这个问题,但是要注意SELECT FOR UPDATE返回空值可能导致方案无效的情况。
3.3. 串行化
串行化是最严格的方案,其吞吐量上限是单个CPU核的吞吐量。
还有一种解决方式是存储过程:
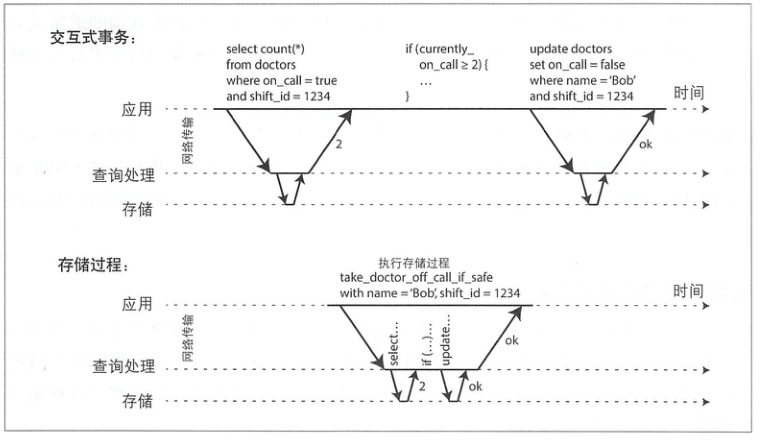
但是存储过程在数据库中运行代码难以管理:与应用服务器相比,调试更加困难,版本控制与部署复杂,测试不便,并且不容易和指标监控系统集成。
隔离级别通常难以理解,而且不同的数据库的实现不尽一致(例如“可重复读取”的含义在各家数据库的差别很大)。
因此应该在理解的基础上,尽量在应用程序侧实现一致性的需求。
4. 分布式系统的挑战
不能假定故障不可能发生而总是期待理想情况。最好仔细考虑各种可能的出错情况,包括那些小概率故障,然后尝试人为构造这种测试场景来充分检测系统行为。可以说,在分布式系统中,怀疑,悲观和偏执狂才能生存。
网络不可靠、时间不可靠。
网络不可靠不用多说,比如 timeout、延迟都是无法预知的。
这里对比了网络和电话线的区别:电话线是独占的,同时信息量少,因此电话很少出现延迟/卡顿的情况。但是网络的设计是共享的,信息量大,非独占就容易出现互相抢占的情况,进而出现延迟和丢包。
这里的介绍也让我想到了 Infiniband VS 以太网。
时间分两种,比如 clock_gettime 支持多种参数:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
int main(int argc,char *argv[])
{
struct timespec time1 = {0};
clock_gettime(CLOCK_REALTIME, &time1);
printf("CLOCK_REALTIME: (%lu, %lu)\n", time1.tv_sec, time1.tv_nsec);
clock_gettime(CLOCK_MONOTONIC, &time1);
printf("CLOCK_MONOTONIC: (%lu, %lu)\n", time1.tv_sec, time1.tv_nsec);
sleep(5);
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time1);
printf("CLOCK_PROCESS_CPUTIME_ID: (%lu, %lu)\n", time1.tv_sec, time1.tv_nsec);
sleep(5);
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
printf("CLOCK_THREAD_CPUTIME_ID: (%lu, %lu)\n", time1.tv_sec, time1.tv_nsec);
printf("now time :%lu\n", time(NULL));
return 0;
}
CLOCK_REALTIME返回 1970.1.1 的秒数,可能会回拨(闰秒)CLOCK_MONOTONIC返回单调时间(系统启动以来的秒数,跟uptime一致)
NTP 可能回拨本地时间,因此 1 返回的值可能会变化;而 2 如其名,是可以保证单调递增的(系统重启重置)
其实我平时看 log4j 日志,不同线程间、不同机器上时间都是可以用来比较先后顺序的,差别很小。
之所以对时间的值这么严谨,是因为分布式数据库写入时,会有
- Last-Write-Win 的机制,即多个并发写,以最后写入的为准
- 快照隔离机制,需要一个单调递增的事务 ID
这种需求,完全依赖于时间,是非常不可靠的。
4.4. 知识,真相与谎言
拜占庭问题,或许公共 update 的系统,比如区块链会需要?内部系统不用考虑。
5. 一致性与共识
5.1 一致性保证
最终一致性,实际是个非常弱的保证。因为没有承诺这“最终”要多久。
事务隔离和分布式一致性有一定的相似之处,但是事务隔离主要是为了处理并发执行事务时的各种临界条件,而分布式一致性则主要是针对延迟和故障等问题来协调副本之间的状态。
5.2 可线性化
想法是让一个系统看起来好像只有一个数据副本,且所有的操作都是原子的。有了这个保证,应用程序就不需要关心系统内部的多个副本
简单来说,一旦某个读操作返回了新值,之后所有的读(包括相同或不同的客户端)都必须返回新值:
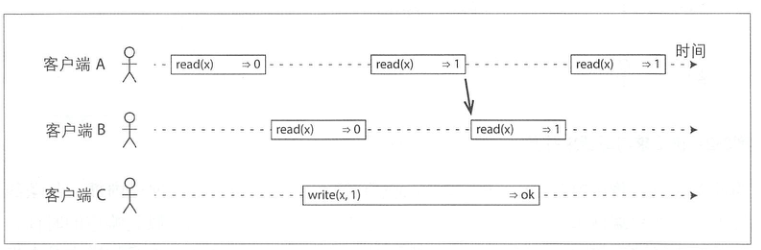
对于主从复制系统,这个要求就强制了所有写请求和线性化读取都必须发送给主节点,因此可用性取决于主节点。
而对于采用其他数据复制方式的系统,一旦出现网络中断,也一样必须在可线性化和可用性之间做出选择了。
这个思路,即 CAP 理论。
CAP 是指一致性,可用性,分区容错性,通常我们会说系统只能支持其中两个特性。但实际上,网络分区是一种故障,现实存在的。因此 CAP 更准确的说法,是当发生网络分区时,要在一致性和可用性之间做出选择。
除了网络分区,实际还有网络延迟、节点宕机等各种异常情况,因此作者认为尽管CAP在历史上具有重大的影响力,但对于一个具体的系统设计来说,它可能没有太大的实际价值
即使从分布式的角度支持了线性化,多核 CPU 计算上也需要通过内存屏障或者 fence 来避免L1/L2Cache 和内存数据的差异。可以想象到这里强制线性化带来的性能损耗,所以大部分数据库不支持线性化的首要出发点,就是提高性能,而不是为了保住容错性。
注意:避免混淆了可线性化(Linearizability)与可串行化(Serializability),后者通常在事务的隔离属性里提到。
5.3 顺序保证
其实读到这里,感觉很多概念都很像,只是应用在了不同的场景,所以进一步抽象的话,是不是存在一些共性?
比如:
- 一致前缀读:问题 -> 答案,避免先观察到了答案
- 检测并发写:两个操作 A B 操作同一个 key,A 是 insert, B 是 update,避免先看到了 update 再看到 insert
- 可串行化的快照隔离:两个操作基于同一个前提,但是一旦一个操作成功后,这个前提就从 true 变成了 false
这里都包含了一层因果顺序关系,如果把上一节的线性化理解为“全序”的话,因果顺序则是一种“偏序”。因果顺序关系,是不会由于网络延迟而显著影响性能,又能对网络故障提供容错的最强的一致性模型。
那接下来的问题就是,如何捕获因果依赖顺序?计数器、Lamport时间戳(每个请求需要带着?)、版本向量
5.4 分布式事务与共识
单节点的原子提交,可以使用事务实现。多节点就复杂了很多,有的节点可能成功,有的可能失败(或者未知),即使能够检测到失败,那已提交的事务是不能回滚的(回滚和提交是并列的,一旦提交,就变得可见,其他操作会基于该事务的结果更新)。
两阶段提交(two-phase commit,2PC)是一种在多节点之间实现事务原子提交的算法,用来确保所有节点要么全部提交,要么全部中止。它是分布式数据库中的经典算法之一。
为什么网络是不可靠的,修改为两次提交就可以解决问题?我一直有这个疑问,这本书里终于找到了答案,实际还有一个关键的组件:协调者。
- 当应用程序启动一个分布式事务时,它首先向协调者请求事务ID。该ID全局唯一。
- 应用程序在每个参与节点上执行单节点事务,并将全局唯一事务ID附加到事务上。此时,读写都是在单节点内完成。如果在这个阶段出现问题(例如节点崩溃或请求超时),则协调者和其他参与者都可以安全中止。
- 当应用程序准备提交时,协调者向所有参与者发送准备请求,并附带全局事务ID。如果准备请求有任何一个发生失败或者超时,则协调者会通知所有参与者放弃事务。
- 参与者在收到准备请求之后,确保在任何情况下都可以提交事务,包括安全地将事务数据写入磁盘(不能以任何借口稍后拒绝提交,包括系统崩溃,电源故障或磁盘空间不足等),并检查是否存在冲突或约束违规。一旦向协调者回答“是”,节点就承诺会提交事务。换句话说,尽管还没有真正提交,但参与者已表态此后不会行使放弃事务的权利。
- 当协调者收到所有准备请求的答复时,就是否提交(或放弃)事务要做出明确的决定(即只有所有参与者都投赞成票时才会提交)。协调者把最后的决定写入到磁盘的事务日志中,防止稍后系统崩溃,并可以恢复之前的决定。这个时刻称为提交点。
- 协调者的决定写入磁盘以后,接下来向所有参与者发送提交/放弃请求。如果此请求出现出现失败/超时,则协调者必须一直重试直到成功为止,同时所有节点不允许反悔。
这里有两个关键的承诺:
- 参与者投票“是”时,它做出了肯定提交的承诺
- 协调者做出了提交(或者放弃)的决定,这个决定也是不可撤销
共识算法,典型的就是Raft,全序广播确保所有参与者以相同的顺序接收和处理消息。