
这篇笔记记录“第三部分-派生数据”的心得。
放到现在看,批处理系统是假定了基于有界的数据集,而流处理系统作为后来者,则面向了有界&无界的数据集,在 Google 的 Data Flow Model 这篇论文里,也论证了,处理无界数据的方法也可以用来处理有界数据。
1. 批处理系统
1.1. 使用UNIX工具进行批处理
“管道”的思想在 UNIX 里很常见,比如可以这么处理文本数据:
cat /var/log/nginx/access.log |
awk '{print $7}' |
sort |
uniq -c |
sort -nr |
head -n 5
这种思想带来的好处,是各个组件的精简和专注,通过组合又可以实现复杂的功能。
1.2. MapReduce与分布式文件系统
关于 MapReduce,非常推荐 MIT 6.824 的课程 Lab-1.
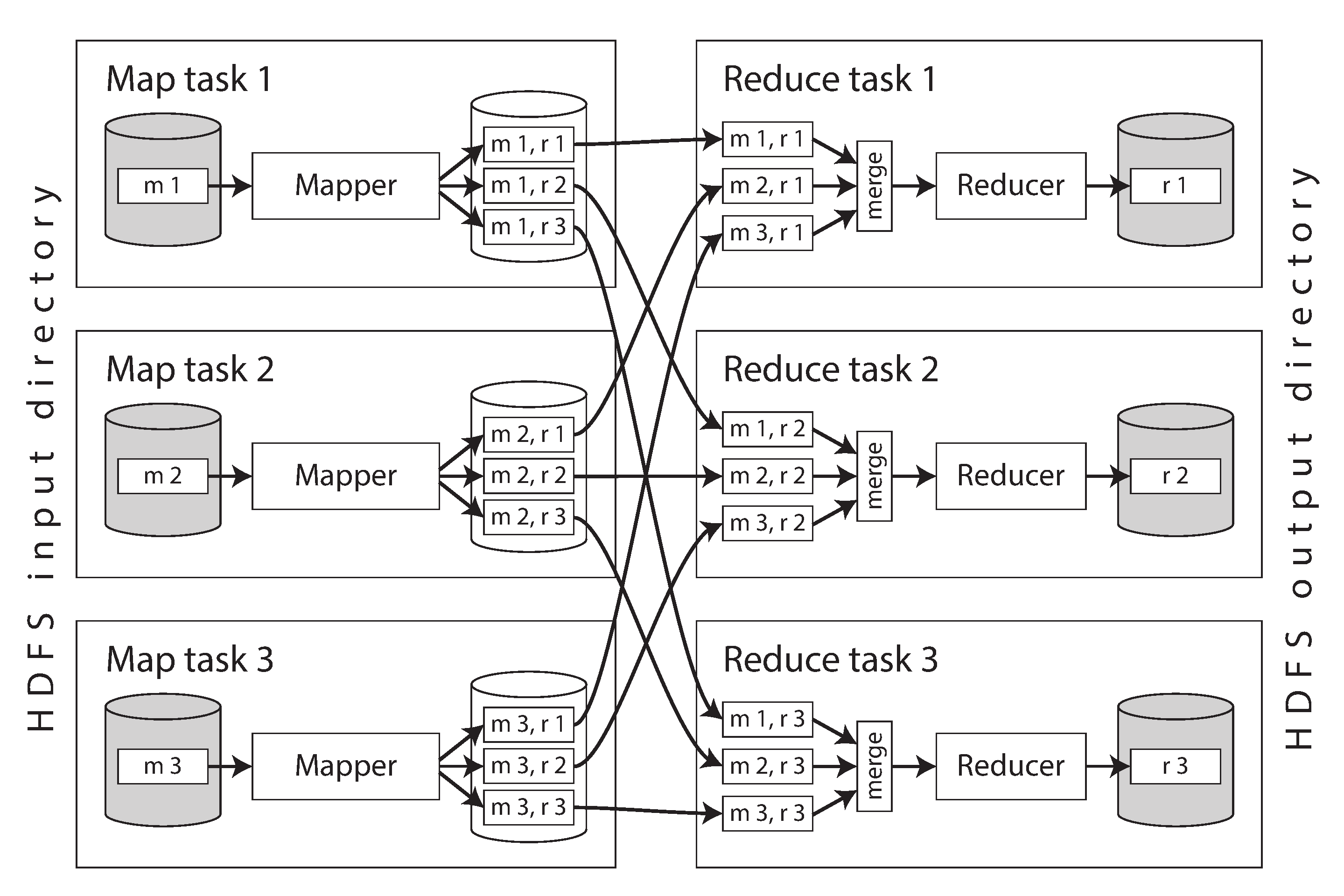
MR 里的 join 可能在 map、reduce 阶段执行。
Reduce Join 最为常见和自然:mapper 提取 joinkey,排序后,reducer 类似双指针的方式操作左右表。
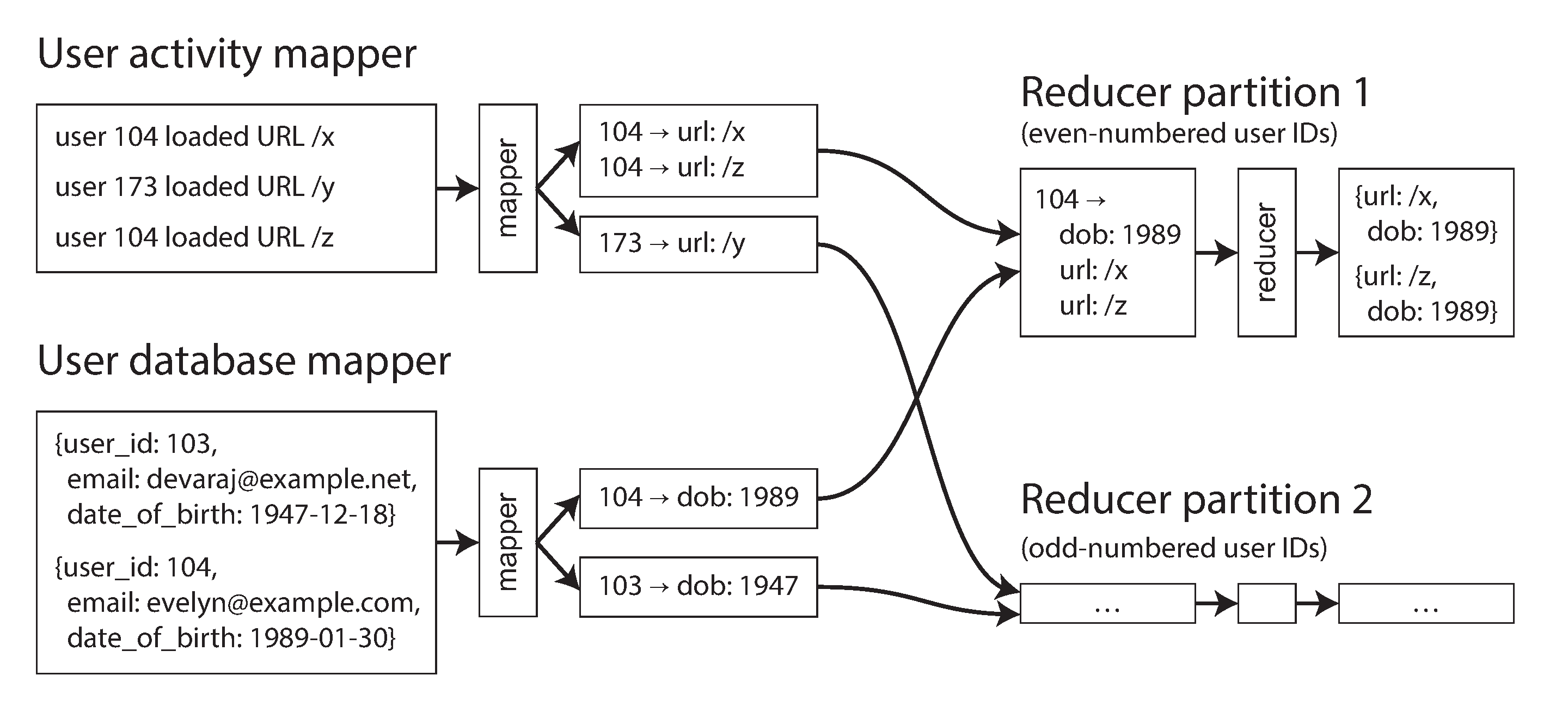
优点是不需要对输入数据做任何假设: 无论其属性与结构如何,mapper 都可以将数据处理好以准备 join。缺点是排序,复制到 reducer 以及合并 reducer 输入可能会是非常昂贵的操作。
优化的方式就是 Map Join :
- Broadcast hash joins: 大表 join 小表的场景,每个 mapper 实例都加载小表的数据到内存里
- Partitioned hash joins: 两个 join 的输入具有相同数量的分区,根据相同的关键字和相同的哈希函数将记录分配至分区。Hive 里成为 Bucket Map Join.
- Map-side merge joins: 我理解也是数据排序然后 merge,跟 Reduce Join 的区别在于数据已经是有序且分桶数相同。无需排序、键值范围一致因此单个 mapper 即完成局部处理,同时无需 shuffle.
注:刚开始接触大数据时,我对 shuffle 这个词很困惑。reducer 与每个 mapper 相连接,并按照其分区从 mapper 中下载排序后的键值对文件。按照 reducer 分区,排序和将数据分区从 mapper 复制到 reducer,这样一个过程被称为 shuffle.
基于 MapReduce,也诞生了一批任务调度系统:Oozie,Azkaban,Luigi,Airflow 和 Pinball,我个人比较熟悉的是 DolphinScheduler
1.3. 超越MapReduce
MapReduce 的一个特点是中间数据持久化,这使得容错变得相对简单。Spark、Flink 则避免数据落盘以提供更高的性能,因此在容错上的设计也对应更为复杂(Spark-RDD 和 Flink-Checkpoint)。
回归到对 UNIX 管道的类比上,MapReduce 像是将每个输出都写到临时文件,而 Flink 则增量的将数据传递出去。而排序算子不可避免的要基于全量数据,这也是在 Flink 里引入 window 的原因了。
2. 流处理系统
2.1. 发送事件流
发送消息时,如果生产速度大于消费速度,可以采用背压的方案,以阻止生产者继续发送消息。
流式处理第一个需要考虑的问题就是乱序,图里即当 ConsumerGroup 里单个 consumer 挂掉后,rebalance 可能导致的数据乱序:
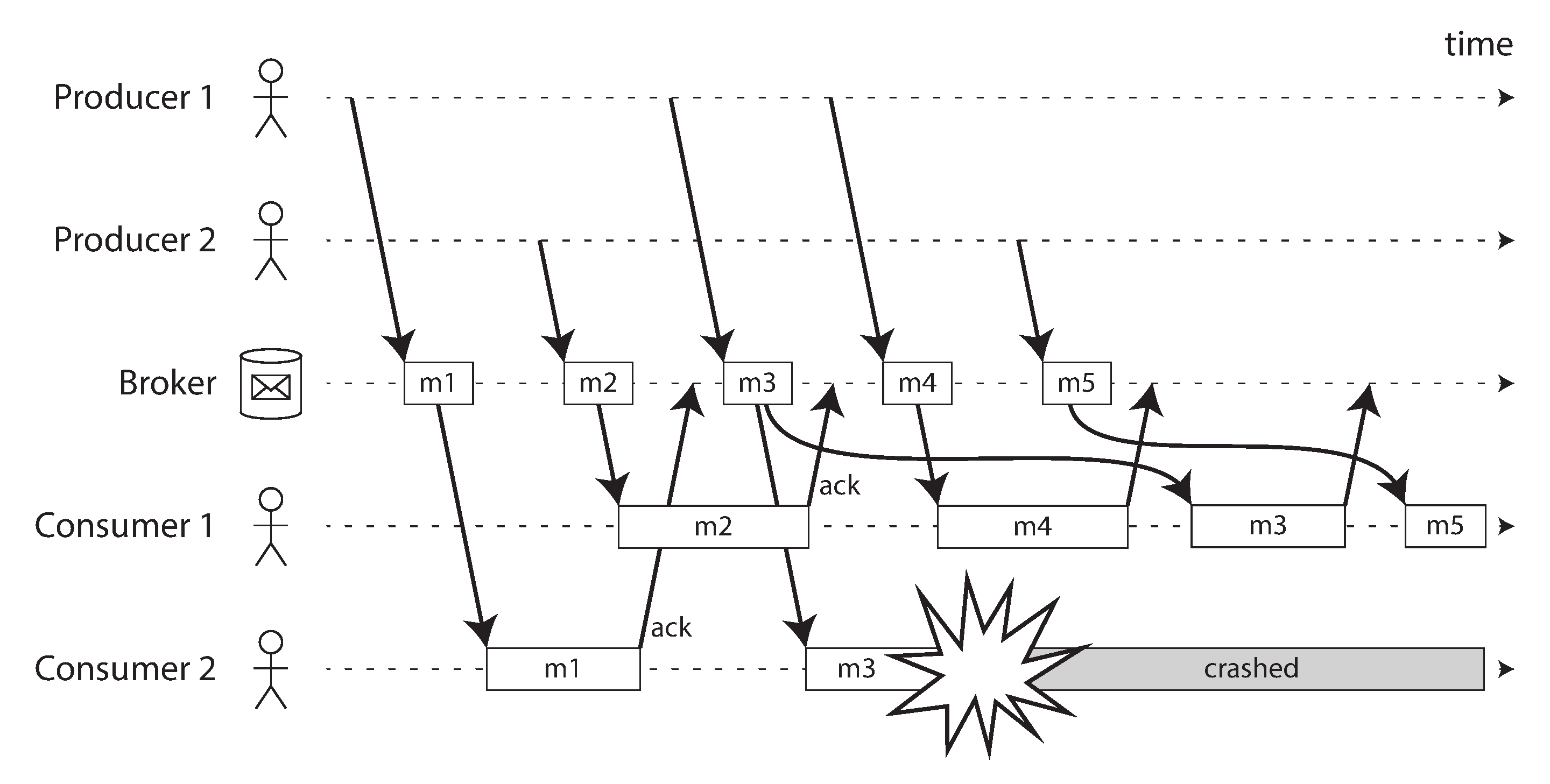
印象里,Flink 里的做法是给每个 TaskManager, 通过assign(Collection<TopicPartition> partition)单独指定了待消费的 partition,即规避了 ConsumerGroup 自身的负载均衡。
2.2. 数据库与流
CDC 捕获数据库变更记录,转化为数据流。Canal、FlinkCDC 都属于这类技术。
2.3. 流处理
处理 unbound 数据,相比 bound 数据有两个明显的区别:
- 排序不能基于全部数据
- 容错不能简单的从头开始
只要输入数据不变,无论运行多少次,批处理的结果都是确定的(特意使用 random 的除外)。因此,在批处理场景,对处理时间关注不多。
流计算场景,则对时间格外看重。Flink 社区提了一个很有意思的比喻:
如果找一个类比的话,可以考虑一下“星球大战”这部电影:
第四部于1977年上映,1980年的第五部,1983年的第六部,之后分别于1999年,2002年和2005年上映第一部,第二部,第三部,以及2015年的第七部。
如果以上映顺序来观看电影,则观看(“处理”)电影的顺序与它们叙述的事件顺序就是不一致的(每部的编号就像事件时间戳一样,而观看电影的日期就是处理时间)。
人类能够应付这样的不连续性,但是流处理算法则需要专门的代码处理,以适应这样的时间和排序问题。
如果要统计“最近 5 分钟的用户行为”,你会发现在流处理有个问题:无法确定是否已经收到所有事件,是否还有一些事件尚未到来。针对这个问题,由于不能无限制的等待(增加了延迟),因此会引入 Lateness 的概念。对于迟到的数据,要考虑好是丢弃还是更新已经发出的数据。
这些问题并不是流处理独有的,批处理也会在时间推理方面遇到相同的问题,只不过在流处理环境中更加明显,我在批处理和流处理的思考介绍了自己的一些初步思考。
流的 join、流 join 的时间特性、流的容错等,也都是非常值得思考的话题,知易行难。我把一些经验总结在了tag-flink
3. 数据系统的未来
3.1. 数据集成
数据集成的概念,现在似乎演变成了不同数据源间的同步能力,外加一些简单的 ETL 功能。
3.2. 分拆数据库
这里不是指分库分表,而是说单一的数据库无法满足全部需求,底层统一 API,上层组合能力。
对分析师来说,很多报表都使用 Excel 实现,当修改单元格的内容时,其他有关联的单元格内容也会修改。或许在迁移到各类数据系统上之后,他们希望的仍然是这个效果:输入修改,可视化的看到改变后输出。
为了确保数据准确,流式系统采用消息排序和容错处理,而没有使用分布式事务的原因,就是代价大太多了。
3.3. 端到端的正确性
Exactly Once 的实现方法可以使用 2PC,如果仅从效果层面看,通过算子支持幂等来达到这个目的要简单的多。
比如虽然在转账时使用了事务:
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance + 11.00 WHERE account_id=1234;
UPDATE accounts SET balance = balance - 11.00 WHERE account_id =4321;
COMMIT;
如果客户端在发送 COMMIT 之后,收到响应之前遭遇网络中断和连接超时等,它就不知道事务是否已被提交或中止了。此时暴力的重试会导致重复执行问题。
此时,为操作生成一个唯一的标识符(如UUID)是一个可行的方案,比如在上述 SQL 里插入:
-- ALTER TABLE requests ADD UNIQUE(request_id)
INSERT INTO
requests
(request_id, from_account, to_account, amound) VALUES
('0286FDB8-D7E1-423F-B40B-792B3608036C', 4321, 1234, 11.00)
从这个例子,可以看到不能简单依赖数据库的特性,来推断应用程序的行为。应用程序同样需要实现确保端到端的正确性。
正因如此,探索更抽象的端到端的正确性解决方案,使得应用程序能够不再关心,更加必要。
作者提到:
在许多商业环境中,实际上可以接受的是暂时违反约束,稍后通过道歉流程来修复。
道歉(金钱或声誉)的成本各不相同,但通常很低:
你不能取消已发送的电子邮件,但可以发送后续电子邮件并进行更正。如果不小心向信用卡收取了两次费用,可以退还其中一笔费用,而你的成本只是处理成本,或者客户投诉
面对不完美的系统时,我们有时候也要承认技术是有限的(尽管你要努力将 99.99% 提高到 99.999%)。
3.4. 做正确的事情
从技术的角度,我们习惯了用指标衡量,尽可能在设计上足够抽象,实现上又斟酌每个细节。
但是回到系统构建的目的本身,许多数据集都是关于人的: 他们的行为、他们的兴趣和他们的身份。我们必须以人性和尊重来对待这些数据。用户也是人,人的尊严是最重要的。
隐私!隐私!隐私!无论是大数据工程还是数仓,所有的参与者都应该从心底敬畏数据。这里可能包含用户的手机号、地址,数据的使用受到道德和法律的监管。