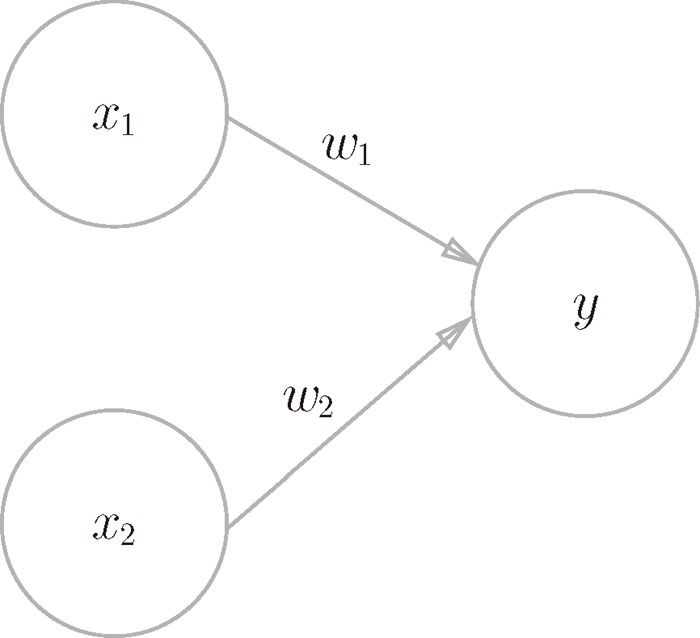
1. Theory - Dataflow Model
Dataflow Model这篇论文,对大数据的处理范式做了总结,并且提出了一套处理模型。
1.1. Window
数据转换操作,有两种:
- ParDo: 1->N,例如 map/flatmap/filter 等,这类操作在 unbound 和 bound 数据集上没有区别
- GroupByKey: 聚合操作在 bound 数据集很自然;在 unbound 数据集上,既然数据不会结束,就需要解决何时聚合的问题。
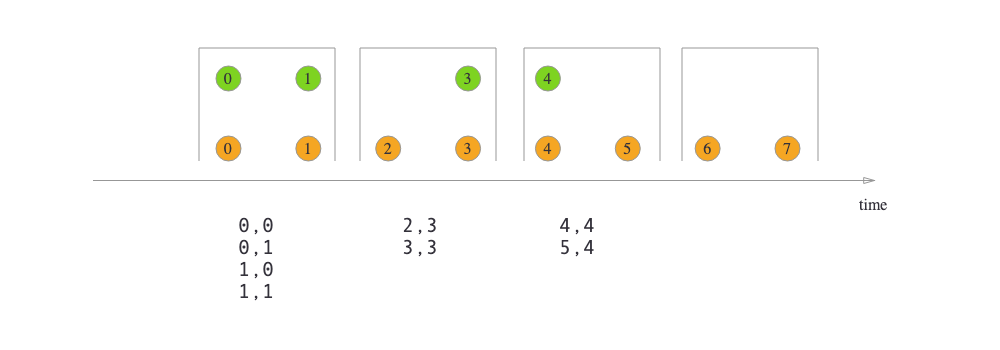
之前在批处理和流处理的思考这篇笔记里提到过,bound 数据集其实也是在 unbound 数据集的一个划分,通常情况是 1 天/小时的数据。而论文则用更抽象的角度,提出了 window 的概念,用于在unbound 的数据集上,人为划分出一个 bound 的数据集合,GroupByKey 变成 GroupByKeyAndWindow.
有了 window 的概念,还需要拆解更进一步的定义解决:
- Where in event time they are being computed : 计算哪些数据
- When in processing time they are materialized : 何时计算数据
1.2. Where - assign and merge
数据应该属于哪个窗口:
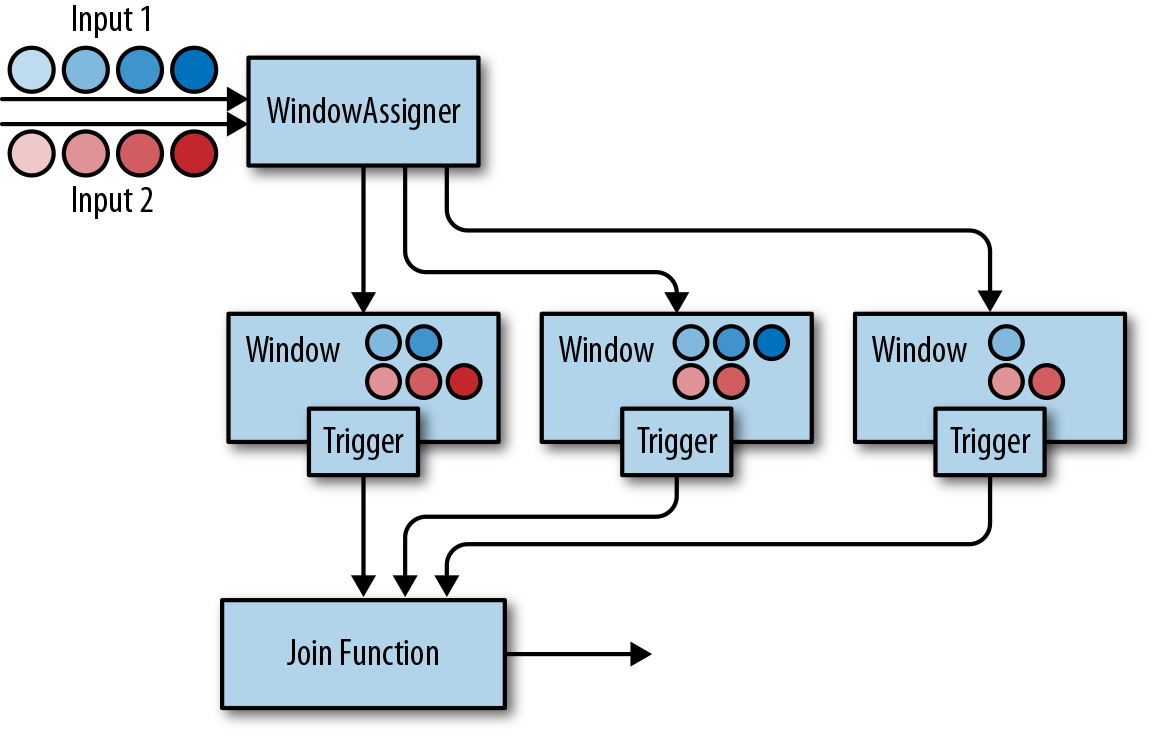
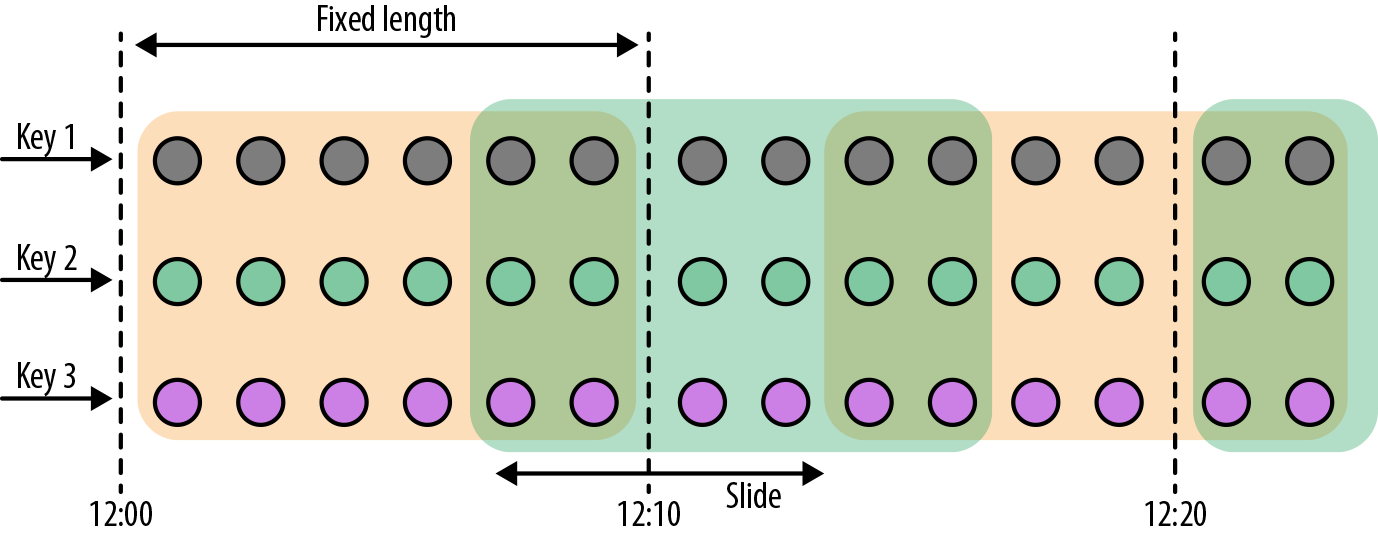
Set<Window> AssignWIndows(T datum): 数据到达后,应该划分到哪些窗口,以 SlidingWindow 为例: 
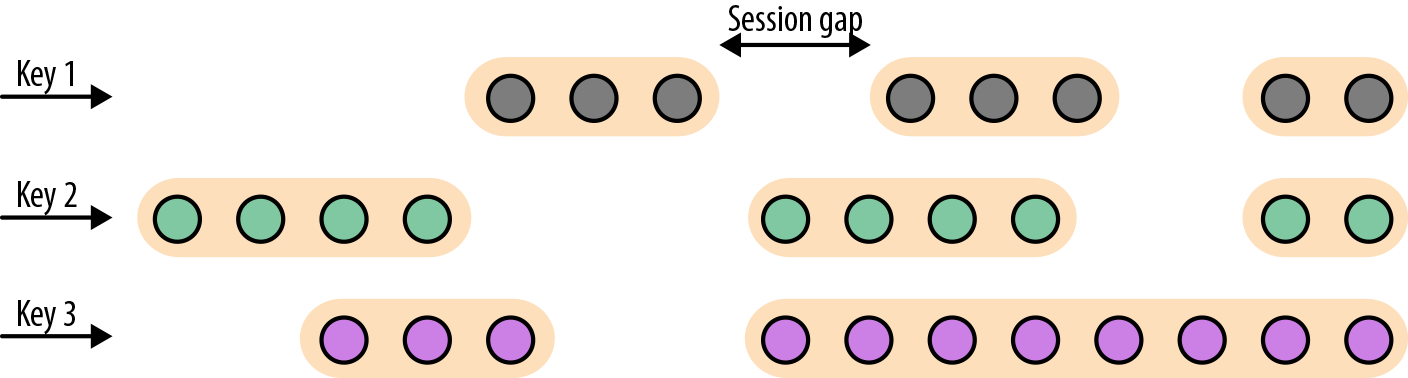
Set<Window> MergeWindows(Set<Window> windows): 典型的如 session 窗口,只从当前数据判断不出窗口范围,依赖收到后续数据判断窗口结束后,对窗口进行 merge,生成需要计算的窗口。以 SessionWindow 为例:

1.3. When - triggers and incremental processing
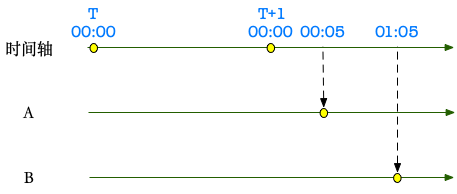
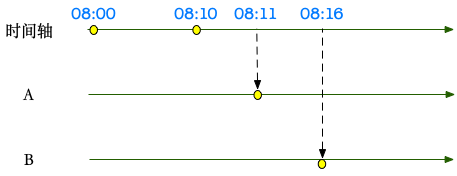
窗口何时结束,开始计算窗口内的数据。但是水位线过快、过慢都有问题。
A useful insight in addressing the completeness problem is that the Lambda Architecture effectively sidesteps the issue…
从 Lambda 架构的经验看:或许可以尽快触发水位线,同时保证能够处理后续数据(已经 trigger 的窗口迟到的数据),以达到最终一致性。
注意这里经常提到水位线,但是窗口跟水位线并不绑定,比如 CountWindow SessionWindow 等
2. Implement - Flink
对论文里的定义,Flink 实现的语义基本都是一致的。这一节介绍代码部分(例子及源码均使用 1.14版本)。
2.1. Example
使用 window 计算 5s 窗口内最小温度值的例子:
// case class SensorReading(id: String, temperature: Double, eventTime: Long = -1L)
env.fromElements(
SensorReading("sensor_a", 2.1, 1000L),
SensorReading("sensor_a", 1.1, 2000L),
SensorReading("sensor_b", 0.1, 2500L),
SensorReading("sensor_a", 3.6, 3000L),
SensorReading("sensor_a", 4.5, 4000L),
SensorReading("sensor_a", 5.0, 5000L),
).assignAscendingTimestamps(_.eventTime)
.keyBy(_.id)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction[SensorReading, (String, Double, Long), String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[SensorReading], out: Collector[(String, Double, Long)]): Unit = {
println(s"now we process with key: $key and window: ${context.window}")
println(s"elements: \n\t${elements.toList.mkString("\n\t")}")
out.collect(key, elements.minBy(_.temperature).temperature, context.window.getEnd)
}
})
// .reduce((a, b) => SensorReading(a.id, a.temperature.min(b.temperature), 0L))
.print("min temperature ")
指定SensorReading第三个参数为事件时间,窗口类型为 TumblingWindow,周期=5s,然后通过process计算窗口内的温度最小值。为了简便说明,数据的 id 是相同的。
输出:
now we process with key: sensor_a and window: TimeWindow{start=0, end=5000}
elements:
SensorReading(sensor_a,2.1,1000)
SensorReading(sensor_a,1.1,2000)
SensorReading(sensor_a,3.6,3000)
SensorReading(sensor_a,4.5,4000)
min temperature > (sensor_a,1.1,5000)
now we process with key: sensor_b and window: TimeWindow{start=0, end=5000}
elements:
SensorReading(sensor_b,0.1,2500)
min temperature > (sensor_b,0.1,5000)
now we process with key: sensor_a and window: TimeWindow{start=5000, end=10000}
elements:
SensorReading(sensor_a,5.0,5000)
min temperature > (sensor_a,5.0,10000)
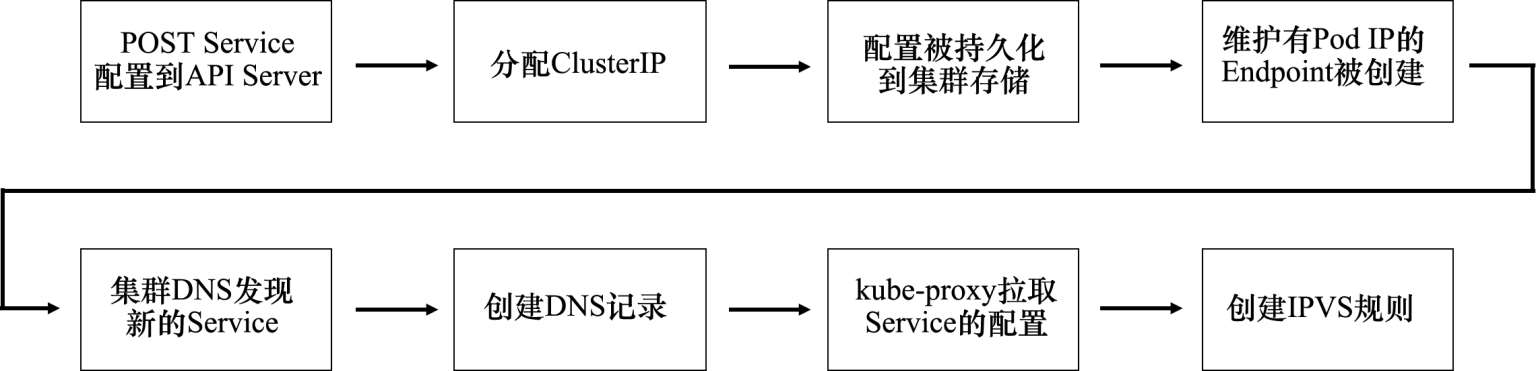
代码实际流程,在 Flink 实现里分为几部分: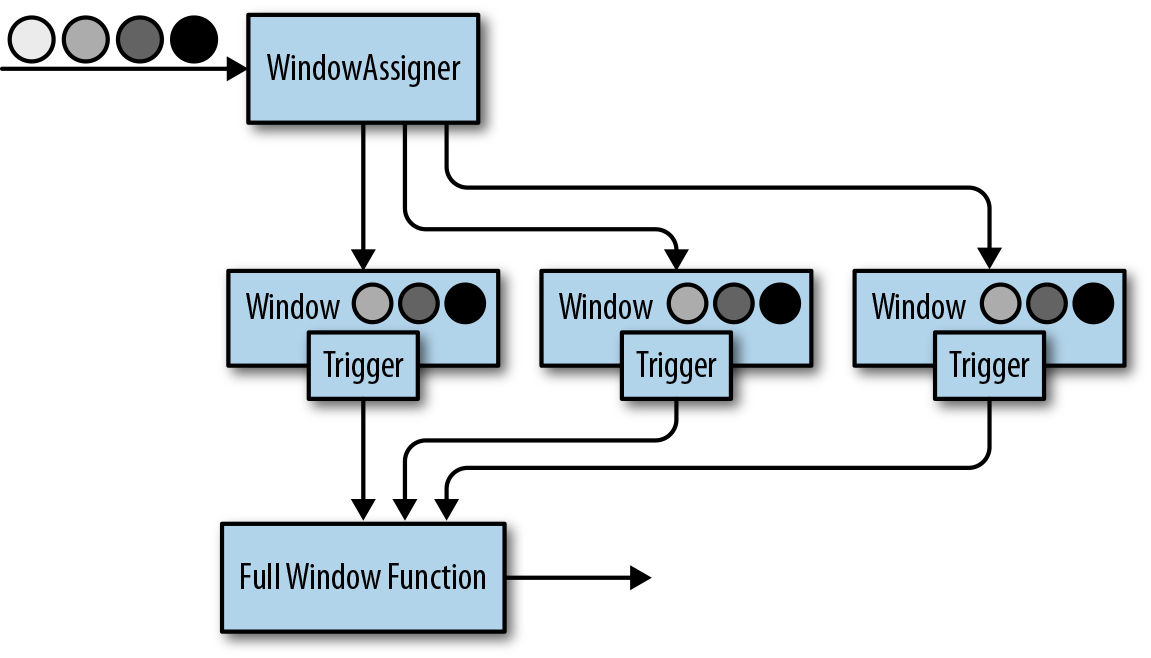
注:代码里是 TumblingWindow,因此 1 条数据只归属到 1 个窗口
包含了:生成时间戳/水位线、WindowAssigner、Trigger、Evictor、Process. 通过组合这几部分,我们可以实现非常复杂的窗口及计算,flink 也内置了一些定制化的实现,在使用以及参考源码上都很有价值。
现在将这几部分拆解看看。
2.2. TimeDomains and Watermark
数据处理的时间分为 EventTime 和 ProcessTime,后面我们会看到这两种时间在处理上的区别。
EventTime 有两个生成的时机:数据源 或者 处理过程。
SourceFunction容易理解,但是实际场景我用的很少(EventTime 跟数据相关,很少跟数据源相关,注意Flink 官方更推荐这种形式,不解)
public interface SourceFunction<T> extends Function, Serializable {
interface SourceContext<T> {
void collectWithTimestamp(T element, long timestamp);
void emitWatermark(Watermark mark);
// ...
}
}
第二种则是在处理过程里,比如上一小节例子里的assignAscendingTimestamps, extractAscendingTimestamp即提取时间戳:
def assignAscendingTimestamps(extractor: T => Long): DataStream[T] = {
val cleanExtractor = clean(extractor)
val extractorFunction = new AscendingTimestampExtractor[T] {
def extractAscendingTimestamp(element: T): Long = {
cleanExtractor(element)
}
}
asScalaStream(stream.assignTimestampsAndWatermarks(extractorFunction))
}
AscendingTimestampExtractor则内置了 watermark 的生成策略:
@Deprecated
@PublicEvolving
public abstract class AscendingTimestampExtractor<T> implements AssignerWithPeriodicWatermarks<T> {
@Override
public final long extractTimestamp(T element, long elementPrevTimestamp) {
final long newTimestamp = extractAscendingTimestamp(element);
if (newTimestamp >= this.currentTimestamp) {
this.currentTimestamp = newTimestamp;
return newTimestamp;
} else {
violationHandler.handleViolation(newTimestamp, this.currentTimestamp);
return newTimestamp;
}
}
@Override
public final Watermark getCurrentWatermark() {
return new Watermark(
currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - 1);
}
}
可以看到:由于是递增的时间戳,所以当前的水位线,可以定义为最近的事件时间(ms)-1
Flink 实现了常用的WatermarkStrategy.forMonotonousTimestamps和WatermarkStrategy.forBoundedOutOfOrderness,分别用于时间单调递增以及最大延迟时间这两种情况。内置的实现或者接口,不同版本变化较大,但是本质上都是做两件事: 为数据生成时间戳以及在合适的时机生成 watermark
2.3. WindowAssigner
例子里的TumblingEventTimeWindows即是一种WindowAssigner,重点关注assignWindows方法的实现,返回指定了起始时间的单个窗口:
public class TumblingEventTimeWindows extends WindowAssigner<Object, TimeWindow> {
private static final long serialVersionUID = 1L;
private final long size;
private final long globalOffset;
private Long staggerOffset = null;
private final WindowStagger windowStagger;
protected TumblingEventTimeWindows(long size, long offset, WindowStagger windowStagger) {
if (Math.abs(offset) >= size) {
throw new IllegalArgumentException(
"TumblingEventTimeWindows parameters must satisfy abs(offset) < size");
}
this.size = size;
this.globalOffset = offset;
this.windowStagger = windowStagger;
}
@Override
public Collection<TimeWindow> assignWindows(
Object element, long timestamp, WindowAssignerContext context) {
if (timestamp > Long.MIN_VALUE) {
if (staggerOffset == null) {
staggerOffset =
windowStagger.getStaggerOffset(context.getCurrentProcessingTime(), size);
}
// Long.MIN_VALUE is currently assigned when no timestamp is present
long start =
TimeWindow.getWindowStartWithOffset(
timestamp, (globalOffset + staggerOffset) % size, size);
return Collections.singletonList(new TimeWindow(start, start + size));
} else {
throw new RuntimeException(
"Record has Long.MIN_VALUE timestamp (= no timestamp marker). "
+ "Is the time characteristic set to 'ProcessingTime', or did you forget to call "
+ "'DataStream.assignTimestampsAndWatermarks(...)'?");
}
}
@Override
public Trigger<Object, TimeWindow> getDefaultTrigger(StreamExecutionEnvironment env) {
return EventTimeTrigger.create();
}
}
如果想要了解前面提到的mergeWindows,可以查看EventTimeSessionWindows.withGap/withDynamicGap ProcessingTimeSessionWindows.withGap/withDynamicGap的源码。
2.4. Trigger
例子里没有指定 trigger,因此实际用到的是 default 的实现:
public WindowedStream(KeyedStream<T, K> input, WindowAssigner<? super T, W> windowAssigner) {
this.input = input;
this.builder =
new WindowOperatorBuilder<>(
windowAssigner,
windowAssigner.getDefaultTrigger(input.getExecutionEnvironment()),
input.getExecutionConfig(),
input.getType(),
input.getKeySelector(),
input.getKeyType());
}
windowAssigner即上一小节的TumblingEventTimeWindows,getDefaultTrigger的实现也已经给出,即返回了EventTimeTrigger(windowAssigner 和 trigger 是解耦的,EventTimeSessionWindows也使用的该 trigger)。
EventTimeTrigger的实现,重点关注:
onElement: 窗口每新增一条数据调用,返回结果有 FIRE, CONTINUE, PURGE, FIRE_AND_PURGE,这里如果超过了窗口,则返回 FIRE,否则注册 eventtimer,返回 CONTINUE,注册的时间为窗口的结束时间onEventTime: 注册的时间服务回调函数clear: 清理回调
public class EventTimeTrigger extends Trigger<Object, TimeWindow> {
private static final long serialVersionUID = 1L;
private EventTimeTrigger() {}
@Override
public TriggerResult onElement(
Object element, long timestamp, TimeWindow window, TriggerContext ctx)
throws Exception {
if (window.maxTimestamp() <= ctx.getCurrentWatermark()) {
// if the watermark is already past the window fire immediately
return TriggerResult.FIRE;
} else {
ctx.registerEventTimeTimer(window.maxTimestamp());
return TriggerResult.CONTINUE;
}
}
@Override
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) {
return time == window.maxTimestamp() ? TriggerResult.FIRE : TriggerResult.CONTINUE;
}
@Override
public void clear(TimeWindow window, TriggerContext ctx) throws Exception {
ctx.deleteEventTimeTimer(window.maxTimestamp());
}
}
之前最开始看到的时候,对官网解释的 FIRE, PURGE 非常不解,比如上述代码实现没有 PURGE,难道数据就不清理了?实际不是这样,当窗口周期结束后,也会清理数据。
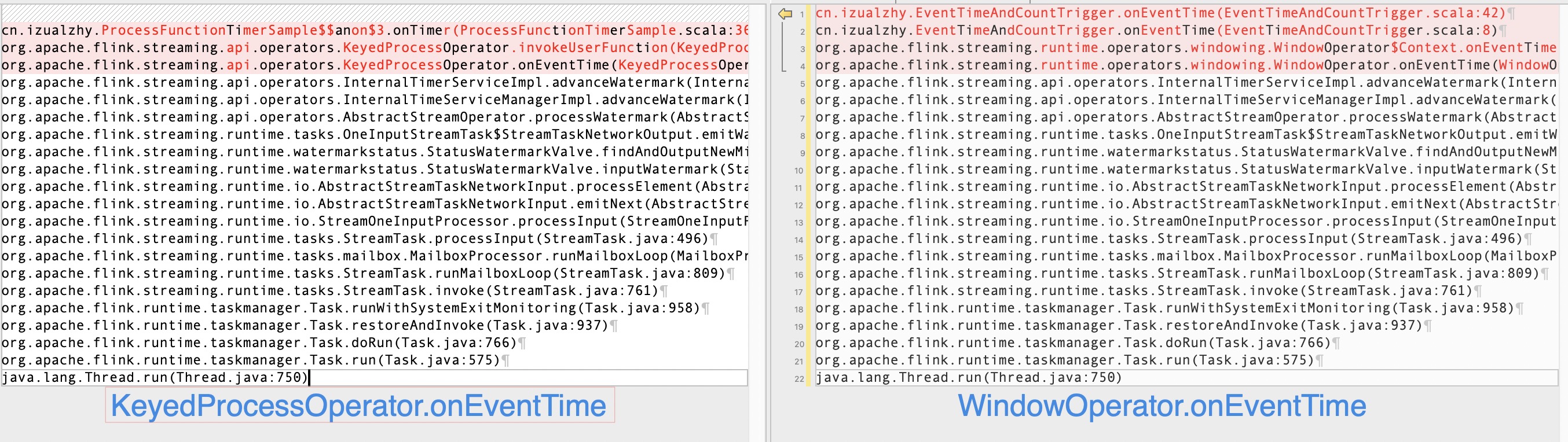
我们也可以自定义实现同时根据 key 的个数或者 EventTime 触发的窗口,来观察其调用栈及枚举值的含义(完整例子):
class EventTimeAndCountTrigger(maxCount: Long = 3) extends Trigger[Any, TimeWindow] {
val logger: Logger = LoggerFactory.getLogger(this.getClass)
val curCountDescriptor = new ReducingStateDescriptor[Long]("counter", (a, b) => a + b , classOf[Long])
override def onElement(t: Any, l: Long, w: TimeWindow, triggerContext: Trigger.TriggerContext): TriggerResult = {
val curCount = triggerContext.getPartitionedState(curCountDescriptor)
curCount.add(1L)
val result = if (curCount.get() >= maxCount || w.maxTimestamp <= triggerContext.getCurrentWatermark) {
curCount.clear()
// 比如窗口时间周期内,提前因为达到 maxCount 触发
// FIRE: maxCount 触发窗口内已经收到的数据参与计算;之后到达 maxTimestamp,这些数据仍然会计算一次
// FIRE_AND_PURGE: maxCount 触发窗口内已经收到的数据参与计算;之后到达 maxTimestamp,这些数据不会再计算一次了
// TriggerResult.FIRE
TriggerResult.FIRE_AND_PURGE
} else {
triggerContext.registerEventTimeTimer(w.maxTimestamp)
TriggerResult.CONTINUE
}
logger.info(s"onElement t:${t} l:${l} w:${w} ${Integer.toHexString(System.identityHashCode(w))} result:${result}")
result
}
override def onProcessingTime(l: Long, w: TimeWindow, triggerContext: Trigger.TriggerContext): TriggerResult = {
logger.info(s"onProcessingTime l:${l} w:${w} ${Integer.toHexString(System.identityHashCode(w))}")
TriggerResult.CONTINUE
}
override def onEventTime(l: Long, w: TimeWindow, triggerContext: Trigger.TriggerContext): TriggerResult = {
val stack = Thread.currentThread().getStackTrace.map(_.toString)
.mkString("\n\t")
logger.info(s"stack:\n${stack}")
val result = if (l == w.maxTimestamp) TriggerResult.FIRE
else TriggerResult.CONTINUE
logger.info(s"onEventTime l:${l} w:${w} ${Integer.toHexString(System.identityHashCode(w))} result:${result}")
result
}
override def clear(w: TimeWindow, triggerContext: Trigger.TriggerContext): Unit = {
logger.info(s"clear w:${w} ${Integer.toHexString(System.identityHashCode(w))}")
triggerContext.deleteEventTimeTimer(w.maxTimestamp)
triggerContext.getPartitionedState(curCountDescriptor).clear()
}
}
比如KeyedStream.countWindow的 Trigger 就用 FIRE_AND_PURGE 以清理数据:
class KeyedStream
public WindowedStream<T, KEY, GlobalWindow> countWindow(long size) {
return window(GlobalWindows.create()).trigger(PurgingTrigger.of(CountTrigger.of(size)));
}
onElement onProcessingTime onEventTime 对应窗口不同的触发模式,可以组合按照事件时间、处理时间、数据本身等各种维度触发窗口。
2.5. Evictor
Evictor 是 flink 单独实现的,用于窗口前、后的数据清理。
不过注意,作用在窗口上的 reduce/sum/min 这类方法,flink 做了优化:只存储聚合数据而不是全部原始数据:
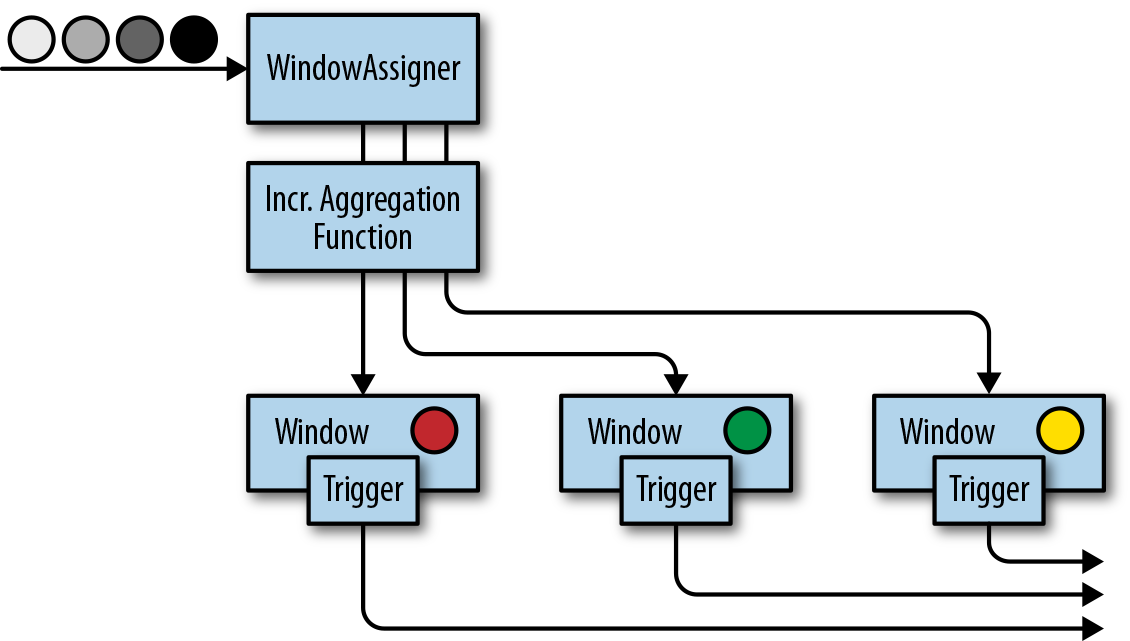
而 Evictor 在语义上需要保留全部数据,因此注意状态过大的问题。
2.6. ReduceFunction/AggregateFunction/ProcessWindowFunction
窗口的结果可以交给这几种函数处理:
- ReduceFunction/AggregateFunction: 只存储和输出聚合结果,每条数据到达后都触发方法计算
- ProcessWindowFunction: 存储全部数据,窗口 trigger 后触发方法计算,传入窗口内的全部数据,同时支持获取窗口的元信息
也可以组合 1 2,这样能够聚合的同时获取窗口元信息,例如:
.reduce(, new ProcessWindowFuncation{...}))
.aggregate(, new ProcessWindowFuncation{...}))
这块实现简单,一些测试用例在Bigdata-Systems,就不多介绍了。
3. Source - WindowOperator
.window方法,对应的底层算子即WindowOperator,flink 实现的调用栈为:
flowchart TB
A("StreamTask.processInput") --> B["StreamOneInputProcessor.processInput"] --> C("AbstractStreamTaskNetworkInput.emitNext") --> D(" AbstractStreamTaskNetworkInput.processElement")
D --> E("OneInputStreamTask$StreamTaskNetworkOutput.emitRecord") --> F("WindowOperator.processElement")
处理数据的入口,是在 WindowOperator.processElement
class WindowOperator {
private transient InternalAppendingState<K, W, IN, ACC, ACC> windowState;
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
// 数据交给 windowAssigner , 返回所属的 N 个 window
final Collection<W> elementWindows =
windowAssigner.assignWindows(
element.getValue(), element.getTimestamp(), windowAssignerContext);
// if element is handled by none of assigned elementWindows
boolean isSkippedElement = true;
// 当前的 key,即 keyBy 指定的分区 key
final K key = this.<K>getKeyedStateBackend().getCurrentKey();
logger.info("YING element:{} getCurrentKey:{}", element, key);
// Merge窗口的处理,注意是否 MergingWindowAssigner 和 elementWindows 个数没有必然关系
if (windowAssigner instanceof MergingWindowAssigner) {
// 获取 merge 后的大 window
W stateWindow = mergingWindows.getStateWindow(actualWindow);
// 之后的处理跟 else 逻辑很像
} else {
for (W window : elementWindows) {
// 指定 windowState 的 nm,添加数据;这样每个 window(包含了key) 都有单独的 windowState
windowState.setCurrentNamespace(window);
windowState.add(element.getValue());
triggerContext.key = key;
triggerContext.window = window;
// 调用 trigger,根据返回结果判断是否触发计算
TriggerResult triggerResult = triggerContext.onElement(element);
if (triggerResult.isFire()) {
ACC contents = windowState.get();
if (contents == null) {
continue;
}
// 处理窗口内数据
emitWindowContents(window, contents);
}
if (triggerResult.isPurge()) {
windowState.clear();
}
registerCleanupTimer(window);
}
}
// ...
}
public void onEventTime(InternalTimer<K, W> timer) throws Exception {
// ...
// 调用内置 or 自定义的 trigger.onEventTime,根据返回结果判断是否触发计算
TriggerResult triggerResult = triggerContext.onEventTime(timer.getTimestamp());
if (triggerResult.isFire()) {
ACC contents = windowState.get();
if (contents != null) {
emitWindowContents(triggerContext.window, contents);
}
}
// ...
}
public void onProcessingTime(InternalTimer<K, W> timer) throws Exception {
// ...
// 调用内置 or 自定义的 trigger.onProcessingTime,根据返回结果判断是否触发计算
TriggerResult triggerResult = triggerContext.onProcessingTime(timer.getTimestamp());
if (triggerResult.isFire()) {
ACC contents = windowState.get();
if (contents != null) {
emitWindowContents(triggerContext.window, contents);
}
}
// ...
}
private void emitWindowContents(W window, ACC contents) throws Exception {
timestampedCollector.setAbsoluteTimestamp(window.maxTimestamp());
processContext.window = window;
// 调用用户实现的 ProcessWindowFunction 方法
userFunction.process(
triggerContext.key, window, processContext, contents, timestampedCollector);
}
}
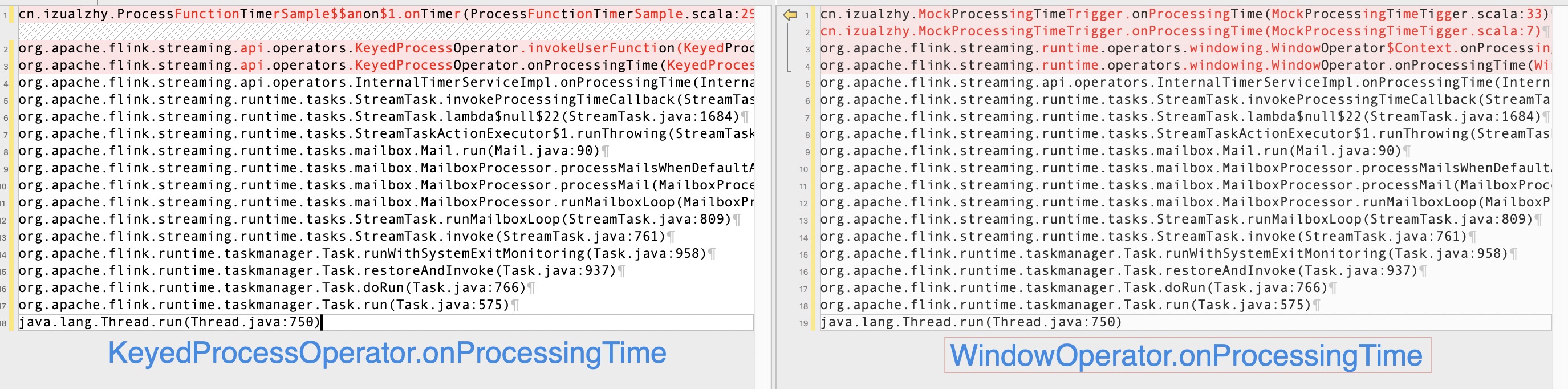
emitWindowContents真正调用用户函数执行计算,入口可能有 3 处:processElement onEventTime onProcessingTime.
其中onEventTime和processElement很像,都是数据触发,入口均在StreamTask.processInput:
flowchart TB
A("StreamTask.processInput") --> B["StreamOneInputProcessor.processInput"] --> C("AbstractStreamTaskNetworkInput.emitNext") --> D(" AbstractStreamTaskNetworkInput.processElement")
D --> E("StatusWatermarkValve.inputWatermark") --> F("StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels") --> G("OneInputStreamTask$StreamTaskNetworkOutput.emitWatermark") --> H("AbstractStreamOperator.processWatermark") --> I("InternalTimeServiceManagerImpl.advanceWatermark") --> J("InternalTimerServiceImpl.advanceWatermark") --> K("WindowOperator.onEventTime") --> L("WindowOperator$Context.onEventTime")
onProcessingTime略有不同,因为不是靠数据触发的,所以需要单独线程ScheduledThreadPoolExecutor触发,具体实现在 SystemProcessingTimeService.
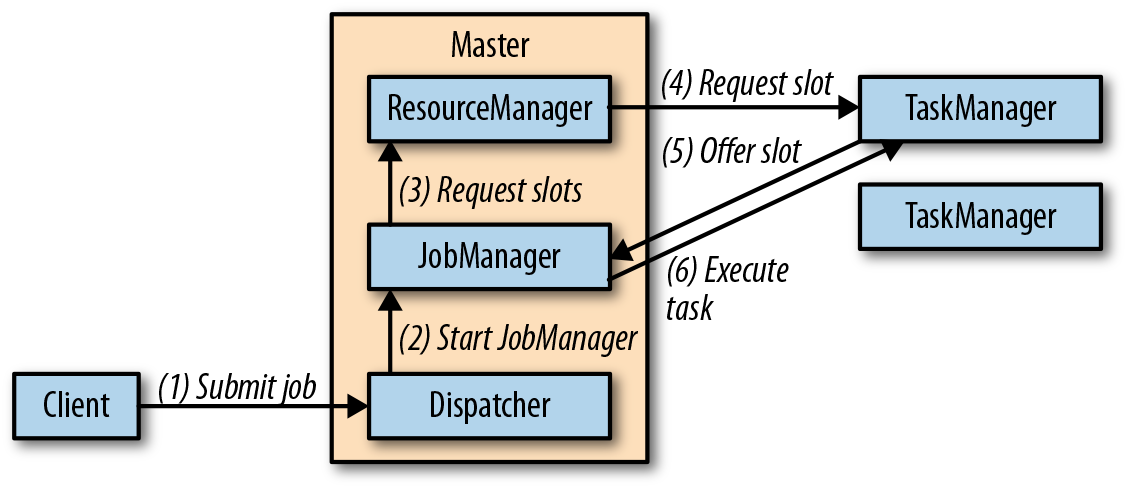
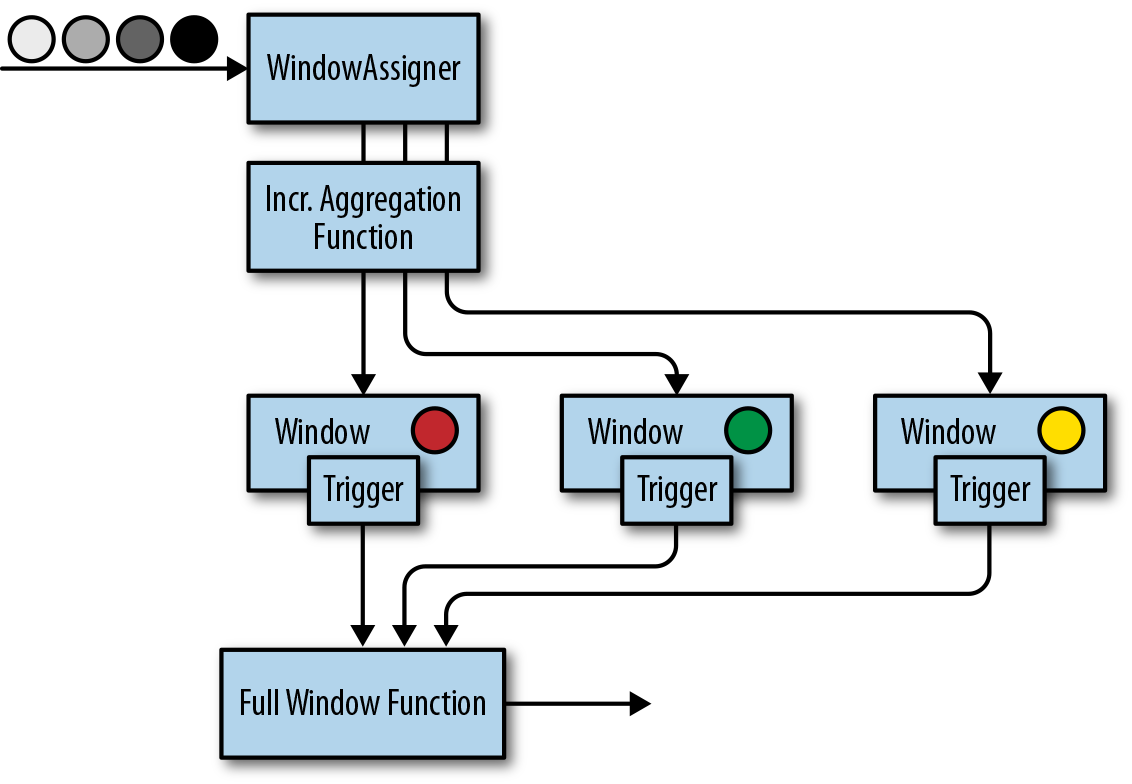
这段代码也对应到了 2.1 小节图片里的流程。
此外还可以总结到几点:
- window 存储了元数据,数据本身存储在 state, state 还存储了 key、keyGroupRange、serializer 等
- 收到的一条数据,如果分配到了多个窗口,那么数据也是 copy 的;因此,比如 size=1day,slide=1second 的滑动窗口,会导致状态很大(1 条数据被存储了 86400 次)
4. Timer
前面介绍了 Window,结尾还想再说一说 Timer.
ProcessFunction里引入了Timer,比如对于KeyedProcessFunction:
- 可以通过 ctx.timerService 获取 TimerService,然后注册 time(event/process),获取处理时间,watermark 等等
- 可以实现 onTimer 方法,在 time 触发后调用该方法
- processElement和onTimer方法不会被同时调用,因此不需要担心同步问题。但这也意味着处理onTimer逻辑是会阻塞处理数据的。
因此 KeyedProcessFunction 也可以实现窗口效果,例如对一段时间内的每个 key 的值求和:
object UseTimerAsWindowApp extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val sourceStream = SourceUtils.generateLocalSensorReadingStream(env)
.assignAscendingTimestamps(r => r.eventTime)
useTimerAsWindow(sourceStream)
env.execute("UseTimerAsWindowApp")
private def useTimerAsWindow(sourceStream: DataStream[SensorReading]): Unit = {
sourceStream.keyBy(_.id)
.process(new OneMinuteWindowProcessFunction)
}
private class OneMinuteWindowProcessFunction extends KeyedProcessFunction[String, SensorReading, String] {
val logger = LoggerFactory.getLogger(classOf[OneMinuteWindowProcessFunction])
private lazy val sumState = getRuntimeContext.getState(new ValueStateDescriptor[Double]("sum", classOf[Double]))
override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, String]#Context, out: Collector[String]): Unit = {
logger.info(s"processElement: ${value} i: ${value.id} timestamp:${ctx.timestamp()} currentProcessingTime:${ctx.timerService().currentProcessingTime()} currentWatermark:${ctx.timerService().currentWatermark()} getCurrentKey:${ctx.getCurrentKey}")
if (sumState.value() == 0) {
if (value.id.equals("sensor_a")) {
val windowEndTimer: Long = (ctx.timestamp() / 60000L + 1) * 60000L - 1
logger.info(s"register windowEndTimer: $windowEndTimer")
ctx.timerService().registerEventTimeTimer(windowEndTimer)
} else {
val windowEndTimer: Long = (ctx.timestamp() / 120000L + 1) * 120000L - 1
logger.info(s"register windowEndTimer: $windowEndTimer")
ctx.timerService().registerEventTimeTimer(windowEndTimer)
}
sumState.update(value.temperature)
} else {
sumState.update(sumState.value() + value.temperature)
}
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext, out: Collector[String]): Unit = {
logger.info(s"collect getCurrentKey:${ctx.getCurrentKey} sumState.value:${sumState.value()} ctx.timestamp:${ctx.timestamp()} timestamp:${timestamp}")
out.collect(s"${ctx.getCurrentKey} ${sumState.value()}")
sumState.clear()
}
}
}
使用自定义 timer,可以设计出更加灵活的逻辑,比如不同 key 指定不同的统计时间,根据 key 的不同值指定不同时间等。阿里云的DataStream的Timer使用最佳实践里也提到了用于发送无数据的心跳。
不过我觉得云厂商这种文档不够严谨。这个例子恰好呼应了论文里的考量点,没有数据是上游异常还是确实无数据,此时我们是应当尽快发送心跳包触发计算还是继续等待水位线?心跳包应当是数据源发送还是可以在处理函数里发送?都是值得进一步考虑的设计。
5. Summary
Flink 的窗口在设计、语义上都跟 G 家的 The Dataflow Model 一致,实现上则依赖了 Timer,同时窗口机制也和时间、时间类型是解耦的。通过组合窗口的各个阶段,可以组合出复杂的业务逻辑。对于更复杂的场景,则可以使用 timer,不过就需要更加注意 state 的处理了。
]]>



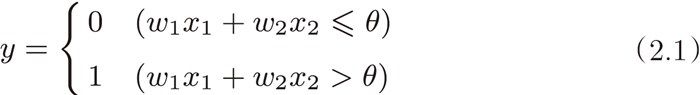

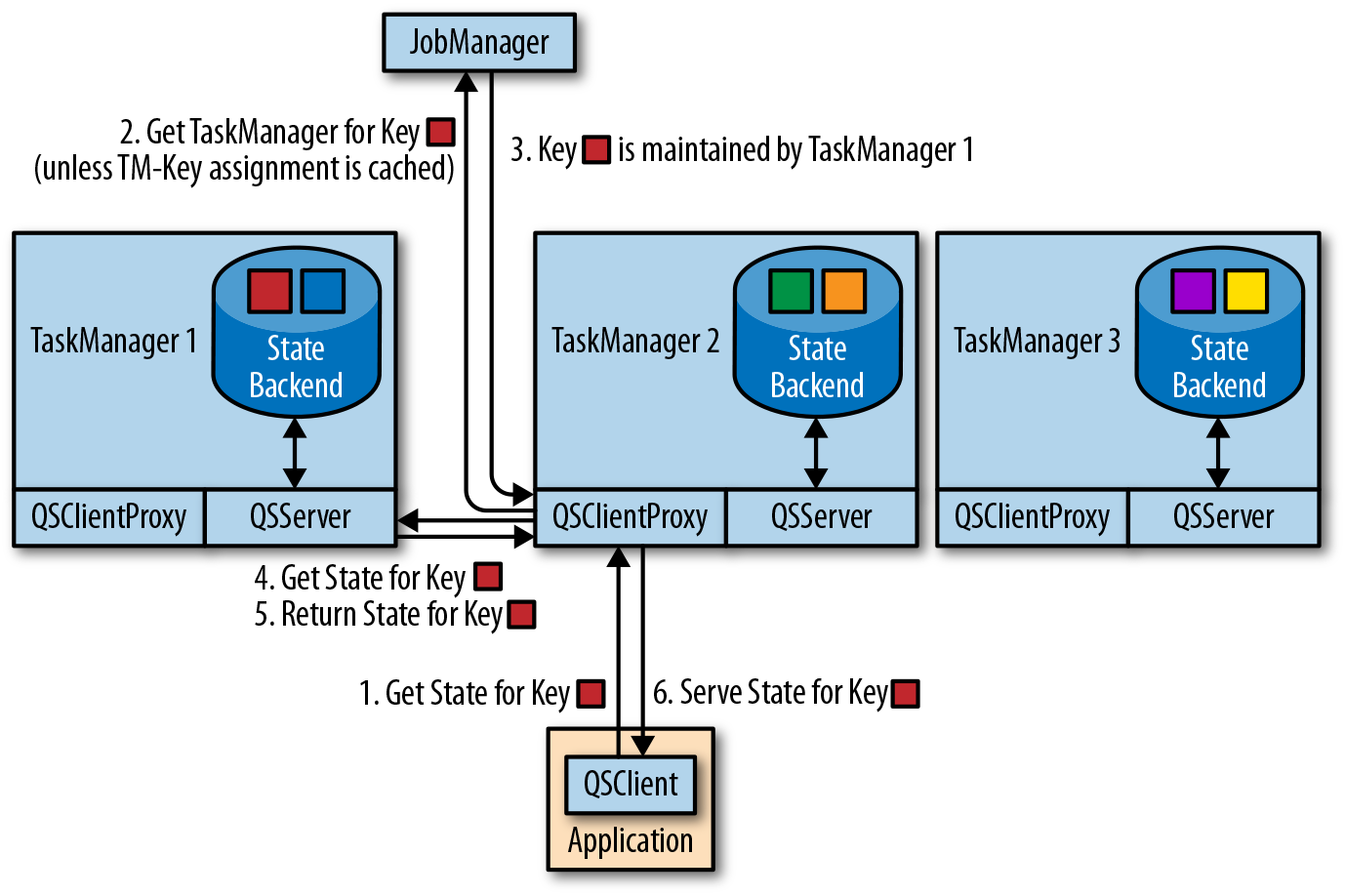 支持 state 的点查和读取,依赖 flink-queryable-state-client-java.
注:之前调研 flink 时,这个功能看上去非常强大,不过目前在官网已经看不到相关文档了。
支持 state 的点查和读取,依赖 flink-queryable-state-client-java.
注:之前调研 flink 时,这个功能看上去非常强大,不过目前在官网已经看不到相关文档了。
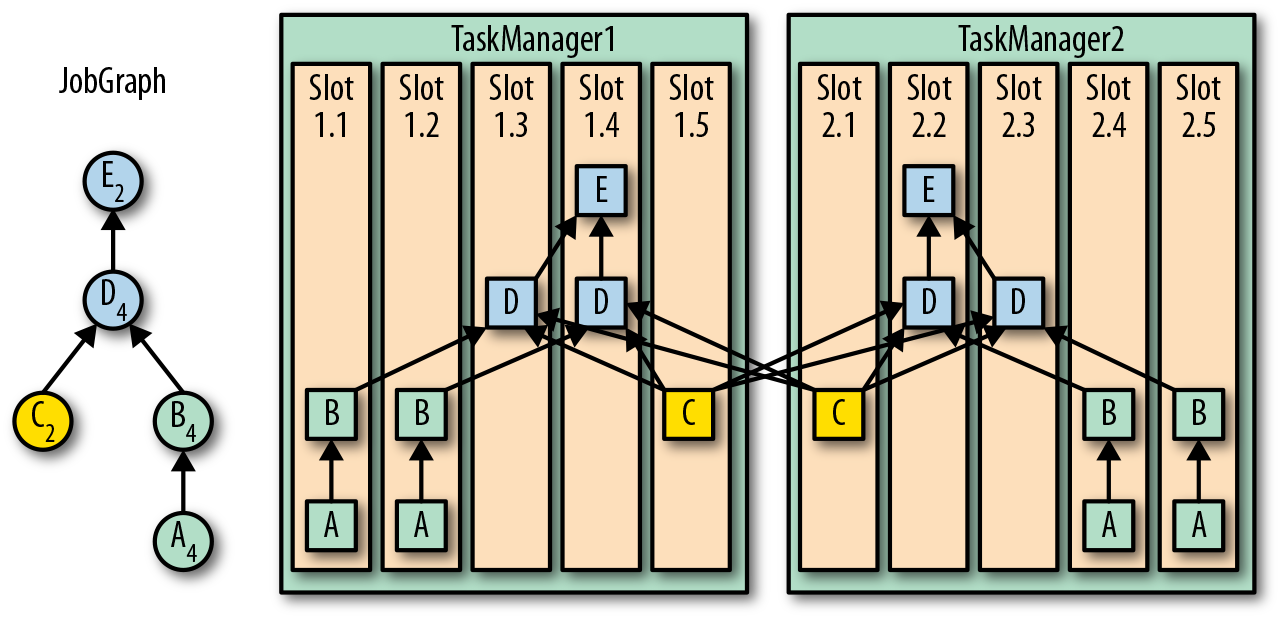
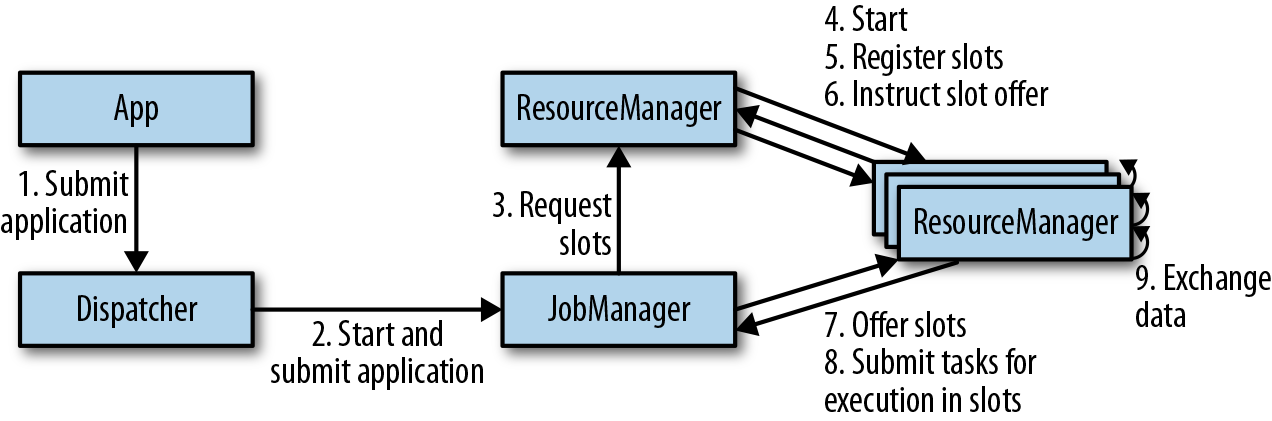
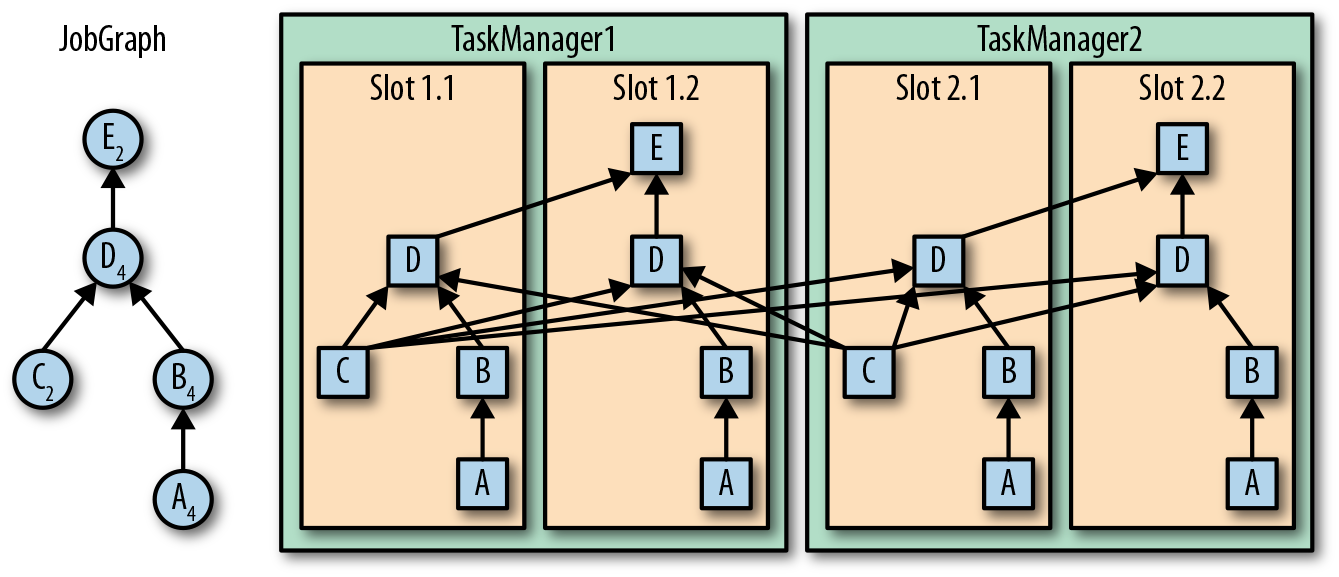
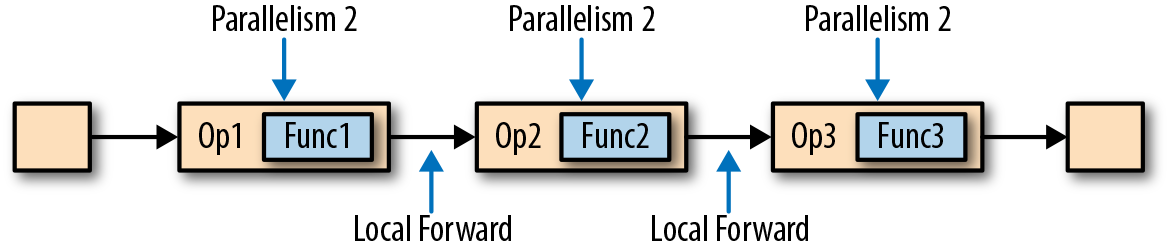
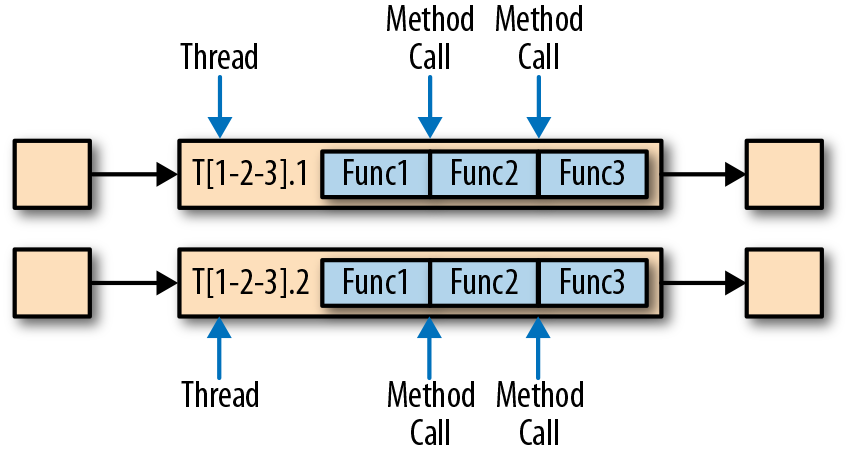
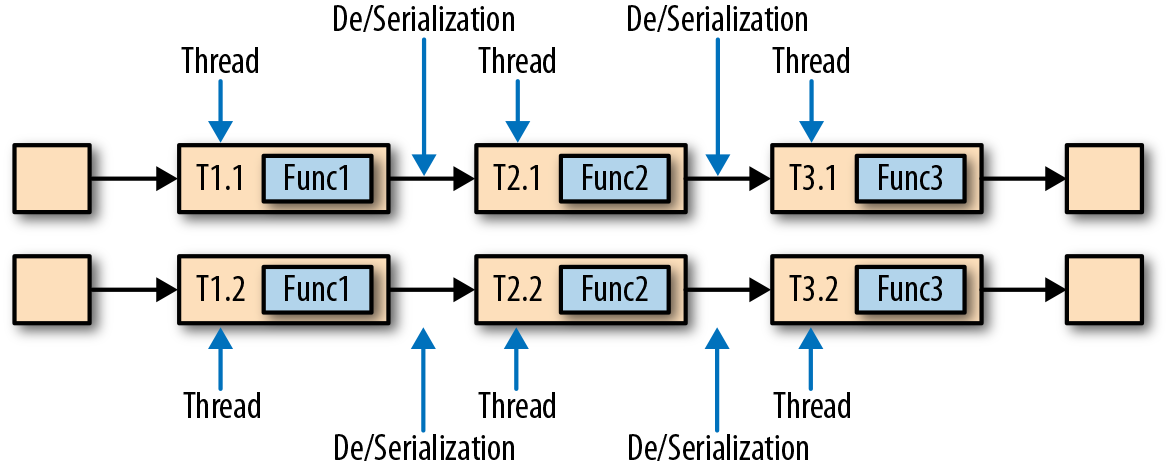
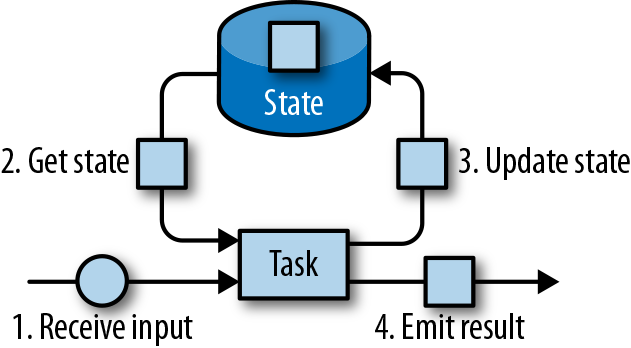
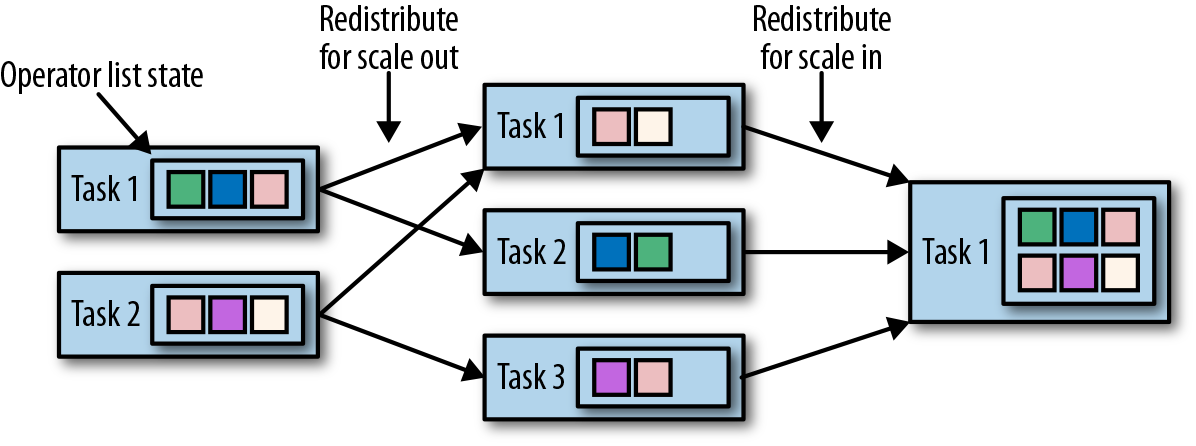
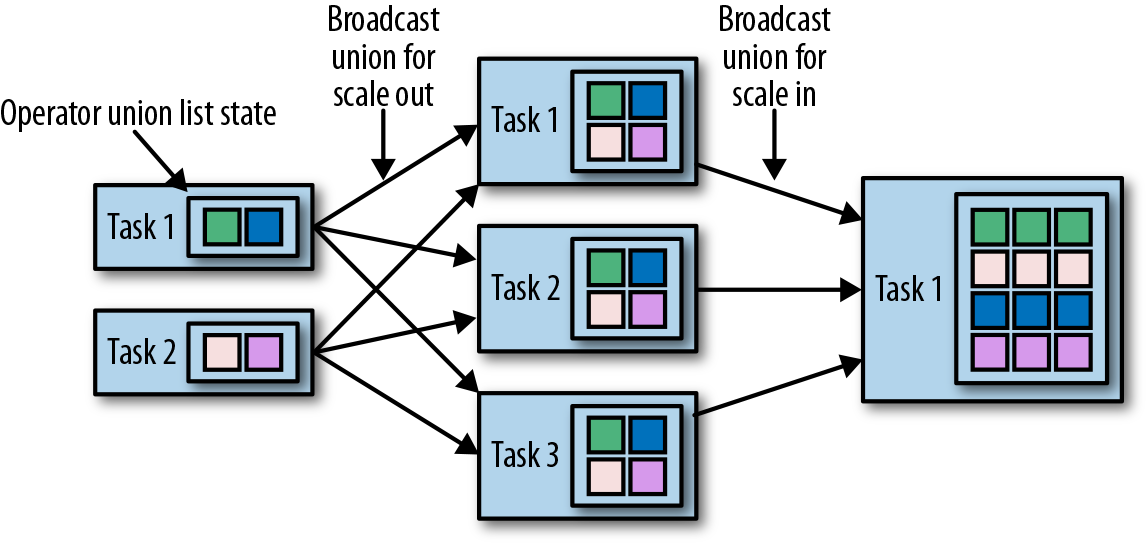
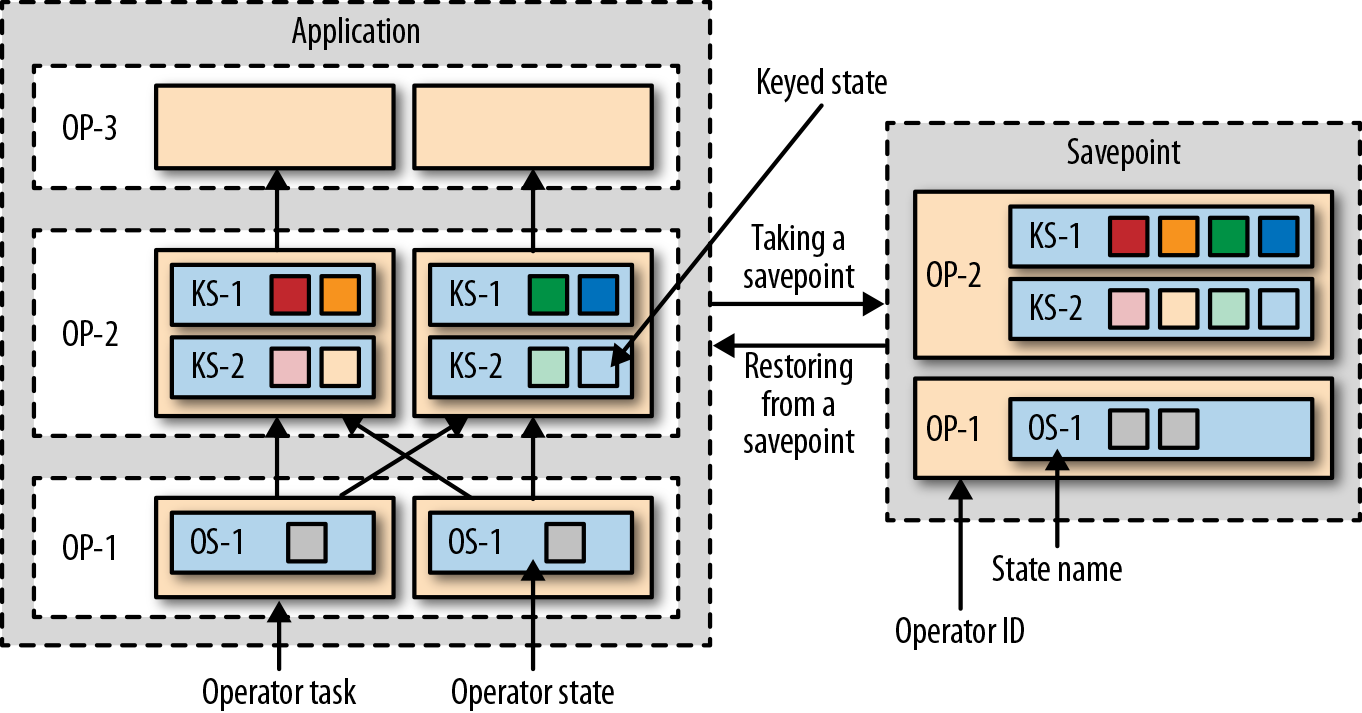
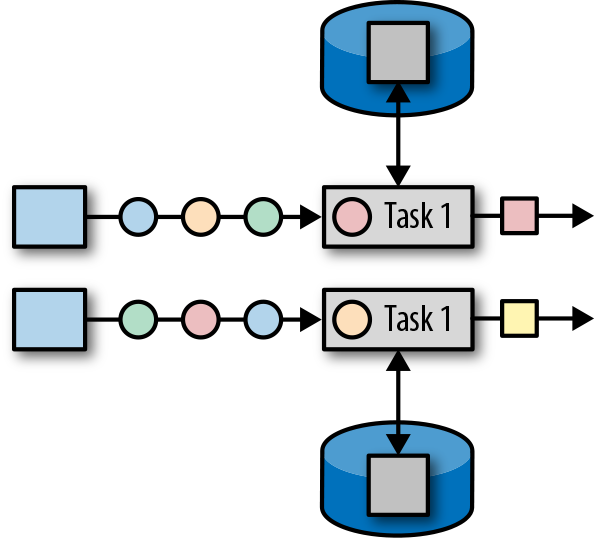 ,有 ListState、UnionListState、BroadcastState
,有 ListState、UnionListState、BroadcastState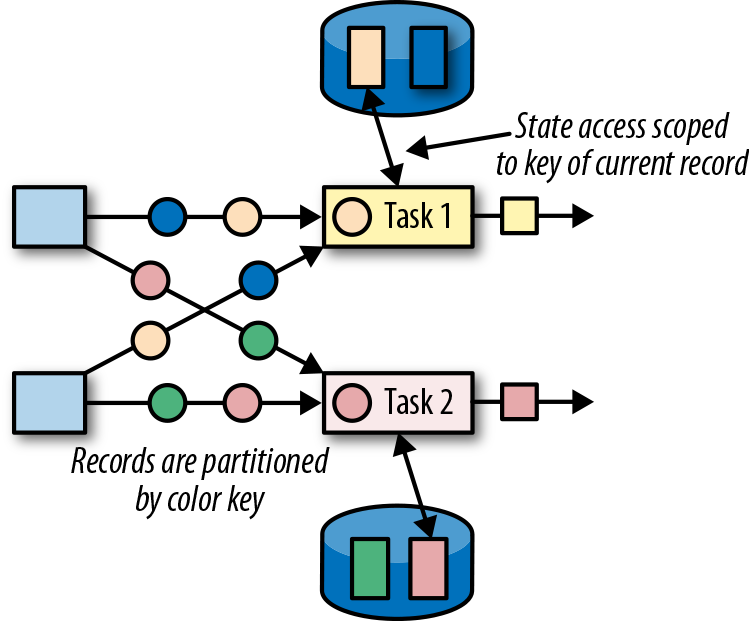 ,有 ValueState、ListState、MapState
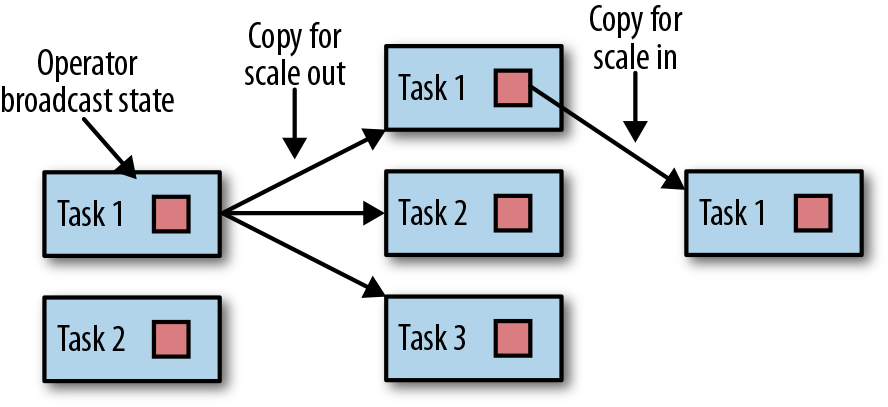
,有 ValueState、ListState、MapState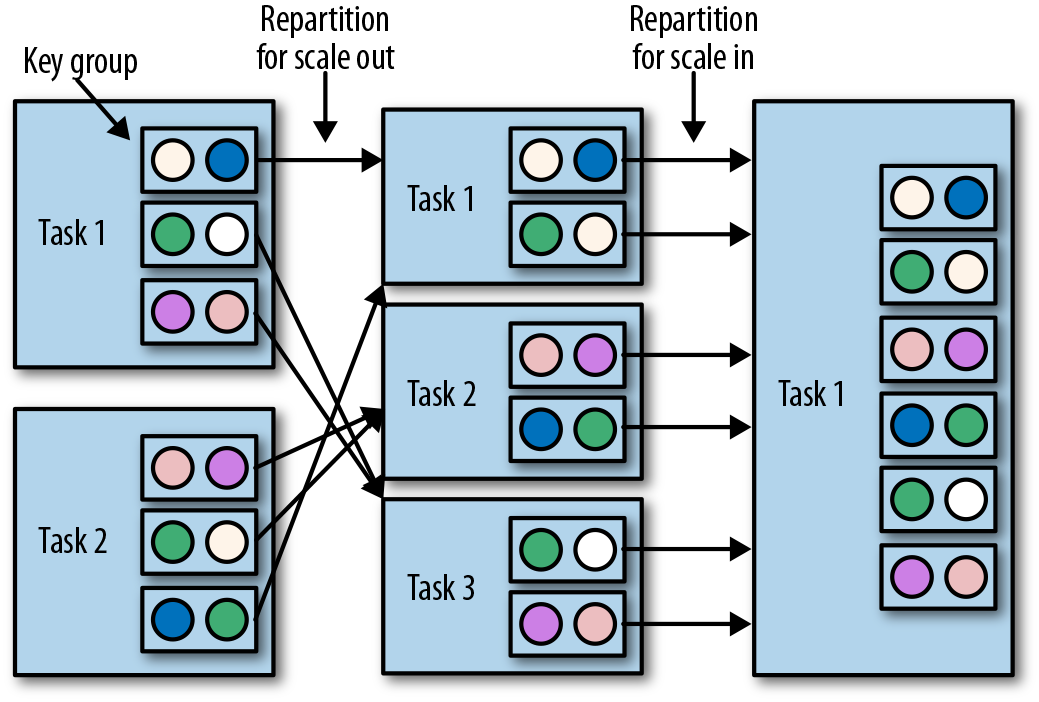 ,scale out、scale in 都按照 key group,而不是 redistribute.
,scale out、scale in 都按照 key group,而不是 redistribute.
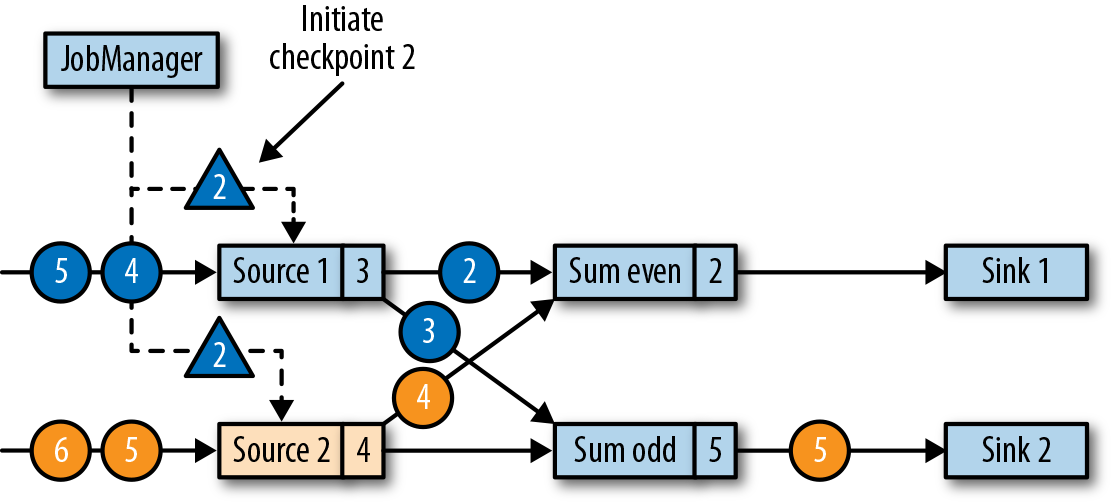
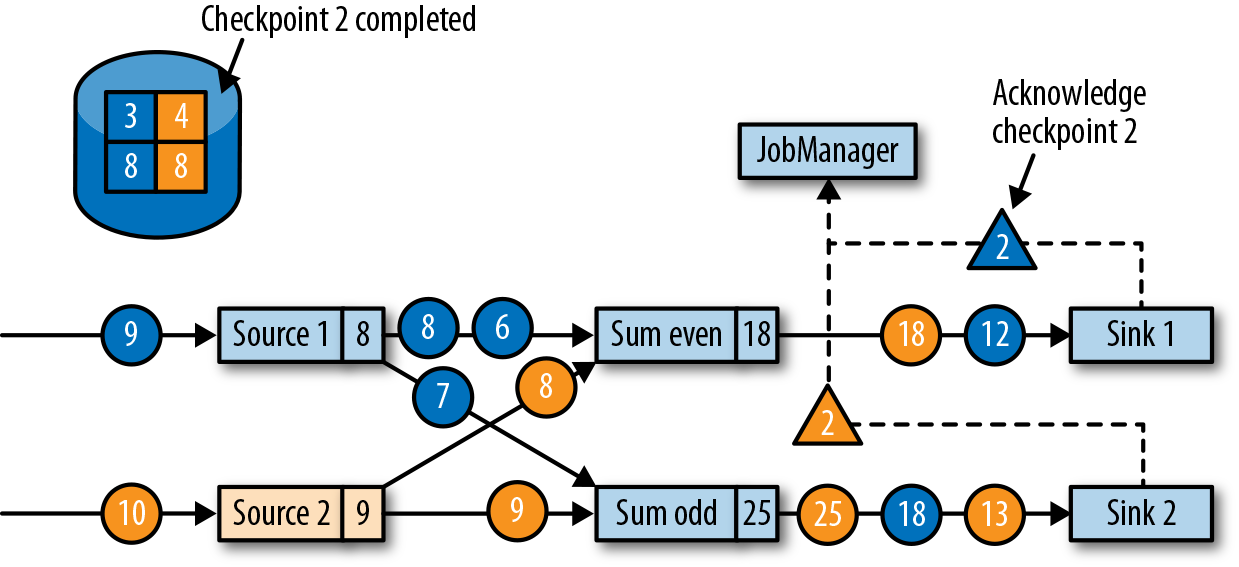
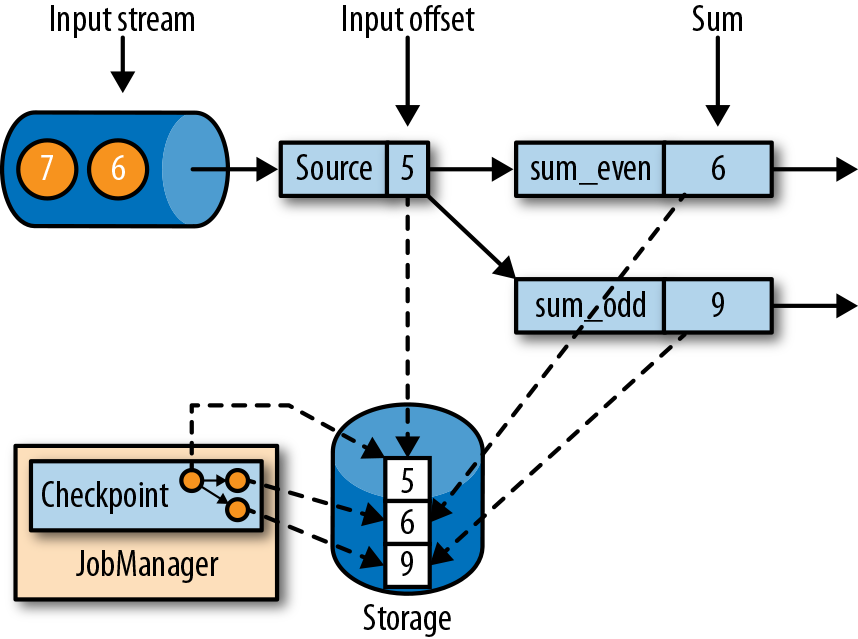 ,Source 产生 1,2,3,… 的数据,在图中的时刻,checkpoint 记录了 Source offset = 5, 而奇数和偶数的 sum 分别为 9 和 6.
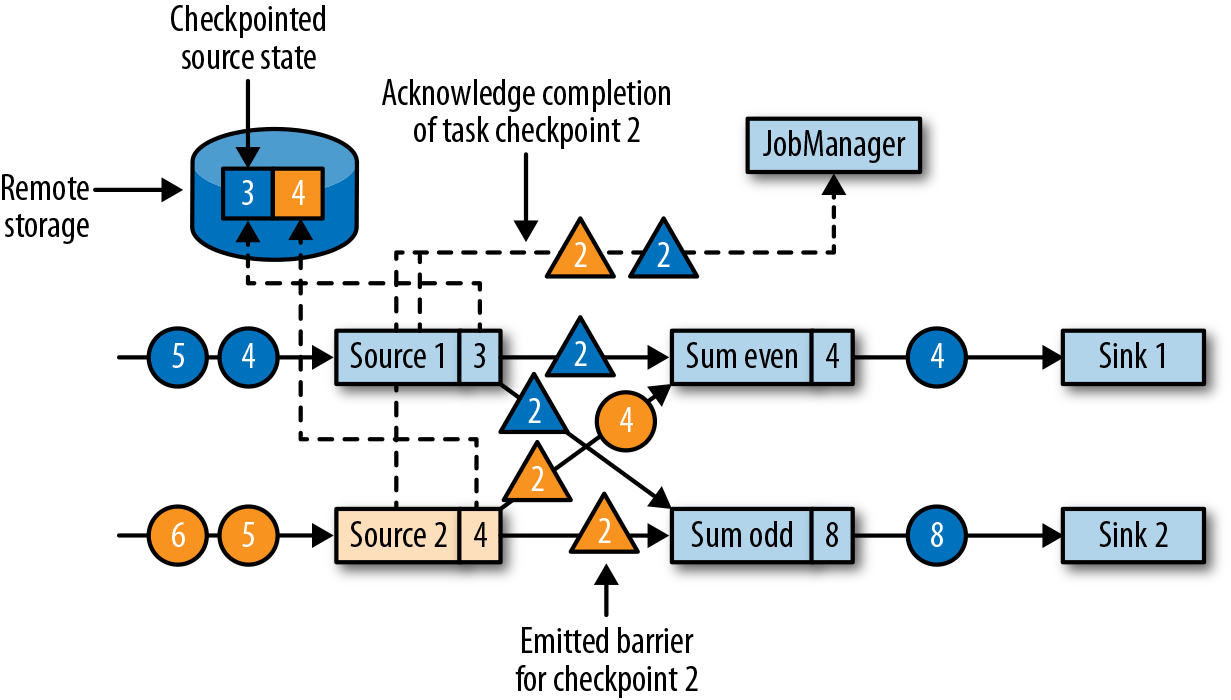
,Source 产生 1,2,3,… 的数据,在图中的时刻,checkpoint 记录了 Source offset = 5, 而奇数和偶数的 sum 分别为 9 和 6.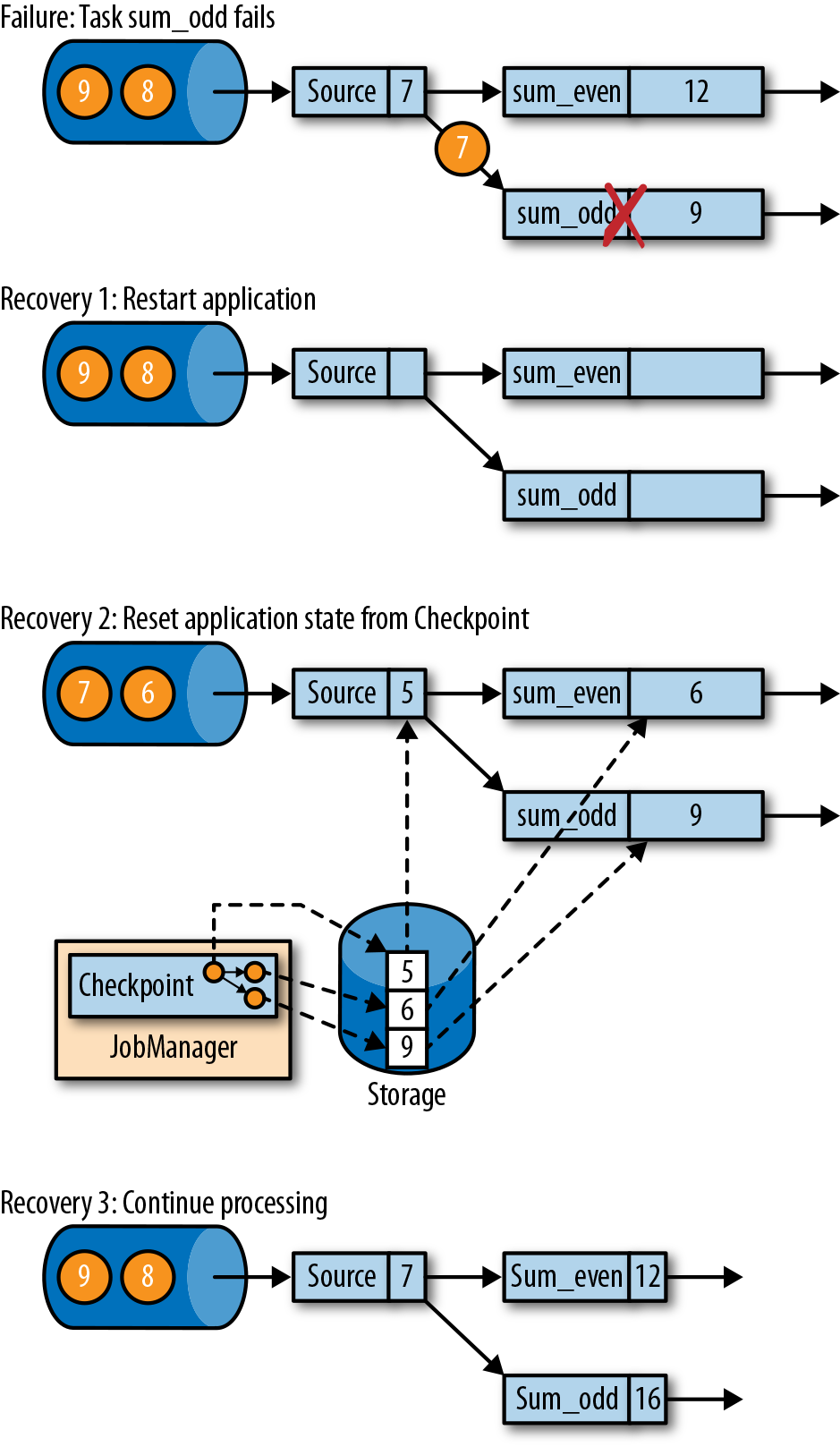 , task 失败从 checkpoint 恢复时,从 5 之后继续消费,数据是正确且一致的。注意 sink operators 可能收到多条。
, task 失败从 checkpoint 恢复时,从 5 之后继续消费,数据是正确且一致的。注意 sink operators 可能收到多条。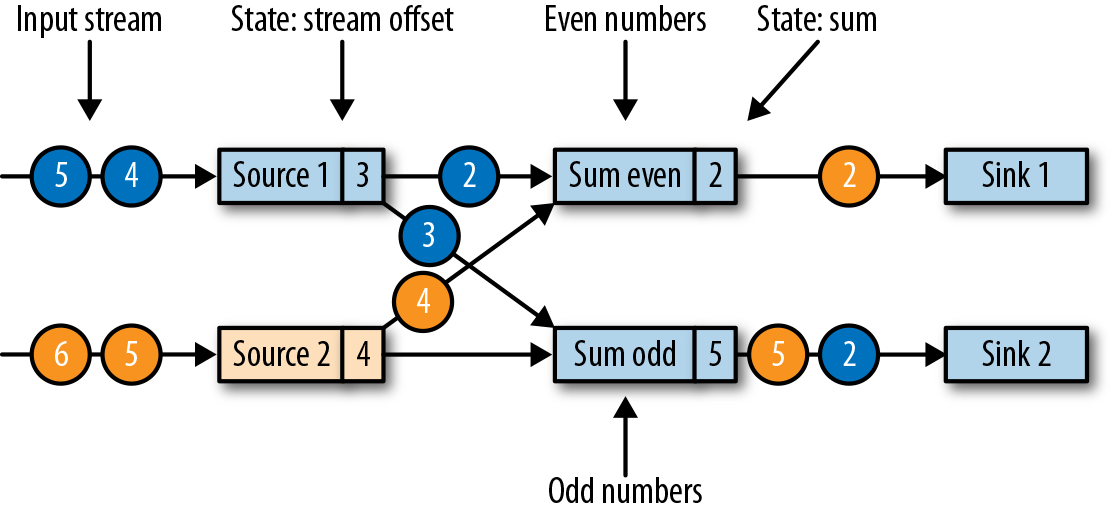
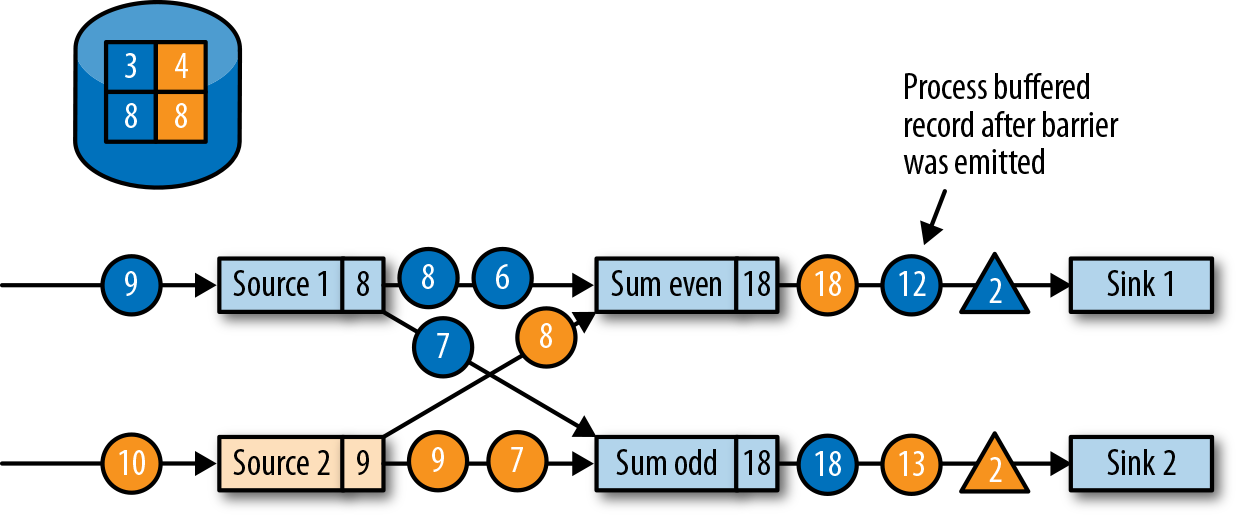
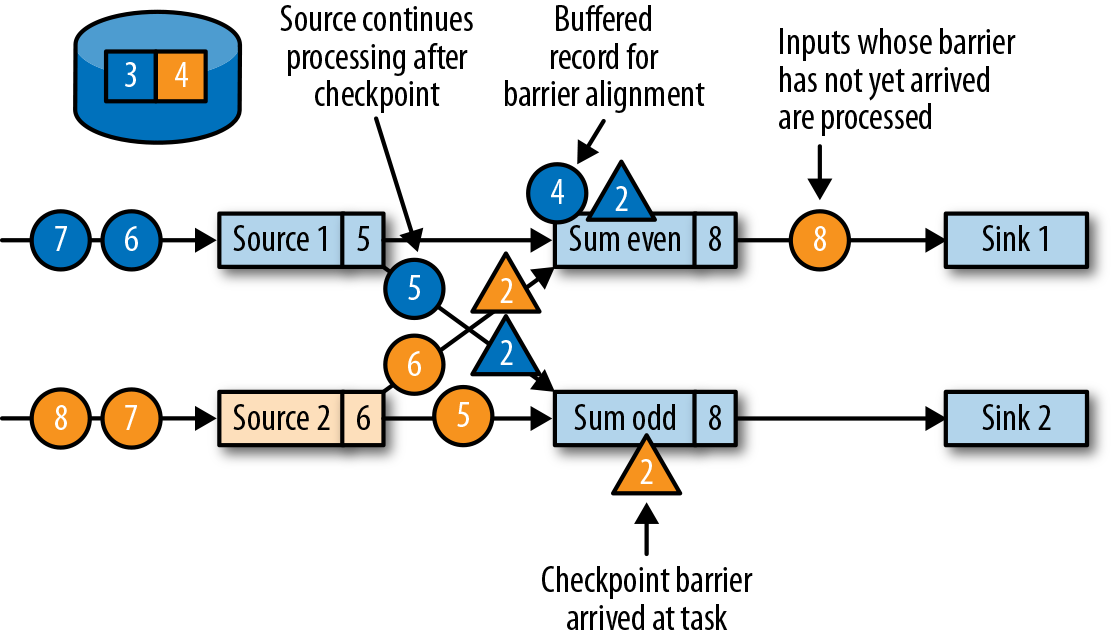 ,此时上游算子仍然在产生数据,当前算子也缓存着晚于 barrier 的数据(例如 Source1 产生的蓝色圆圈4)
,此时上游算子仍然在产生数据,当前算子也缓存着晚于 barrier 的数据(例如 Source1 产生的蓝色圆圈4)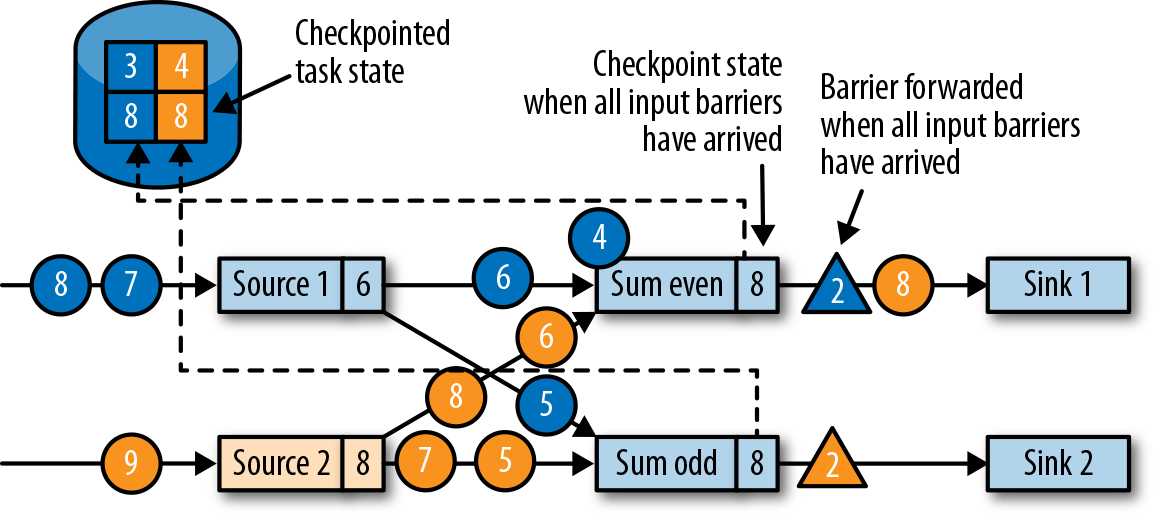
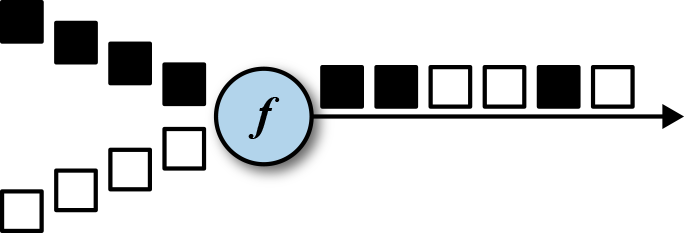
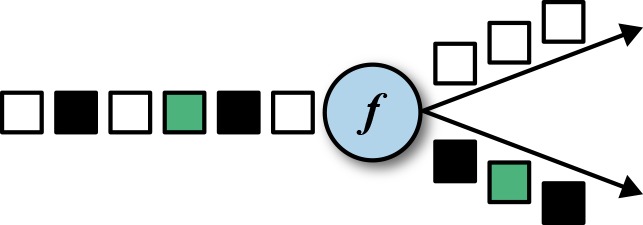 ,返回 SplitStream, 通过 select 方法返回不同的 DataStream
,返回 SplitStream, 通过 select 方法返回不同的 DataStream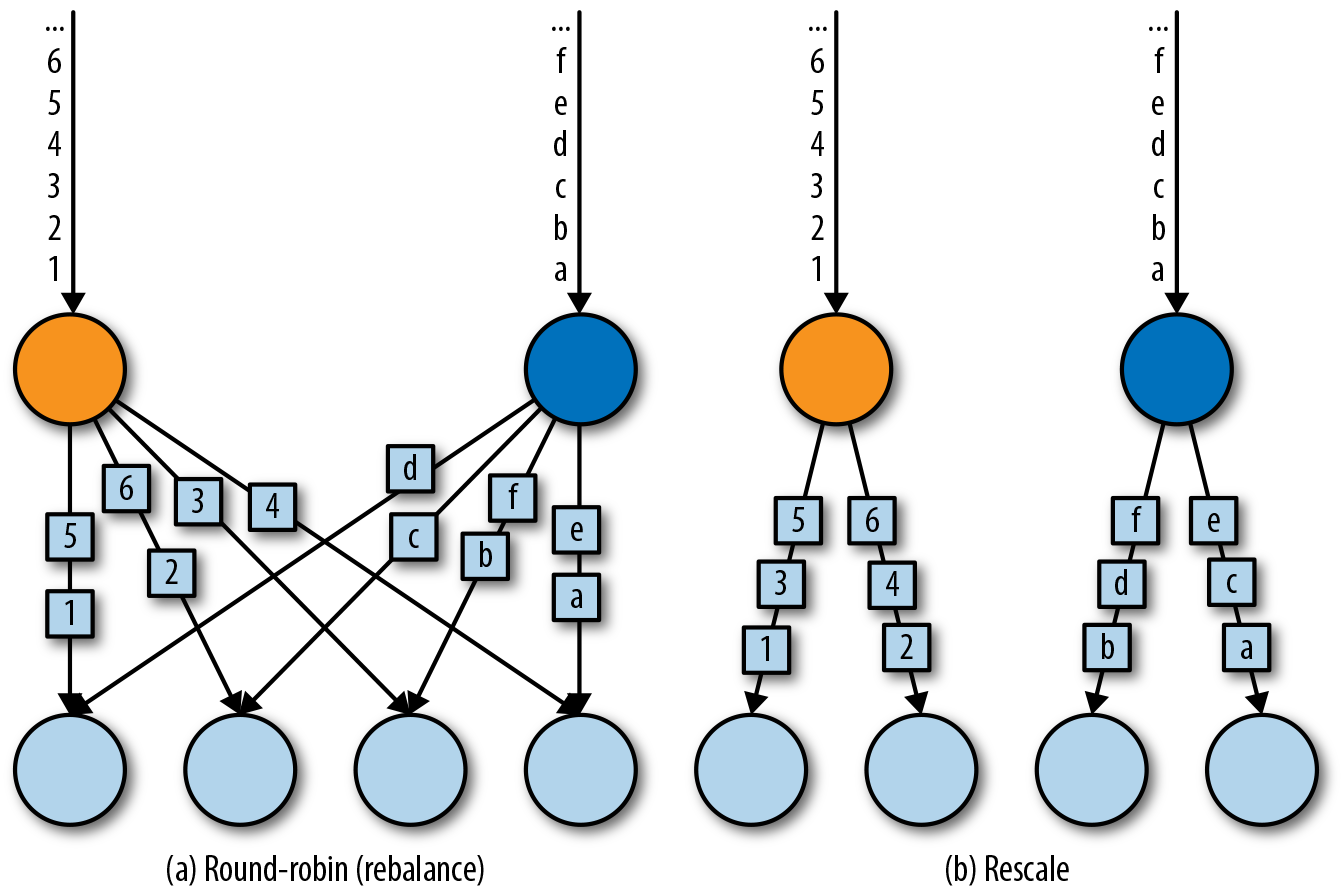 /broadcast/global/partitionCustom(自定义)
/broadcast/global/partitionCustom(自定义)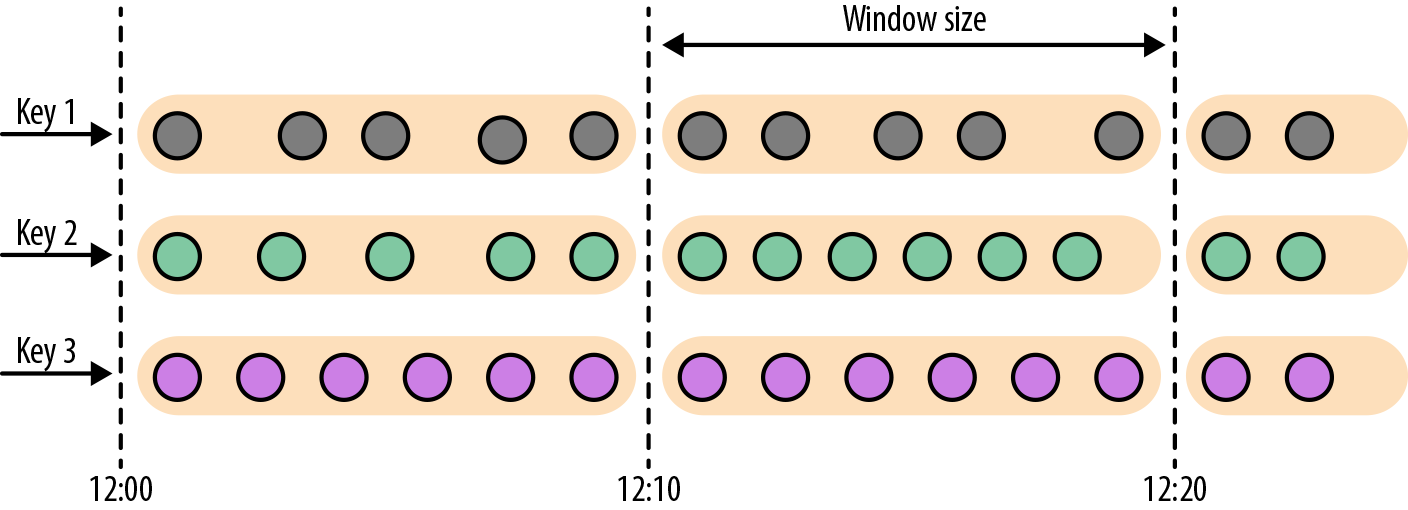 ,
, ,
,  ,
, 
 ){:width=”300”}
){:width=”300”}