1.时间的边界
1.1. T+1
时间分两种,处理时间和事件时间。大部分情况,数据处理都会选择事件时间。
以离线的天级 Hive 表任务为例,我们看看是如何产出 T+1 的数据的。
T+1 00:00 是处理时间,假定 A 表 Tday 的数据在 00:05 完全到达,B 表 T-day 的数据在 01:05 完全到达。
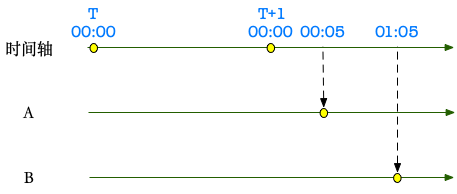
数据完全到达后,开始 merge Tday 的增量数据,然后根据需要生成全量表或者拉链表。可能的时间轴:
- 00:05 -> 00:30: merge A 表 Tday 的增量数据,记录到 A-inc
- 00:30 -> 01:35: merge A-inc + A-base,记录到 A 表 Tday 分区
- 01:05 -> 01:10: merge B 表 Tday 的增量数据,记录到 B-inc
- 01:10 -> 01:50: merge B-inc + B-base,记录到 B 表 Tday 分区
- 01:50: 开始执行 SQL A + B -> C,产出 C 表的 Tday 分区
这里为离线数仓任务的开发建立了一个非常友好的模型:SQL 处理的是需要的全量数据。
基于这个易用且成熟的模型,基础设施上只需要确保两点:
- 如何判断数据是否完全到达?需要考虑生产环境一直没有数据的情况,因此依赖 FileAgent/CDC 的心跳包。整个数据流是保序的,当 T+1 day 的心跳包到达,就可以认为 T day 的数据已经采集完成。
- 如何编排上述任务?依赖于任务调度系统,相比于 K8S jobs、Linux crontab,大数据的任务调度系统,在功能上最强大的两点之一便是编排任务 DAG 的能力。通过任务编排,离线任务简单划分为了依赖检查和任务执行两个阶段。
1.2. Micro Batch
离线是处理1天的数据,微批处理时间间隔更小,比如10分钟。因此面对实时的需求,从离线过渡到微批,似乎更加顺理成章一些。
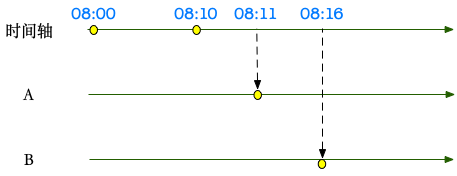
[08:00, 08:10] 区间的数据,A 表在 08:11 完全到达,B 表在 08:16 完全到达。如果完全复用离线处理的思路:(A-base + A-inc) JOIN (B-base + B-inc),但是数据量就太大了,包含了很多的无用计算&存储,同时对下游,也不是 Micro Batch,而是全量数据。
因此,构建的目标应当是产出该 Mirco Batch 内产生变化的数据。
一个初步的想法是:(A-inc JOIN B-base) UNION (B-inc JOIN A-base),不过 A-inc 和 B-inc 的数据可能也有关联,因此修正为:
(A-inc JOIN (B-base + B-inc)) UNION (B-inc JOIN (A-base + A-inc)). 这样 SQL 产出的数据就是需要给到下游的全部增量数据。
基于这个想法,具体的落地需求:
- B-base + B-inc 如何实现?需要一个支持 upsert 的存储系统
- A-inc JOIN B-merged:需要该存储系统支持点查
- 同样依赖调度系统编排任务
- A-inc 应该如何获取?通过存储系统字段/用户字段,或者计算引擎的 windows/batch/binlog 处理,从实现复杂度上前者更合适。
使用事件时间的好处,是系统对外清晰,当前批次处理完成,那么 <= 08:10 的数据就都处理完成。如果放到生产环境,还需要考虑使用事件时间时,一次性要处理的数据可能过多。
反过来,如果 T+1 关注的是昨天(<今天00:00)的指标,当开始追求微批处理,我们关注的其实是时效性,而不是这个数据是否一定 <= 08:10。这种情况下,也可以考虑使用处理时间。
上一节在处理 A-inc 时,还有一个默认对用户屏蔽的点,就是删除数据。在当前系统,需要 A 表只能 markDel,如果物理删除的话依赖从 binlog 读取增量数据。因此,基于 Micro Batch 模型,SQL 用户也需要考虑删除数据如何传递的问题。
如果数据在时间周期内多次更新,Micro Batch 和 T+1 都有一个好处,就是可以仅用最新数据触发一次。
1.3. Stream
从微批到流,我觉得变化最大的是模型。
举一个计算用户历史订单的例子,微批处理时,计算 10 分钟内新增订单的用户,所有历史订单:
SELECT uid, COUNT(1)
FROM trade_table
WHERE update_time IN [current_time, current_time - 10min)
trade_table 存储在 OLAP 引擎,用户开发的 SQL,跟 T+1 的区别不大。如果这个 SQL 交给流计算引擎解释,至少两点是模糊不清的:
- COUNT 这个聚合操作,包含了哪些订单数据?实时任务启动以来的,还是 trade_table 里所有的历史数据?trade_table 存储在 Kafka?
- IN 的时间范围是不是不需要了?
我们会发现单纯靠流计算引擎里的 state,解决这个问题是完全不靠谱的。进一步,假设 trade_table_a 是订单的更新流,存储在 Kafka;table_table_b 是历史所有订单,存储在 hbase。
SELECT uid, COUNT(1)
FROM trade_table_a
JOIN(Temporal) table_table_b
ON trade_table_a.uid = table_table_b.uid
如果从全量模型的角度,这里的 COUNT(1) 是 JOIN 到的所有历史订单的总数。但是对于流计算,从 SQL 语义上,其实是 trade_table_a 流上的 COUNT,每次更新 uid,都会触发历史数据在当前基础上再 COUNT 一次。
对于流上 JOIN、AGGREGATE 的处理过程,特别像是后端的一次点查。其 SQL 也跟离线在全量模型上的写法,变化较大。
因此,随着时间边界的不同,模型、思维上都发生了很大变化。
2. 调度
T+1 的调度,前提条件是“全部数据”,也就是任务 DAG . 因此对离线任务来讲,任务调度平台是不可或缺的。流处理任务的“调度”概念要轻的多,我觉得叫做托管更合适一些。
对批处理和流处理任务,对调度的要求更多是稳定性。
- 批处理任务,关注任务能否按时启动。因此调度系统核心指标之一是调度延迟。
- 流处理任务,关注任务失败恢复的时间。因此流式任务里,会格外看重 HA , Restart-Strategy 的设计。
我最开始做实时计算,看着批处理任务的调度很简单:任务每天都会调度,调度上的修改隔天就能生效。流任务则复杂的多,因为流任务都是 long-running 的,调度上的修改需要重启任务。时间一长,较早的任务和新运行的任务,底层配置和依赖已经变化很大了。
后来做离线任务调度,才发现正因为每天都调度,数据库的压力、版本变化带来的影响更大。同时如何确保任务不因调度系统重启而重启,是一个非常大的挑战。
也算是一个特别的体验了。
同时调度也都会影响到正确性,这点容易被忽略:
- 对批处理,影响准确性的点是变量替换。例如用户在任务里指定 $[yyyyMMddHH-1/24],实际执行的 SQL 应该替换为正确的时间。
- 对流处理,影响准确性的点是 checkpoint. 从错误的 checkpoint 启动,可能会造成丟数。
两者的异同:
- 相似点,比如任务状态和日志的管理、任务的提交流程、失败都需要重试、报警、语法检测等。
- 不同点,比如定时执行还是 long running,监控(qps、延迟、cpu、mem、gc),任务资源自动调优等,同时 Flink 任务的管理,在 checkpoint 上也会做的比较重。
功能上,开发平台都会需要考虑草稿箱、权限、任务组、集群注册、任务发布和回滚的流程、审批审计、运行日志等。
对公司来讲,一套平台可以提供统一的使用习惯、权限、报警等,因此无论是实时还是离线,都应该通过一套平台开发和管理任务。而底层调度系统,对于一次性(批)还是 long running(流)的任务,统一管理还有些难度,但是我觉得也应该尽量统一。这点资源调度上,K8S 做的非常靠前,提供了 Job、Crontab、Deployment 等多种资源对象,值得学习。