本文是一篇分布式菜鸟阅读Raft论文过程中的一些心得。
1.为什么需要有Raft
换言之,Raft尝试解决什么问题。
我接触Raft时,看到的很多文章首先都是先回顾历史(paxos,multi-paxos,CAP/BASE理论等),我觉得不如先讲清楚Raft要解决什么问题。
1.1. 分布式要解决容错问题
当分布式系统里机器数量达到一定规模后,硬件的异常问题开始变得频繁(甚至可能高于软件的异常)。关于这个可以参考Jeff Dean的stanford-295-talk的Page4。
The Joys of Real Hardware
Typical first year for a new cluster:
~0.5 overheating (power down most machines in <5 mins, ~1-2 days to recover)
~1 PDU failure (~500-1000 machines suddenly disappear, ~6 hours to come back)
~1 rack-move (plenty of warning, ~500-1000 machines powered down, ~6 hours)
~1 network rewiring (rolling ~5% of machines down over 2-day span)
~20 rack failures (40-80 machines instantly disappear, 1-6 hours to get back)
~5 racks go wonky (40-80 machines see 50% packetloss)
~8 network maintenances (4 might cause ~30-minute random connectivity losses)
~12 router reloads (takes out DNS and external vips for a couple minutes)
~3 router failures (have to immediately pull traffic for an hour)
~dozens of minor 30-second blips for dns
~1000 individual machine failures
~thousands of hard drive failures
slow disks, bad memory, misconfigured machines, flaky machines, etc.
为了防止机器异常导致数据丢失,例如内存、硬盘数据,常用的方案就是多备份,也就是Replication,那么就会有一个新的问题:各备份实例上的数据如何保持一致。
数据副本是分布式系统解决数据丢失异常的唯一手段。
1.2. Replicated state machines的一致性算法
假定我们使用5台机器来备份,毫无疑问这5台机器上的数据需要一致:
任意一台机器挂了,从其余机器可以读到完全相同的数据。
那么问题来了:
- 写入数据时应当等待这5台机器都写入后,才返回写入成功吗?那如果一台机器响应慢(网络延迟),或者宕机怎么办?
- 如果先写入1台机器,应当选择哪台机器?这台机器写入成功就返回吗?
- 写入1台机器后,怎么保证其余机器也能写入?例如不同机器看到的多条数据顺序不一致(乱序),数据个数不一致(丢包),同步数据到其余机器时timeout是否重发(重包)。同步过程中这1台机器挂掉或者网络分区(CAP里的P),怎么搞?
这只是分布式系统里问题的冰山一角,多个client同时写一条数据时,应该怎么保证顺序和一致。
面对这么多问题,Raft也不是万金油,要解决的问题只有一个:
即使在网络丢包、乱序、延迟,机器宕机的情况下,如何保证多个机器就数据达成一致。
也就是标题里提到的一致性算法(Consensus Algorithm).
通俗点讲,Raft要解决的问题就是上面提到的:
- 选择一台机器写入,由该机器同步给其他机器。应该选择哪台?
- 如何保证在各种异常情况下,所有机器最终达到一致?
好,希望到这里讲清楚了分布式系统里一致性问题确实是个大问题,而Raft就是为此而生的一种算法。
2. Raft如何做的
这一节开始逐步介绍,希望能够讲明白。 先介绍几个名词和背景:
- leader/follower/candidate : Raft算法里的角色,进程在角色间转换
- term : 算法划分的时间,一段时间称为一个term,具体长度不一,当机器出现异常时,可能会进入一个新的term
- LogEntry : 客户端的一个命令对应一个LogEntry
2.1 角色划分
Raft将N个实例划分为不同的role。
leader负责跟client交互,同步数据到其他实例。也就是前面提到了“先写入1台机器”。同时负责周期性的发送心跳包(heartbeat)到follower,目的是为了维持自己的leader角色。
算法保证任何时刻都只存在一个合法的leader。
其他实例作为follower的角色,被动接收RPC请求并做响应,比如leader请求添加日志数据,candidate请求选举。
follower本身是被动的,不会主动发起RPC。
而当follower一段时间内没有收到leader的heartbeat(可能是leader挂了,可能是自己网络出问题了),就认为当前leader失效,转变为candidate角色。
转为candiate后,向其他实例发送选举请求,如果获取超过半数的投票则成为leader;如果已经有新leader产生则成为follower;如果一段时间没有收到半数投票,也没有收到新leader的heartbeat,那么认为split vote,再次发起选举。
通过心跳包的机制就可以解决上面提到的这个问题:
一台机器负责跟client交互,这台机器挂掉怎么办?
角色关系的转换在Raft论文里非常清晰:
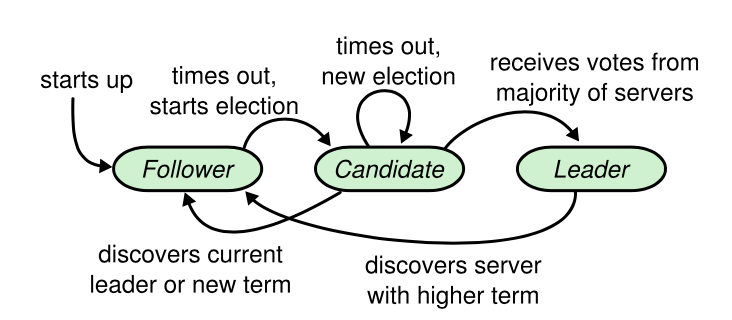
2.2 时间划分
随着时间推移,各种网络、机器异常都会出现,Raft将时间按照term区分,term是一个单调递增的整数,有点像三体里的纪元。
当某个follower超时后,则认为当前term的leader已经失效。follower转为candidate,自增term,发送选举RPC到其他实例,进入新的一轮选举。
其他实例接收到选举请求后,如果发现candiate比自己当前term高,那么意识到新一轮选举开始了,投票给该follower。(牵扯到日志后,这个判断会复杂些,即高term不一定就能获取赞同票,后续讨论)。
因此一轮term总是从意识到没有leader开始,选举出leader或者选举超时后结束。
当然也有可能是这个follower自己网络除了问题,结果就是导致term一直自增,而其他实例term没有改变。也就是说,不同实例同一时刻认为的term是不同的,但是同一实例上,时间被划分为不同的term。
2.3 LogEntry
我在看到这个术语的时候比较困惑,这里具体说明下。比如我们依次设置了N个keyx=1; y=2; z=3,或者操作单独一个keyadd 1;del;insert 100。
这些都属于Log,类似于binlog/undolog/redolog等,实例重启后从这些Log可以恢复到一个状态。
从这里就可以看到Log顺序的重要性,比如不同备份分别看到add -> del与del -> add,最后的状态是完全相反的。
因为term是个递增的值,Log是追加的形式,因此Log里下标越大的LogEntry对应的term是非递减的。
即:
如果有下标j > i,那么termj >= termi.
2.4 Quorum机制
不得不说分布式理论里有各种各样的名词和机制,这里想介绍下Quorum机制,因为觉得Raft充分应用了这个想法。
假定我们有N个实例,写操作时如果N个实例都返回写成功,此时认为写成功。那么之后任意1个实例都能读取正确(比如GFS是这么做的?)。
同样场景,还是N个实例,假定写操作W个实例返回写成功,之后读取任意R台机器,只要W + R >= N + 1,那么读取R台机器的结果里,一定包含了写入的数据。
以上就是Quorum机制,GFS里的做法是Quorum的一个特例:W = N, R = 1。
至于如何筛选出真正的数据,则需要更丰富的协议来实现。
2.5 对比下Paxos
很多新人会纠结在paxos理论上,反正我是没看懂,或者说看的一知半解不知道怎么下手,Raft论文里引用了chubby的观点:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. . . . the final system will be based on an unproven protocol [4].
Raft按照问题把整个流程分为了两部分:
- Leader election
- Log replication
同时包含具体的实现和比较易懂的证明。
所以对于新人,建议直接阅读Raft
介绍完了这些名词和背景,下面详细介绍下流程
2.6 Leader election
本节尝试解释清楚:
leader在何时被选举,如何选举出来,选举出来做什么。
关于更多代码上的介绍,可以参考上篇笔记,show me your code.
Raft论文里提到:
Raft uses a heartbeat mechanism to trigger leader election. When servers start up, they begin as followers.A server remains in follower state as long as it receives valid RPCs from a leader or candidate.Leads send periodic heartbeats(AppendEntries RPCs that carray no log entries) to all followers in order to maintain their authority.If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader.
实例启动时默认为follower角色,如果没有收到heartbeat则转为candidate角色:
- Increment currentTerm
- Vote for self
- Reset election timer
- SendRequestVote RPCs to all other servers
注意出于效率考虑,4里SendRequestVote RPCs 应当是并行的发送到其他server。
选举后可能的情况有三种:
- it wins the election
- another server establishes itself as eleader
- a period of time goes by with no winner.
我们逐个分析下
2.6.1 win
candidate在以下情况下赢得本轮选举:
获取相同term下超过半数的投票
这个条件带来以下的property:
Election Safety: at most one leader can be elected in a given term.
因为任何实例保证对一个term,只会投票给一个实例,所以同一term下只要有一个实例获得了超过半数的投票,那么其他实例将无法胜出。
2.6.2 lose
candidate在等待投票的过程中,可能收到其他实例的AppendEntries RPCs,如果发现RPC里参数的term >= 自身的currentTerm,那么就意识到已经有新的leader选出,自己败选,转为follower.
如果收到其他实例的RequestVote RPCs,发现RPC里的参数term > 自身的currentTerm,那么就意识到已经有新的term开始,转为follower.
2.6.3 split vote
如果上述两者都没有发生,那么选举超时,再次进入下一轮选举。
接下来继续说一些leader election其他tips
2.6.4 election timeout
split vote时有个选举超时时间,本文第一张图里也有一个follower等待heartbeat超时的时间。
这两个时间大小的选取上是随机的,这样可以加快选举进程(避免不同实例同时超时同时发起选举),Raft给出的建议是150~300ms。
本节我们介绍下超时时间的一些误区。
图1里看起来有两个超时时间:
- times out, start election.
- times out, new election.
但实际上,这两个timeout应当是同一个计时器,比如某些情况下candidate转为follower时,不重置超时。
举个例子:
有A B C D E 5个实例
- A当选为leader,同步数据到D E并commit,之后D E宕机
- A网络断连,B C都成为candidate,不断自增term,但由于只有两个实例,无法满足Quorum决议
- A网络恢复,此时B C term都较高,因此A接收到RequestVote后转为follower
- 由于A的日志里已经有commit的数据,此时规则需要保证只有A胜出(因为A的日志较多,这个会在介绍Log replication后介绍)
- A B C 3个实例,如果B C随机超时时间总是较短,那么总是能发出RequestVote RPC使得A转为follower一直无法参与选举
当然5里的情况是概率性的,如果A超时时间较短,那么就能很快选为leader,但是概率降低为只有1/3的几率。在实际大型项目里,包括我在6.824的测试里,都有几率复现这个case。
那么什么情况下需要重置timeout呢?
- candidate开始选举后,这个无需多言
- 如果收到
RequestVote,只有在投票给对方转为follower的情况下,才重置 - 如果收到
AppendEntries,如果收到的term比自身大,则转为follwer并重置
对应上面的例子,例如A收到RequestVote,虽然RPC里的term较大会导致A转为follower,但是由于日志更多,因此不会投票给对方,超时timer不重置,所以总能wake up以参与选举。
2.6.5 RPC的参数
Raft一致性算法里一共有两个RPC,一个是RequestVote,用于选举;一个是AppendEntries,用于同步日志数据。另外还有SnapShot,实际环境中需要,跟一致性算法无关。
RequestVote的request/reply参数及实现:
// Invoked by candidates to gather votes (§5.2).
// Arguments:
term // candidate’s term
candidateId // candidate requesting vote
lastLogIndex // index of candidate’s last log entry (§5.4)
lastLogTerm // term of candidate’s last log entry (§5.4)
//Results:
term // currentTerm, for candidate to update itself
voteGranted // true means candidate received vote
// Receiver implementation:
// 1. Reply false if term < currentTerm (§5.1)
// 2. If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
candidateId用于通知对方自己的身份ID
term也是必须的,用来通知对方自己的currentTerm
lastLogIndex lastLogTerm在介绍日志后说下为什么是必须的,包括up-to-date的判断。
reply参数里的term为接收者处理完成后的currentTerm, voteGranted表示是否赞成这次投票。
好,目前介绍了leader何时选举,如何选举的过程。
接下来介绍下leader选举后做什么,也就是如何复制日志。
2.7 Log replication
leader选举出后,开始负责与client通信:
- 接收client的数据,决定如何同步到其他状态机
- 根据同步到其他状态机的结果,决定何时反馈给client数据已提交(提交后不会丢失)
我们先直观看下log是怎么回事
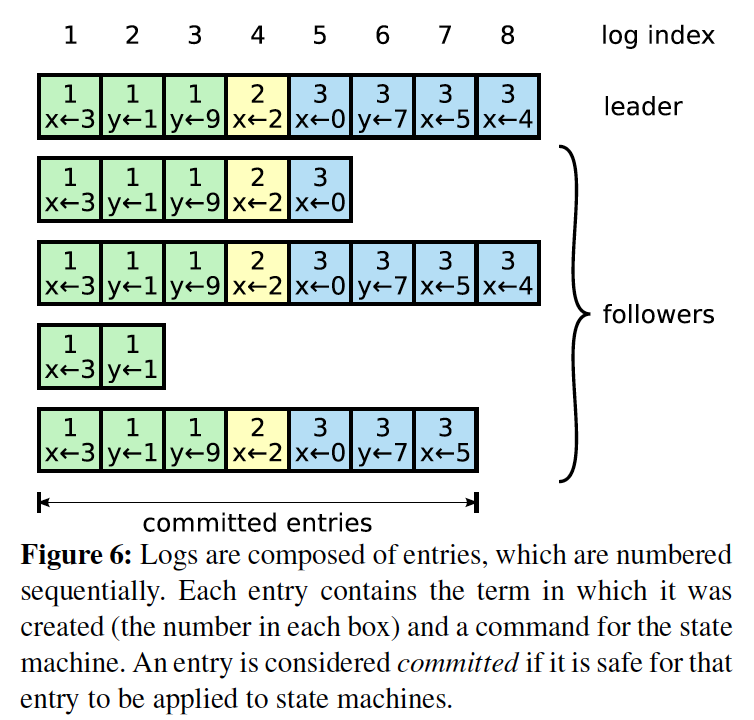
每个方格代表一个LogEntry,可以看到Log是由一个个LogEntry组成的,理想情况下所有实例上该数组都是一致的。
Log元素根据状态的不同,又分为未提交和已提交。只有已提交的LogEntry才会返回客户端写入成功。
最上面一行是log index,也就是下标值,单调递增。
方格内x<-2是Command,2是该Command对应的term。
注:论文里有commited和applied两个词,commiteid是已提交。不太确定applied是否是应用到本地或者未提交。
2.7.1 各实例log状态多样
leader同步数据时,其他实例上的状态机可能是多种多样的。我们用Raft论文里的Figure7来说明下,相比上一张图,省略了Command。
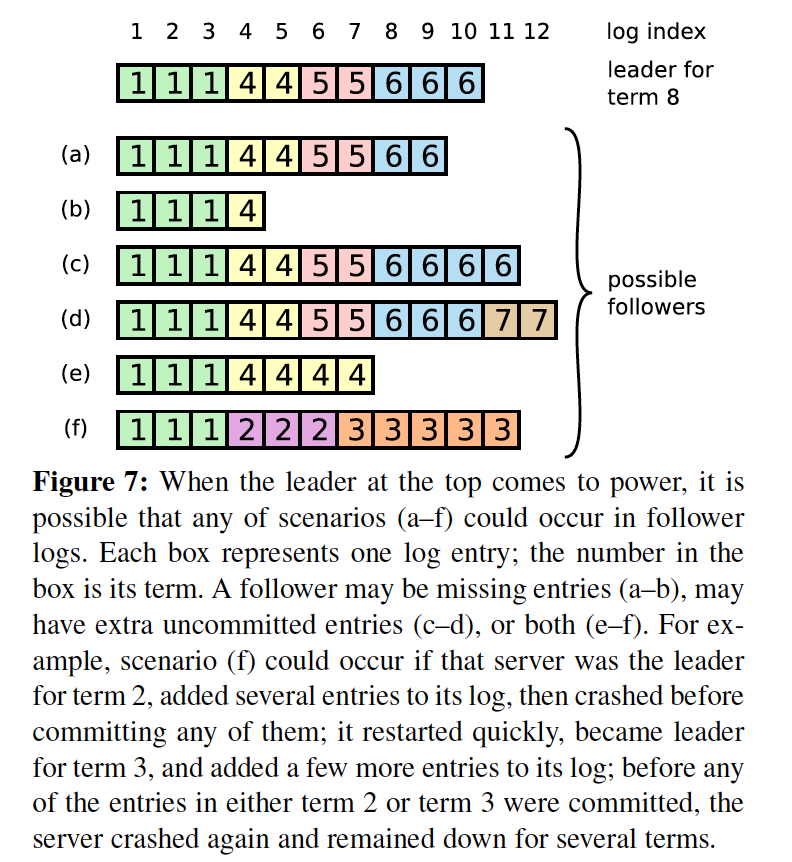
可以看到follower的情况各不相同:
- a b日志较少
- c d日志更多
- e f日志冲突
leader的作用就是将自己的Log同步到其他实例,如果一个元素同步到超过一半的实例,那么就可以标记为已提交。
2.7.2 如何同步
Raft的每个实例维护着一个nextIndex数组,这个数组在leader状态使用。
The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower.When a leader first comes to power, it initializes all nextIndex values to the index just after the last one in its log (11 in Figure 7).
比如上面的图片,leader当选后将nextIndex元素都设置为11,也就是自身的nextIndex。
因此,leader发送的第一个AppendEntries RPC往往是一个空的包(不包含日志数据的心跳包,大部分时候是空的,如果当选leader和发送AppendEntries之间leader接收了新的数据,那么这部分新数据也会发送)。
其他实例在收到AppendEntries后,
首先判断term是否>=自身term,如果是的话,那么就意识到有新的leader产生。
接着从RPC request参数里判断日志数据是否冲突,当前已提交的log index等,然后更新本地的Logs和commitIndex。
具体怎么做的,看下AppendEntries RPC的参数及实现
2.7.3 RPC的参数
之前说了,Raft一致性协议有两个RPC,AppendEntries负责同步日志数据。
// Invoked by leader to replicate log entries (§5.3); also used as heartbeat (§5.2).
// Arguments:
term // leader’s term
leaderId // so follower can redirect clients
prevLogIndex // index of log entry immediately preceding new ones
prevLogTerm // term of prevLogIndex entry
entries[] // log entries to store (empty for heartbeat; may send more than one for efficiency)
leaderCommit // leader’s commitIndex
// Results:
term // currentTerm, for leader to update itself
success // true if follower contained entry matching prevLogIndex and prevLogTerm
// Receiver implementation:
// 1. Reply false if term < currentTerm (§5.1)
// 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
// 3. If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3)
// 4. Append any new entries not already in the log
// 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
term的作用在于follower用来判断是否听从该AppendEntries里的日志参数。
leaderId用来通知对方自己的身份。
prevLogIndex prevLogTerm用于解决日志从哪里开始复制的问题,比如上面讲到的nextIndex的做法,那么在上张图里的leader当选后,发送的prev是这样的:
prevLogIndex = 10
prevLogTerm = 6
各个follower判断自己对应的index是否是这个term,如果发现日志冲突,success = flase返回给leader。leader尝试将prevLogIndex递减,直到日志匹配。
论文里还提到一种优化方法,follower返回冲突的index及对应的term,我认为还是值得尝试的:
ConflictIndex int
ConflictTerm int
对应上张图,这里会有几种情况:
- 日志缺少,比如a b e不存在logindex == 10, 则
ConflictIndex = len(logs), success = false - 日志冗余,比如c d,那么删除logindex > 10的日志,返回
success = true - 日志冲突,比如f,那么返回冲突term出现的第一个logindex,也就是通知leader从哪个term开始冲突的
- 日志完全匹配,那么添加RPC request里的日志到本地,返回
success = true
leaderCommit用于通知实例自己已经提交的日志下标
关于日志数据流的处理,最重要的一个原则就是:
不能丢失、修改任何commit的日志
从使用方来看也是合理的,因为commit之后我们会返回给client数据更新成功,因此这个数据是不能丢失和修改的。
接下来我们就逐步看下为什么按照RPC里的这种处理方式,能够满足上面的原则。
2.7.4 相同index、相同term的LogEntry一定存储了相同的数据
Raft算法保证leader接收client的请求时,每条数据只会创建一个LogEntry,并且位置不再变化。
相同term的LogEntry一定来源于同一个leader,而leader的LogEntry不会改变位置。
也就可以保证我们的标题。
这里需要注意的是这个LogEntry可能被替换,比如这条日志没有被提交,而产生了更高term的leader,新的leader会使用更高term的数据覆盖这个位置的日志,但对应的term也发生了变化
2.7.5 相同index、相同term的LogEntry之前一定存储了相同的数据
Raft要求实例接收到leader发送AppendEntries后做日志一致性检查。
这也是AppendEntries Request里prev参数的作用:
prevLogIndex // index of log entry immediately preceding new ones
prevLogTerm // term of prevLogIndex entry
entries[] // log entries to store (empty for heartbeat; may send more than one for efficiency)
实例只有在以下情况下才会将entries[]应用到本地日志:
自身满足 Log[prevLogIndex].term == prevLogTerm
正如2.7.3介绍的,如果发现不符合,那么返回leader的response里设置success = false。而leader接收到后,递减prevLogIndex--发送给该实例重试,直到实例返回success = true。
由于最开始状态都是一致的(全部为空),因此如果prevLogIndex减少到日志最小的index - 1,那么一致性检查就能通过,保证了上面的重试一定能够成功。
在这样的机制下,我们可以用反证法来证明这一小节的题目:
假设a b两个实例在index = j处有相同的index和term,而存在某个最大的i,满足
index = i and i < j and a.Log[i].term != b.Log[i].term
说明a.Log[i]与b.Log[i]来自不同的leader(可能是a b自身),而在index = i + 1的时候被某个leader x统一了,那么这里就产生了矛盾:
x.Log[i].term == a.Log[i].term and x.Log[i].term == b.Log[i].term
目前我们可以得到Raft的又一个property:
Log Matching: if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.
2.7.6 日志数据流只从leader -> follower
In Raft, the leader handles inconsistencies by forcing the followers’ logs to duplicate its own.
这也是为什么上面介绍日志冲突时,解决方案总是leader同步自己的日志到follower。
由于日志数据流是单向的,因此这样的设计可以大大的简化流程与算法的复杂度。
这个设计带来Raft的第三个property:
Leader Append-Only: a leader never overwrites or deletes entries in its log; it only appends new entries.
当然这个设计也带来了一个问题,例如考虑这样的场景:
假定集群中有a b c d e实例,其中a b c d正常复制日志,term = 1。
而e网络分区,不断选举->超时->选举,term越来越大。当term = 100时e的网络恢复正常,此时a b c d已经存储了很多日志但是term = 1,e没有存储日志但是term = 100。由于日志数据流总是从leader到follower,因此为了不丢失日志数据,即使e的term高,仍然需要一个规则来限制e不能成为leader。
接下来进入下一节,介绍下这个规则以及其他一些safety
2.8 Safety
2.8.1 Election restriction
上一节的讨论,还有一个需要解决的问题:
如何限制term高但是日志较少的实例成为leader?
也就是说实例不能单纯以RequestVote args里的term大小,来决定是否投票。
2.6.5节里last...参数正是出于这个目的设计:
lastLogIndex // index of candidate’s last log entry (§5.4)
lastLogTerm // term of candidate’s last log entry (§5.4)
leader发送RequestVote时,lastLogIndex设置为len(Logs) - 1,即自己Log最后一个元素,lastLogTerm为元素对应的term。
实例接收RequestVote后,首先判断term,其次需要判断Log是否满足up-to-date,全部满足条件才能投票。
引用下原文解释下up-to-date的具体判断:
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
即:
- 先比较末尾LogEntry的term大小,term大的最新。
- 如果term相等,Log长的最新。
优先用term的原因:
比如server-1选为leader(term=1),接收了N条client的数据,但是没有同步到其他server,之后server-1 crash, server-2选为leader(term=2),接收1条client数据并同步到多数server,返回client commited,server-2 crash。之后server-1 2同时resume并且选举,那么必须是 server-2 win vote。
经过这个规则选举出的leader一定包含了所有commit的日志。
说下我理解的证明过程:
假设该规则选举出的leader并没有包含所有的commit日志,这条日志为对应的index = i,term = ti,同时这条日志在超过一半的实例上存在,当前选举出的leader记为leadercurrent。
不妨假设leader的最后一条日志term为tlast,同时tlast >= 超过一半的实例上的最后一条日志的term,记录为tmajority.
因为ti tmajority都在超过一半的实例上存在,可以推断出ti <= tmajority。
tlast ti的大小关系分为三种情况讨论:
- < : 可以推导出不等式 tlast < ti <= tmajority <= tlast,矛盾。
- = : 记term = ti时对应的leader为leaderi,leaderi已经同步了该日志到超过一半的实例并提交,而leadercurrent显然并没有接收到该日志,因此日志长度小于其他接收到日志的实例日志长度。与规则里Log长的最新矛盾。
- > : 记term = tlast时对应的leader为leaderlast,那么leaderlast上是否存在日志i呢?假定存在日志i而没有同步到leadercurrent,而tlast > ti,由于日志元素里的term非递减,此时一定已经同步了所有< tlast的日志,因此矛盾。也就是是之前某个leaderlast上,就已经不存在日志i。从tlastsub>往前递推直到,继续应用这三种情况,可以证明矛盾。
经过这样的设计,可以看到只要一条数据commited了,之后的所有leader一定会带着这条数据并标记为commited.也就是property:
Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms. §5.4
2.8.2 Committing entries from previous terms
前面提到了当leader同步了日志到超过一半的实例后,就可以放心的将数据标记为commited并通知client。这里其实隐藏了一个前提,那就是这条日志数据对应的term必须是自己的currentTerm。
解释下这张图:

每个格子表示一个LogEntry,格子内数字为term值,最上面是Log的索引号。
相同颜色的格子表示同一个LogEntry。
最开始是a状态,随时间变化到接下来的状态:
- a状态:term = 2 && leader = s1,s1复制index = 2的数据到s2
- b状态:s1 crash,term = 3 && leader = s5,s5接收client的命令在index = 2产生一条数据
- c状态:s5 crash,term = 4 && leader = s1,s1继续复制index = 2的数据到s3,目前s1 s2 s3在index = 2的数据都一致,term = 2
那么问题来了?此时能否标记index = 2的数据为已提交?
答案是不可以,即
Raft never commits log entries from previous terms by counting replicas.
原因继续往下看:
c->d状态:s1 crash, leader = s5(voted by s2 s3 s4 and s5 self),可以看到原来index = 2 && term = 2的数据被替换了,因此s1不能标记index = 2 and term = 2的数据已提交。
解决方法呢?
c->e状态:假设s1没有crash,继续同步index = 3 and term = 4的数据并提交,自然能够将之前index = 2 and term = 2的数据提交上来。
2.8.3 Safety argument
Raft论文里会有这一节,主要为了证明我们2.8.1提到的property(论文里也有很详细的反证法),以及另外一个property:
State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. §5.4.3
我理解因为我们同步日志时总有prevLogIndex prevLogTerm这个check机制,那么顺序一定是相同的。
到这里梳理下Raft的所有safety,也就是论文里的figure3
- 选举安全特性 对于一个给定的任期号,最多只会有一个领导人被选举出来
- 领导人只附加原则 领导人绝对不会删除或者覆盖自己的日志,只会增加
- 日志匹配原则 如果两个日志在相同的索引位置的日志条目的任期号相同,那么我们就认为这个日志从头到这个索引位置之间全部完全相同
- 领导人完全特性 如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中
- 状态机安全特性 如果一个领导人已经在给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会提交一个不同的日志
希望我讲明白了 ![]()
2.9 实现中的一致性
我理解一致性最简单的解释就是:
对client而言,如果返回我已经写入了,那么接下来一定能够查询的到,不会因为机器、网络问题等丢失。
而如果返回写入失败,那么一定查询不到。
如果返回超时,则结果不确定。关于这种情况,sdk需要保证操作是幂等的,我理解比如每个数据请求带一个id,如果server收到已更新的重复id,那么就忽略,否则添加到日志中。
而server多个实例间的一致性由Raft算法保证,leader挂掉则重新选举leader,按照上面的介绍,如果已经返回了client数据已经写入(提交),那么新的leader也保留这些数据。
更具体的情况,比如leader接收client数据后,同步到了部分follower上后crash,此时新选举出的leader可能包含这部分数据,也可能不包含。client没有收到RPC响应超时重发,新的leader如果存在这条数据,那么根据幂等性处理,如果不存在,那么添加到自己的日志里,准备同步给其他follower。保证了我上面提到的数据一致性。
2.10 State
2.10.1 persist
持久化这块是最初一直想不清楚的,因为纠结在数据落盘的时机:先更新内存数据还是先持久化。
最后发现其实Figure2也早就给了答案,那就是在响应RPC之前。
因为follower一旦响应了RPC,leader就可能将这条数据标记为已提交。而此时如果follower持久化失败,那么重新启动reload硬盘数据后,就可能丢失了某些已提交的数据。
而persist如果做到RPC里,就要求有很高的性能,这块也是我很感兴趣的点。
2.10.2 volatile
Figure2提到的一些State(实际Raft内存里记录的多得多)
//Persistent state on all servers: (Updated on stable storage before responding to RPCs)
currentTerm //latest term server has seen (initialized to 0 on first boot, increases monotonically)
votedFor //candidateId that received vote in current term (or null if none)
log[] //log entries; each entry contains commandfor state machine, and term when entry was received by leader (first index is 1)
//Volatile state on all servers:
commitIndex //index of highest log entry known to be committed (initialized to 0, increasesmonotonically)
lastApplied //index of highest log entry applied to state machine (initialized to 0, increases monotonically)
//Volatile state on leaders: (Reinitialized after election)
nextIndex[] //for each server, index of the next log entry to send to that server (initialized to leader last log index + 1),要发送到该实例的日志下标起始位置,也就是prevLogIndex + 1,如果日志一致时才满足matchIndex + 1 = nextIndex。
matchIndex[] //for each server, index of highest log entry known to be replicated on server (initialized to 0, increases monotonically) 实例返回的已经同步的日志下标,找到一个最大的N,满足超过半数实例的matchIndex >= N,那么就可以标记为已提交了
2.11 时间要求
毫无疑问时间上是有限制的,比如发送heartbeat的时间间隔一定小于follower的超时时间。
broadcastTime ≪ electionTimeout ≪ MTBF
MTBF: Mean tiem Between Failure
Raft里还讲了集群实例数变更和log compaction的方法,本文就不再赘述了。
3. 回顾
本来想简单几句说清楚Raft的,却啰嗦了一大堆,成了我目前写的笔记里最长的一篇了![]()
而Raft已经以understandability出名了,那么可想而知,为什么很多人在说paxos多么复杂。
从参考资料里可以看到raft发表后有很多开源实现,给我的经验就是设计一个系统或者算法,同时有能力讲清楚、易于实现是极为重要的。
我们也能清楚的看到,算法要求各个实例在某个角色下该做什么,不该做什么,不会发送一些假数据出来。而如果发送一些假数据出来,系统一定会不可控,这也是分布式总提到的“拜占庭问题”。
4. 参考资料
- 大名鼎鼎的Raft论文:除了论文,页面上的的slides一定看下。
- Raft流程的可视化介绍
- The Raft Consensus Algorithm:上面有非常丰富的视频以及slides资料,同时相比上面的可视化,这里的可视化是交互式的,可以模仿timeout/stop/drop等一系列网络问题。