1. Timer
系统收到 1 条数据,计算,输出 0~N 条数据,这种 Event-driven 的方式是最简单和自然的。
但实际上,由于存在乱序、丟数,以及业务周期性更新的需求,计算还会依赖于时间触发,例如Dataflow Model的第三节 IMPLEMENTATION & DESIGN 的场景。
这些场景依赖于 Timer,Flink 的窗口也是基于 Timer 实现。
Timer 不是简单的时间触发回调,Process Function#Timers文档介绍了 Timers,主要有几点:
- ProcessingTime 和 EventTime 都是由 TimerService 维护的,定时触发用户的
onTimer方法 - TimerService 会对 key + timestamp 去重
onTimer和processElement是串行的,使用者实现逻辑即可,不用担心并发导致不一致的问题- Timer 会存储到 state,因此是 Fault Tolerance 的
这几个 feature 都是易用性、稳定性上非常重要的设计。
我们自己实现的话,也会非常复杂,比如:EventTime 是靠水位线/数据触发,ProcessingTime 则是靠系统时间触发,两者是如何都回调到onTimer方法的;onTimer的回调,跟processElement是如何做到串行的?TimerService 是如何管理多个 timer 的,如何保证顺序性,如何存储的?扩缩容时,timer 的 state 还能被不同并发正常读取么,如何保证 timer 不丢?
这篇笔记,试着解释 timer 的用法和原理(基于 flink 1.14.5 版本)。
2. KeyedProcessFunction
看一个KeyedProcessFunction使用 timer 的例子:
val sourceStream = SourceUtils.generateKafkaSensorReadingStream(env, sensorReadingTopic, bootStrapServers, groupId)
sourceStream.keyBy(_.id)
.process(new KeyedProcessFunction[String, SensorReading, String] {
val logger: Logger = LoggerFactory.getLogger(this.getClass)
override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, String]#Context, out: Collector[String]): Unit = {
logger.info(s"processElement:${value} ctx.timestamp:${ctx.timestamp} ctx.timerService:${ctx.timerService} ctx.getCurrentKey:${ctx.getCurrentKey}")
val nextProcessTimestamp = System.currentTimeMillis() + 300000L
logger.info(s"nextProcessTimestamp:${nextProcessTimestamp}")
ctx.timerService().registerProcessingTimeTimer(nextProcessTimestamp)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext, out: Collector[String]): Unit = {
logger.info(s"onTimer:${timestamp} ctx.getCurrentKey:${ctx.getCurrentKey}")
}
})
收到数据后,注册一个当前时间 + 5min 的 timer,该 timer 会在指定时间触发执行onTimer方法。
如果使用registerEventTimeTimer,在数据的水位线超过该时间后,也是相同的效果。
KeyedProcessFunction#Context.timerService()返回TimerService,是一个接口,支持了定时、删除和读取 ProcessingTime/EventTime:
public interface TimerService {
String UNSUPPORTED_REGISTER_TIMER_MSG = "Setting timers is only supported on a keyed streams.";
String UNSUPPORTED_DELETE_TIMER_MSG = "Deleting timers is only supported on a keyed streams.";
long currentProcessingTime();
long currentWatermark();
void registerProcessingTimeTimer(long time);
void registerEventTimeTimer(long time);
void deleteProcessingTimeTimer(long time);
void deleteEventTimeTimer(long time);
}
除了KeyedProcessFunction,Flink - 窗口理论、实现里的 trigger 也都支持访问TimerService,区别在于 trigger 里没有暴露TimerService,而是直接提供了 register/delete 相关的接口:
public interface TriggerContext {
long getCurrentProcessingTime();
long getCurrentWatermark();
void registerProcessingTimeTimer(long time);
void registerEventTimeTimer(long time);
void deleteProcessingTimeTimer(long time);
void deleteEventTimeTimer(long time);
}
其触发机制是一样的。
KeyedProcessFunction#Context.timerService()返回的实际是SimpleTimerService:
public class SimpleTimerService implements TimerService {
private final InternalTimerService<VoidNamespace> internalTimerService;
public SimpleTimerService(InternalTimerService<VoidNamespace> internalTimerService) {
this.internalTimerService = internalTimerService;
}
}
这是暴露给用户的类,方法实现都 delegate 给了 internalTimerService, 这是 Flink 内部的实现类。
ProcessFunction#Context 不支持 TimerService ,代码里会抛出异常:
public class ProcessOperator<IN, OUT>
extends AbstractUdfStreamOperator<OUT, ProcessFunction<IN, OUT>>
implements OneInputStreamOperator<IN, OUT> {
private class ContextImpl extends ProcessFunction<IN, OUT>.Context implements TimerService {
@Override
public void registerEventTimeTimer(long time) {
throw new UnsupportedOperationException(UNSUPPORTED_REGISTER_TIMER_MSG);
}
}
}
这么实现代码的好处,是用户看到的接口及实现都非常简洁,复杂度留在了internalTimerService.
2. KeyedProcessOperator And WindowOperator
KeyedProcessFunction 在 ExecGraph 对应的算子是 KeyedProcessOperator,ProcessWindowFunction 则是 WindowOperator.
上一篇笔记贴过 WindowOperator.onEventTime 的调用栈,其实两者是非常像的:
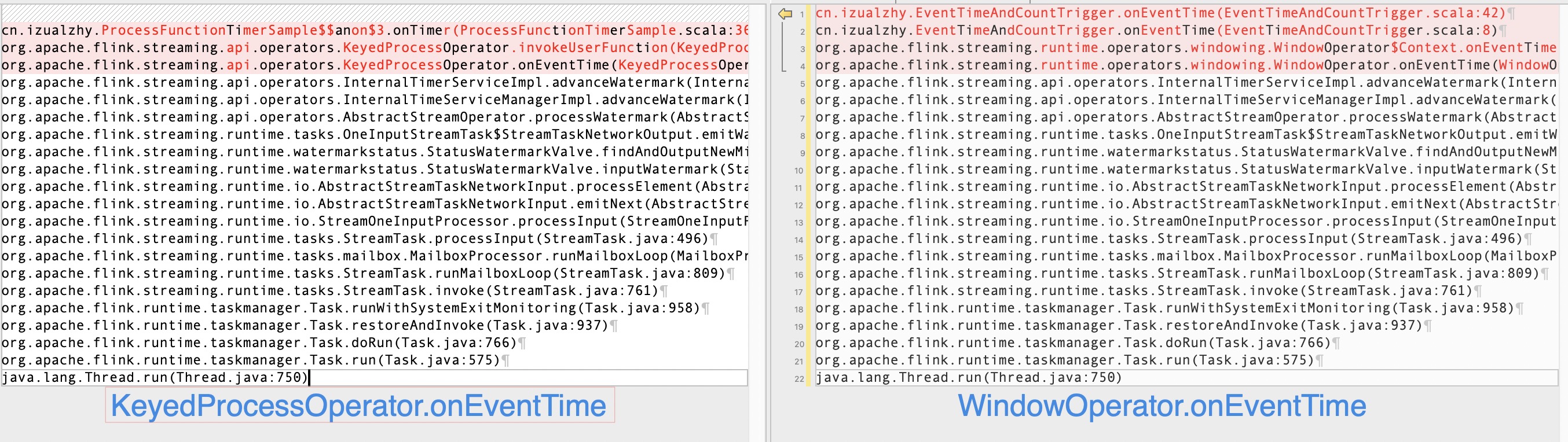
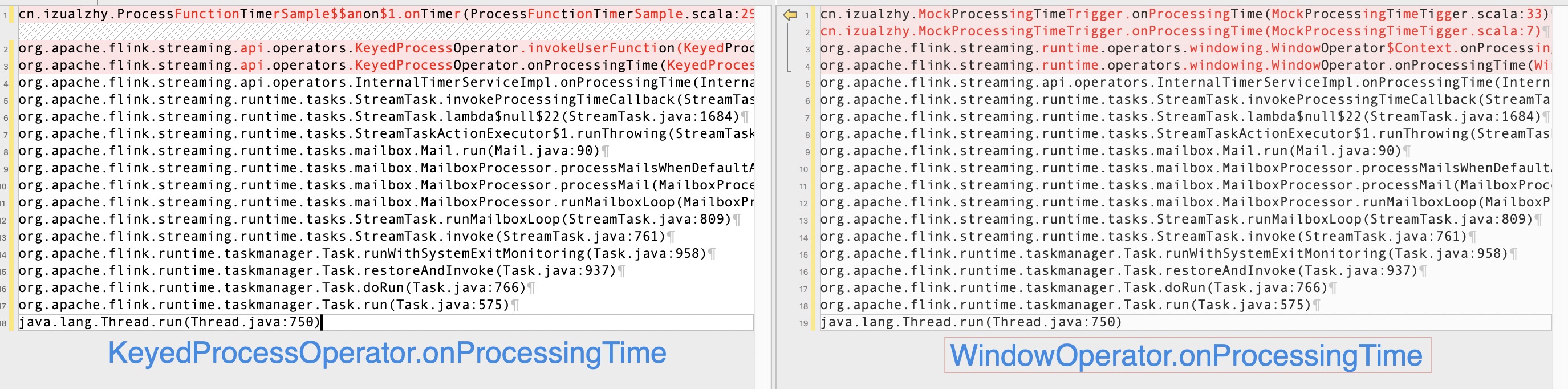
通过上面两张调用栈的对比图,可以总结到:
无论是哪种 operator,
onEventTime都是随着processElement调用的,即处理数据时提取 watermark,进而触发了该方法:InternalTimeServiceManagerImpl.advanceWatermark -> InternalTimerServiceImpl.advanceWatermarkonProcessingTime和onEventTime都是随着MailboxProcessor.runMailboxLoop调用的:StreamTask.invokeProcessingTimeCallback -> InternalTimerServiceImpl.onProcessingTime- 两者都有一个非常重要的类:
InternalTimerServiceImpl,分别调用了advanceWatermark和onProcessingTime方法
InternalTimerServiceImpl实际就是上一节InternalTimerService的子类。
3. KeyedProcessOperator 源码分析
3.1. KeyedProcessOperator.open
KeyedProcessOperator.open方法里,构造SimpleTimerService传入了internalTimerService:
public class KeyedProcessOperator<K, IN, OUT>
extends AbstractUdfStreamOperator<OUT, KeyedProcessFunction<K, IN, OUT>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, VoidNamespace> {
public void open() throws Exception {
// ...
InternalTimerService<VoidNamespace> internalTimerService =
getInternalTimerService("user-timers", VoidNamespaceSerializer.INSTANCE, this);
TimerService timerService = new SimpleTimerService(internalTimerService);
context = new ContextImpl(userFunction, timerService);
}
WindowOperator.open方法类似:
public class WindowOperator<K, IN, ACC, OUT, W extends Window>
extends AbstractUdfStreamOperator<OUT, InternalWindowFunction<ACC, OUT, K, W>>
implements OneInputStreamOperator<IN, OUT>, Triggerable<K, W> {
protected transient InternalTimerService<W> internalTimerService;
public void open() throws Exception {
// ...
internalTimerService = getInternalTimerService("window-timers", windowSerializer, this);
getInternalTimerService是共同的基类AbstractStreamOperator的方法,只是参数不同,同时第三个参数传入了 operator 自身。
AbstractStreamOperator
▲
│
AbstractUdfStreamOperator
▲ ▲
│ │
KeyedProcessOperator WindowOperator
该方法返回了InternalTimerService.
3.2. AbstractStreamOperator.getInternalTimerService
从该方法可以看到,InternalTimerService 是由 InternalTimerServiceManager 管理的
abstract class AbstractStreamOperator
// 引入了 namespace key 的概念
// name: "user-timers", "window-timers"
// namespaceSerializer:
// triggerable: timer的回调, operator 自身
public <K, N> InternalTimerService<N> getInternalTimerService(
String name, TypeSerializer<N> namespaceSerializer, Triggerable<K, N> triggerable) {
if (timeServiceManager == null) {
throw new RuntimeException("The timer service has not been initialized.");
}
@SuppressWarnings("unchecked")
InternalTimeServiceManager<K> keyedTimeServiceHandler =
(InternalTimeServiceManager<K>) timeServiceManager;
KeyedStateBackend<K> keyedStateBackend = getKeyedStateBackend();
checkState(keyedStateBackend != null, "Timers can only be used on keyed operators.");
return keyedTimeServiceHandler.getInternalTimerService(
name, keyedStateBackend.getKeySerializer(), namespaceSerializer, triggerable);
}
3.3. InternalTimerServiceImpl
InternalTimerService相比暴露给用户的 TimerService,多了 namespace 的概念;InternalTimerServiceImpl是真正的实现类,管理了注册的时间戳、ProcessingTimeService、以及持久化。
这里可以看到第 2 节里非常重要的两个方法:onProcessingTime和advanceWatermark,都是根据传入的时间戳,不断从注册队列里取出时间,填充需要传给用户函数的数据,触发 trigger 对应的 onProcessingTime或者onEventTime方法。
// 存储注册的时间队列, 真正触发回调的timerservice,
InternalTimerServiceImpl implements InternalTimerService
private final ProcessingTimeService processingTimeService
KeyGroupedInternalPriorityQueue<TimerHeapInternalTimer<K, N>> processingTimeTimersQueue;
KeyGroupedInternalPriorityQueue<TimerHeapInternalTimer<K, N>> eventTimeTimersQueue;
startTimerService
// 从队列里取出第一个 timer
InternalTimer<K, N> headTimer = processingTimeTimerQueue.peek()
// 注册回调,时间为取出的 timer,函数为 onProcessingTime,注意 processingTimeService 会 wrap 以确保串行执行
nextTimer = processingTimeService.registerTimer(headTimer.getTimestamp(), this::onProcessingTime);
private void onProcessingTime(long time)
InternalTimer<K, N> timer;
// 从 processingTimeTimerQueue 取出 timer,直到未达到触发时间
// 调用 triggerTarget.onProcessingTime
// 这里 InternalTimerServiceImpl.triggerTarget 即为 KeyedProcessOperator
// 继续注册最近的一个 timer
while ((timer = processingTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) {
processingTimeTimersQueue.poll();
keyContext.setCurrentKey(timer.getKey());
triggerTarget.onProcessingTime(timer);
}
// 注册新的 timer (这套方式,添加新的 timer 时应该也需要这个逻辑?)
if (timer != null && nextTimer == null) {
nextTimer =
processingTimeService.registerTimer(
timer.getTimestamp(), this::onProcessingTime);
}
public void advanceWatermark(long time) throws Exception {
currentWatermark = time;
InternalTimer<K, N> timer;
while ((timer = eventTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) {
eventTimeTimersQueue.poll();
keyContext.setCurrentKey(timer.getKey());
triggerTarget.onEventTime(timer);
}
}
InternalTimeServiceManager主要是按照 name 返回不同的InternalTimerServiceImpl,为了避免重复创建,这一层缓存是必要的:
InternalTimeServiceManagerImpl implements InternalTimeServiceManager
private final Map<String, InternalTimerServiceImpl<K, ?>> timerServices;
getInternalTimerService
// 先查找 timerServices 是否存在 name,是的话直接返回;否则创建 InternalTimerServiceImpl,插入到 timerServices 返回
InternalTimerServiceImpl<K, N> timerService =
registerOrGetTimerService(name, timerSerializer);
//
timerService.startTimerService(
timerSerializer.getKeySerializer(),
timerSerializer.getNamespaceSerializer(),
triggerable);
return timerService;
3.4. KeyGroupedInternalPriorityQueue 和 TimerHeapInternalTimer
TimerHeapInternalTimer包含了四元组,timestamp 越小则越小:
public final class TimerHeapInternalTimer<K, N>
implements InternalTimer<K, N>, HeapPriorityQueueElement {
@Nonnull private final K key;
@Nonnull private final N namespace;
private final long timestamp;
private transient int timerHeapIndex;
public int hashCode() {
int result = (int) (timestamp ^ (timestamp >>> 32));
result = 31 * result + key.hashCode();
result = 31 * result + namespace.hashCode();
return result;
}
public int comparePriorityTo(@Nonnull InternalTimer<?, ?> other) {
return Long.compare(timestamp, other.getTimestamp());
}
同时可以看到其 hashCode 跟 timestamp、key、namespace 都有关系。
namespace 的概念最难理解,我的理解是:
- 对于 KeyedProcessFunction,不需要区分,因此其 namespace 只有一个,即 VoidNamespaceSerializer.INSTANCE
- 对于 ProcessWindowFunction,回调跟 window 有关,因为同一时刻可能存在多个 window,而 window 之间的数据是互不影响的,所以 namespace 各不相同
也就是起到了分组隔离的作用。
KeyGroupedInternalPriorityQueue实现了二叉堆,同时按照 keyGroup 管理(方便扩缩容)
3.5. ProcessingTimeService
靠 ProcessingTime 触发的话,就必须引入单独的触发线程了,这里封装的也很绕(尽量理解思想吧,这类开源项目,代码级别变动的太频繁了)
首先看一下StreamTask
class StreamTask
// createTimerService 创建,new SystemProcessingTimeService,或者传入
TimerService timerService
public ProcessingTimeServiceFactory getProcessingTimeServiceFactory() {
return mailboxExecutor ->
new ProcessingTimeServiceImpl(
timerService,
callback -> deferCallbackToMailbox(mailboxExecutor, callback));
}
ProcessingTimeCallback deferCallbackToMailbox(
MailboxExecutor mailboxExecutor, ProcessingTimeCallback callback) {
return timestamp -> {
mailboxExecutor.execute(
() -> invokeProcessingTimeCallback(callback, timestamp),
"Timer callback for %s @ %d",
callback,
timestamp);
};
}
private void invokeProcessingTimeCallback(ProcessingTimeCallback callback, long timestamp) {
try {
callback.onProcessingTime(timestamp);
} catch (Throwable t) {
handleAsyncException("Caught exception while processing timer.", new TimerException(t));
}
}
这里构造了ProcessingTimeServiceImpl,传入给 3.3 节里的InternalTimerServiceImpl.processingTimeService
而ProcessingTimeServiceImpl最重要的,是做了一层 wrapper,实现上则又都 delegate 给了内部的timeSerivce成员变量:
// timer 操作都交给成员变量 timerService,支持 wrap callback 和注册的 timer 个数计数
class ProcessingTimeServiceImpl implements ProcessingTimeService
private final TimerService timerService
// 注册的是 wrap 后的 callback
// 传入的值是 StreamTask.deferCallbackToMailbox,再在 mailboxExecutor 里执行 invokeProcessingTimeCallback -> callback.onProcessingTime
// 这样就达到 单线程处理 的效果了
processingTimeCallbackWrapper
实际管理时间回调线程的,则是SystemProcessingTimeService类:
// 单线程的 timerService,支持传入时间戳,到时间后调用 callback
// 可以多次调用 timestamp + callback
class SystemProcessingTimeService implements TimerService extends ProcessingTimeService
ScheduledThreadPoolExecutor timerService;
ScheduledFuture<?> registerTimer(long timestamp, ProcessingTimeCallback callback)
// wrapOnTimerCallback 将 callback + timestamp 封装到 ScheduledTask
timerService.schedule(wrapOnTimerCallback(callback, timestamp), delay, TimeUnit.MILLISECONDS)
不要小看了这层 wrapper,正是这个封装,使得回调方法和处理数据一样,都放到了mailboxExecutor里执行,因此也就起到了串行的效果。
4. 总结
Timer 在数据计算场景是不可或缺的,Flink 在 Timer 的管理和接口上,花了很大的巧思:
- 处理数据和 timer 回调是串行的,这部分主要是通过都放到了
mailboxExecutor执行实现的 - Process和 window 的场景都需要 timer(或者说 window 就是用 timer 实现的),因此 timer 引入了 name、namespace 的概念
InternalTimerServiceImpl管理了所有的 key 及 timer,对象个数跟 Operator 个数有关?(“user-timers” 和 “window-timers”)TimerHeapInternalTimer的 hashCode 跟 (key, timestamp, namespace) 有关,也就回答了文档里说同一个 key + timestamp 会去重的问题了- time 的回调函数是固定的,这一点降低了实现的复杂度
InternalTimeServiceManagerImpl缓存了 name -> InternalTimerServiceImpl,那如果有两个 KeyedProcessOperator ,是否会导致异常?还是因为不会 chain 的一块,所以不会出现这种情况。- timer 的持久化是在
InternalTimerServiceImpl实现的 SystemProcessingTimeService回归到了我们最自然理解的Timer,注册、回调等
一直以来,Flink 的代码我看的不多,这类大型工程,更适合的是一个兴趣小组,每个组员定期分享的模式,效率会高很多。经常是忙活一阵之后,发现新版本的变动已经很大了,兴趣索然。因此笔记不对的地方,也欢迎指正。
更重要的,是理解其实现的目的、思路和瓶颈,而不单纯是代码,以在必要时解决开源版本无法解决的问题,或者预判自己的场景里可能的瓶颈。