了解关系代数有助于从逻辑或者各类名词上理解 Calciate,惭愧的是我只记得学过高等代数、抽象代数,好在看了下影响不大,其实从使用关系数据库的时候就已经潜移默化的有这些概念了。
1. Relational Algebra
Relational algebra is at the heart of Calcite.
关系代数是跟 SQL 一一对应的,一条 SQL 查询语句,可以转换为一个由关系运算符组成的树。这么说可能有些读者没有准确的概念,举两个例子说明:
比如上一篇笔记里的 SQL:
SELECT name FROM EMPS WHERE EMPNO = 1
转化成关系代数:
π name
σ empno = 1 emps
图形化的结果:

其中 σ 对应了WHERE关键字,π 对应了SELECT
再看个复杂点的 SQL:
SELECT b.id,
b.title,
b.publish_year,
a.fname,
a.lname
FROM Book AS b
LEFT OUTER JOIN Author a
ON b.author_id = a.id
WHERE b.publish_year > 1830
ORDER BY b.id
转化成关系代数:
τ b . id
π b . id, b . title, b . publish_year, a . fname, a . lname
σ b . publish_year > 1830
(ρ b book ⋈oL b . author_id = a . id
ρ a author)
图形化的结果:

π = SELECT, σ = WHERE,ρ 对应 Rename,也就是表的别名,⋈oL 对应了 LEFT OUTER JOIN(也有的用 ⟕ 表示)
如果想直观的了解更多转换结果,可以在Query Converter网站上试验。
无论是关系数据库还是 Calcite,都依赖这个一一的转换关系。基于这层转换,从 SQL Query 就得到一个计算机可以理解的 Tree.
2. MySQL Arch
在 Calcite 之前 MySQL 就一直可以执行 SQL ,我们不妨先看看 MySQL 的架构:
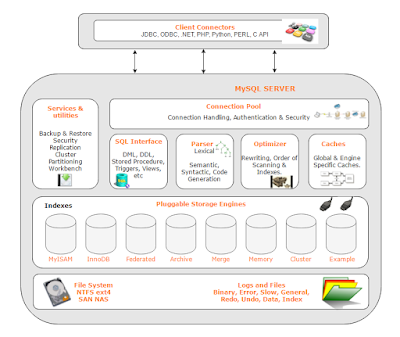
- Connection Pool:连接池、鉴权等
- SQL Interface → Parser → Optimizer : SQL 的解析和优化流程
- Caches & Pluggable Storage Engines: 结果缓存以及可插拔的存储引擎,比如常见的 InnoDB、MyISAM.
上篇笔记提到“One size fits all” is an idea whose time has come and gone”, MySQL 的这套架构,抽出部分来是否也能支持其他存储?是的,但是目标不同,所以发展思路不同。注意Pluggable的特性,更多的是把其他引擎作为插件,接口标准已经定义,不同引擎按照标准适配。
而 Calcite 的特性是flexible, embeddable, and extensible,是把自身作为一个插件嵌入到其他系统中,这种目标的不同,就会导致哪些接口开放、开放的形式不同。
3. Calcite Arch
再对比着看下 Calcite 的架构:
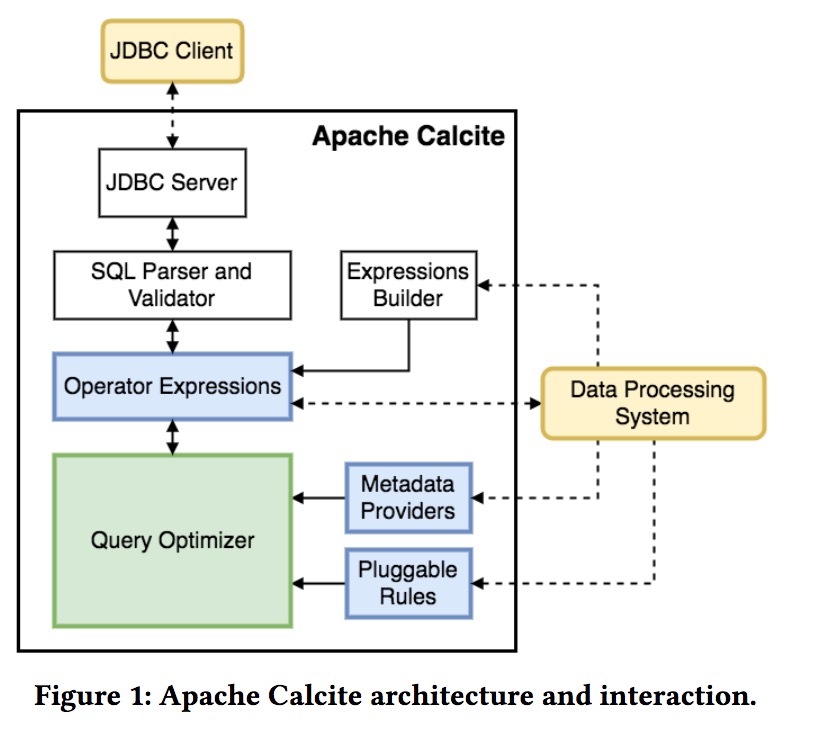
- 外部系统入口:
- JDBC Client: 通过类似sqlline的工具,SQL 作为入口
- Data Processing System: 通过直接构建 Expressions 来使用 Caclite
- 扩展:Operator Expressions/Metadata Providers/Pluggable Rules,外部系统接入时,可以扩展对应的接口,来提供更多的信息。
- 优化器:如果说关系代数是 Calcite 的心脏的话,Query Optimizer 就是 Calcite 的大脑,2扩展部分最终是为 Optimizer 服务的,以生成更符合自身的执行计划
不支持哪些部分?数据存储/元数据存储/数据处理等,比如 MySQL 架构里的 Storage Engines、Caches 等。
两者(保留核心+不支持数据处理相关)加起来,完成了”One Size”到”One Planner”的蜕变,使得 calcite “有能力”支持众多的数据存储和数据处理系统:
4. 处理流程
上一节的 Calcite 架构,在代码层面处理流程如下图所示:
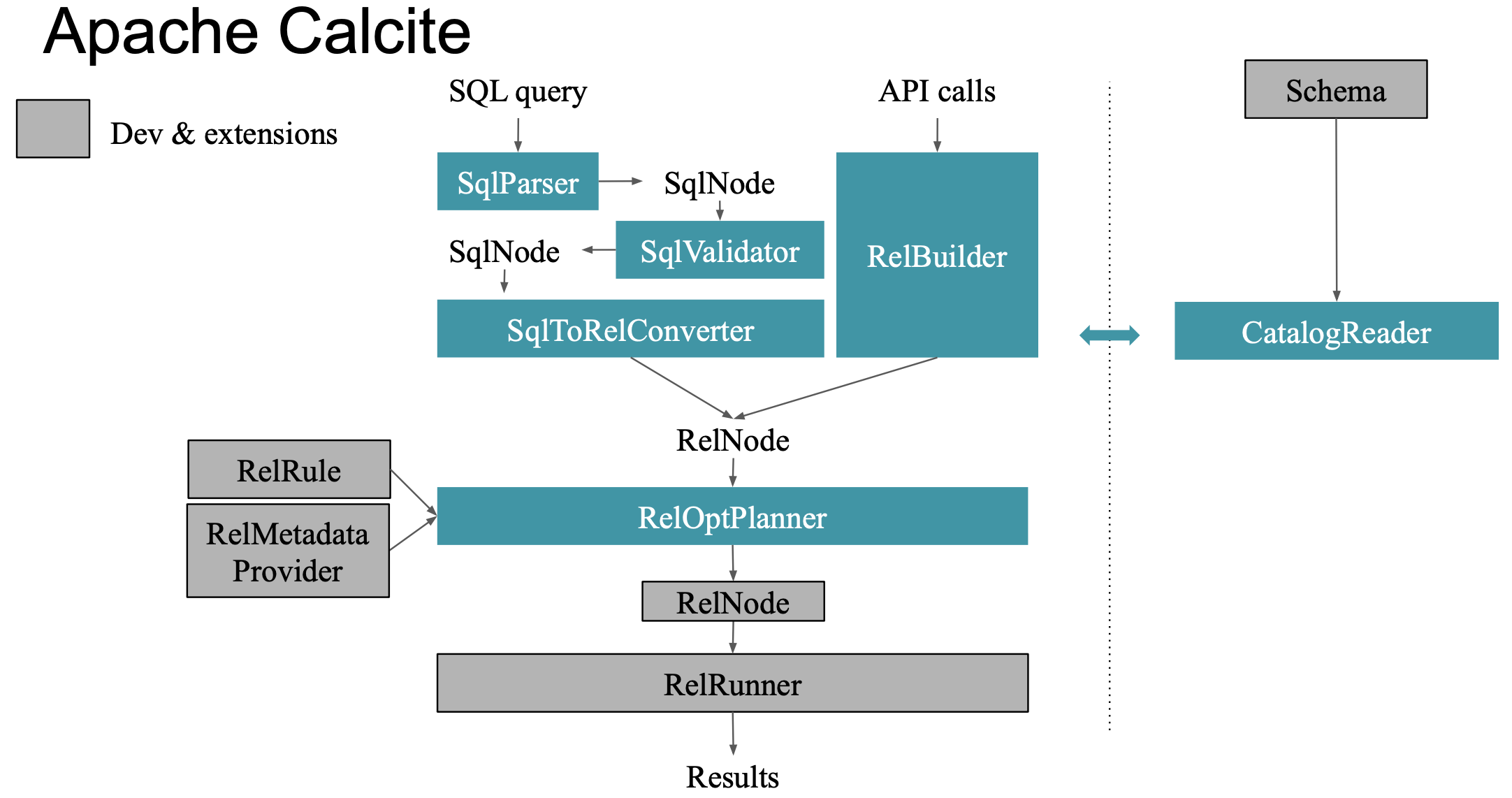
- SqlParser: Query → SqlNode,即查询字符串转换为一个 AST
- SqlValidator: SqlNode → SQLNode,判断 AST 是否合法,例如字段是否存在、类型是否一致等,因此该阶段会引入 CatalogReader
- SqlToRelConverter: SqlNode → RelNode,转换为一个关系运算符组成的树
- RelOptPlanner: RelNode → RelNode,根据规则优化树的节点组成,因此该阶段会引入 RelRule RelMetadataProvider
- RelRunner: 根据 RelNode 树执行的过程
注意还有一个入口是 API calls ,通过 RelBuilder 构造关系表达式。下一篇笔记,我们用实际代码来深入看看这套架构和处理流程。