最开始了解 Calcite 的时候,印象最深的是众多名词。而由于 Calcite 的定位,其应用方式又多种多样,所以有一种以为看懂了,却还是不知道如何应用的感觉。这篇笔记,记录下我对 Calcite 的理解。
1. 背景
2005年,Michael Stonebraker 发表了“One size fits all” is an idea whose time has come and gone,即传统关系型数据库一招吃遍天的时代过去了。
事实证明确实如此,随着数据量的增长,各种数据库层出不穷,各有所长。除非硬件突破,短时间内我们也很难看到一统江湖(One size fits all)的局面。
2015年,Julian Hyde 在 XLDB 上做了一次演讲,题为Apache Calcite: One planner fits all.这个题目可以理解成对上述论文的进一步阐述。
在数据库百花齐放时,也有一些是不变的,比如 SQL 的需求。SQL 的一大价值是用户的熟悉程度,即关系型数据库积累的经验和习惯。所以各种数据库都会提供 SQL(或者 SQL Like) 的交互方式。除了查询,流式数据处理也会有 SQL 需求,比如现在的 KSQL、SparkStreamingSQL、FlinkSQL.
那如何能够抽象出不变的部分,而通过接口/插件的形式支持异构的部分?Apache Calcite 正是预见了这一点,所以从 Hive 项目里独立出来,为更多的计算和存储提供统一的 SQL 查询解决方案。
在 Calcite 的 github 主页和论文里,这么一句话概括了 Calcite 的定位:
Apache Calcite is a dynamic data management framework.
2. Tutorial - 一个极简例子
在引入架构图以及不知所云的各种名词前,先通过一个官网文档例子看下。
./sqlline 2>/dev/null
sqlline> !connect jdbc:calcite:model=src/test/resources/model.json admin admin
0: jdbc:calcite:model=src/test/resources/mode> !tables
+-----------+-------------+------------+--------------+---------+----------+------------+-----------+---------------------------+----------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_CAT | TYPE_SCHEM | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION |
+-----------+-------------+------------+--------------+---------+----------+------------+-----------+---------------------------+----------------+
| | SALES | DEPTS | TABLE | | | | | | |
| | SALES | EMPS | TABLE | | | | | | |
| | SALES | SDEPTS | TABLE | | | | | | |
| | metadata | COLUMNS | SYSTEM TABLE | | | | | | |
| | metadata | TABLES | SYSTEM TABLE | | | | | | |
+-----------+-------------+------------+--------------+---------+----------+------------+-----------+---------------------------+----------------+
0: jdbc:calcite:model=src/test/resources/mode> SELECT * FROM emps;
+-------+-------+--------+--------+---------------+-------+------+---------+---------+------------+
| EMPNO | NAME | DEPTNO | GENDER | CITY | EMPID | AGE | SLACKER | MANAGER | JOINEDAT |
+-------+-------+--------+--------+---------------+-------+------+---------+---------+------------+
| 100 | Fred | 10 | | | 30 | 25 | true | false | 1996-08-03 |
| 110 | Eric | 20 | M | San Francisco | 3 | 80 | | false | 2001-01-01 |
| 110 | John | 40 | M | Vancouver | 2 | null | false | true | 2002-05-03 |
| 120 | Wilma | 20 | F | | 1 | 5 | | true | 2005-09-07 |
| 130 | Alice | 40 | F | Vancouver | 2 | null | false | true | 2007-01-01 |
+-------+-------+--------+--------+---------------+-------+------+---------+---------+------------+
0: jdbc:calcite:model=src/test/resources/mode> SELECT d.name, COUNT(*)
. . . . . . . . . . . . . . . . . . semicolon> FROM emps AS e JOIN depts AS d ON e.deptno = d.deptno
. . . . . . . . . . . . . . . . . . semicolon> GROUP BY d.name;
+-----------+--------+
| NAME | EXPR$1 |
+-----------+--------+
| Sales | 1 |
| Marketing | 2 |
+-----------+--------+
上面的例子里,calcite 支持了先connect model.json,然后使用 SQL 查询数据。
看下 model.json 文件:
{
"version": "1.0",
"defaultSchema": "SALES",
"schemas": [
{
"name": "SALES",
"type": "custom",
"factory": "org.apache.calcite.adapter.csv.CsvSchemaFactory",
"operand": {
"directory": "sales"
}
}
]
}
CsvSchemaFactory 是入口类,SQL 查询的表格式以及数据定义在 sales 目录下。文档中有一些介绍,补充一下 UML:
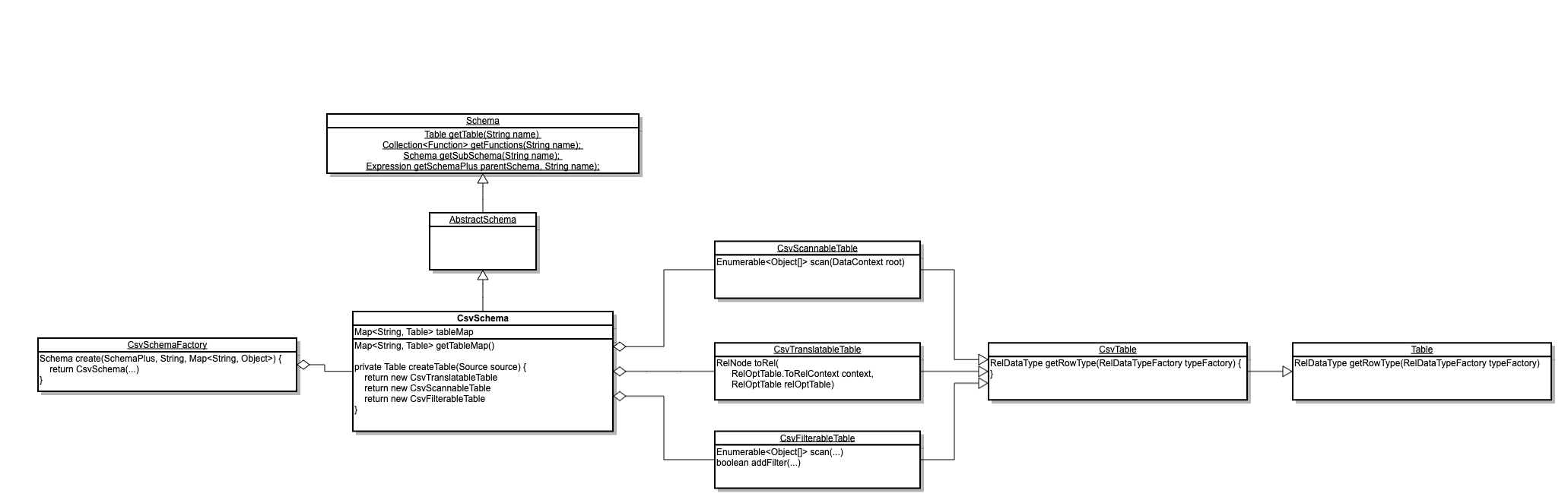
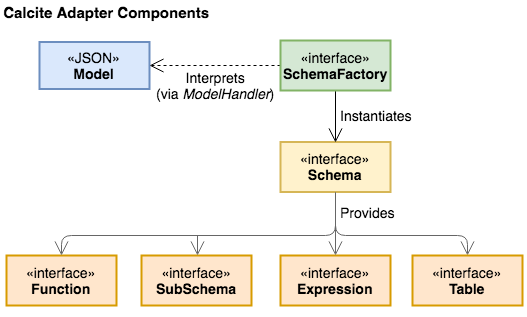
Calcite 作为框架本身不包含数据存储、数据处理的过程,重点是提供 SQL 解析、查询流程优化的能力,跟外部系统的对接是通过 Adapter 完成的。 对应这里就是CsvSchema,定义了Table Functions SubSchema Expressions。对照上面的 UML 图能够更好的理解论文里这个图:
这个例子就是通过定义一套 CSV 的 Adapter 来支持 SQL 查询本地 csv 文件这个“数据库”,而不用关心框架是如何一步步解析 SQL 并且调用用户的实现类的。
3. Tutorial - Optimizing
应用到实际场景必须引入一些优化规则,比如文档Optimizing queries using planner rules一节提到的:假定 emps 表有上百列,select name from emps;执行时是否能够支持只读取 name 这一列,无论对于列存储还是 IO 都会更友好。
3.1. CsvScannableTable
上一节的例子,CsvSchemaFactory构造的是CsvScannableTable,该类继承自 ScannableTable,实现了scan接口:
public Enumerable<Object[]> scan(DataContext root) {
final List<CsvFieldType> fieldTypes = getFieldTypes(root.getTypeFactory());
final List<Integer> fields = ImmutableIntList.identity(fieldTypes.size());
final AtomicBoolean cancelFlag = DataContext.Variable.CANCEL_FLAG.get(root);
return new AbstractEnumerable<Object[]>() {
public Enumerator<Object[]> enumerator() {
return new CsvEnumerator<>(source, cancelFlag, false, null,
CsvEnumerator.arrayConverter(fieldTypes, fields, false));
}
};
}
fieldTypes fields分别为表的全部字段类型及位置索引。
实际 scan 的过程在CsvEnumerator实现:读取磁盘上 csv 文件的每行数据,通过arrayConverter转换为一行结果数据,然后在下一步的执行方法里选出 name 列对应索引下标的值。
所以整个执行过程分为两部分:
sqlline> !connect jdbc:calcite:model=src/test/resources/model.json admin admin
sqlline> explain plan for select name from emps;
+-----------------------------------------------------+
| PLAN |
+-----------------------------------------------------+
| EnumerableCalc(expr#0..9=[{inputs}], NAME=[$t1]) |
| EnumerableTableScan(table=[[SALES, EMPS]]) |
+-----------------------------------------------------+
- 读取出全部数据
- 计算出需要的列
3.2. CsvTranslatableTable
smart.json 的执行计划对上述过程做了优化,CsvSchemaFactory构造的是CsvTranslatableTable,该类实现里相关的是project方法:
public Enumerable<Object> project(final DataContext root,
final int[] fields) {
final AtomicBoolean cancelFlag = DataContext.Variable.CANCEL_FLAG.get(root);
return new AbstractEnumerable<Object>() {
public Enumerator<Object> enumerator() {
return new CsvEnumerator<>(
source,
cancelFlag,
getFieldTypes(root.getTypeFactory()),
ImmutableIntList.of(fields));
}
};
}
该方法传入的fields值为[1],即 project 之后每行数据下标为 1 的字段值。
由于示例使用的 csv 文件,所以仍然是从磁盘文件读取每行数据。但是从接口层面上可以只传入 select 的列,以支持 Adapter 可能的数据读取优化方案。
通过 explain plan 可以看到调用了CsvTableScan直接获取 name 列的值:
sqlline> !connect jdbc:calcite:model=src/test/resources/smart.json admin admin
0: jdbc:calcite:model=src/test/resources/smar> explain plan for select name from emps;
+----------------------------------------------------+
| PLAN |
+----------------------------------------------------+
| CsvTableScan(table=[[SALES, EMPS]], fields=[[1]]) |
+----------------------------------------------------+
SQL 解析部分,Calcite 是使用 JavaCC 实现的,将 SQL 语句转化为 Java 代码,然后进一步转化为 AST.后续执行部分,则是使用了 Janino 支持运行时编译 Java 代码。
文档接下来用了比较短的篇幅介绍了跟CsvProjectTableScanRule有关,但是我看到这儿的时候还是有很多疑问,比如:
- Rule 是如何生效的,为什么 Plan 会不同,背后流程是什么样的?
- SQL 是如何转换为代码的
- 很多文章里提到 Parse/Validate/Optimize,SqlNode/RelNode/RexNode 具体指什么?
- 不同的场景应该如何使用 Calcite,嵌入到什么程度,比如 Drill Flink 是如何使用 Calcite 的?sqlline 是必须的么?
- Calcite 的 flexible, embeddable, and extensible 体现在哪?
- 想要自己实现其他优化的 Rule 应该如何做?