单纯看Calcite-2里的架构图理解不深,这篇笔记通过代码示例补充下 SqlParser、SqlValiator、SqlToRelConverter 等的处理流程。
实现主要参考了1和源码单测里的CsvTest,使用 Book & Author 表,查询 SQL 跟关系代数里基本一致以方便前后对比,完整的代码可以参考CalciteProcessSteps.scala
1. SqlParser
val query =
"""SELECT b.id,
| b.title,
| b.publish_year,
| a.fname,
| a.lname
|FROM Book AS b
|LEFT OUTER JOIN Author a
| ON b.author_id = a.id
|WHERE b.publish_year > 1830
|ORDER BY b.id LIMIT 5
|""".stripMargin
// parse: sql -> SqlNode
val sqlParser = SqlParser.create(query)
val sqlNodeParsed = sqlParser.parseQuery()
println(s"[Parsed query]\n${sqlNodeParsed}")
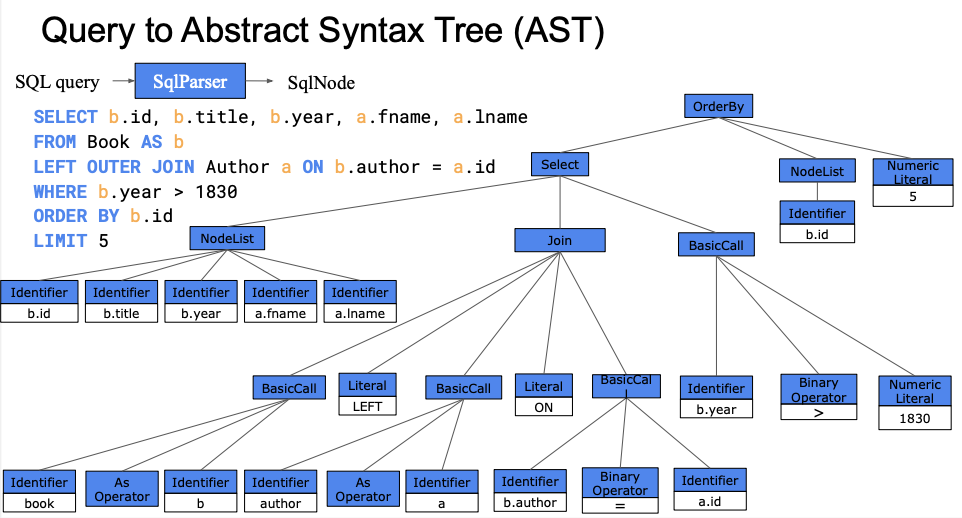
解析阶段不需要引入依赖,代码只要几行,主要是将 Query 解析为各类 SqlNode,结果保存到以 sqlNodeParsed 为根节点的一棵语法树:
sqlNodeParsed(SqlOrderBy)
├── query(SqlSelect)
│ ├── keyWordList(SqlNodeList)
│ ├── selectList(SqlNodeList)
│ ├── from(SqlJoin)
│ │ ├── left(SqlBasicCall)
│ │ ├── right(SqlBasicCall)
│ │ ├── condition(SqlBasicCall)
│ │ ├── joinType(SqlLiteral)
│ │ ├── ...
│ ├── where(SqlBasicCall)
│ ├── ...
├── orderList(SqlNodeList)
├── fetch(SqlNumericLiteral)
用图表示的话:
2. SqlValidator
合法性检测,需要检查表名、字段名、字段类型等,因此这个阶段代码稍微复杂一点,需要引入表结构。使用到的两张表结构如下:
Book表结构:
| 字段名 | 字段类型 |
|---|---|
| id | int |
| title | string |
| price | decimal |
| publish_year | int |
| author_id | int |
Author表结构:
| 字段名 | 字段类型 |
|---|---|
| id | int |
| fname | string |
| lname | string |
| birth | date |
// 参考第一篇笔记里的 CsvSchema 初始化 author book 表,resources/book_author 目录
val rootSchema = Frameworks.createRootSchema(true)
val csvPath = getClass.getClassLoader.getResource("book_author").getPath
val csvSchema = new CsvSchema(new File(csvPath.toString), CsvTable.Flavor.SCANNABLE)
rootSchema.add("author", csvSchema.getTable("author"))
rootSchema.add("book", csvSchema.getTable("book"))
val sqlTypeFactory = new JavaTypeFactoryImpl()
val properties = new Properties()
properties.setProperty(CalciteConnectionProperty.CASE_SENSITIVE.camelName(), "false")
// reader 接收 schema,用于检测字段名、字段类型、表名等是否存在和一致
val catalogReader = new CalciteCatalogReader(
CalciteSchema.from(rootSchema),
CalciteSchema.from(rootSchema).path(null),
sqlTypeFactory,
new CalciteConnectionConfigImpl(properties))
// 简单示例,大部分参数采用默认值即可
val validator = SqlValidatorUtil.newValidator(
SqlStdOperatorTable.instance(),
catalogReader,
sqlTypeFactory,
SqlValidator.Config.DEFAULT)
// validate: SqlNode -> SqlNode
val sqlNodeValidated = validator.validate(sqlNodeParsed)
println(s"[Validated query]\n${sqlNodeParsed}")
结果跟 parse 差别不大
[Validated query]
SELECT `B`.`ID`, `B`.`TITLE`, `B`.`PUBLISH_YEAR`, `A`.`FNAME`, `A`.`LNAME`
FROM `BOOK` AS `B`
LEFT JOIN `AUTHOR` AS `A` ON `B`.`author_id` = `A`.`id`
WHERE `B`.`publish_year` > 1830
ORDER BY `B`.`id`
FETCH NEXT 5 ROWS ONLY
ORDER BY `B`.`ID`
FETCH NEXT 5 ROWS ONLY
主要是引入了:
- CalciteSchema.SchemaPlusImpl: 记录了 csvSchema, csvSchema 又记录了表的 schema
- CalciteCatalogReader: 读取 schema,传入了 JavaTypeFactoryImpl,该类支持创建 RelDataType 类型,例如
sqlTypeFactory.createSqlType(SqlTypeName.TIMESTAMP) sqlTypeFactory.createStructType(Pair.zip(names, types)) - SqlValidator:
validate方法校验 SqlNode
3. SqlToRelConverter
val rexBuilder = new RexBuilder(sqlTypeFactory)
val hepProgramBuilder = new HepProgramBuilder()
hepProgramBuilder.addRuleInstance(CoreRules.FILTER_INTO_JOIN)
val hepPlanner = new HepPlanner(hepProgramBuilder.build())
hepPlanner.addRelTraitDef(ConventionTraitDef.INSTANCE)
val relOptCluster = RelOptCluster.create(hepPlanner, rexBuilder)
val sqlToRelConverter = new SqlToRelConverter(
// 没有使用 view
new ViewExpander {
override def expandView(rowType: RelDataType, queryString: String, schemaPath: util.List[String], viewPath: util.List[String]): RelRoot = null
},
validator,
catalogReader,
relOptCluster,
// 均使用标准定义即可
StandardConvertletTable.INSTANCE,
SqlToRelConverter.config())
var logicalPlan = sqlToRelConverter.convertQuery(sqlNodeValidated, false, true).rel
println(RelOptUtil.dumpPlan("[Logical plan]", logicalPlan, SqlExplainFormat.TEXT, SqlExplainLevel.NON_COST_ATTRIBUTES))
这一步则由语法树转换为了关系运算符组成的树,即 SqlNode -> RelNode:
[Logical plan]
LogicalSort(sort0=[$0], dir0=[ASC], fetch=[5]), id = 8
LogicalProject(ID=[$0], TITLE=[$1], PUBLISH_YEAR=[$3], FNAME=[$6], LNAME=[$7]), id = 7
LogicalFilter(condition=[>($3, 1830)]), id = 6
LogicalJoin(condition=[=($4, $5)], joinType=[left]), id = 5
LogicalTableScan(table=[[book]]), id = 1
LogicalTableScan(table=[[author]]), id = 3
用图表示的话:
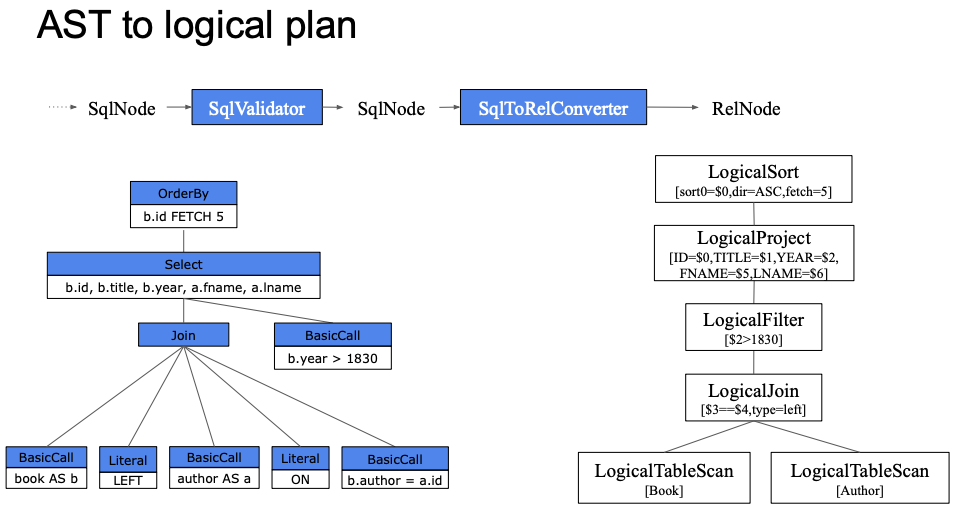
到这一步,其实我们发现跟关系运算树在逻辑上是一致的,只是用计算机的语言表达了出来。
4. RelOptPlanner
这一步即优化部分,比如我们在第一篇笔记里提到的,扫描各表时,仅获取需要的列。
在这个例子里,观察上一节的图,还有一个比较明显的优化手段,就是扫描 Book 表时,提前应用b.publish_year > 1830这个条件,减少 b 表的 IO。这个想法,对应就是 Calcite 的内置FilterIntoJoinRule规则。我们在一节构造hepPlanner时已经加进来了,这里看下优化后的效果:
// Start the optimization process to obtain the most efficient physical plan based on the
// provided rule set.
hepPlanner.setRoot(logicalPlan)
val phyPlan = hepPlanner.findBestExp()
println(RelOptUtil.dumpPlan("[Physical plan]", phyPlan, SqlExplainFormat.TEXT, SqlExplainLevel.NON_COST_ATTRIBUTES))
对比 Logical Plan 和 Physical Plan,LogicalFilter下推到了 Scan 阶段:
[Physical plan]
LogicalSort(sort0=[$0], dir0=[ASC], fetch=[5]), id = 17
LogicalProject(ID=[$0], TITLE=[$1], PUBLISH_YEAR=[$3], FNAME=[$6], LNAME=[$7]), id = 15
LogicalJoin(condition=[=($4, $5)], joinType=[left]), id = 22
LogicalFilter(condition=[>($3, 1830)]), id = 19
LogicalTableScan(table=[[book]]), id = 1
LogicalTableScan(table=[[author]]), id = 3
Rule 优化就跟第三方的实现有关了,比如在看阿里 MaxCompute 时就提到过优化 MergeJoin + GroupAggregate 算子。我的理解是,MergeJoin 算子需要提前对字段排序,两个表的字段如果在同一区间,就需要分配到同一实例实现拉链式 Join. 而该字段的相同值分配到同一实例后,GroupAggregate 算子就可以局部聚合而不影响准确性,因此也可以下推到跟 MergeJoin 算子同时进行,避免了全局的多次排序。
可见其思路也是尽量降低不必要的 IO,我觉得跟Z-Order一样,核心思想是 DataSkipping,对应到 SQL 的优化手段就是谓词下推(Predicate Pushdown - CoreRules.FILTER_INTO_JOIN)、常量折叠(Constant Folding - CoreRules.PROJECT_REDUCE_EXPRESSIONS)、列裁剪(Column Pruning)等。
5. RelBuilder
在 Calcite 的架构图里,还有一个入口是 Expressions Builder (RelBuilder),即不通过 SQL 直接构建关系运算符的树结构。
写了一个代码示例:
val rootSchema = Frameworks.createRootSchema(true)
val csvPath = getClass.getClassLoader.getResource("book_author").getPath
val csvSchema = new CsvSchema(new File(csvPath.toString), CsvTable.Flavor.SCANNABLE)
rootSchema.add("author", csvSchema.getTable("author"))
rootSchema.add("book", csvSchema.getTable("book"))
val frameworkConfig = Frameworks.newConfigBuilder()
.parserConfig(SqlParser.Config.DEFAULT)
.defaultSchema(rootSchema)
.build()
val relBuilder = RelBuilder.create(frameworkConfig)
val node = relBuilder
.scan("book")
.scan("author")
.join(JoinRelType.LEFT, "id")
.filter(
relBuilder.call(SqlStdOperatorTable.GREATER_THAN,
relBuilder.field("publish_year"),
relBuilder.literal(1830)))
.project(
relBuilder.field("id"),
relBuilder.field("title"),
relBuilder.field("publish_year"),
relBuilder.field("lname"),
relBuilder.field("fname"))
.sortLimit(0, 5, relBuilder.field("id"))
.build()
println(RelOptUtil.toString(node))
可见整体流程是是类似的,省了 SQL 解析成 AST 的部分,效果上跟第一节里的 SQL 也基本一致(JOIN 条件没有看懂应该如何指定不同的字段名)。感兴趣的可以看下源码里RelBuilderExample这个类。
6. SqlNode RelNode RexNode
通过前面的示例,总结下代码里这三种 Node 的区别:
- SqlNode 是 Parse、Validate 阶段的结果,对应 SQL 转换为语法树后的每个节点,例如 SqlSelect SqlJoin.
- RelNode 是 SqlToRelConverter、Optimize 阶段的结果,对应语法树转换为关系运算符的节点,例如 LogicalProject LogicalJoin,这些节点操作的都是集合,是关系代数运算符的一种,即 relational expression.
- RexNode 跟 RelNode 位于同一阶段,操作的是数据本身,例如
limit 5里的 5 是RexLiteral,b.publish_year > 1830、b.author_id = a.id都是RexCall,对应常量、函数的表达式,即 Expression Node.
引用4的一段话来总结下:
SqlNode is the abstract syntax tree that represents the actual structure of the query a user input. When a query is first parsed, it’s parsed into a SqlNode. For example, a SELECT query will be parsed into a SqlSelect with a list of fields, a table, a join, etc. Calcite is also capable of generating a query string from a SqlNode as well.
RelNode represents a relational expression - hence “rel.” RelNodes are used in the optimizer to decide how to execute a query. Examples of relational expressions are join, filter, aggregate, etc. Typically, specific implementations of RelNode will be created by users of Calcite to represent the execution of some expression in their system. When a query is first converted from SqlNode to RelNode, it will be made up of logical nodes like LogicalProject, LogicalJoin, etc. Optimizer rules are then used to convert from those logical nodes to physical ones like JdbcJoin, SparkJoin, CassandraJoin, or whatever the system requires. Traits and conventions are used by the optimizer to determine the set of rules to apply and the desired outcome, but you didn’t ask about conventions :-)
RexNode represents a row expression - hence “Rex” - that’s typically contained within a RelNode. The row expression contains operations performed on a single row. For example, a Project will contain a list of RexNodes that represent the projection’s fields. A RexNode might be a reference to a field from an input to the RedNode, a function call (RexCall), a window (RexOver), etc. The operator within the RexCall defines what the node does, and operands define arguments to the operator. For example, 1 + 1 would be represented as a RexCall where the operator is + and the operands are 1 and 1.