1. Csv表
之前记录了 Calcite 的架构和简化后的代码流程,这篇笔记回归下最开始Tutorial笔记里的 Csv 表,仿照写了一个可以 Debug 的例子(TutorialTest.scala):
val csvPath = getClass.getClassLoader.getResource("sales_from_calcite_sources").getPath
// val csvSchema = new CsvSchema(new File(csvPath), CsvTable.Flavor.SCANNABLE)
val csvSchema = new CsvSchema(new File(csvPath), CsvTable.Flavor.TRANSLATABLE)
val properties = new Properties()
properties.setProperty("caseSensitive", "false")
val connection = DriverManager.getConnection("jdbc:calcite:", properties)
val calciteConnection = connection.unwrap(classOf[CalciteConnection])
val rootSchema = calciteConnection.getRootSchema
rootSchema.add("sales", csvSchema)
query("SELECT empno, name, deptno FROM sales.emps WHERE deptno > 20")
def query(sql: String): Unit = {
println(s"****** $sql ******")
val statement = calciteConnection.createStatement()
val resultSet = statement.executeQuery(sql)
dumpResultSet(resultSet)
}
分别创建 SCANNABLE or TRANSLATABLE 的表,通过executeQuery执行 SQL,结果存储到ResultSet
源数据跟 Calcite 源码数据里一致,程序输出:
****** SELECT empno, name, deptno FROM sales.emps WHERE deptno > 20 ******
EMPNO:110 NAME:John DEPTNO:40
EMPNO:130 NAME:Alice DEPTNO:40
executeQuery的实现里,能够看到对应的一直到生成 RelRoot 的几个核心步骤:

不过结果查询出来存储到ResultSet,光生成到关系运算符的树不够,还需要代码生成和编译的环节。我在应用 FlinkSQL 的时候,遇到问题,第一时间还是想看到代码反查问题。
2. 编译: Janino
Calcite 使用 Janino[1] 编译 Java 代码,Janino 可以比较方便的执行一段 Java 的表达式、代码、或者获取编译后的符号。
基本流程都是类似的,根据不同需求初始化不同的 Evaluator,然后编译或者运行。看下常见的几个用法:
2.1. ExpressionEvaluator
public static void ExpressionEvaluator() {
try {
IExpressionEvaluator ee = CompilerFactoryFactory.getDefaultCompilerFactory().newExpressionEvaluator();
ee.setExpressionType(int.class);
ee.setParameters(
new String[] {"a", "b"},
new Class[] {int.class, int.class}
);
ee.cook("a + b");
Integer res = (Integer) ee.evaluate(
new Object[] {10, 11}
);
System.out.println("res = " + res);
} catch (Exception e) {
e.printStackTrace();
}
}
执行表达式a+b,输出结果:res = 21
2.2. ScriptEvaluator
public static void ScriptEvaluator() {
try {
IScriptEvaluator se = CompilerFactoryFactory.getDefaultCompilerFactory().newScriptEvaluator();
se.setReturnType(boolean.class);
se.cook("static void method1() {\n"
+ " System.out.println(1);\n"
+ "}\n"
+ "\n"
+ "method1();\n"
+ "method2();\n"
+ "\n"
+ "static void method2() {\n"
+ " System.out.println(2);\n"
+ "}\n"
+ "return true;\n"
);
Object res = se.evaluate(new Object[0]);
System.out.println("res = " + res);
} catch (Exception e) {
e.printStackTrace();
}
}
执行给定的代码字符串,输出结果:
1
2
res = true
2.3. ClassBodyEvaluator
public static void ClassBodyEvaluator() {
try {
IClassBodyEvaluator cbe = CompilerFactoryFactory.getDefaultCompilerFactory().newClassBodyEvaluator();
String code = ""
+ "public static void main(String[] args) {\n"
+ " System.out.println(java.util.Arrays.asList(args));\n"
+ "}";
cbe.cook(code);
Class<?> c = cbe.getClazz();
Method mainMethod = c.getMethod("main", String[].class);
String[] args = {"Hello", "World", "Hello", "Janino"};
mainMethod.invoke(null, (Object)args);
} catch (Exception e) {
e.printStackTrace();
}
}
提取代码片段里的main方法,执行后输出结果:[Hello, World, Hello, Janino]
2.4. SimpleCompilerEvaluator
public static void SimpleCompilerEvaluator() {
try {
ISimpleCompiler simpleCompiler = CompilerFactoryFactory.getDefaultCompilerFactory().newSimpleCompiler();
String code = "" +
"public class Foo {\n" +
" public static void main(String[] args) {\n" +
" new Bar().meth(\"Foo\");\n" +
" }\n" +
"}\n" +
"\n" +
"public class Bar {\n" +
" public void meth(String who) {\n" +
" System.out.println(\"Hello! \" + who);\n" +
" }\n" +
"}";
simpleCompiler.cook(code);
Class<?> fooClass = simpleCompiler.getClassLoader().loadClass("Foo");
fooClass.getDeclaredMethod("main", String[].class).invoke(null, (Object)new String[]{"hello", "world"});
Class<?> barClass = simpleCompiler.getClassLoader().loadClass("Bar");
barClass.getDeclaredMethod("meth", String.class).invoke(barClass.newInstance(), "Janino");
} catch (Exception e) {
e.printStackTrace();
}
}
跟上一节类似,提取代码片段里的类及方法,输出结果:
Hello! Foo
Hello! Janino
3. 代码生成: Expressions
Expressions源码来自于 linq4j,是 Julian Hyde 的个人项目,用于生成代码。
我们写代码时,常量、变量、参数、循环、函数、类等,都可以通过Expressions的子类表示出来,然后生成为一段代码。
假定我们想要生成这么一段 Hello World 的待执行代码:
public class MyHelloWorld implements java.io.Serializable {
public static void hello(String who) {
System.out.println("Hello World, " + who + "!");
}
}
需要将代码块里的所有元素拆解为Expressions对应的子类,比如:
- ConstantExpression: 例如字符串”Hello World, “、”!”
- ParameterExpression: 例如
String who - MemberExpression: 例如
System.out - MethodCallExpression: 例如
println - MethodDeclaration、ClassDeclaration等
完整的映射关系为:
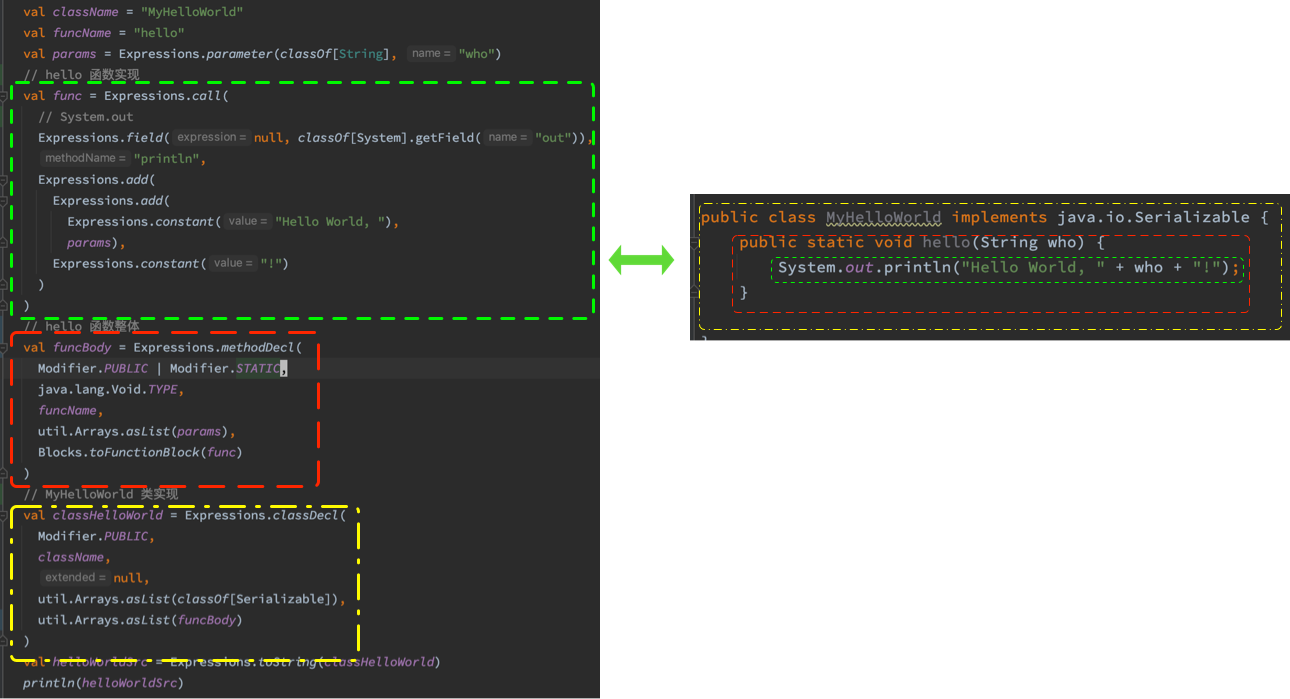
然后通过上一节的SimpleCompiler编译:
val sc = CompilerFactoryFactory.getDefaultCompilerFactory.newSimpleCompiler
sc.cook(helloWorldSrc)
val helloWorldClass = sc.getClassLoader.loadClass(className)
helloWorldClass.getMethod(funcName, classOf[String]).invoke(null, "Expressions")
程序输出:
public class MyHelloWorld implements java.io.Serializable {
public static void hello(String who) {
System.out.println("Hello World, " + who + "!");
}
}
Hello World, Expressions!
具体代码: ExpressionsHelloWorld.scala,更多Expressions的用法可以参考ExpressionTest这个单测的实现。
4. Calcite 源码分析
如第一节里的处理流程,代码生成在implement(root)部分,入口类是CalcitePrepareImpl,核心实现在EnumerableRelImplementor.implementRoot.
该方法首先调用 root 节点的implement,由于是树的结构,接下来会循环调用子节点(input)的implement方法:
对应第一节的例子,一共有两个节点:
EnumerableCalc.ENUMERABLE.[](input=CsvTableScan#25,expr#0..2={inputs},expr#3=20,expr#4=>($t2, $t3),proj#0..2={exprs},$condition=$t4)
CsvTableScan.ENUMERABLE.[](table=[sales, EMPS],fields=[0, 1, 2])
root 节点是EnumerableCalc,递归调用CsvTableScan的implement方法,也是用户需要自己实现的:
public class CsvTableScan extends TableScan implements EnumerableRel {
...
public Result implement(EnumerableRelImplementor implementor, Prefer pref) {
PhysType physType =
PhysTypeImpl.of(
implementor.getTypeFactory(),
getRowType(),
pref.preferArray());
if (table instanceof JsonTable) {
return implementor.result(
physType,
Blocks.toBlock(
Expressions.call(table.getExpression(JsonTable.class),
"enumerable")));
}
return implementor.result(
physType,
Blocks.toBlock(
Expressions.call(table.getExpression(CsvTranslatableTable.class),
"project", implementor.getRootExpression(),
Expressions.constant(fields))));
}
...
}
Blocks.toBlock 生成了这样一段代码:
{
return ((org.apache.calcite.adapter.csv.CsvTranslatableTable) root.getRootSchema().getSubSchema("sales").getTable("EMPS")).project(root, new int[] {
0,
1,
2});
}
可以看到调用了CsvTranslatable.project方法,也是需要用户自定义实现的:
@SuppressWarnings("unused") // called from generated code
public Enumerable<Object> project(final DataContext root,
final int[] fields) {
final AtomicBoolean cancelFlag = DataContext.Variable.CANCEL_FLAG.get(root);
return new AbstractEnumerable<Object>() {
public Enumerator<Object> enumerator() {
return new CsvEnumerator<>(
source,
cancelFlag,
getFieldTypes(root.getTypeFactory()),
ImmutableIntList.of(fields));
}
};
}
如注释所说,是在生成代码里调用的。接着会生成调用current moveNext遍历数据的代码。Debug 时,你可能会看到很多Baz的类名,也能够顺着找到出处。
以上步骤里有好几处都会自动生成代码,感兴趣的可以参考[2]的方式将生成代码打印出来。
EnumerableInterpretable.getBindable对应了编译部分,使用IClassBodyEvaluator,通过 Debug 第一节的例子完整的看遍执行流程效果会更好,不再赘述。