文件存储格式,即数据在磁盘上是如何组织的,比如 leveldb 的 sst 文件由 DataBlock、FilterBlock、IndexBlock、Footer 等组成。这种格式的设计,适应了单机写多读少、读取新写入数据的场景。
{kind=link}
1. 大数据为何偏爱列存储
Apache ORC、Apache Parquet 都是典型的列存储格式,大数据的场景,为何偏爱列存储?
首先无论场景如何变化,从单机到大数据,面临的磁盘性能是一致的,引用 Jeff Dean 演讲的数据1:
Latency Comparison Numbers (~2012)
| Operation | Time in Nano Seconds |
|---|---|
| L1 cache reference | 0.5 ns |
| Branch mispredict | 5 ns |
| L2 cache reference | 7 ns |
| Mutex lock/unlock | 25 ns |
| Main memory reference | 100 ns |
| Compress 1K bytes with Zippy | 3,000 ns |
| Send 1K bytes over 1 Gbps network | 10,000 ns |
| Read 4K randomly from SSD | 150,000 ns |
| Read 1 MB sequentially from memory | 250,000 ns |
| Round trip within same datacenter | 500,000 ns |
| Read 1 MB sequentially from SSD* | 1,000,000 ns |
| Disk seek | 10,000,000 ns |
| Read 1 MB sequentially from disk | 20,000,000 ns |
| Send packet CA->Netherlands->CA | 150,000,000 ns |
也就是磁盘顺序读性能远远大于 seek.
提到列存储,普遍认知第一个优势是 IO。大数据表列数很多,但是查询时往往只用到少数几列,只需要读取更少的列,因此 IO 效率更高。
SIGMOD 2008 有一篇论文: Column-Stores vs. Row-Stores: How Different Are They Really?2 3,总结了以下四点。
首先是 Block iteration: 块遍历,每次读取的数据格式相同,可以充分利用现代 CPU 的 SIMD 指令集加速计算。当然这一点需要跟计算引擎的向量化充分结合。后续各类计算引擎的向量化实现、Vector/Array 数据结构的设计,也都证明了这一点。
其次是 Column-specific compression techniques: low information entropy,相同格式的数据压缩比更高。即使不采用压缩,一些算法例如 run-length encoding. 在存储(Disk/Mem)空间更小的前提下不会增加常见算法的复杂度,如果某一列的数据有序、或者前缀相同,那么效果会更好。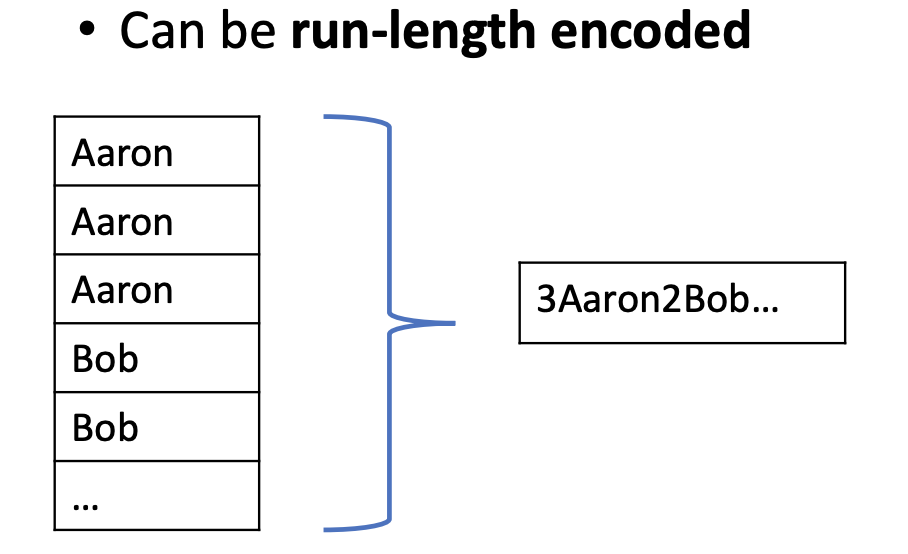
然后是 Late materialization: 列存储能够更好的应用延迟物化技术,例如 Traditional Query Plan VS Late Materialized Query Plan:
 VS
VS

放到现在看主要就是 bitmap、谓词下推等方案。 优势在于:
- Selection 和 Aggregation 操作时:尽可能的降低传递 Tuple 的大小和个数,最好读取时就过滤、聚合。(Selection and aggregation operators tend to reduce the number of tuples which need to be constructed)
- 前面提到了压缩降低了空间占用,但是解压同样消耗 CPU,延迟物化可以屏蔽掉这个隐患。(Data compressed using column-oriented compression methods must be decompressed during the tuple construction process)
- Cache performance improved: 这里说的 cache 是前面提到的 L1/L2 Cache,相同格式的数据,cache 容易对齐且一次性加载到了 Cache Line.
最后一点是 Invisible Join,看着还是延迟物化思想的进一步阐述。
这几点总结的都很有道理,不过反过来,Row-Stores 可以模拟出 Column-Stores 的这些效果么?文章总结了几个方案:
- Vertical Partitioning
- Index-Only Plans
- Materialized Views
但是由于存储、I/O、应用场景限制等,很难达到 Column-Stores 的性能。
两者各有擅长的场景: 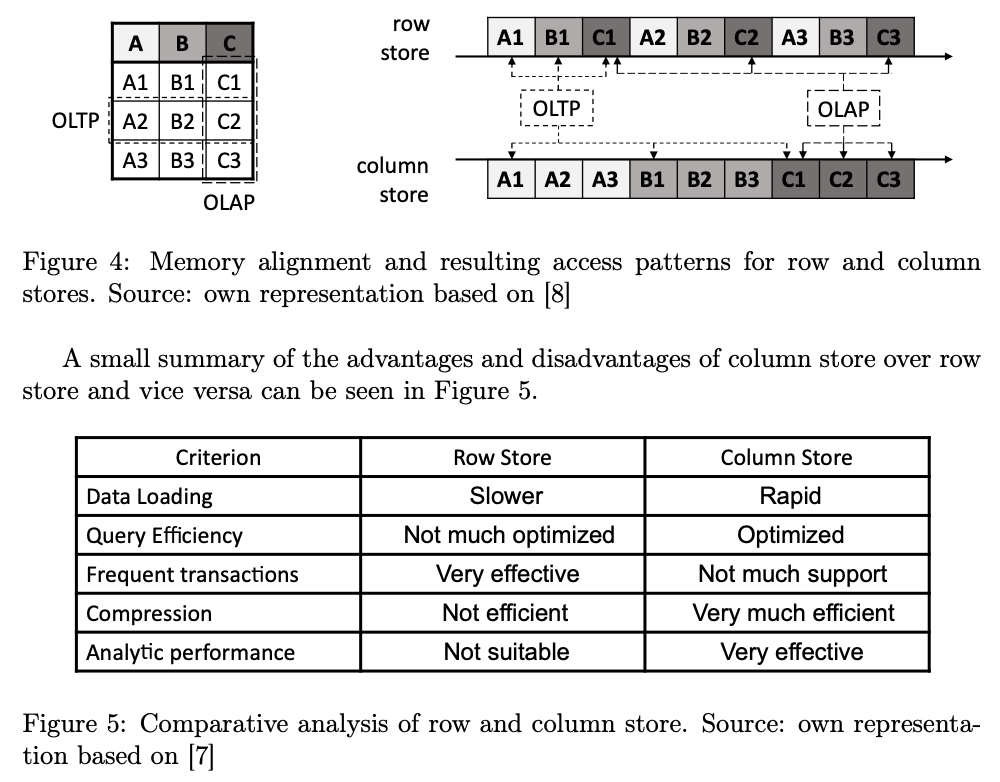
2. Apache ORC
2.1. 文件结构
ORC(Optimized Row Columnar)是在 Hive 项目里引入的4,文件结构包括三部分:
- Stripe:
- Index Data: 每列的最大值、最小值、the row positions within each column、以及可能的 BloomFilter.
- Row Data: 数据本身
- Stripe Footer: a directory of stream locations
- File Footer: ORC File文件主体的布局,包括schema信息、行总数、每行的统计信息等。
- PostScript: ORC文件级别的元信息,包括footer长度、ORC版本号、采用的压缩算法等
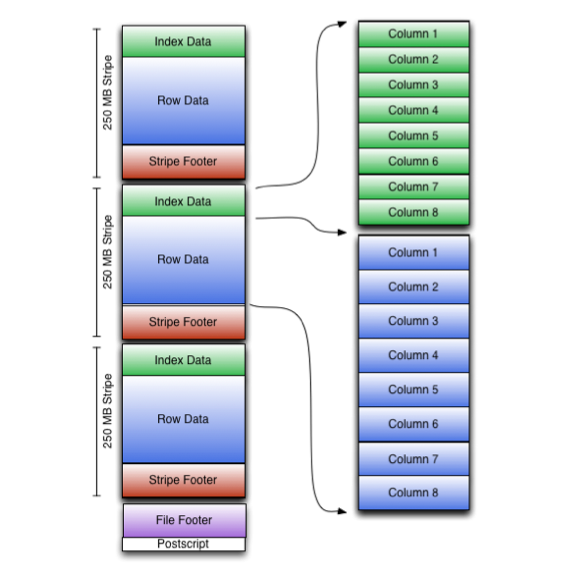
ORC 文件有三个级别的索引:文件级别、stripe级别、行级别(每10000行)。
更多细节可以参考 ORCv15
2.2. 代码示例
ORC 提供了多种写入方式, Spark、Hive、PyArrow 等,这里以 Core Java 为例:
public static void orcWriterSample() throws IOException {
Path testFilePath = new Path("/tmp/people.orc");
// 文件结构
TypeDescription schema = TypeDescription.fromString(
"struct<name:string,location:map<string,string>,birthday:date,last_login:timestamp>"
);
Configuration conf = new Configuration();
FileSystem.getLocal(conf);
Faker faker = new Faker();
try (Writer writer =
OrcFile.createWriter(testFilePath,
OrcFile.writerOptions(conf).setSchema(schema))) {
// 创建 row batch,每一列通过单独的 ColumnVector 写入
VectorizedRowBatch batch = schema.createRowBatch();
BytesColumnVector name = (BytesColumnVector) batch.cols[0];
MapColumnVector location = (MapColumnVector) batch.cols[1];
LongColumnVector birthday = (LongColumnVector) batch.cols[2];
TimestampColumnVector last_login = (TimestampColumnVector) batch.cols[3];
BytesColumnVector mapKey = (BytesColumnVector) location.keys;
BytesColumnVector mapValue = (BytesColumnVector) location.values;
// Each map has 2 elements
final int MAP_SIZE = 2;
final int BATCH_SIZE = batch.getMaxSize();
System.out.println("BATCH_SIZE : " + BATCH_SIZE);
// Ensure the map is big enough
mapKey.ensureSize(BATCH_SIZE * MAP_SIZE, false);
mapValue.ensureSize(BATCH_SIZE * MAP_SIZE, false);
// 写入 1500 行数据
for (int i = 0; i < 1500; i++) {
int row = batch.size++;
name.setVal(row, faker.name().fullName().getBytes());
birthday.vector[row] = DateWritable.dateToDays(new java.sql.Date(faker.date().birthday(1, 123).getTime()));
last_login.time[row] = faker.date().past(10, TimeUnit.DAYS).getTime();
location.offsets[row] = location.childCount;
location.lengths[row] = MAP_SIZE;
location.childCount += MAP_SIZE;
mapKey.setVal((int) location.offsets[row], "country".getBytes());
mapValue.setVal((int) location.offsets[row], faker.country().name().getBytes());
mapKey.setVal((int) location.offsets[row] + 1, "address".getBytes());
mapValue.setVal((int) location.offsets[row] + 1, faker.address().streetAddress().getBytes());
if (row == BATCH_SIZE - 1) {
writer.addRowBatch(batch);
batch.reset();
}
}
if (batch.size != 0) {
writer.addRowBatch(batch);
batch.reset();
}
}
}
orc-tools 可以读取数据、元数据等一系列信息:
➜ Downloads java -jar orc-tools-1.9.2-uber.jar meta /tmp/people.orc (0s)[12:52:40]
Processing data file /tmp/people.orc [length: 41072]
Structure for /tmp/people.orc
File Version: 0.12 with ORC_517 by ORC Java
[main] INFO org.apache.orc.impl.ReaderImpl - Reading ORC rows from /tmp/people.orc with {include: null, offset: 0, length: 9223372036854775807, includeAcidColumns: true, allowSARGToFilter: false, useSelected: false}
[main] INFO org.apache.orc.impl.RecordReaderImpl - Reader schema not provided -- using file schema struct<name:string,location:map<string,string>,birthday:date,last_login:timestamp>
Rows: 1500
Compression: ZLIB
Compression size: 262144
Calendar: Julian/Gregorian
Type: struct<name:string,location:map<string,string>,birthday:date,last_login:timestamp>
Stripe Statistics:
Stripe 1:
Column 0: count: 1500 hasNull: false
Column 1: count: 1500 hasNull: false bytesOnDisk: 11857 min: Aaron Hamill II max: Zona Roob sum: 21912
...
File Statistics:
Column 0: count: 1500 hasNull: false
Column 1: count: 1500 hasNull: false bytesOnDisk: 11857 min: Aaron Hamill II max: Zona Roob sum: 21912
...
Stripes:
Stripe: offset: 3 data: 40195 rows: 1500 tail: 148 index: 240
Stream: column 0 section ROW_INDEX start: 3 length 12
Stream: column 1 section ROW_INDEX start: 15 length 53
...
Encoding column 0: DIRECT
Encoding column 1: DIRECT_V2
...
File length: 41072 bytes
Padding length: 0 bytes
Padding ratio: 0%
3. Apache Parquet
3.1. 文件结构
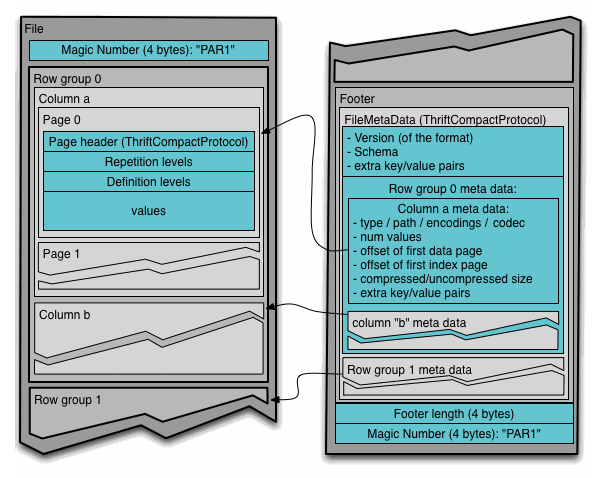
- Row Group: N 个 record 组成的分片,因此每个 group 的 record 个数是一致的。
- Column Chunk: 每一列的数据构成的分片,多个 Column Chunk 组成 Row Group。
- Page: 数据读取、压缩的最小单元,多个 Page 组成 Column Chunk.
此外就是 Header、Footer、Index 等索引数据。
3.2. 代码示例
static void parquetWriterSample() throws IOException {
Types.MessageTypeBuilder schemaBuilder = Types.buildMessage();
schemaBuilder.addField(new PrimitiveType(Type.Repetition.REQUIRED, PrimitiveType.PrimitiveTypeName.BINARY, "name"));
schemaBuilder.addField(new PrimitiveType(Type.Repetition.REQUIRED, PrimitiveType.PrimitiveTypeName.INT64, "last_login"));
MessageType schema = schemaBuilder.named("record");
Configuration conf = new Configuration();
FileSystem.getLocal(conf);
GroupWriteSupport.setSchema(schema, conf);
GroupWriteSupport writeSupport = new GroupWriteSupport();
writeSupport.init(conf);
Path testFilePath = new Path("/tmp/people.parquet");
Faker faker = new Faker();
try (ParquetWriter<Group> writer = new ParquetWriter<Group>(testFilePath,
writeSupport,
CompressionCodecName.SNAPPY,
ParquetWriter.DEFAULT_BLOCK_SIZE, ParquetWriter.DEFAULT_PAGE_SIZE, ParquetWriter.DEFAULT_PAGE_SIZE,
ParquetWriter.DEFAULT_IS_DICTIONARY_ENABLED,
ParquetWriter.DEFAULT_IS_VALIDATING_ENABLED,
ParquetWriter.DEFAULT_WRITER_VERSION,
conf)) {
for (int i = 0; i < 1500; i++) {
Group group = new SimpleGroupFactory(schema).newGroup();
group.add("name", Arrays.toString(faker.name().fullName().getBytes()));
group.add("last_login", faker.date().past(10, TimeUnit.DAYS).getTime());
writer.write(group);
}
}
}
parquet-cli 可以读取 parquet 文件:
✗ parquet-tools inspect /tmp/people.parquet (2s)[17:12:28]
############ file meta data ############
created_by: parquet-mr version 1.10.0 (build 031a6654009e3b82020012a18434c582bd74c73a)
num_columns: 2
num_rows: 1500
num_row_groups: 1
format_version: 1.0
serialized_size: 437
############ Columns ############
name
last_login
############ Column(name) ############
name: name
path: name
max_definition_level: 0
max_repetition_level: 0
physical_type: BYTE_ARRAY
logical_type: None
converted_type (legacy): NONE
compression: SNAPPY (space_saved: 60%)
############ Column(last_login) ############
name: last_login
path: last_login
max_definition_level: 0
max_repetition_level: 0
physical_type: INT64
logical_type: None
converted_type (legacy): NONE
compression: SNAPPY (space_saved: 24%)
文中的代码都上传到了Bigdata-Systems/fileformats.
4. 总结
关于 ORC 和 Parquet 的比较7:
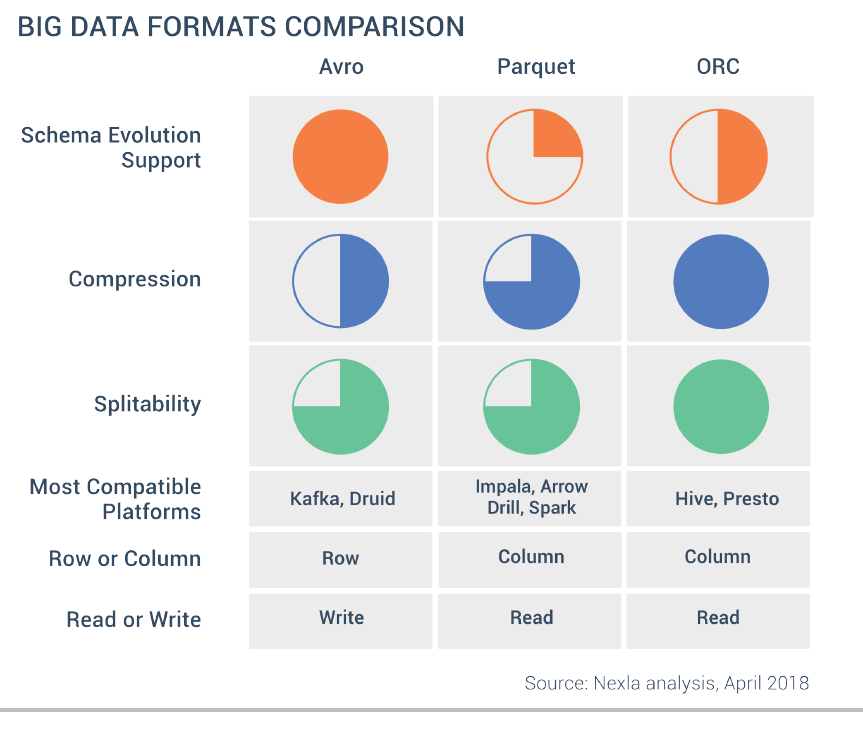
总的来说,ORC 的压缩比更高,而 Parquet 跟 Spark 结合的更好一些。
关于列存文件,SO 上有个问题很有意思。Row Stores vs Column Stores: 既然列存储的优势在于读取部分列,那我这几个 SQL 如何?
SELECT * FROM Person;
SELECT * FROM Person WHERE id=5;
SELECT AVG(YEAR(DateOfBirth)) FROM Person;
INSERT INTO Person (ID,DateOfBirth,Name,Surname) VALUES(2e25,'1990-05-01','Ute','Muller');
可以想到除了第3个SQL,列存的效果都一般。
归根结底,现代存储格式的设计,无论列存还是行存,都有其擅长的场景,同时无法覆盖 100% 的 SQL. Hybrid-Store8的出现,也只是做了一定程度的折衷。这种形式,恐怕在新的硬件出来之前都不会改变。