前几天纷飞的大雪还未消融,周末又赶上降温。于是踏实关在屋里,快速读了一遍 linkedin/coral1 的代码,这篇笔记记录下整体流程。
1. 背景:SQL 重写的需求
大数据领域,随着数据量变大、时效性要求越来越多样化,SQL 计算引擎也越来越多,从原来的 HiveSQL,到如今的 Presto/Trino、Flink、Spark。同时,随着 storage format、table format、table schema 各个方向的精细发展,SQL 的形式也越来越多,短期内也很难出现事实上的统一标准。
SQL 往往需要在不同执行计算引擎间变更,比如:
- 分析师的 HiveSQL 运行很慢,希望能够修改为 TrinoSQL 执行
- 数仓工程师的 HiveSQL,希望能够统一修改为 SparkSQL 执行
由于不同 SQL 间存在语法差异,SQL 工程师就需要重新学习新 SQL 的特有语法,类比于开发工程师重新学习一门编程语言。
SparkSQL 和 HiveSQL 间语法差异很多,诸如 order by 别名、hash方法、返回值、grouping sets、时间函数、ambiguous的语义等。HiveSQL 和 PrestoSQL 也是如此。
除了 SQL 重写,另外一种解决思路,是一份数据多处存储,由单个计算引擎统一SQL。例如对于一份数据,ClickHouse 以宽表的形式存在,Hive 则定义成多张表(或者 join 成 view)。如果想要统一 SQL,就需要建立 access layer:
┌──────────────┐
│ access layer │
└──────┬───────┘
│
│
┌─────────┬────────┼───────────┬─────────────┐
│ │ │ │ │
│ │ │ │ │
┌──┴──┐ ┌──┴──┐ ┌─┴──┐ ┌────┴──┐ ┌──────┴───┐
│Trino│ │Kafka│ │Hive│ │Iceberg│ │ClickHouse│
└─────┘ └─────┘ └────┘ └───────┘ └──────────┘
这一层是逻辑上的表,通过元数据关联到具体存储层(Trino、Kafka、Hive、Iceberg、CH、etc.)的表。
这里有点像 Flink 之前一直推广的流批一体2,不同的是其思路是想用 FlinkSQL 统一所有计算,而不是将 SQL 按不同引擎重写。
SQL 重写,python 里的小工具比较多,例如tobymao/sqlglot,没有过多依赖,用于简单的 SQL 重写、元数据提取就足够了。复杂 SQL 的场景,Coral 是一个比较好的解决方案。
2. 思路:Coral 介绍
linkedin 对 Coral 的定义是:SQL translation, analysis, and rewrite engine3.
Coral 的核心思路是将 HiveSQL 转为 calcite 的 RelNode(文档里的Coral IR?),然后再转为其他方言的 SQL.

由于存在 views 这一层,因此 coral-hive 需要负责读取其中的元信息:database/table/view(schema)、字段信息(例如 select * 提取出字段) 等。使用 Hive 的能力将 sql 转为 AST(Abstract Syntax Tree),然后遍历转换为 calcite 的 RelNode.(注:关于 RelNode 介绍Calcite-3:处理流程的代码例子)
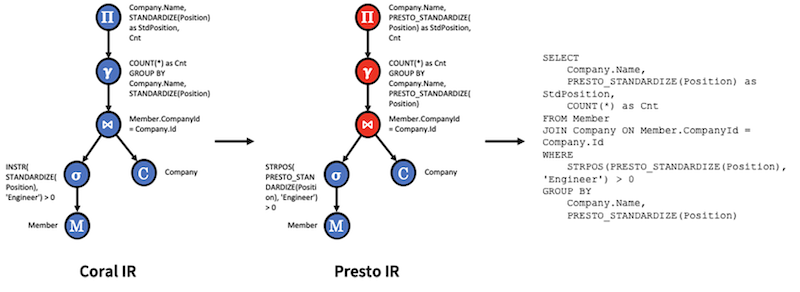
然后再将 RelNode 重写为 PrestoSQL
3. 实现:Coral 代码
如何用 ANTLR 解析和重写SQL笔记里,介绍过如何重写 SQL : SELECT size(ARRAY (1, 2)),这里仍然复用该 SQL 说明下 Coral 里重写的过程:
public class HiveToTrinoConverterTest {
@Test
public void testTypeCastForCardinalityFunction() {
RelToTrinoConverter relToTrinoConverter = TestUtils.getRelToTrinoConverter();
RelNode relNode = TestUtils.getHiveToRelConverter().convertSql("SELECT size(ARRAY (1, 2))");
String targetSql = "SELECT CAST(CARDINALITY(ARRAY[1, 2]) AS INTEGER)\n" + "FROM (VALUES (0)) AS \"t\" (\"ZERO\")";
String expandedSql = relToTrinoConverter.convert(relNode);
assertEquals(expandedSql, targetSql);
}
}
代码分为两个步骤:
- hiveSQL -> relNode: 通过
RelNode HiveToRelConverter.convertSql(String sql)实现 - relNode -> trinoSQL: 通过
String RelToTrinoConverter.convert(RelNode relNode)实现
3.1. hiveSQL -> relNode
这个过程用一句话概括,就是先根据 hive 的 antlr 语法文件解析成 ASTNode,然后遍历节点逐个转为 SqlNode,再调用 calcite 的方法转为 RelNode.
整体的流程:hiveSQL -> ASTNode -> SqlNode -> RelNode
ToRelConverter.convertSql
│
├─►ToRelConverter.toSqlNode // hiveSql -> SqlNode
│ │
│ ├──►ParseTreeBuilder.process
│ │ │
│ │ ├─►CoralParseDriver.parse // hiveSql -> ASTNode
│ │ │
│ │ └─►ParseTreeBuilder.processAST // ASTNode -> SqlNode
│ │ │
│ │ └─►AbstractASTVistor.visit
│ │
│ ├──►sqlNode.accept(FuzzyUnionSqlRewriter...)
│ │
│ └──►sqlNode.accept(HiveSqlNodeToCoralSqlNodeConverter...)
│
└─►ToRelConverter.toRel // SqlNode -> RelNode
│
└─►HiveSqlToRelConverter.convertQuery
public class ParseTreeBuilder extends AbstractASTVisitor<SqlNode, ParseTreeBuilder.ParseContext> {
public SqlNode process(String sql, @Nullable Table hiveView) {
ParseDriver pd = new CoralParseDriver();
try {
ASTNode root = pd.parse(sql);
return processAST(root, hiveView);
} catch (ParseException e) {
throw new RuntimeException(e);
}
}
}
第一步,CoralParseDriver基本复用了 Hive 原生org.apache.hadoop.hive.ql.parse.ParseDriver代码,调用 antlr 的 HiveParser/HiveLexer. pd.parse解析出的 ASTNode 树结构形如:
nil
TOK_QUERY
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_FUNCTION
size
TOK_FUNCTION
ARRAY
1
2
<EOF>
注意这里还是 antlr3 的语法
第二步,processAST遍历 ASTNode 根据node.getType()调用不同的 visit 方法,逐个转换为 SqlNode。
例如对于TOK_SELECT,则调用visitSelect: 先遍历所有子节点,然后构造SqlNodeList返回:
@Override
protected SqlNode visitSelect(ASTNode node, ParseContext ctx) {
List<SqlNode> sqlNodes = visitChildren(node, ctx);
ctx.selects = new SqlNodeList(sqlNodes, ZERO);
return ctx.selects;
}
对于TOK_FUNCTION,则调用visitFunction -> visitFunctionInternal方法:
public class ParseTreeBuilder extends AbstractASTVisitor<SqlNode, ParseTreeBuilder.ParseContext> {
protected SqlNode visitFunction(ASTNode node, ParseContext ctx) {
return visitFunctionInternal(node, ctx, null);
}
private SqlNode visitFunctionInternal(ASTNode node, ParseContext ctx, SqlLiteral quantifier) {
ArrayList<Node> children = node.getChildren();
checkState(children.size() > 0);
// 对 TOK_FUNCTION,首节点即为函数本身,取出函数名
ASTNode functionNode = (ASTNode) children.get(0);
String functionName = functionNode.getText();
// 遍历所有子节点转换为 SqlNode 列表
List<SqlNode> sqlOperands = visitChildren(children, ctx);
// 根据函数名、函数参数个数,查找对应的 hiveFunction
Function hiveFunction = functionResolver.tryResolve(functionName, ctx.hiveTable.orElse(null),
// The first element of sqlOperands is the operator itself. The actual # of operands is sqlOperands.size() - 1
sqlOperands.size() - 1);
// Special treatment for Window Function
SqlNode lastSqlOperand = sqlOperands.get(sqlOperands.size() - 1);
if (lastSqlOperand instanceof SqlWindow) {
// ...
}
if (functionName.equalsIgnoreCase("SUBSTRING")) {
// ...
}
// 创建 SqlBasicCall 返回
return hiveFunction.createCall(sqlOperands.get(0), sqlOperands.subList(1, sqlOperands.size()), quantifier);
}
}
HiveFunctionResolver functionResolver内部维护StaticHiveFunctionRegistry对象,注册了所有的 hive built-in UDF 到 SqlOperator 的映射,例如对于 “size” 和 “array”:
/**
* The ARRAY Value Constructor. e.g. "<code>ARRAY[1, 2, 3]</code>".
*/
public static final SqlArrayValueConstructor ARRAY_VALUE_CONSTRUCTOR =
new SqlArrayValueConstructor.SqlArrayValueConstructorAllowingEmpty();
// Complex type constructors
addFunctionEntry("array", ARRAY_VALUE_CONSTRUCTOR);
/**
* The CARDINALITY operator, used to retrieve the number of elements in a
* MULTISET, ARRAY or MAP.
*/
public static final SqlFunction CARDINALITY =
new SqlFunction(
"CARDINALITY",
SqlKind.OTHER_FUNCTION,
ReturnTypes.INTEGER_NULLABLE,
null,
OperandTypes.COLLECTION_OR_MAP,
SqlFunctionCategory.SYSTEM);
// Collection functions
addFunctionEntry("size", CARDINALITY);
functionResolver.tryResolve根据函数名查找对应的Function对象,该对象记录了函数名、SqlOperator,然后调用hiveFunction.createCall创建对应的SqlCall对象。
例如对于树里的两个TOP_FUNCTION节点,转换后的对象如图:
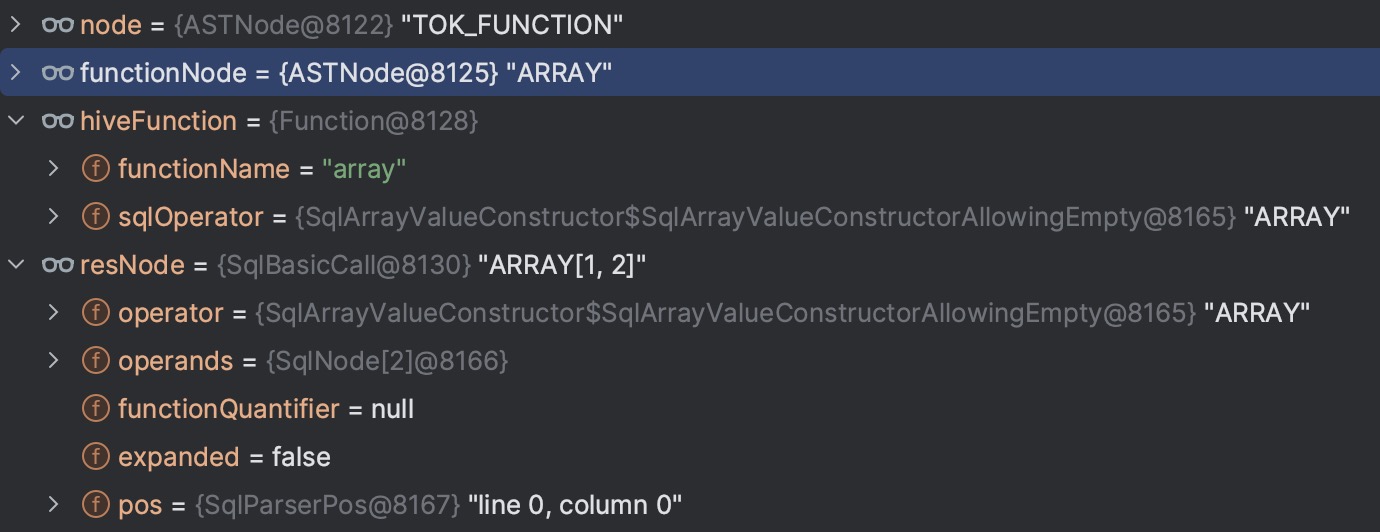
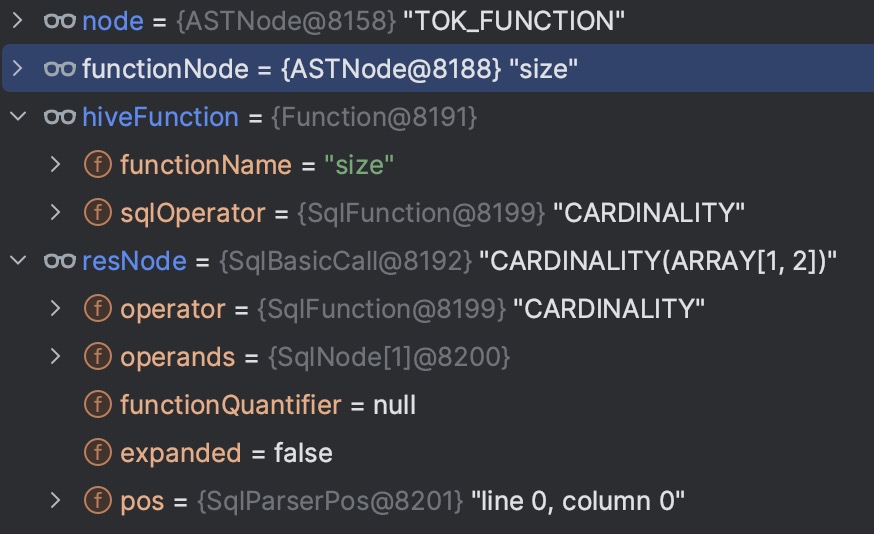
很多类型例如nil TOK_QUERY TOK_INSERT TOK_SELEXPR等则直接调用visitChildren然后返回首节点。
这一步得到的SqlNode 树结构形如:
SqlSelect =(SELECT CARDINALITY(ARRAY[1,2])
│
└──►SqlNodeList = CARDINALITY(ARRAY[1,2])
│
└──►SqlBasicCall = CARDINALITY(ARRAY[1,2])
│
├──►SqlFunction = CARDINALITY
│
└──►SqlBasicCall = ARRAY[1,2]
│
├──►SqlArrayValueConsturctorAllowingEmpty
│
├──►SqlNumericLiteral = 1
│
└──►SqlNumericListeral = 2
这一步的 SqlNode 还需要经过两次遍历优化:
FuzzyUnionSqlRewriter: 比如两个 UNION ALL 表 struct 结构不一致,b struct<b1:string>vsb struct<b1: string, b2:int>,那 SQL 会改写为:CAST(row("b"."b1") as row("b1" varchar)) AS "b"的形式。注:这种 incompatible 的类型确实需要兼容么?HiveSqlNodeToCoralSqlNodeConverter:ShiftArrayIndexTransformer解决 hiveSQL 数组下标从0开始而 prestoSQL 下标从 1 开始的 diff.
第三步,ToRelConverter.toRel转化为 SqlNode 到 RelNode。
org.apache.calcite.sql2rel.SqlToRelConverter在之前笔记Calcite-3:处理流程的代码例子介绍过,coral 使用了自定义的HiveSqlToRelConverter:
if (sqlToRelConverter == null) {
sqlToRelConverter =
new HiveSqlToRelConverter(new HiveViewExpander(this), getSqlValidator(), getCalciteCatalogReader(),
RelOptCluster.create(new VolcanoPlanner(), new HiveRexBuilder(getRelBuilder().getTypeFactory())),
getConvertletTable(),
SqlToRelConverter.configBuilder().withRelBuilderFactory(HiveRelBuilder.LOGICAL_BUILDER).build());
}
return sqlToRelConverter;
HiveViewExpander.expandView方法使用HiveMetaStoreClient访问 hive 元数据,如果 tableType 是 VIRTUAL_VIEW,则返回getViewExpandedText即 view 的定义,如果是 MANAGED_TABLE EXTERNAL_TABLE INDEX_TABLE 等则返回SELECT * FROM $dbName.$tableName。- 使用了
VolcanoPlanner基于 CBO 优化 SQL
转换后的 RelNode Plan 为:
[RelNode Plan]
LogicalProject(EXPR$0=[CARDINALITY(ARRAY(1, 2))]): rowcount = 1.0, cumulative cost = {2.0 rows, 2.0 cpu, 0.0 io}, id = 1
LogicalValues(tuples=[[{ 0 }]]): rowcount = 1.0, cumulative cost = {1.0 rows, 1.0 cpu, 0.0 io}, id = 0
RelNode 树结构: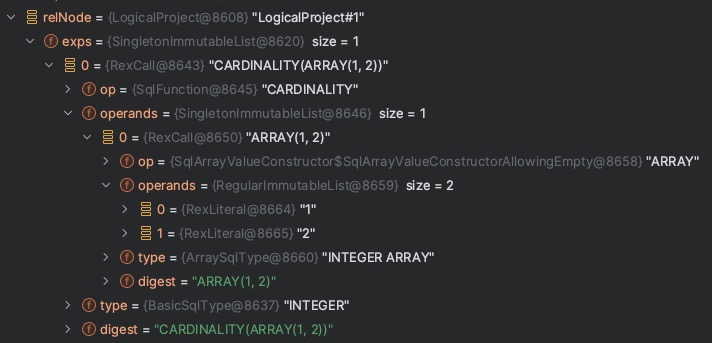
3.2. relNode -> trinoSQL
和上一节的顺序正好相反,这一节的数据结构转换过程:RelNode -> SqlNode -> trinoSQL
public class RelToTrinoConverter extends RelToSqlConverter {
public String convert(RelNode relNode) {
RelNode rel = convertRel(relNode, configs);
SqlNode sqlNode = convertToSqlNode(rel);
SqlNode sqlNodeWithRelDataTypeDerivedConversions =
sqlNode.accept(new DataTypeDerivedSqlCallConverter(_hiveMetastoreClient, sqlNode));
SqlNode sqlNodeWithUDFOperatorConverted =
sqlNodeWithRelDataTypeDerivedConversions.accept(new CoralToTrinoSqlCallConverter(configs));
return sqlNodeWithUDFOperatorConverted.accept(new TrinoSqlRewriter()).toSqlString(TrinoSqlDialect.INSTANCE)
.toString();
}
}
DataTypeDerivedSqlCallConverter、CoralToTrinoSqlCallConverter定义了众多的SqlCallTransformer,例如以下两个 transformer 的作用:
public class ConcatOperatorTransformer extends SqlCallTransformer {
@Override
// 当 sqlCall.getOperator().getName() 为 concat 时调用该方法
protected SqlCall transform(SqlCall sqlCall) {
List<SqlNode> updatedOperands = new ArrayList<>();
// 遍历所有参数节点
for (SqlNode operand : sqlCall.getOperandList()) {
RelDataType type = deriveRelDatatype(operand);
// 如果不是 VARCHAR CHAR 类型,则强制转换 CAST (xxx AS VARCHAR(65535))
if (!OPERAND_SQL_TYPE_NAMES.contains(type.getSqlTypeName())) {
SqlNode castOperand = SqlStdOperatorTable.CAST.createCall(POS,
new ArrayList<>(Arrays.asList(operand, VARCHAR_SQL_DATA_TYPE_SPEC)));
updatedOperands.add(castOperand);
} else {
updatedOperands.add(operand);
}
}
return sqlCall.getOperator().createCall(POS, updatedOperands);
}
}
该方法产生如下的转换效果:
- Input - SqlCall: `concat`(CURRENT_DATE, ‘|’, CURRENT_DATE, ‘-00’)
- Output - SqlCall: `concat`(CAST(CURRENT_DATE AS VARCHAR(65535)), ‘|’, CAST(CURRENT_DATE AS VARCHAR(65535)), ‘-00’)
public class OperatorRenameSqlCallTransformer extends SourceOperatorMatchSqlCallTransformer {
@Override
protected SqlCall transform(SqlCall sqlCall) {
return createSqlOperator(targetOpName, sourceOperator.getReturnTypeInference())
.createCall(new SqlNodeList(sqlCall.getOperandList(), SqlParserPos.ZERO));
}
}
则将RLIKE转换为REGEXP_LIKE,RAND转换为RANDOM(),SUBSTRING转换为SUBSTR等。
TrinoSqlDialect.INSTANCE定义了 trino 一些特殊写法,例如concat -> "concat"。
对于上一节的 SQL,由于并不复杂,实际上在这一步只用calcite的原始接口(RelNode -> SqlString -> String)也生成正确的 trinoSQL.
4. 总结
SQL 重写的工具很多,如果要比较重写的效果,HiveToTrinoConverterTest单测的 SQL 是个不错的选择,例如:
| HiveSQL | TrinoSQL |
|---|---|
| SELECT RAND() | SELECT “RANDOM”() |
| SELECT size(ARRAY (1, 2)) | SELECT CAST(CARDINALITY(ARRAY[1, 2]) AS INTEGER) |
| select concat(current_date(), ‘|’, current_date(), ‘-00’) | SELECT “concat”(CAST(CURRENT_DATE AS VARCHAR(65535)), ‘|’, CAST(CURRENT_DATE AS VARCHAR(65535)), ‘-00’) |
但是由于 hive/trino/presto 版本多,很难做到100%准确的转换,就像将一门编程语言准确的转换为另一种一样,更多的是作为参考。
Coral项目本身代码非常值得一读,对 calcite 框架、hive/trino/sparkSQL 都能有更深的理解。快速读了一遍,我还是有很多疑问,比如同样是遍历重写 SqlNode,为什么分别在转换 RelNode 前后实现?跟 view 有关?为什么同样是 SqlCallTransformer,实现在了多个类里?