微服务间调用链路要清晰,才能方便的进行后续的架构升级、核心链路演练等。大数据里的表/任务之间也是如此,同时由于任务量大,血缘系统的设计更加重要。
这篇笔记记录下我理解的数据血缘系统。
1. 使用场景
大数据很多功能都会依赖血缘,例如:
- 数据开发:任务的修改、下线,影响产出表的操作,依赖血缘周知下游
- 数据治理:通过血缘分析数据间的冗余依赖、是否存在依赖环
- 数据资产:计算表的使用热度(血缘的入度、出度)、展示字段来源
- 数据质量:字段质量的归因分析(上游)
因此数据血缘系统应当作为大数据的基石来建设。
2. 如何评价
血缘做的好坏,评价标准有三点:
- 准确率:表关系(输入、输出)、字段关系
- 覆盖率:覆盖的任务、存储类型
- 响应时间:血缘数据复杂,需要关注查询性能,特别是层数
时效性按需,一般不需要太高,也不应当影响技术方案
1 2 依赖血缘信息采集,3 依赖存储选型和设计。
3. 血缘信息采集
血缘信息采集,常见的思路有两个
| 思路 | 具体方式 | 优点 | 缺点 |
|---|---|---|---|
| 被动 | 实现执行引擎对应的 Hook/Listener | 引擎自身输出结果,准确率和覆盖率高 | 1. 只有运行时才能获取 2. 需要随引擎增加/升级 |
| 主动 | 解析 SQL | 1. 跟运行无关,轻量级解析 2. 底层实现可统一 |
非本地解析加上没有元数据, 因此准确率和覆盖率不如1高 |
同时,由于 shell、scala/java 任务无法解析,因此也需要开放血缘接口支持手动修正、登记。
如表所述,方式各有优劣,这里主要介绍下每个思路可以考虑的做法。
3.1. Hook/Listener
hive 支持了多种 hook/listener: hive.exec.pre.hooks、hive.exec.post.hooks、hive.exec.failure.hooks.
hook/listener 的应用场景可以很广泛,比如可能历史原因会导致很多用户有 beeline/hive client,但是又想控制用户的建表语句,就可以使用 hive.metastore.pre.event.listeners hive.metastore.event.listeners,客户端建表时自动回调该方法。
订阅运行时 SQL 解析结果,可以使用hive.exec.post.hooks:
SET hive.exec.post.hooks=org.apache.hadoop.hive.ql.hooks.LineageLogger
SELECT `uid` AS uid,
UPPER(`uid`) AS upper_uid,
CONCAT(`uid`,
'_', `i`) AS cuid, (`time0` + 1) AS time1, CURRENT_TIMESTAMP() AS cts
FROM test001
WHERE dt = 20231203 LIMIT 5
这里用了 hive 自带的org.apache.hadoop.hive.ql.hooks.LineageLogger:
package org.apache.hadoop.hive.ql.hooks;
public class LineageLogger implements ExecuteWithHookContext {
@Override
public void run(HookContext hookContext) {
// ...
}
}
SQL 执行时,解析信息会打印到 hs 日志:
[HiveServer2-Background-Pool: Thread-211] hooks.LineageLogger: {"version":"1.0","user":"hadoop","timestamp":1701667488,"duration":303,"jobIds":[],"engine":"spark","database":"default","hash":"201fa8ddc618ef7f7d66aef4cdc731e4","queryText":"SELECT `uid` as uid, UPPER(`uid`) AS upper_uid, CONCAT(`uid`, '_', `i`) AS cuid, (`time0` + 1) AS time1, CURRENT_TIMESTAMP() AS cts FROM test001 WHERE dt = 20231203 LIMIT 5","edges":[{"sources":[5],"targets":[0],"edgeType":"PROJECTION"},{"sources":[5],"targets":[1],"expression":"upper(test001.uid)","edgeType":"PROJECTION"},{"sources":[5,6],"targets":[2],"expression":"concat(test001.uid, '_', test001.i)","edgeType":"PROJECTION"},{"sources":[7],"targets":[3],"expression":"(test001.time0 + 1)","edgeType":"PROJECTION"},{"sources":[],"targets":[4],"expression":"CURRENT_TIMESTAMP()","edgeType":"PROJECTION"},{"sources":[8],"targets":[0,1,2,3,4],"expression":"(test001.dt = 20231203)","edgeType":"PREDICATE"}],"vertices":[{"id":0,"vertexType":"COLUMN","vertexId":"uid"},{"id":1,"vertexType":"COLUMN","vertexId":"upper_uid"},{"id":2,"vertexType":"COLUMN","vertexId":"cuid"},{"id":3,"vertexType":"COLUMN","vertexId":"time1"},{"id":4,"vertexType":"COLUMN","vertexId":"cts"},{"id":5,"vertexType":"COLUMN","vertexId":"default.test001.uid"},{"id":6,"vertexType":"COLUMN","vertexId":"default.test001.i"},{"id":7,"vertexType":"COLUMN","vertexId":"default.test001.time0"},{"id":8,"vertexType":"COLUMN","vertexId":"default.test001.dt"}]}
日志输出两部分:edges、vertices,包含表及字段的信息。这份数据用于血缘的结果,我们可以直接参考 Apache Atlas.
Apache Atlas 的架构在知易行难-读《中台落地手记》里介绍过,血缘采集的流程2:
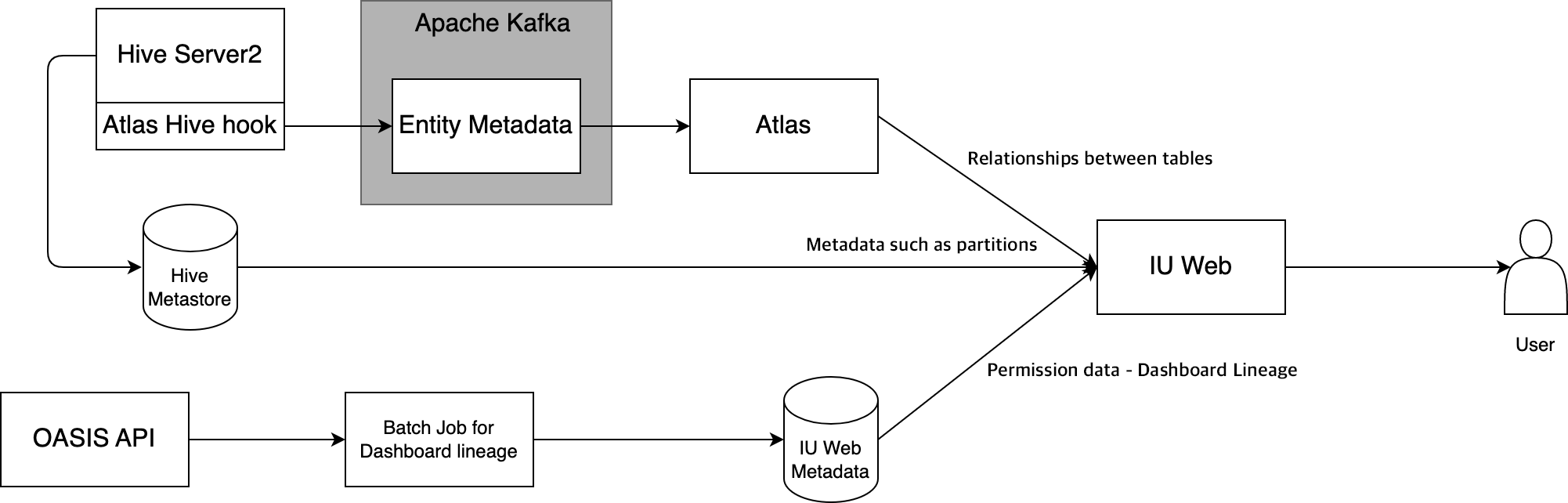
实现上使用自定义的 Hook2 :
public class HiveHook extends AtlasHook implements ExecuteWithHookContext {
@Override
public void run(HookContext hookContext) throws Exception {
// ...
}
}
ExecuteWithHookContext是 Hive 的基类,AtlasHook则是 Atlas 各种存储类型 Hook 的基类,hbase、sqoop、storm 都有对应的实现。
Atlas 的血缘参考效果:
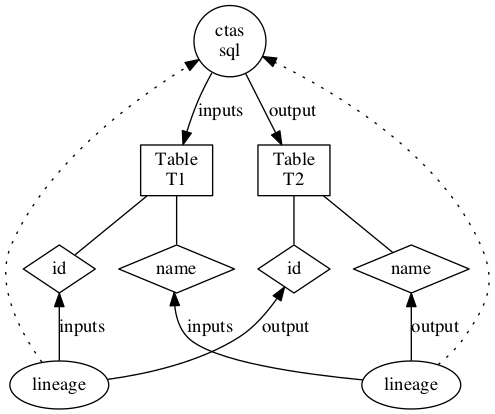
对 Spark/Presto,则需要使用对应的 QueryExecutionListener/EventListener.
3.2. 解析 SQL
实际上,即使采用了方案1,解析 SQL 往往也是不可缺的,主要在于有单独 SQL 解析场景,例如我开发了一版任务,只是想看看该任务的输入、输出表是否符合预期,并不想直接提交运行。
SQL 解析的方案很多,有 python 实现基于正则的 sqlparse3,haskell实现的 uber/queryparser4,不过在大数据会更倾向于使用 java/scala 实现的模块。
常见的方式有:
- alibaba/druid: 使用 SQL Parser,能够解析出 AST.缺点是大数据的常见存储里,只支持了 Hive
- antlr4: 之前介绍过一篇笔记SQL 解析之 ANTLR,网上也有比较多的应用:parseX6 webgjc/sql-parser7
- 从各个引擎里抽取对应的代码,例如常见的存储引擎:
- HiveSQL ->
ParseUtils.parse - SparkSQL ->
SparkSqlParser.parsePlan - PrestoSQL ->
io.prestosql.sql.parser.SqlParser
- HiveSQL ->
4. 总结
可以看到可用的方式很多,但是都不够完善,因此需要结合准确率、覆盖率的目标来搞,我更倾向于使用 antlr4 来实现,代码统一、可扩展,缺点是前期开发成本较大。
存储上,适合使用图数据库,重点考虑任务是作为边还是节点存储,以及像取上下游层数这种数据的性能。