1. 简介
ANTLR(ANother Tool for Language Recognition)1是一个强大的 parser generator,可以根据规则生成 parser 代码,用于读取、处理、执行和翻译结构化或二进制数据。Hive/Trino/Spark/Flink/Doris/… 等常见大数据组件都用到了 ANTLR.
如果要实现 C++ 代码的解析器,需要提取出其中的变量、常量、关键字、注释;解析 JSON ,需要提取出{} [] '";解析 SQL、Protobuf 也是如此。 解析完成后,还需要能够遍历结果树,判断语法是否正确。
ANTLR 使用通用的方式解决了这一点,并对应分成两个步骤:
- LEXER: 输入流解析为 tokens
- PARSER: tokens 解析为 AST
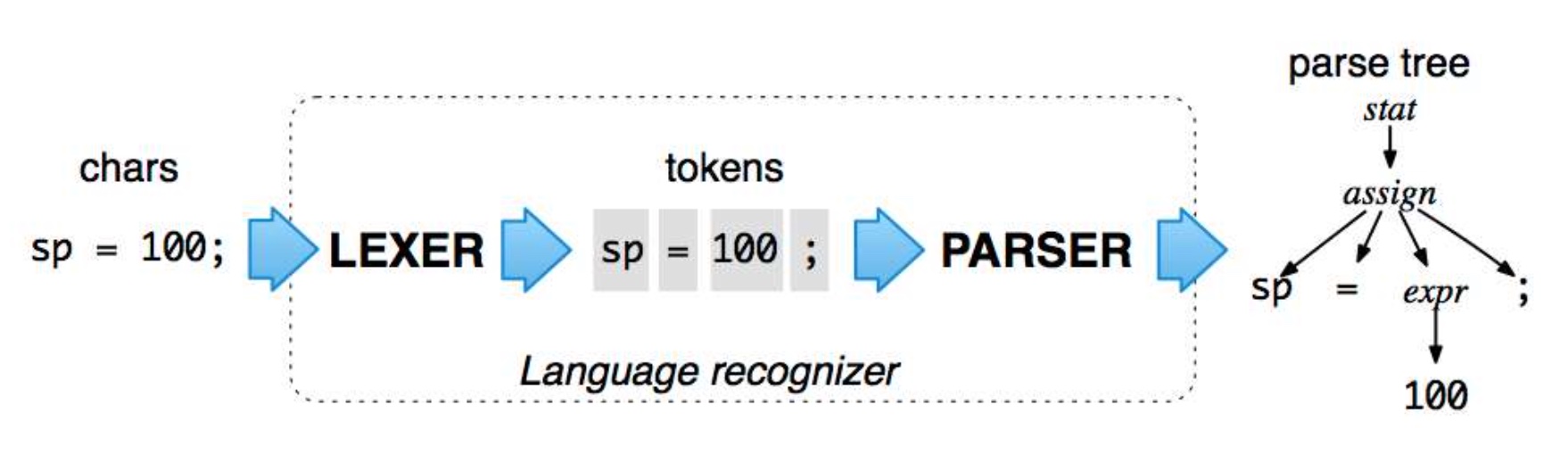
类似的工具还有javacc、LEX+YACC.
2. 场景
简单的解析需求实际上正则就可以完成,但是随着场景、文本变复杂,例如 SQL 重写,正则表达式本身会越来越难维护,原因是没有从根本上解决问题。
ANTLR 主要用于实现基础的构建语言的框架,例如语言翻译、代码分析、自定义语言等。grammars-v42里提供了很多语法文件,比如 JAVA、SQL、JSON、Protobuf,不过我觉得实际场景里,应用最广泛的还是解析 SQL,即围绕上述使用了 ANTLR 且 SQL 实践广泛的大数据组件。
3. 使用
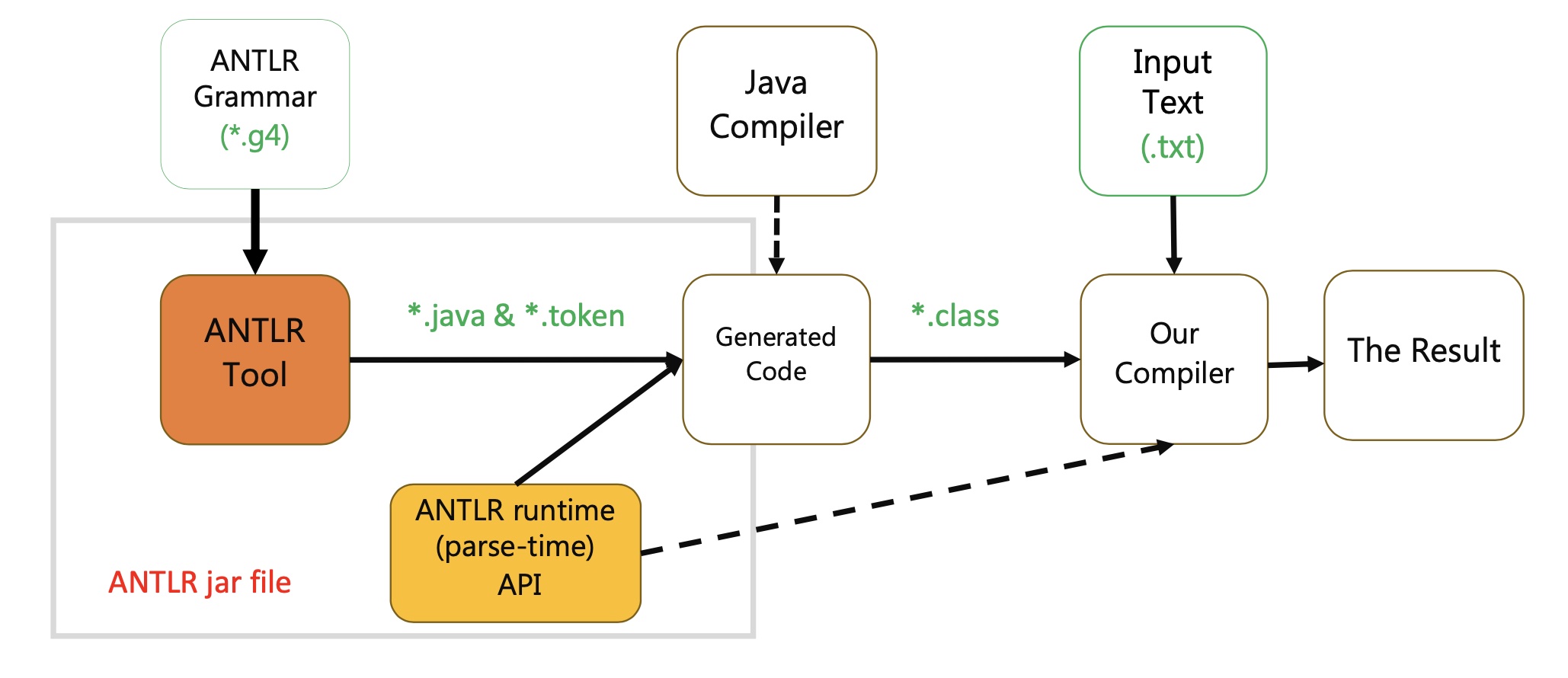
类似使用 protobuf、thrift ,分为三步:
- 定义语法文件:描述了关键字、元素之间的规则等,按照 ANTLR 格式实现,.g4 格式
- 通过工具生成代码:ANTLR 支持生成多个语言的代码,例如 java、python、go 等,代码包含了 Lexer/Parser/Visitor/Listener
- 使用 runtime API 及生成代码遍历 AST:支持 Visitor/Listener 两种模式。
接下来逐步介绍。
3.1. g4 语法文件
语法文件的基础格式:
/** Optional javadoc style comment */
grammar Name; ①
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleN
注意:
- 注释使用 /* */ //
- 解析规则通常是 lower camel case (对应函数名)
- 词法规则、词法单元通常是大写字母
- 字符、字符串统一用 ‘’
- | 用于连接两个规则(或的关系)
- fragment 用于定义辅助规则,仅用于其他规则内使用
- 支持调试,例如在语法文件里使用
{System.out.println("Parsed successfully!");}
更多高级的语法可以参考 grammars-v4 的模板以及《The Definitive ANTLR 4 Reference》的 Exploring Some Real Grammars 部分。跟之前介绍过的 Parser.jj 很像,本质上也是定义了词法分析与解析的一套语法。
例如 Hello.g4
// Define a grammar called Hello
grammar Hello;
hello : 'Hello' name ', I am' name EOF ; // match keyword hello followed by an identifier
name : ID ;
ID : [a-zA-Z']+ ; // match lower-case identifiers
WS : [ \t\r\n]+ -> skip ; // skip spaces, tabs, newlines
定义了名为 Hello 的 grammar,包含唯一的规则r,该规则:
- 匹配类似
Hello Han'Meimei, I am Li'Lei的内容, 匹配部分将会保存到 name - 定义了空白字符并忽略这些字符
3.2. 生成代码
手动的方式,可以通过 Intellij 的 ANTLR v4 插件,该插件还支持 ANTLR Preview,即指定语法文件后,对输入串解析并可视化的展示4,形如: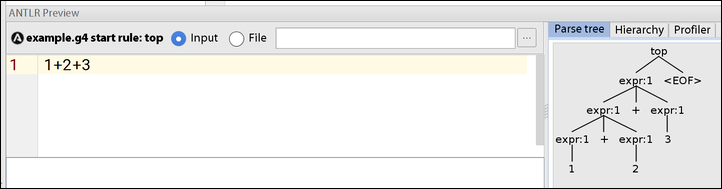
手动的方式需要往代码库 ci 生成后的代码,但是代码库应当尽量使用语法文件本身,以方便升级版本。因此更推荐自动的方式,可以在 pom.xml 配置 antlr4-maven-plugin 实现.
生成的代码列表:
- <Grammar>Lexer.java: Lexer
- <Grammar>Parser.java: Parser
- <Grammar>Listener.java: Listener 接口
- <Grammar>BaseListener.java: Listener 默认实现
- <Grammar>Visitor.java: Visitor 接口
- <Grammar>BaseVisitor.java: Visitor 默认实现
- <Grammar>[Lexer].tokens: 当语法被拆分成多个多个文件时用于同步编号
Parser.java 里会根据规则生成方法:例如HelloContext hello()、NameContext name(),变量对应TerminalNode
class ${RULE}Context包含了#{SUBRULE}Context、TerminalNode用于递归。
static class HelloContext extends RarserRuleContext {
public List<NameContext> name() { return getRuleContexts(NameContext.class); }
public NameContext name(int i) { return getRuleContext(NameContext.class, i); }
}
static class NameContext extends ParserRuleContext {
public TerminalNode ID() { return getToken(HelloParser.ID, 0); }
}
如果有多个同名的子 rule,通过List获取。
BaseVisitor.java BaseListener.java 里则定义了访问到具体规则的默认实现:
public class HelloBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements HelloVisitor<T> {
@Override public T visitHello(HelloParser.HelloContext ctx) { return visitChildren(ctx); }
@Override public T visitName(HelloParser.NameContext ctx) { return visitChildren(ctx); }
}
public class HelloBaseListener implements HelloListener {
@Override
public void enterHello(HelloParser.HelloContext ctx) { }
@Override
public void exitHello(HelloParser.HelloContext ctx) { }
@Override
public void enterName(HelloParser.NameContext ctx) { }
// ...
}
有意思的是 ANTLR4 提供了两种遍历方式: visitor/listener:
visitor 是主动遍历,我们可以手动调用visitHello;而 listener 是被动遍历,因此需要配合ParseTreeWalker,遍历到某个节点,则调用对应的enter${RULE}方法。
3.3. 应用代码
应用上,主要分为两部分:校验、遍历
public class HelloTest {
private static void run(String expr) {
ANTLRInputStream input = new ANTLRInputStream(expr);
Lexer lexer = new HelloLexer(input);
CommonTokenStream commonTokenStream = new CommonTokenStream(lexer);
HelloParser parser = new HelloParser(commonTokenStream);
ParseTree parseTree = parser.hello();
System.out.println("parserTree:" + parseTree.toStringTree(parser));
HelloWhatVisitor helloWhatVisitor = new HelloWhatVisitor();
System.out.println(helloWhatVisitor.visit(parseTree));
ParseTreeWalker walker = new ParseTreeWalker();
HelloWhatListener helloWhatListener = new HelloWhatListener();
walker.walk(helloWhatListener, parseTree);
}
public static void main(String[] args) {
run("Hello Han'Meimei, I am Li'Lei");
}
}
parser.hello运行 hello 规则。
HelloWhatListener重载关注的规则方法:
public class HelloWhatListener extends HelloBaseListener {
@Override
public void enterHello(HelloParser.HelloContext ctx) {
System.out.println("HelloWhatListener enterHello");
List<HelloParser.NameContext> nameContextsList = ctx.name();
if (nameContextsList.size() == 1) {
System.out.println("someone say hello to " + nameContextsList.get(0).ID());
} else if (nameContextsList.size() == 2) {
System.out.println(nameContextsList.get(1).ID() + " say hello to " + nameContextsList.get(0).ID());
}
super.enterHello(ctx);
}
}
4. SQL 解析
解析 SQL 的需求很常见,通过 ANTLR4 实现的好处是统一,比如 HiveSQL、PrestoSQL、FlinkSQL 都可以使用 ANTLR4 实现。
以 HiveSQL 解析为例,输入:
INSERT INTO app.table_c PARTITION(dt = '20231221')
SELECT a.id,
table_a.col1,
c.col2
FROM app.table_a a
LEFT JOIN bdm.table_b c
ON a.id=c.id
表血缘预期的结果:
[app.table_a,bdm.table_b] -> [app.table_c@partition(dt='20231221')]
Hive 2.x 版本里使用的还是 antlr3 的语法(HiveParser.g6),我使用了 grammars-v4 提供的 antlr4 实现。
首先是需要明确关注哪些规则。
在 FromClauseParser.g4 里定义了 From 字句的规则:
fromClause
: KW_FROM fromSource
;
fromSource
: uniqueJoinToken uniqueJoinSource (COMMA uniqueJoinSource)+
| joinSource
;
atomjoinSource
: tableSource lateralView*
| virtualTableSource lateralView*
| subQuerySource lateralView*
| partitionedTableFunction lateralView*
| LPAREN joinSource RPAREN
;
joinSource
: atomjoinSource (
joinToken joinSourcePart (KW_ON expression | KW_USING columnParenthesesList)?
)*
;
tableSource
: tableName tableProperties? tableSample? (KW_AS? identifier)?
;
tableName
: identifier DOT identifier
| identifier
;
因此可以通过 tableName 规则得到输入表。
HiveParser.g4 里定义了 insert 的规则:
insertClause
: KW_INSERT KW_OVERWRITE destination ifNotExists?
| KW_INSERT KW_INTO KW_TABLE? tableOrPartition (LPAREN columnNameList RPAREN)?
;
tableOrPartition
: tableName partitionSpec?
;
destination匹配写入文件的 SQL,不关注可忽略。因此可以通过 tableOrPartition 规则得到写入的表。
对应的代码就明确了,使用了 listener 模式:
public class HiveParserListenerImpl extends HiveParserBaseListener {
List<String> inputTables = new ArrayList<>();
List<Pair<String, String>> outputTables = new ArrayList<>();
@Override
public void enterSelectStatement(HiveParser.SelectStatementContext ctx) {
super.enterSelectStatement(ctx);
}
@Override
public void enterTableSource(HiveParser.TableSourceContext ctx) {
inputTables.add(ctx.tableName().getText());
super.enterTableSource(ctx);
}
@Override
public void enterTableOrPartition(HiveParser.TableOrPartitionContext ctx) {
String table = ctx.tableName() != null ? ctx.tableName().getText() : "UNKNOWN";
String partition = ctx.partitionSpec() != null ? ctx.partitionSpec().getText() : "UNKNOWN";
outputTables.add(new Pair<>(table, partition));
super.enterTableOrPartition(ctx);
}
public void show() {
System.out.println(inputTables.stream().collect(Collectors.joining(",", "[", "]")) +
" -> " + outputTables.stream()
.map(pair -> pair.a + "@" + pair.b)
.collect(Collectors.joining(",", "[", "]")));
}
}
注意对应实现了ANTLRNoCaseStringStream以适配 HiveSQL,实际还要补全各种场景比如 CTE。如果要做字段血缘,那复杂度就完全不同了,需要关注 selectList lateralView joinSource 的众多细节。
5. SQL 重写
SQL 重写是在解析的基础上,对 AST 进行重写,比如将 HiveSQL 重写为 TrinoSQL:
-- HiveSQL
SELECT size(ARRAY (1, 2))
-- 转换为TrinoSQL
SELECT CARDINALITY(ARRAY [1, 2])
可以通过TokenStreamRewriter实现,本质上也还是遍历parseTree,重写节点。
public class HiveSQLRewriter extends HiveParserBaseListener {
TokenStreamRewriter tokenStreamRewriter;
public HiveSQLRewriter(CommonTokenStream commonTokenStream) {
tokenStreamRewriter = new TokenStreamRewriter(commonTokenStream);
}
@Override
public void enterFunction(HiveParser.FunctionContext ctx) {
// size(...) to size[...]
Optional.of(ctx)
.map(HiveParser.FunctionContext::functionName)
.map(HiveParser.FunctionNameContext::sql11ReservedKeywordsUsedAsFunctionName)
.map(HiveParser.Sql11ReservedKeywordsUsedAsFunctionNameContext::KW_ARRAY)
.ifPresent(__ -> {
tokenStreamRewriter.replace(ctx.LPAREN().getSymbol(), "[");
tokenStreamRewriter.replace(ctx.RPAREN().getSymbol(), "]");
});
super.enterFunction(ctx);
}
@Override
public void enterIdentifier(HiveParser.IdentifierContext ctx) {
if (ctx.Identifier().getText().equalsIgnoreCase("size")) {
tokenStreamRewriter.replace(ctx.Identifier().getSymbol(), "CARDINALITY");
}
super.enterIdentifier(ctx);
}
public String toSQL() {
return tokenStreamRewriter.getText();
}
}
enterFunction重写ARRAY(1, 2)为ARRAY[1, 2],enterIdentifier则重写size为CARDINALITY.除了replace,TokenStreamRewriter还支持delete、insertAfter、insertBefore等方法。
示例代码统一上传到了 antlr example5.
当然这里只是介绍了原理,毫无疑问逐个重写是需要耐心和成本的。如果要放到生产环境中,推荐基于coral实现。