C 代码编译时要经过词法分析、语法分析:比如提取关键字(int/for/#define, ETC.),判断语法是否正确。
类似的,SQL 字符串解析为SqlNode也需要词法分析。
在 Calcite 中,这一过程借助于 javacc 完成。预配置的语法文件里,包含了需要的关键字以及对应的代码模板。随着解析字符串匹配到关键字,一步步生成需要的代码。
这篇笔记主要记录 javacc 以及 Calcite 里对应的源码分析。
1. javacc
javacc1是一个 java 版本的语法解析库,我们可以用来定义自己的关键字,生成 java 代码。
举个例子,我们定义一个自解释的Explain关键字,输入形如:
EXPLAIN javacc;
预期的输出是打印参数(javacc),并且输出对应的 base64 编码。希望能够生成一段代码来完成这项工作。
1.1. parser.jj
首先需要定义对应的语法文件,文件名为parser.jj.
// 控制 javacc 生成代码的整体配置
// 更多的 options 参考:https://javacc.github.io/javacc/documentation/cli.html
options {
STATIC = false;
JDK_VERSION = "1.8";
// DEBUG_PARSER = true;
}
// PARSER_BEGIN PARSER_END 之间是解析器类的定义
PARSER_BEGIN(Explain)
package cn.izualzhy;
public class Explain {
public static void main(String[] args) throws ParseException {
Explain explainer = new Explain(System.in);
explainer.explain();
}
}
PARSER_END(Explain)
// SKIP 表示遇到这些字符串了则忽略
SKIP : {" "}
SKIP : { "\n" | "\r" | "\r\n" }
// 定义了一些关键字,后面的匹配流程会用到
TOKEN : {
<EXPLAIN : "EXPLAIN" | "Explain" | "explain">
|
<IDENTITY : (["a" - "z", "A" - "Z", "0" - "9"])+>
|
<SEMICOLON : ";">
}
void explain() throws ParseException:
{
System.out.println("Explain Plan.");
Token token;
}
{
// 当遇到 explain xxx 时,生成的代码
<EXPLAIN> token = <IDENTITY>
{
// token.image 获取应的字符串
String identity = token.image;
System.out.println(">>>>>> identity:" + identity);
String encodedStr = java.util.Base64.getEncoder().encodeToString(identity.getBytes());
System.out.println(">>>>>> identity puzzle:" + encodedStr);
}
// 当遇到 ; 时,生成的代码
<SEMICOLON>
{
System.out.println("Explain Over.");
}
}
如同我们学习一门编程语言的 Hello World 一样,写一个简单的 parser.jj 并不复杂,遵循 javacc 定义的语法即可。 这个过程看着复杂,其实就是一个逐步匹配的过程,遇到某个关键字,就生成对应的代码。
实际上这种简单的 case,自己实现字符串匹配比 javacc 复杂度要更低。大型项目下,javacc 的优势才能体现出来,例如提供大家理解一致的可读模板、更低的复杂度以及更高的成熟度等。如果要写出更深入的例子,建议参考2的步骤逐步深入了解。
1.2. 如何使用
通过执行
generated_code_dir='./cn/izualzhy'
rm -rf "${generated_code_dir}"
javacc -JDK_VERSION:1.8 -OUTPUT_DIRECTORY="${generated_code_dir}" parser.jj
就会生成一系列的 java 代码文件:
➜ codegen git:(main) ✗ tree ./cn/izualzhy
./cn/izualzhy
├── Explain.java
├── ExplainConstants.java
├── ExplainTokenManager.java
├── ParseException.java
├── SimpleCharStream.java
├── Token.java
└── TokenMgrError.java
对比下 parser.jj 和 Explain.java 能够更直观的看到语法解析的过程:
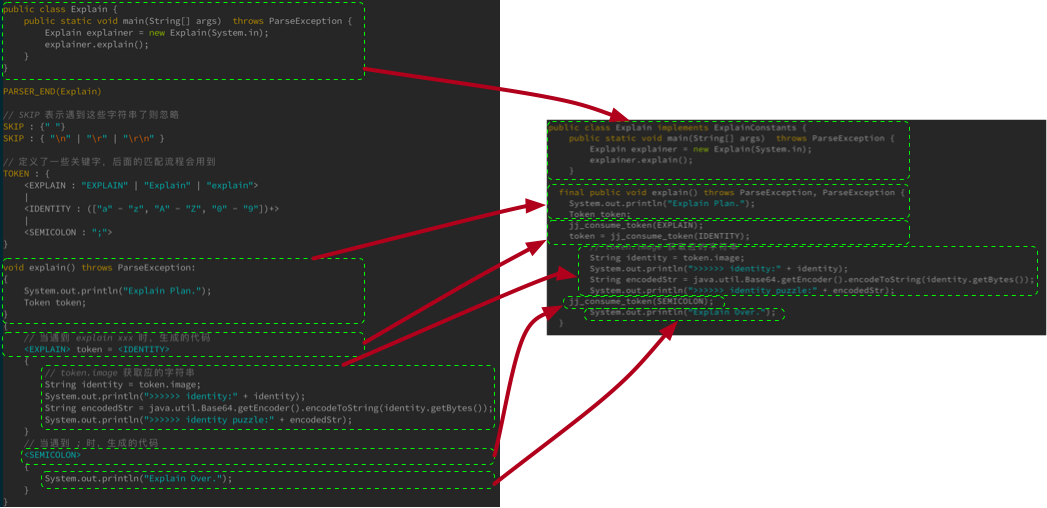
代码里 jj_ 开头的都是自动填充的代码,用来解析某个 token(关键字)。
生成 java 文件后的执行就都比较熟悉了:
/usr/bin/javac "${generated_code_dir}"/*.java
echo 'EXPLAIN javacc;' > ./args
/usr/bin/java cn.izualzhy.Explain < ./args
执行结果:
Explain Plan.
>>>>>> identity:javacc
>>>>>> identity puzzle:amF2YWNj
Explain Over.
完整的例子放在了codegen
2. Calcite 源码分析
Calcite 的Parser.jj定义了 SQL 解析的语法及代码模板,对比第一小节的例子,能够看到熟悉的语法开头:
options {
STATIC = false;
IGNORE_CASE = true;
UNICODE_INPUT = true;
}
PARSER_BEGIN(${parser.class})
package ${parser.package};
对应生成的类是SqlParserImpl.java
参考资料3里有一个非常用心的图,一目了然:
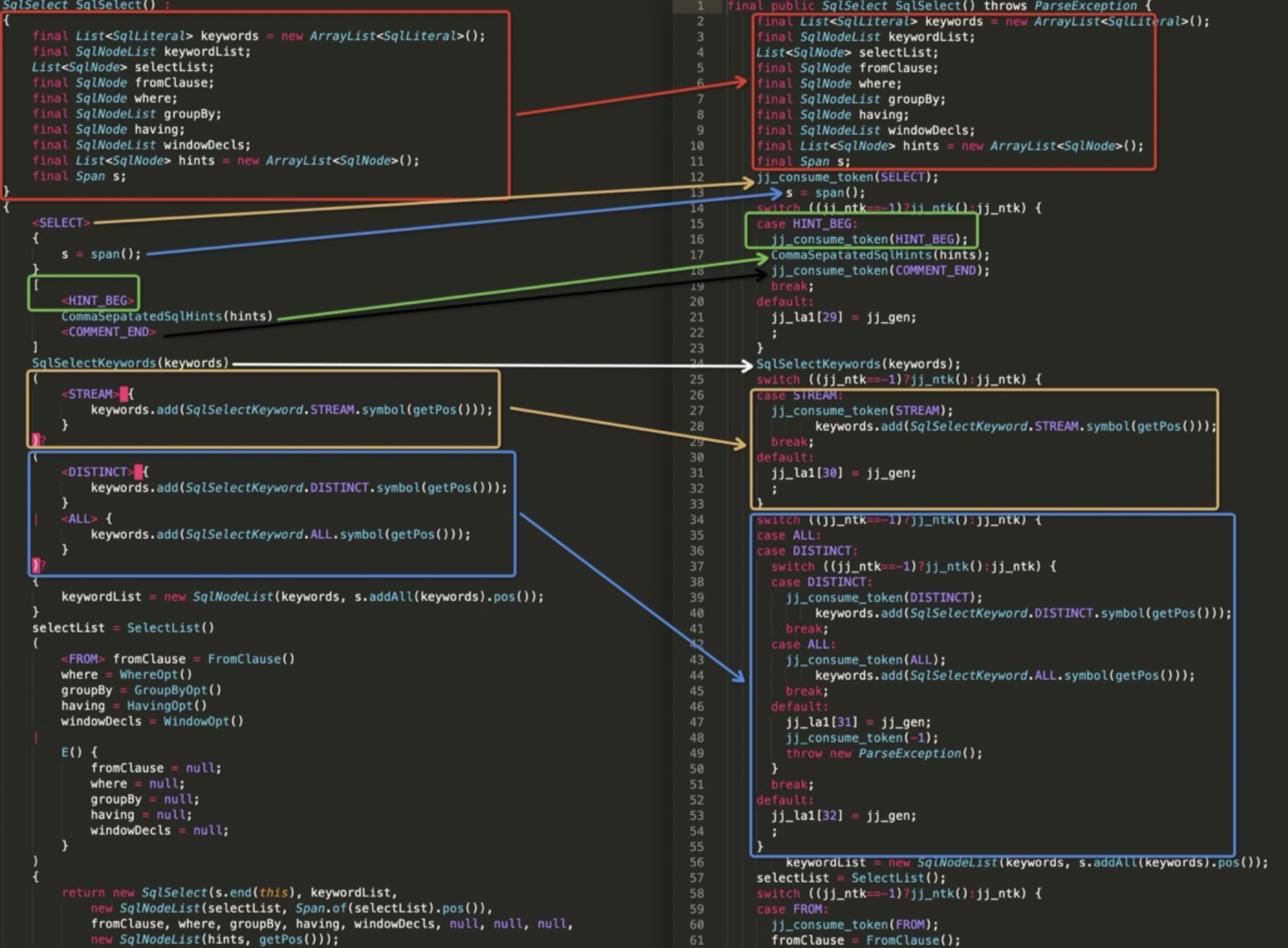
为避免拾人牙慧,就不多介绍了。
3. 总结
Calcite-3:处理流程的代码例子里创建的SqlParser,默认的 config 里使用的是SqlParserImplFactory:
public class SqlParser {
...
public interface Config {
/** Default configuration. */
Config DEFAULT = ImmutableBeans.create(Config.class)
.withLex(Lex.ORACLE)
.withIdentifierMaxLength(DEFAULT_IDENTIFIER_MAX_LENGTH)
.withConformance(SqlConformanceEnum.DEFAULT)
.withParserFactory(SqlParserImpl.FACTORY);
SqlParserImplFactory会构造SqlParserImpl,作为成员变量存储到SqlParser.
这两个类都是使用 javacc 工具加工 Parser.jj 生成的。Parser.jj 里详细定义了 SQL 解析需要的关键字以及对应的代码,例如SqlSelect、SqlInsert、SqlUpdate等类。
通过这些模板生成的代码,Calcite 就有了将 SQL 字符串转换为 SqlNode 树的能力,即完成 AST 阶段的工作。而到了执行阶段,则需要将RelNode转换为代码,因此又会需要代码生成、代码编译的能力。
整个流程理解下来,感觉有点像学习编译、链接的过程。不过想想也是,一种是解释 SQL,一种是解释代码。无论 SQL 还是代码,对于计算机来讲,我们都是汇编之上的高级语言了。