1. 简介
leveldb 无论哪一层文件,都是 sstable 的格式,即 Sorted String Table。
如果说 protobuf 是 google 通用的数据格式,那么 google 最流行的用于存储、处理、交换的数据输出方式之一,就是 sstable了。
If Protocol Buffers is the lingua franca of individual data record at Google, then the Sorted String Table (SSTable) is one of the most popular outputs for storing, processing, and exchanging datasets.
前面的笔记里,block和filter block都是 sstable 的一个组件,负责构造部分数据格式。本文介绍 sstable 的设计意图以及完整的数据格式实现,然后通过源码介绍数据格式的构造过程。
2. sstable
sstable,即 leveldb 后缀为 .sst/.ldb 的文件,被设计用于存储大量的 {key:value} 数据,当我们在 leveldb 查找某个 key 时,可能需要逐层查找多个 sstable 文件。
因此,sstable 在文件格式设计上,主要考虑:
- 查找速度,通过建索引解决
- 文件大小,通过压缩解决
3. 文件格式
为了优化查找速度,sstable 在逻辑上分为多个数据段。
3.1. data block 及索引
首先需要记录原始数据,即需要存储的 {key:value} 对,这是必不可缺的。
sstable 支持存储的 {key:value} 数目比较多,原始数据可能会比较大,查找某个 key 时,顺序 seek 全部数据太慢了。
因此需要把全部数据分为连续的多部分,每一部分称为一个 data block。对于每个 data block,记录3要素:
- offset:即 data block 的偏移量
- size:即 data block 的大小
- data_block_key:满足条件
>= block 内所有的 key
这样当查找某个 key 时,先跟 data_block_key 比较,判断可能存在于哪个 data block,如果存在,然后用 offset + size 快速定位这个 data block。
这个记录其实就是建索引的过程,称为 index block,有多少个 data block,索引就有多少行.
那么如何划分全部数据呢?
一种方式是根据 {key:value} 的个数,超过一定个数则使用新的 data block 存储,但是这样每个 data block 的大小就是不确定的,而对于磁盘而言,每次 seek 的范围如果是固定的,明显更友好(数据均匀化)。因此 leveldb 使用固定大小的方式来划分多个 data block,默认值是 block_size = 4k.
到这里,细心的读者可能会发现:data block 和 index block 虽然存储多种不同的数据,但是有个共同点:
schema相同:都是多条 key:value 组成,data block 无需多言,对 index block
key = data_block_key
value = (offset + size)
实际在实现上也是统一的类Block Builder来完成的。
3.2. filter block 及索引
levedb 支持设置 filter policy,例如 bloom filter。设置后,sstable 就会生成对应的 filter block,记录 filter policy 生成的数据。
查找 key 时,先通过 filter block 判断是否存在,如果不存在则直接跳过对应的 data block。由于 filter block 的查找时间复杂度是O(1)级别的,因此读性能可以显著提高。filter block的数据是 FilterBlockBuilder生成的。
跟 data block 一样,找到filter block 也需要建立一个索引数据,这个索引数据称为 meta index block.
在 leveldb 的设计中,meta block 预计是包含很多种类型的 blcok,不过当前只实现了 filter block,因此:
- meta block 当前等价于 filter block.
- meta index block 用于定位各种类型的 block,例如对于 filter block,在 meta index block 里这么记录
key=filter.Name, value=(offset + size),因此 meta index block 也是通过Block Builder实现的。
根据1 2,得出另一条结论:
meta index block 只包含了一组 {key:value} 数据。
3.3. footer
我们使用索引来定位 block,例如通过 index block 定位 data block, 通过 meta index block 定位 meta block,那么如何找到索引的位置呢?答案是靠 footer。也就是说 footer 记录了
index of data block'index
index of mata block'index
footer 需要首先读取、解析出来,然后才能“按图索骥”找到其他 block,因此 footer 是定长的,而且位置固定在文件尾部。
用一张图来直观的看下各个 block 的位置及作用:
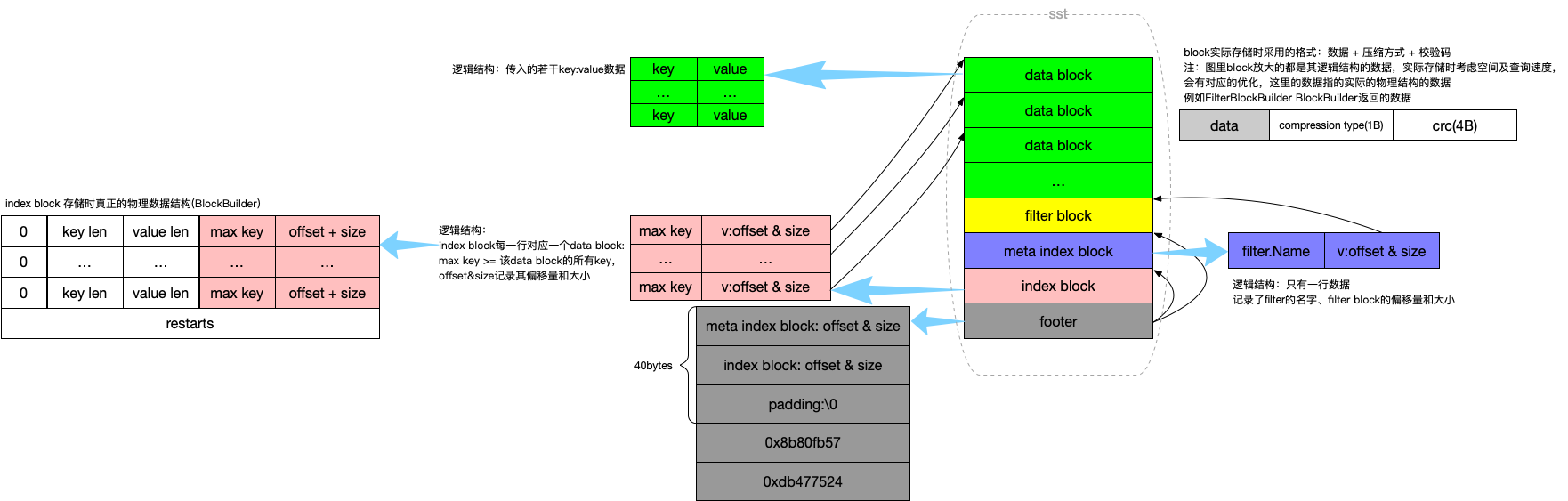
<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1]
...
[meta block K]
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
<end_of_file>
注:meta block按照 leveldb 的设计里,可能会有多种,filter block只是当前实现的一个。这也是为什么没有直接把 filter block 的 offset&size 写到 footer的原因。
4. class leveldb::TableBuilder
前面介绍了设计思路及数据格式,这一节开始介绍下实现部分。
TableBuilder被用来实现生成 sstable,实现上都封装到了class leveldb::TableBuilder::Rep (这是什么的缩写🤔).
示例图里的几个数据段,分别由Rep的几个成员对象负责构造:
struct TableBuilder::Rep {
...
//data block&&index block都采用相同的格式,通过BlockBuilder完成
//不过block_restart_interval参数不同
BlockBuilder data_block;
BlockBuilder index_block;
...
FilterBlockBuilder* filter_block;
...
5. 源码解析
上图里的结构也是文件实际的物理结构,data block 在最前,存储所有的 {key:value},写完之后再写入其他 block.
对应的,TableBuilder提供了两个接口:Add接收有序的 {key:value} 数据生成 data block,Finish追加其他 block 到文件,在介绍这两个接口之前,先介绍下一些辅助的类和函数。
5.1. BlockHandle
查找任意一个 block 数据块,都需要两条数据:offset && size.起到 handle block 作用,称为BlockHandle,支持序列化和反序列化。
class BlockHandle {
...
//|varint64(offset) |varint64(size) |
void EncodeTo(std::string* dst) const;
Status DecodeFrom(Slice* input);
// Maximum encoding length of a BlockHandle
// varint64后最多占10个字节
enum { kMaxEncodedLength = 10 + 10 };
private:
uint64_t offset_;
uint64_t size_;
};
EncodeTo就是把 offset && size 序列化到 value,实际上就是两次 varint.DecodeFrom是其逆过程。
因此,BlockHandle记录的就是 block 3要素里的前两个:offset && size.
5.2. Footer
Footer 记录了两份索引数据的偏移量和大小,即metaindex_handle_ index_handle_,对应示例图的 footer.
// Footer encapsulates the fixed information stored at the tail
// end of every table file.
class Footer {
...
void EncodeTo(std::string* dst) const;
Status DecodeFrom(Slice* input);
// Encoded length of a Footer. Note that the serialization of a
// Footer will always occupy exactly this many bytes. It consists
// of two block handles and a magic number.
enum {
kEncodedLength = 2*BlockHandle::kMaxEncodedLength + 8
};
private:
BlockHandle metaindex_handle_;
BlockHandle index_handle_;
};
EncodeTo即序列化Footer对象,该数据在文件最末尾写入,读取时需要先读取,因此序列化是定长的。
两个 block handle 相邻存储,最多占用 40 bytes,如果不足的话,padding 补 0,最后添加两个 magic words,因此总共占用48个字节,记录到了kEncodedLength。
magic words占8个字节,值为0xdb4775248b80fb57ull,来源比较有意思
# 取前8个字节
echo http://code.google.com/p/leveldb/ | sha1sum
db4775248b80fb57d0ce0768d85bcee39c230b61 -
读取时直接 seek 到 f.size() - 48,读取接下来的 48 个 bytes,就可以读到 footer EncodeTo 后的数据了。
5.3. WriteRawBlock
函数原型为
void TableBuilder::WriteRawBlock(const Slice& block_contents,
CompressionType type,
BlockHandle* handle);
依次写入block_contents、1bytes的compression_type、4bytes的的crc,其中后5个字节称为 BlockTrailer,大小定义为:
// 1-byte type + 32-bit crc
static const size_t kBlockTrailerSize = 5;
对应格式图里右上角部分,所有的 block,例如 data block/filter block/meta index block/index block,都按照|block_contents |compression_type |crc |这种格式组织,区别是 block_contents 格式不同。
handle为输出变量,记录写入前的文件offset 及 block_contents大小
5.4. WriteBlock
void WriteBlock(BlockBuilder* block, BlockHandle* handle);
其实就是从 block 取出数据,判断是否需要压缩,将最终结果调用WriteRawBlock.
判断是否压缩:
- 如果设置了
kNoCompression,那么一定不压缩 - 如果设置了
kSnappyCompression,那么尝试 snappy 压缩,如果压缩后的大小小于原来的 87.5%,那么使用压缩后的值,否则也不压缩
N个 data blocks, 1个 index block,1个 meta_index block,都使用这种方式写入,也就是都采用BlockBuilder构造的数据组织格式,filter block的数据格式由FilterBlockBuilder构造。
5.5. Flush
Flush主要是将r->data_block更新到文件,记录该 data block的offset及大小,等待下次Add or Finish时写入(原因参考Add)
//写入r->data_block到r->file
//更新pending_handle: size为r->data_block的大小,offset为写入data_block前的offset
//因此pending_handle可以定位一个完整的data_block
WriteBlock(&r->data_block, &r->pending_handle);
同时通知 filter block 新的 offset,fitlter block 通过这个接口判断上一个 data block 都包含哪些 keys.
r->filter_block->StartBlock(r->offset);
5.6. Add
讲了前面这么多,只是为了能把Add讲清楚😄
Add整体流程如图:
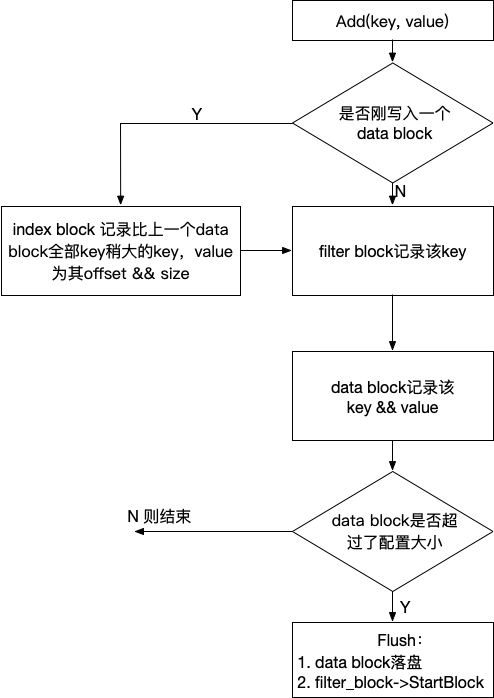
重点说下修改 index block 的部分:
//刚写入了一个data block后设置为true
if (r->pending_index_entry) {
assert(r->data_block.empty());
//计算满足>r->last_key && <= key的第一个字符串,存储到r->last_key
//例如(abcdefg, abcdxyz) -> *1st_arg = abcdf
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
//pending_handle记录的是上个block写入前的offset及大小
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
如果刚写入一个 data block,那么在 index block 里记录之,value 记录在pending_handle,用于定位该 data block.
r->options.comparator->FindShortestSeparator(&r->last_key, key);更新后的r->last_key满足条件:
刚好大于等于 data block 所有 key.
即 block 3要素的第3点:data_block_key.
这么构造 data_block_key 的好处是,当查找某个 target-key 时,如果 target-key > r->last_key,那么 target-key 一定大于该 data block 所有的key,因此不需要在 data block 查找了,也就是 index 的意义。
value 是该 data block 的 BlockHandle 序列化后的值。
5.7. Finish
Finish直接决定了完整的数据格式。
首先把未落盘的 {key: value} 落盘.
Rep* r = rep_;
//更新未写入的block
Flush();
assert(!r->closed);
r->closed = true;
写入 filter block,对应的 offset & size 记录到 filter_block_handle.
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
// Write filter block
// 一次性写入filter block
if (ok() && r->filter_block != nullptr) {
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
写入 meta index block, 即 filter block’s index. key 为 filter 名字,value为 filter_block_handle 序列化后的值,这个 block 只有一条数据。
// Write metaindex block
// 写入index of filter block,这里称为meta_index_block
if (ok()) {
//meta_index_block只写入一条数据
//key: filter.$filter_name
//value: filter_block的起始位置和大小
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
// Add mapping from "filter.Name" to location of filter data
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
写入 footer
// Write footer
if (ok()) {
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
一个完整的 sst 至此构造完成。
6. 例子
写了一个手动调用TableBuilder上述接口构造 sstable 的例子,能够更直观的看到各个接口调用后的效果。
首先Add几组数据调用Flush生成数据:
leveldb::TableBuilder table_builder(options, file);
table_builder.Add("confuse", "value");
table_builder.Add("contend", "value");
table_builder.Add("cope", "value");
table_builder.Add("copy", "value");
table_builder.Add("corn", "value");
//flush后的文件
//00000000: 0007 0563 6f6e 6675 7365 7661 6c75 6503 ...confusevalue.
//00000010: 0405 7465 6e64 7661 6c75 6502 0205 7065 ..tendvalue...pe
//00000020: 7661 6c75 6503 0105 7976 616c 7565 0004 value...yvalue..
//00000030: 0563 6f72 6e76 616c 7565 0000 0000 2e00 .cornvalue......
//00000040: 0000 0200 0000 00a7 ddaf 02 ...........
//文件70 bytes,为block_contents
//00 为CompressionType
//a7dd af02为crc
leveldb::Status status = table_builder.Finish();
std::cout << status.ToString() << std::endl;
block_contents可以参考leveldb block最后的例子,详细介绍了这70个 bytes 的数据生成过程。
调用close后,首先追加 meta index block:
meta_index_block(offset=75, size=8)未Add数据
因此block_contents: 00 0000 0001 0000 00
type && crc: 00 c0f2 a1b0
其次追加 index block:
index_block(offset=88, size=14)Add的数据为:key=d value=|varint64(0) |varint64(70) | ->0046
因此block_contents: 0001 0264 0046 0000 0000 0100 0000
type && crc: 0032 6ceb 60
最后追加 footer:
metaindex_handle: |varint64(75) |varint64(8) | -> 4b08
index_handle: |varint64(88) |varint64(14) | -> 580e
36个00用于补全
magic: 57 fb80 8b24 7547 db
这就是每一个字节的来源解释了,完整代码参见table_builder_test.