1. 简介
leveldb 里 sstable 文件里,有多个数据 block,其中 data block, index block,meta index block 都采用相同的数据格式,由类 BlockBuilder 负责生成。
本文主要分析 BlockBuilder 这个类的实现。
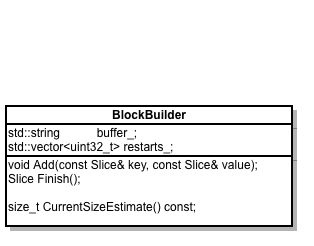
2. class leveldb::BlockBuilder
BlockBuilder 用于格式化传入的 key:value 数据,采用了 share key 的手段来优化存储的数据大小。
注意BlockBuilder本身并不与存储打交道,所有数据都格式化到了内存,通过Finish接口返回数据,由更上层对象写入到文件。
key:value通过Add接口传入,一组key:value被称为 entry。这个接口有一个假定的前提:传入的key是有序的,并且越来越大。
我们一步步来探索下BlockBuilder是怎么设计数据格式的,先不妨假设一种最简单的格式:
|key length |key |value length |value |...
这里有个明显的问题是没有应用 varint,因此可以这么改进
|varint(key length) |key |varint(value length) |value |...
而我们还忽略的一个特性是 key 有序,leveldb 的作者发现实际使用时,排序后的大量 key 之间经常有相同的前缀(实践出真知🐮),因此BlockBuilder构造一条 entry 的数据格式实际上是这样的:
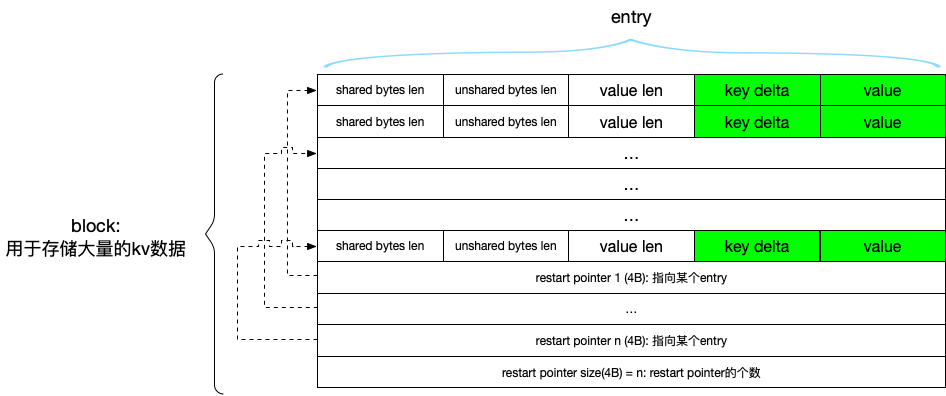
# len都经过varint处理
|shared key len |non-shared key len | value len |non-shared key |value |
简单总结规则就是:如果连续的 key 有相同的前缀,那么记录这个前缀的长度,后面的 key 只存储不同的部分。
而为了读取更加高效,每 N 条 entry则不再应用该规则,直接存储完整的 key. leveldb 称之为 restart,这条 entry 在文件的偏移量称之为一个 restart point.
N 对应代码里的block_restart_interval。
用一张图来总结 BlockBuilder 数据格式:
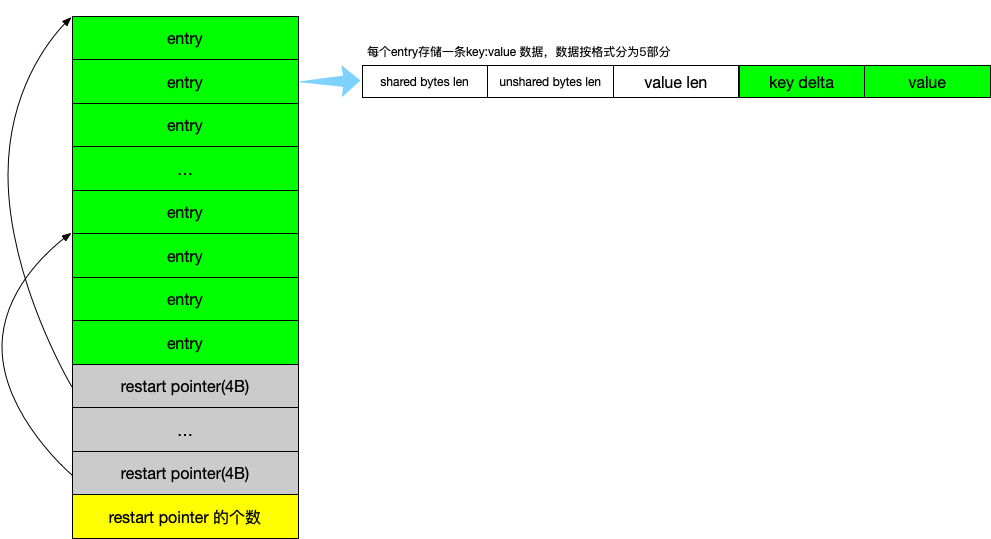
由 entry、restart point、sizeof(restart point) 三部分组成。
每一个 entry 都是由 key&&value 组成
3. 源码解析
3.1. construct
explicit BlockBuilder(const Options* options);
BlockBuilder构造函数非常简单,参数为leveldb::Options,只用到了两个参数:
comparator: 用来比较 key,确保Add接口传入的 key 是递增的block_restart_interval: 每 N 条则不再应用前缀优化记录的 key 大小,即 restart
restarts 数据初始化时,只包含 0,表示这是第一个 restart pointer.
3.2. Add
Add(const Slice& key, const Slice& value)
更新 key&&value 到 buffer,更新 restart pointer 数组。
- 如果 counter < block_restart_interval,计算当前 key 与上一个 key 的最大相同前缀
- 否则记录当前 buffer 大小到 restarts_ 数组, counter归零,当前 key 认为是这一轮第一个 key,相同前缀个数记为0
- buffer 添加
<shared><non_shared><value_size><non_shared key><value> - count++
3.3. Finish
Slice Finish();
在 buffer 后追加 restart_ 数组里的全部元素及数组大小。
注意这里元素及数组大小都是使用的原始大小,即4个 bytes,没有用 varint 可以在读取时更加方便。
4. 例子
我们可以直接使用BlockBuilder来构造数据,得到一个更直观的结果,代码位于 block_builder_test。
首先构造一个BlockBuilder对象,block_restart_interval默认值为16,为了用更少的代码观察到效果,设置为 4.
leveldb::Options option;
option.block_restart_interval = 4;
leveldb::BlockBuilder block_builder(&option);
写入第一条数据 ‘confuse:value’
//|shared key len |non-shared key len | value len |non-shared key |value |
//restarts_ = [0]
//0x00 07 05 c o n f u s e v a l u e
block_builder.Add("confuse", "value");//12
由于是第一条数据,share key为空,因此生成的数据为:
- shared key len = 0
- non-shared key len = sizeof(‘confuse’) = 7
- value len = sizeof(‘value’) = 5
- non-shared key = ‘confuse’
- value = ‘value’
接着写入第二条数据 ‘contend:value’
//0x03 04 05 t e n d v a l u e
block_builder.Add("contend", "value");//12
跟 ‘confuse’ 有3个相同前缀 ‘con’,因此生成的数据为:
- shared key len = 3
- non-shared key len = sizeof(‘tend’) = 4
- value len = sizeof(‘value’) = 5
- non-shared key = ‘tend’
- value = ‘value’
继续写入两条数据,判断是否有share key.
//0x02 02 05 p e v a l u e
block_builder.Add("cope", "value");//9
//0x03 01 05 y v a l u e
block_builder.Add("copy", "value");//9
目前为止已经写入了4条数据,下次写入时,就需要 restart 了
//当前buffer大小为2e
//restarts_ = [0, 2e]
//0x00 04 05 c o r n v a l u e
block_builder.Add("corn", "value");//8
restart 主要有两个效果:
- share key从新计算,因此share key len = 0
- 增加一个 restart point:值为当前 buffer.size
最后一步,调用Finish写入全部 restart points 及 个数: restarts = [0, 0x2e]
//0x00 00 00 00 2e 00 00 00 02 00 00 00
leveldb::Slice block_builder_buffer = block_builder.Finish();
写入全部数据完成,我们看下block_builder内的数据,其实就是前面分析所有数据的集合:
// 00000000: 0007 0563 6f6e 6675 7365 7661 6c75 6503 ...confusevalue.
// 00000010: 0405 7465 6e64 7661 6c75 6502 0205 7065 ..tendvalue...pe
// 00000020: 7661 6c75 6503 0105 7976 616c 7565 0004 value...yvalue..
// 00000030: 0563 6f72 6e76 616c 7565 0000 0000 2e00 .cornvalue......
// 00000040: 0000 0200 0000 ......
std::cout << block_builder_buffer.ToString();
有兴趣的读者可以继续推断下,不使用 share key/varint 后数据有多大,会发现更小一些…(这个例子看来不是很贴切😅,主要目的还是介绍机制)
在我看来,share key类似一种朴素的压缩想法,如果想关掉,直接设置block_restart_interval为1即可,就像 index block.如果我们指定了 TableBuilder 里的压缩方式,空间上也会有很好的压缩效果。