1. 简介
leveldb 里 sstable 文件里,有多个 block 组成。其中 filter block 用于提高 sstable 的读取效率,源码位于 filter_block.cc.
本文主要分析 filter block 的数据格式以及FilterBlockBuilder/FilterBlockReader类的实现。
2. 如何提高查找性能
在 leveldb 中,查找 data block使用二分法,能够达到 lg(n) 的复杂度,如果想进一步提高,就需要用到 filter block 了。
如果说 data block 的作用是查找 key 对应的 value,那么 filter block 则是查找 key 是否存在于该 data block,起到提前过滤的作用,这也是 filter block 名字的由来。
filter block的想法其实很简单,就是拿空间换时间,例如我们可以构造 data block 内所有 key 的 hash table,将hash table对应的序列化数据存储到 fitler block.leveldb 并没有直接这么做,而是采用了 bloom filter,在达到O(1)的前提下,用一个巧妙的办法使用了更少的空间。
3. 数据格式
同Block Builder一样,FilterBlockBuilder单纯的组织数据格式,并不会直接操作文件,我们先看下整体的数据格式:
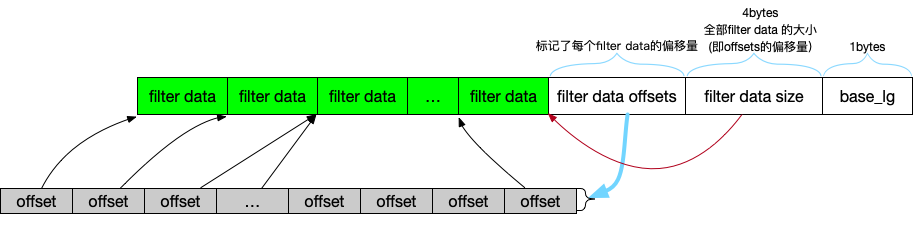
主要由几部分组成:
- N 段 filter data: filter policy 每传入一组 keys, 就会产出 filter data, 用于判断某个 key 是否存在于这组 keys.
- filter data offset: 数组结构,记录每段 filter data 的偏移量(注意数组元素个数可能 > N).
- filter data size: 1的总大小,也是数据2的offset(offset’s offset)😅
- base lg: 决定了2的数组元素个数,默认为11,即0x0b.
4. class FilterBlockBuilder
主要有 3 个接口,我们分别介绍下
4.1. AddKey(const Slice& key)
AddKey的实现非常简单,就是记录下传入的参数 key.
void FilterBlockBuilder::AddKey(const Slice& key) {
Slice k = key;
//start_记录key在keys的offset,因此可以还原出key
//为什么不直接使用std::vector<std::string>?
start_.push_back(keys_.size());
keys_.append(k.data(), k.size());
}
keys_记录了参数key,start_则记录了在keys_的偏移量,两者结合可以还原出key本来来。
注: 不理解为什么不直接用一个std::vector<std::string>参数记录
4.2. StartBlock(uint64_t block_offset)
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
//每2KB一个filter,计算当前数据大小总共需要多少个filter
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while (filter_index > filter_offsets_.size()) {
GenerateFilter();
}
}
kFilterBase为 2KB.
注意这里传入的参数block_offset跟 filter block 内的数据无关,这个值是 sstable 里 data block 的偏移量,新的 data block 产生时就会调用。
我们不记录偏移量,而是根据这个值,计算总共需要多少个 filter,然后依次调用GenerateFilter,如果block_offset较小可能一次也不会调用,较大可能多次调用,因此,data block 和 filter data 不是一一对应的。
GenerateFilter主要是更新result_和filter_offsets_,即数据格式里的1 2部分。
void FilterBlockBuilder::GenerateFilter() {
const size_t num_keys = start_.size();
//如果相比上一个filter data没有新的key
//那么只更新offsets数组就返回
if (num_keys == 0) {
// Fast path if there are no keys for this filter
filter_offsets_.push_back(result_.size());
return;
}
// Make list of keys from flattened key structure
// starts最后一个元素是keys_的总大小,此时starts元素个数=num_keys + 1
// 这样 [starts[i], starts[i+1]) 就可以还原所有的key了
start_.push_back(keys_.size()); // Simplify length computation
tmp_keys_.resize(num_keys);
//遍历start_,同时通过keys_获取当前记录的所有key,存储到tmp_keys_
for (size_t i = 0; i < num_keys; i++) {
const char* base = keys_.data() + start_[i];
size_t length = start_[i+1] - start_[i];
tmp_keys_[i] = Slice(base, length);
}
// Generate filter for current set of keys and append to result_.
// 记录当前result_大小,也就是新的filter数据的offset
filter_offsets_.push_back(result_.size());
// 生成filter数据,追加到result_
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
tmp_keys_.clear();
keys_.clear();
start_.clear();
}
从start_ keys_解析出最近 Add 的全部 key,记录到tmp_keys。将tmp_keys传入到 policy ,产出对应的 filter 数据。
filter 数据会追加到result_,同时在filter_offsets_记录起始位置。
最后清空相关变量,预备下一次写入。
注意如果有新 Add 的 key,GenerateFilter在生成对应的 filter 数据后,会清空 key.而如果 key 为空,则只是简单的把result_大小更新到filter_offsets。
StartBlock里while多次调用就会走到这个逻辑,因此一次StartBlock调用,可能不更新filter_offsets,也可能会更新多次filter_offsets,除了第一次调用,其余 append 的值都是相同的。
- 注:为什么
StartBlock不是只调用一次GenerateFilter,而是每 2KB 就产生一个 filter offset 的原因,在这里看起来并没有道理,接下来的FilterBlockReader会解释下 *
4.3. Finish
Slice FilterBlockBuilder::Finish() {
if (!start_.empty()) {
GenerateFilter();
}
// Append array of per-filter offsets
const uint32_t array_offset = result_.size();
// 每 4 个bytes记录1个filter_offsets
for (size_t i = 0; i < filter_offsets_.size(); i++) {
PutFixed32(&result_, filter_offsets_[i]);
}
//记录全部 filter 的总大小
PutFixed32(&result_, array_offset);
//11 = 0x0b
result_.push_back(kFilterBaseLg); // Save encoding parameter in result
return Slice(result_);
}
图例的数据格式在Finish组装并返回。
- 如果还有新增 key,那么在
result_追加对应的 filter data - 记录当前
result_的大小,即所有 filter data 的大小。然后result_追加所有的filter_offset,用于记录每个 filter data 的偏移量 - 追加2记录的
result_的大小,即filter_offset的偏移量,占 4 个bytes. - 追加
kFilterBaseLg,占 1 个bytes.
5. FilterBlockReader
跟 Block 与 BlockBuilder 的关系一样,FilterBlockReader用于读取FilterBlockBuilder产出的数据。通过介绍读取的过程,能够帮助读者更深入的理解一个 filter block 的数据格式。
构造函数传按照数据格式依次解析记录到base_lg_ data_ offset_ num_.
FilterBlockReader::FilterBlockReader(const FilterPolicy* policy,
const Slice& contents)
: policy_(policy),
data_(nullptr),
offset_(nullptr),
num_(0),
base_lg_(0) {
size_t n = contents.size();
if (n < 5) return; // 1 byte for base_lg_ and 4 for start of offset array
//最后1个字节记录kFilterBaseLg
base_lg_ = contents[n-1];
//base_lg_前4个字节,记录filter data总大小,也是filter offset的起始位置
uint32_t last_word = DecodeFixed32(contents.data() + n - 5);
if (last_word > n - 5) return;
data_ = contents.data();
//filter data offsets
offset_ = data_ + last_word;
//filter的个数
num_ = (n - 5 - last_word) / 4;
}
KeyMayMatch查找指定的key是否存在,注意filter不要求完全准确,因此只是可能存在。
另外一个参数是block_offset,跟FilterBlockBuilder::StartBlock一样,这里也是 sstable 里 data block 的偏移量。
bool FilterBlockReader::KeyMayMatch(uint64_t block_offset, const Slice& key) {
//位于哪个filter data
uint64_t index = block_offset >> base_lg_;
if (index < num_) {
//[start, limit)标记了一个block_offset对应的filter data
uint32_t start = DecodeFixed32(offset_ + index*4);
uint32_t limit = DecodeFixed32(offset_ + index*4 + 4);
if (start <= limit && limit <= static_cast<size_t>(offset_ - data_)) {
//取出 filter data,判断key是否存在
Slice filter = Slice(data_ + start, limit - start);
return policy_->KeyMayMatch(key, filter);
} else if (start == limit) {
// Empty filters do not match any keys
return false;
}
}
return true; // Errors are treated as potential matches
}
函数首先查找对应的 filter data,再通过 filter data 判断 key 是否存在。
block_offset每 2KB 就产生一个新的 filter data,因此对一个 data block,其对应的 filter data下标为block_offset / 2K。
回到 leveldb 查找 filter block 的场景,我们需要传入一个 data block 的 offset,然后通过 filter block 查找 key 是否存在。一种解决方案是,每一个 data block,产生一个 filter data,一一对应。那么在 filter block,还需要额外的空间记录所有的 offset,使用 2KB 这个方案则避免了这点。
当然,这个只是猜测,真实的原因无从确认,因为我个人更倾向于一一对应的解决方案。
6. 例子
照常写了一个单独测试的例子,辅助理解
int main() {
const leveldb::FilterPolicy* bloom_filter = leveldb::NewBloomFilterPolicy(10);
leveldb::FilterBlockBuilder filter_block_builder(bloom_filter);
filter_block_builder.StartBlock(0);
//1000 1431 1109 0002 06
filter_block_builder.AddKey("Hello");
filter_block_builder.AddKey("World");
filter_block_builder.StartBlock(3000);
//2002 0043 8821 4404 06
filter_block_builder.AddKey("Go");
filter_block_builder.AddKey("Programmer");
filter_block_builder.StartBlock(20000);
//1a38 64d0 c001 8300 06
filter_block_builder.AddKey("a");
filter_block_builder.AddKey("b");
filter_block_builder.AddKey("c");
leveldb::Slice result = filter_block_builder.Finish();
//00000000: 1000 1431 1109 0002 0620 0200 4388 2144 ...1..... ..C.!D
//00000010: 0406 1a38 64d0 c001 8300 0600 0000 0009 ...8d...........
//00000020: 0000 0012 0000 0012 0000 0012 0000 0012 ................
//00000030: 0000 0012 0000 0012 0000 0012 0000 0012 ................
//00000040: 0000 001b 0000 000b ........
// std::cout << result.ToString();
leveldb::FilterBlockReader filter_block_reader(bloom_filter, result);
std::cout << filter_block_reader.KeyMayMatch(0, "Hello") << std::endl;//1
std::cout << filter_block_reader.KeyMayMatch(0, "World") << std::endl;//1
std::cout << filter_block_reader.KeyMayMatch(0, "Go") << std::endl;//0
std::cout << filter_block_reader.KeyMayMatch(3000, "Go") << std::endl;//1
std::cout << filter_block_reader.KeyMayMatch(20000, "b") << std::endl;//1
std::cout << filter_block_reader.KeyMayMatch(20000, "d") << std::endl;//0
delete bloom_filter;
从KeyMayMatch的结果可以看到,block_offset的指定必须要准确。
result的结果如图所示:
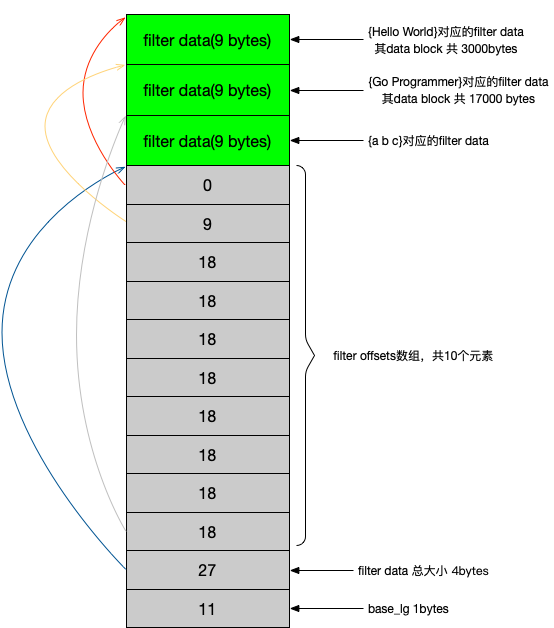
3段 filter data都占用 9 个字节,包含最少 8 个字节 + 1个字节存储hash函数个数。
filter offsets一共 10 个元素,
StartBlock(3000) 后 filter_offsets_ = {0}
StartBlock(20000) 后 filter_offsets_ = {0, 9, 18, 18, 18, 18, 18, 18, 18}
Finish 后 filter_offsets_ = {0, 9, 18, 18, 18, 18, 18, 18, 18, 18}
查找时,根据filter offsets数组 + filter data 总大小,首先找到 filter data 区间,例如KeyMayMatch(20000, "b"),首先计算 filter data 左边界:20000 / 2K = 9,对应的 filter data 偏移量为 18,即示例图灰线,右边界即为下一个元素存储的值 27,即示例图蓝线。
得到 filter data 区间后,交给 policy 查找是否存在。