上一篇笔记看到 restore state 时找不到 operator id 的问题:
Cannot map checkpoint/savepoint state for operator 77fec41789154996bfa76055dea29472 to the new program
这些数字的变化乍看非常奇怪,这篇笔记尝试分析下这些数字是如何生成的并且修复上个例子。
1. 唯一OperatorID
OperatorID 对应的就是 StreamGraph 里的节点 id,不过在 Transformation->StreamGraph 阶段,都还是自增的 id。在生成 JobGraph 时,会首先为每个 StreamNode 生成 hashID,代码入口在createJobGraph,通过StreamGraphHasherV2.traverseStreamGraphAndGenerateHashes得到。
定义唯一 id 最简单朴素高效的方式大概就是 UUID,但考虑最基础的情况,如果只是程序重启或者某个 transform 内部修改,id 可以保持不变,也就是当这个 JobGraph 没有发生改变时节点 id 无须改变。当节点只有后续节点改变,且后续节点改变对该节点没有影响时,该节点的 id 也无须变化。
因此,节点的 id 取决于 3 个因素:
- 节点在图中的位置,用于判断前序节点的部分图是否发生了变化
- 输入节点的id,判断输入节点是否发生变化
- 输出节点(chainable)的个数
其实不同的用途,id 取决的因素也会不同。这里也只是大概的猜测,flink 从通用性的角度,实现上也会更严格些,感兴趣的可以直接看下traverseStreamGraphAndGenerateHashes这块代码。
为了提高易用性,flink 还提供了手动设置Assigning Operator IDs的方式,uid接口用于生成节点 id.
2. traverseStreamGraphAndGenerateHashes
我们模仿traverseStreamGraphAndGenerateHashes实现一个简单的版本:
MicroStreamGraph记录了影响 hash 值的几个元素,如果没有设置uid,通过(输入节点id, chainable的出边个数,节点位置)计算,如果设置了uid,则基于设置值计算。
其中构造了两个StreamNodes,对应前面的两个例子:StreamWithStateSample、Word Count
object JobVertexGenerator extends App {
val hashFunction = Hashing.murmur3_128(0)
val hashes = mutable.HashMap.empty[Int, Array[Byte]]
// Plan
// {"nodes":[{"id":1,"type":"Source: Custom Source","pact":"Data Source","contents":"Source: Custom Source","parallelism":4},{"id":2,"type":"Map","pact":"Operator","contents":"Map","parallelism":4,"predecessors":[{"id":1,"ship_strategy":"FORWARD","side":"second"}]},{"id":4,"type":"Map","pact":"Operator","contents":"Map","parallelism":4,"predecessors":[{"id":2,"ship_strategy":"HASH","side":"second"}]},{"id":5,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to Std. Out","parallelism":4,"predecessors":[{"id":4,"ship_strategy":"FORWARD","side":"second"}]}]}
case class MicroStreamGraph(nodeId: Int,
userSpecifiedUID: String,
chainableOutEdgeCnt: Int,
inEdgeNodeIds: List[Int])
// https://izualzhy.cn/flink-source-kafka-checkpoint-init#3-reading-state
val streamNodes = List(
MicroStreamGraph(1, "source_uid", 1, List.empty[Int]),
MicroStreamGraph(2, null, 0, List(1)),
MicroStreamGraph(4, "count_uid", 1, List(2)),
MicroStreamGraph(5, null, 0, List(4))
)
/*
// https://izualzhy.cn/flink-source-job-graph
val streamNodes = List(
MicroStreamGraph(1, null, 1, List.empty[Int]),
MicroStreamGraph(2, null, 0, List(1)),
MicroStreamGraph(4, null, 0, List(2)),
MicroStreamGraph(5, null, 0, List(4))
)
*/
// StreamGraphHasherV2.traverseStreamGraphAndGenerateHashes
streamNodes.map{
case streamNode if streamNode.userSpecifiedUID == null =>
// StreamGraphHasherV2.generateDeterministicHash
val hasher = hashFunction.newHasher()
hasher.putInt(hashes.size)
(0 until streamNode.chainableOutEdgeCnt).foreach(_ => hasher.putInt(hashes.size))
val hash = hasher.hash().asBytes()
streamNode.inEdgeNodeIds.foreach{inEdgeNodeId =>
val inEdgeNodeHash = hashes(inEdgeNodeId)
println(s"inEdgeNodeHash:${byteToHexString(inEdgeNodeHash)}")
(0 until hash.length).foreach(i =>
hash(i) = (hash(i) * 37 ^ inEdgeNodeHash(i)).toByte)
}
println(s"hash:${byteToHexString(hash)}")
hashes.update(streamNode.nodeId, hash)
case streamNode if streamNode.userSpecifiedUID != null =>
// StreamGraphHasherV2.generateUserSpecifiedHash
// OperatorIDGenerator.fromUid
val hasher = hashFunction.newHasher()
hasher.putString(streamNode.userSpecifiedUID.toString, Charset.forName("UTF-8"))
hashes.update(streamNode.nodeId, hasher.hash().asBytes())
}
streamNodes.foreach(streamNode => println(s"${streamNode.nodeId} ${byteToHexString(hashes(streamNode.nodeId))}"))
}
对于第一个 StreamNodes,输出结果为
1 64248066b88fd35e9203cd469ffb4a53
2 d216482dd1005af6d275607ff9eabe2c
4 77fec41789154996bfa76055dea29472
5 f0bb9ed0d20321fef7413e1942e21550
可以看到这里跟读取 State时得到的 operatorID 是一致的。
也可以确认operatorID:77fec41789154996bfa76055dea29472的 state size = 2114,对应的就是map(new CountFunction)。
对于第二个 StreamNodes,输出结果为
1 cbc357ccb763df2852fee8c4fc7d55f2
2 7df19f87deec5680128845fd9a6ca18d
4 9dd63673dd41ea021b896d5203f3ba7c
5 1a936cb48657826a536f331e9fb33b5e
跟这里的日志一致。
注:搜 cbc357ccb763df2852fee8c4fc7d55f2,大部分都是关于 flink 的结果😅
事实上,启动StreamWithStateSample的日志里也记录了非uid的hash值(对于uid的 hash 值,flink默认不会记录到日志)
... DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash 'd216482dd1005af6d275607ff9eabe2c' for node 'Map-2' {id: 2, parallelism: 1, user function: org.apache.flink.streaming.api.scala.DataStream$$anon$4}
... DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash 'f0bb9ed0d20321fef7413e1942e21550' for node 'Sink: Print to Std. Out-5' {id: 5, parallelism: 1, user function: org.apache.flink.streaming.api.functions.sink.PrintSinkFunction}
到了这里,关于OperatorID报错的修复也就比较简单了,增加相同的uid即可。
// env.addSource(new MockKafkaSource).print()
env.addSource(new MockKafkaSource).uid("source_uid").print()
注:对比 flink 源码里的 java 实现,scala 的这个例子虽然代码行数更少,但是可读性并不高。源码里的这段逻辑并不简单,相比之前 State 的代码实现要优雅很多
3. OperatorID 应用
3.1. State
flink 支持有状态的计算,状态是跟每一个 JobVertexID 关联的,通过SavePoint.getOperatorStates接口声明也可以说明这点。从 state 恢复时也依赖逐个遍历且映射每个 OperatorID.
3.2. metrics
比如我们通过REST API查看例子里的 job 状态,可以看到这么一组 vertices:
{
...
"vertices":[
{
"id":"64248066b88fd35e9203cd469ffb4a53",
"name":"Source: Custom Source -> Map",
...
},
{
"id":"77fec41789154996bfa76055dea29472",
"name":"Map -> Sink: Print to Std. Out",
...
}
]
...
}
也就是实际运行时节点 chain 优化为了两条:
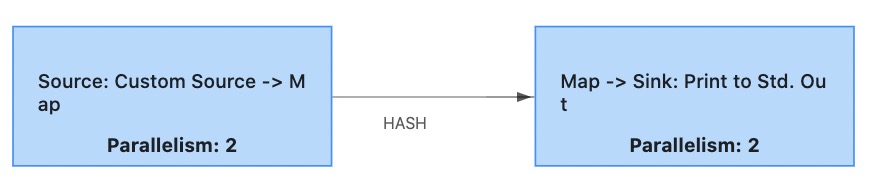
metrics 看到的节点都是每条 chain 的首节点,开启了Latency tracking后,也可以看到每个 OperatorID 之间的 latency,形如「latency.source_id.X.source_subtask_index.0.operator_id.Y.operator_subtask_index.3.latency_p99」.
4. 总结
StreamGraph 生成 JobGraph 的过程中,会为每个节点生成 hash id,生成规则为:
- 如果指定了 uid,则使用 uid hash 结果,如果确认 state 可以复用,就可以手动指定。
- 如果没有指定 uid,则跟输入节点的个数以及输入节点是否发生变化,所在图节点的位置,以及可 chain 的出边个数有关。
JobGraph chain 时,符合条件的节点被 chain 到首节点,相关监控都使用首节点 id.当然全部节点 id 也都记录下来,用于 latency 这类 metrics,state 存储等。例如在 latency metrci 的命名结构latency.source_id.X.source_subtask_index.0.operator_id.Y.operator_subtask_index.3.latency_p99」,其中 X Y 都是对应的 VertexID,如果能够使用uid name等可读性明显更高一些,最开始接触 flink 时在社区里也提过疑问,不过没有回应,后来看到LatencyMetric scope should include operator names,flink 的 owner 暂时不打算增加这个易用性的功能。