前面介绍了读取 state,这篇笔记介绍下 state 是如何触发写入的。
1. Why
考虑订阅 Kafka 写 HBase 的场景:
- 写入 HBase 时,为了获取最大的写入性能,可能会先缓存到内存然后批量写入
- 消费 Kafka 时,需要记录当前的 offsets,方便重启时继续消费。
因此,就需要有数据同步的机制,在上传 kafka 的 offsets 前,确保 hbase 收到了全部数据并且将内存的数据持久化,这就是 flink 里 checkpoint 的作用。
2. How
Fault Tolerance via State Snapshots 里这张图从理论上解释的非常清楚:

简单来讲,相比 spark 物理上微批处理的方式,flink 在逻辑上同样将数据分成了批次,数据是实时逐条处理,但是只有逻辑上一个批次处理完了,才会将 offsets 更新到 kafka.
how-apache-flink-manages-kafka-consumer-offsets这里也有更加清晰的介绍。
checkpoint 需要数据流上的算子整体参与协调完成:
- 当收到 checkpoint barrier 时,算子将当前内存的数据持久化
- 当数据流上全部算子完成 1 里的动作后,就可以认为 barrier 之前的数据各个算子都已经承诺处理完成,此时 source 算子可以将 offsets 上传到 kafka
这两个步骤,flink 分别通过两个类暴露出对应的接口:
CheckpointedFunction:initializeState用于初始化以及恢复state,snapshotState对应发起 checkpoint 或者收到 barrier 时的行为CheckpointListener: 各个算子的snapshotState都已完成后,调用notifyCheckpointComplete(long checkpointId)
注意 checkpoint 和 state 并不是强绑定的关系,在 checkpoint 时可以完成 state 同步到文件系统,也可以是将内存的数据持久化到存储系统,由算子内部决定。完成snapshotState意味着该算子承诺了 checkpointId 之前的数据处理完成。因此,可以猜测在 flink-runtime 里,需要保证在调用算子的snapshotState之前,一定已经将该 barrier 之前的全部数据交给了算子处理。这个顺序性,对所有的算子以及算子所有物理实例都是一致的。顺序性的保证,底层是多线程+锁还是单线程来实现,用户在实现一个算子时也应当是无感的。
大部分的文章都会强调 barrier 如何对齐,这的确是 checkpoint 理论中最重要的一环。不过在稍微了解了 barrier 的原理后,我们也会好奇 barrier 是从哪里来的,这些理论和 flink 暴露出来的接口是什么关系,对于自定义的 source/sink,应该如何实现确保数据不丢?
接下来通过一个例子,尝试把这些问题介绍一个初步的轮廓,方便感兴趣的读者继续深入理解。
3. 例子🌰
我们首先实现两个类:StateSource StateSink,这两个类都额外继承了CheckpointedFunction CheckpointListener
def logPrint(className: String)(msg: String) = {
println(s"${new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())} L${Thread.currentThread().getId} ${className} ${msg}")
}
class StateSource extends SourceFunction[String] with CheckpointedFunction with CheckpointListener {
private val log = logPrint(getClass.getSimpleName)_
override def run(ctx: SourceFunction.SourceContext[String]): Unit = {
(1 to 10000).foreach{i =>
log(s"send:${i}")
ctx.collect(i.toString)
Thread.sleep(1000)
}
}
override def cancel(): Unit = {}
override def initializeState(context: FunctionInitializationContext): Unit = {
log(s"initializeState")
}
override def snapshotState(context: FunctionSnapshotContext): Unit = {
log(s"snapshotState begin")
// log(s"snapshotState begin \n${Thread.currentThread().getStackTrace().mkString("\n")}")
Thread.sleep(10000)
log("snapshotState end")
}
override def notifyCheckpointComplete(checkpointId: Long): Unit = {
log(s"notifyCheckpointComplete ${checkpointId}")
}
}
class StateSink extends SinkFunction[String] with CheckpointedFunction with CheckpointListener {
private val log = logPrint(getClass.getSimpleName)_
override def invoke(value: String): Unit = {
log(s"recv:${value}")
}
override def initializeState(context: FunctionInitializationContext): Unit = {
log(s"initializeState")
}
override def snapshotState(context: FunctionSnapshotContext): Unit = {
log(s"snapshotState begin")
// log(s"snapshotState begin \n${Thread.currentThread().getStackTrace().mkString("\n")}")
Thread.sleep(10000)
log("snapshotState end")
}
override def notifyCheckpointComplete(checkpointId: Long): Unit = {
log(s"notifyCheckpointComplete ${checkpointId}")
}
}
可以看到实现非常简单,source 端每隔 1s 发送一条数据,source发送、sink接收时都会打印一条日志,同时两者都实现了snapshotState,sleep 10s 模拟一段持久化的操作。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val fsStateBackend = new FsStateBackend("file:///tmp")
env.setStateBackend(fsStateBackend)
env.enableCheckpointing(60000)
env.addSource(new StateSource)
.addSink(new StateSink)
.setParallelism(1)
env.execute(s"${getClass}")
为了聚焦问题,运行也非常简单,Source -> Sink,中间没有数据处理;为了确保 source/sink chain 为一个节点,我们设置 sink 的并发为1。
观察下输出:
2020-08-16 21:38:02 L53 StateSink initializeState
2020-08-16 21:38:02 L53 StateSource initializeState
2020-08-16 21:38:02 L55 StateSource send:1
2020-08-16 21:38:02 L55 StateSink recv:1
2020-08-16 21:38:03 L55 StateSource send:2
2020-08-16 21:38:03 L55 StateSink recv:2
2020-08-16 21:38:04 L55 StateSource send:3
2020-08-16 21:38:04 L55 StateSink recv:3
...
2020-08-16 21:38:55 L55 StateSource send:54
2020-08-16 21:38:55 L55 StateSink recv:54
2020-08-16 21:38:56 L66 StateSink snapshotState begin
2020-08-16 21:38:56 L55 StateSource send:55
2020-08-16 21:39:06 L66 StateSink snapshotState end
2020-08-16 21:39:06 L66 StateSource snapshotState begin
2020-08-16 21:39:16 L66 StateSource snapshotState end
2020-08-16 21:39:16 L55 StateSink recv:55
2020-08-16 21:39:16 L66 StateSink notifyCheckpointComplete 1
2020-08-16 21:39:16 L66 StateSource notifyCheckpointComplete 1
根据输出可以简单推断出:
- source/sink 处理数据是在同一个线程,因为 chain 为了一个 JobVertex,符合预期
- source/sink snapshotState 是在同一个线程,串行进行,一次 checkpoit 需要 20s;且跟处理数据不同线程
- 虽然 1 2 线程不同,不过从效果上看两者是互相阻塞的关系
- 21:38:56 StateSource 发送了数据
55,21:39:16 StateSink 收到了该数据,很明显 StateSink 在第一次snapshotState时还没有收到这条数据,那 StateSource 第一次snapshotState时如何确保不会包含该数据(类比 KafkaSource 的话,就是不能将 55 这种 on fly 的数据对应的 offset 上传,因为下游 StateSink 还没有确保收到并且持久化)
继续修改下代码 Source -> Sink 为 Source -> keyBy -> Sink,这样两者不会 chain 为一个 JobVertex
env.addSource(new StateSource)
.keyBy(i => i)
.addSink(new StateSink)
.setParallelism(1)
运行看下效果:
2020-08-16 22:07:00 L53 StateSource initializeState
2020-08-16 22:07:00 L57 StateSource send:1
2020-08-16 22:07:00 L55 StateSink initializeState
2020-08-16 22:07:00 L55 StateSink recv:1
2020-08-16 22:07:01 L57 StateSource send:2
2020-08-16 22:07:01 L55 StateSink recv:2
2020-08-16 22:07:02 L57 StateSource send:3
2020-08-16 22:07:02 L55 StateSink recv:3
...
2020-08-16 22:07:51 L55 StateSink snapshotState begin
2020-08-16 22:07:51 L68 StateSource snapshotState begin
2020-08-16 22:07:52 L57 StateSource send:52
2020-08-16 22:08:01 L55 StateSink snapshotState end
2020-08-16 22:08:01 L68 StateSource snapshotState end
2020-08-16 22:08:01 L68 StateSource notifyCheckpointComplete 1
2020-08-16 22:08:01 L73 StateSink notifyCheckpointComplete 1
2020-08-16 22:08:01 L55 StateSink recv:52
再分析下这里的输出:
- source 的处理和 snapshotState 仍然不是一个线程
- sink 的处理和 snapshotState 相同线程
- source/sink 的 snapshotState 由于是不同线程,因此是并行执行的,一次 checkpoint 需要 10s
- 同样需要考虑 on fly 的数据
4. 思考
上一节观察到的第二种情况,对应的是这么一个线程调用模型
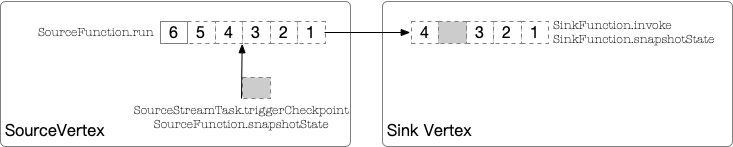
注:具体线程调用过程的代码解析,我们放到下一篇笔记单独分析
- source节点: 用户实现
SourceFunction.run流式的产出数据,当需要触发 checkpoint 时,会由其他线程添加一个标记数据发送到下游 - sink节点: 接收数据时,如果是普通数据,则调用
SinkFunction.invoke处理,如果是标记数据,则调用SinkFunction.snapshotState处理,这也就解释了为什么invoke/snapshotState线程号相同。
SinkFunction.snapshotState完成后,就意味着承诺了数据 1 2 3 已经处理,如果我们希望实现数据流的 At-Least Once,那么对于 source 节点来讲,需要将 lastOffset = 3(此次 checkpoint 的上一个i的值)记录下来。
- 生成数据是在
SourceFunction.run,这里可以记录i - 读取
i是在SourceFunction.snapshotState,同时需要确保恰好是发出 checkpoint barrier 之前的值
前面两种情况看到,1 2位于不同线程:
因此问题变成对 source 节点,这两个线程之间如何准确的同步 offset 数据?
具体来讲,数据源产出数据时需要暴露 offset 值,例如:
override def run(ctx: SourceFunction.SourceContext[String]): Unit = {
...
ctx.collect(i.toString)
lastOffset = i
...
}
而对添加标记数据的线程而言:
sendCheckpointBarrier(...)
override def SourceFunction.snapshotState(...) = {
...
currentOffset = lastOffset
...
}
这两个操作之间,lastOffset的值不能发生变化,需要确保跟下游看到的也是一致的。
flink 的处理方式也比较简单粗暴,就是强制的加了一个锁确保两者是同步的,因此我们在实现SourceFunction时,也需要考虑何时加锁的问题。
当 SourceVertex SinkVertex 的 snapshotState 已经完成,就会调用CheckpointListener.notifyCheckpointComplete方法通知感兴趣的算子,例如在 SourceVertex,我们可以这么做:
override def notifyCheckpointComplete(checkpointId: Long): Unit = {
persist((checkpoindId, currentOffset)
}
这样即使数据流重启,我们从持久化的(checkpointId, currentOffset)恢复,也就自然解决 At-Least Once 的需求了。
这个不符合我最开始的理解,预期用户不应该关注到这层实现。不过继续考虑下,这或许是最直接最朴素的一种做法。
5. 实现
这一节根据前面的分析看下源码实现,分别是 Kafka 记录以及上传 offsets,以及 HBase 的持久化。
5.1. Kafka
FlinkKafkaConsumerBase继承自RichParallelSourceFunction,在其run的实现里,从 topic 消费数据,然后通过SourceContext.collect产出,类似于StateSource.
循环委托给了AbstractFetcher,看下产出数据时的代码:
public abstract class AbstractFetcher<T, KPH> {
...
protected void emitRecord(T record, KafkaTopicPartitionState<KPH> partitionState, long offset) throws Exception {
if (record != null) {
if (timestampWatermarkMode == NO_TIMESTAMPS_WATERMARKS) {
// fast path logic, in case there are no watermarks
// emit the record, using the checkpoint lock to guarantee
// atomicity of record emission and offset state update
synchronized (checkpointLock) {
sourceContext.collect(record);
partitionState.setOffset(offset);
}
} ...
}
可以看到加了一把锁checkpointLock,使得 发送数据和设置 offset 是原子的。
再看下 snapshotState 的实现:
public abstract class FlinkKafkaConsumerBase<T> extends RichParallelSourceFunction<T> implements
...
public final void snapshotState(FunctionSnapshotContext context) throws Exception {
...
HashMap<KafkaTopicPartition, Long> currentOffsets = fetcher.snapshotCurrentState();
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
// the map cannot be asynchronously updated, because only one checkpoint call can happen
// on this function at a time: either snapshotState() or notifyCheckpointComplete()
pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets);
}
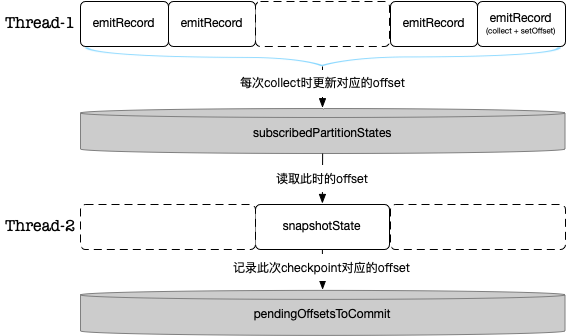
将currentOffsets记录到了pendingOffsetsToCommit,这是一个checkpointId -> offsets的 HashMap 结构,currentOffsets通过AbstractFetcher.snapshotCurrentState获取
public HashMap<KafkaTopicPartition, Long> snapshotCurrentState() {
// this method assumes that the checkpoint lock is held
assert Thread.holdsLock(checkpointLock);
HashMap<KafkaTopicPartition, Long> state = new HashMap<>(subscribedPartitionStates.size());
for (KafkaTopicPartitionState<KPH> partition : subscribedPartitionStates) {
state.put(partition.getKafkaTopicPartition(), partition.getOffset());
}
return state;
}
subscribedPartitionStates即emitRecord里的partitionState,同时注意注释假定已经持有了checkpointLock,这样就保证了这里读取到的 offsets 对应的数据已经发送出去。
当所有算子的snapshotState完成,flink 调用算子的notifyCheckpointComplete
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
...
try {
final int posInMap = pendingOffsetsToCommit.indexOf(checkpointId);
...
Map<KafkaTopicPartition, Long> offsets =
(Map<KafkaTopicPartition, Long>) pendingOffsetsToCommit.remove(posInMap);
...
// 上传 offsets 到 kafka 的 __consumer_offsets
fetcher.commitInternalOffsetsToKafka(offsets, offsetCommitCallback);
可以看到此时将对应 checkpoint 的 offsets 更新到 kafka 就可以了。
一图胜千言:
5.2. HBase
HBase 的实现比 Kafka 简单很多,只需要关注snapshotState就可以了,而实现该函数时,不需要用户确保跟invoke的同步关系。
如果跟 source 相同 vertex,flink 通过 checkpointLock 同步,如果不同,则跟invoke天然在一个线程。
public class HBaseUpsertSinkFunction
extends RichSinkFunction<Tuple2<Boolean, Row>>
implements CheckpointedFunction, BufferedMutator.ExceptionListener {
...
// 接收数据,先缓存,超过一定数量批量 flush
public void invoke(Tuple2<Boolean, Row> value, Context context) throws Exception {
checkErrorAndRethrow();
if (value.f0) {
Put put = helper.createPutMutation(value.f1);
mutator.mutate(put);
} else {
Delete delete = helper.createDeleteMutation(value.f1);
mutator.mutate(delete);
}
// flush when the buffer number of mutations greater than the configured max size.
if (bufferFlushMaxMutations > 0 && numPendingRequests.incrementAndGet() >= bufferFlushMaxMutations) {
flush();
}
}
// 收到 checkpoint barrier,则 flush 确保数据写入
public void snapshotState(FunctionSnapshotContext context) throws Exception {
while (numPendingRequests.get() != 0) {
flush();
}
}
6. 思考Again
可以看到对于非 source 算子,实现起来还是比较简单的。对于一些非常简单的数据流,其实完全和 barrier 没有产生任何关系,更多的是靠一个超大范围的锁来提供数据不丢的底层架构。
但是对于 source 算子,flink 暴露出的接口就没有这么优雅了。或许可以将锁封装到SourceContext.collect内部避免用户需要自行加锁,或者我理解无论是普通数据,还是 CheckpointBarrier,最终都是放到发送的 FIFO 队列,能否支持写入一些额外的数据例如offsets logid等,这样 flink 就可以自行完成SourceFunction.snapshotState的行为,在notifyCheckpointComplete时再返回给用户。当然,flink 需要考虑的场景太多,例如 exactly-once 等,基于这些复杂场景大概最终折衷是这样一个实现,我们的思考更多是纸上谈兵了。
从逻辑上看,需要锁住的范围应该只是记录对应的 offset,这个锁的范围应该尽可能的小,那么其底层是怎样一个过程?细心的读者可能也会发现,这篇笔记里还没有介绍清楚一个问题,如果要确保数据不丢,那么 source 发送 barrier 前的数据需要恰好是 snapshotState 记录的 offset。state 和 checkpoint 的关系是什么?是何时落盘的?