上篇笔记介绍了从用户视角看如何正确的应用 state,不过要想进一步确认一些猜测,例如对于 kafka-source,是如何确保snapshotState与emitRecord互相阻塞执行的,发送 CheckpointBarrier 时怎么保证 barrier 与普通数据的顺序性?这篇笔记比较简单,我们直接撸一下代码。
1. StackTrace
把上篇笔记例子里的getStackTrace的日志打开,当 source sink 位于不同的 vertex 时,source 的调用是从 SourceStreamTask -> StreamTask -> AbstractUdfStreamOperator:
java.lang.Thread.getStackTrace(Thread.java:1559)
cn.izualzhy.flink.SourceSinkStateSample$StateSource.snapshotState(SourceSinkStateSample.scala:40)
org.apache.flink.streaming.util.functions.StreamingFunctionUtils.trySnapshotFunctionState(StreamingFunctionUtils.java:118)
org.apache.flink.streaming.util.functions.StreamingFunctionUtils.snapshotFunctionState(StreamingFunctionUtils.java:99)
org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.snapshotState(AbstractUdfStreamOperator.java:90)
org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:399)
org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.checkpointStreamOperator(StreamTask.java:1282)
org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.executeCheckpointing(StreamTask.java:1216)
org.apache.flink.streaming.runtime.tasks.StreamTask.checkpointState(StreamTask.java:872)
org.apache.flink.streaming.runtime.tasks.StreamTask.performCheckpoint(StreamTask.java:777)
org.apache.flink.streaming.runtime.tasks.StreamTask.triggerCheckpoint(StreamTask.java:686)
org.apache.flink.streaming.runtime.tasks.SourceStreamTask.triggerCheckpoint(SourceStreamTask.java:179)
org.apache.flink.runtime.taskmanager.Task$1.run(Task.java:1155)
java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
java.util.concurrent.FutureTask.run(FutureTask.java:266)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
java.lang.Thread.run(Thread.java:748)
sink 的调用,是 StreamTask -> AbstractUdfStreamOperator
java.lang.Thread.getStackTrace(Thread.java:1559)
cn.izualzhy.flink.SourceSinkStateSample$StateSink.snapshotState(SourceSinkStateSample.scala:61)
org.apache.flink.streaming.util.functions.StreamingFunctionUtils.trySnapshotFunctionState(StreamingFunctionUtils.java:118)
org.apache.flink.streaming.util.functions.StreamingFunctionUtils.snapshotFunctionState(StreamingFunctionUtils.java:99)
org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.snapshotState(AbstractUdfStreamOperator.java:90)
org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:399)
org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.checkpointStreamOperator(StreamTask.java:1282)
org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.executeCheckpointing(StreamTask.java:1216)
org.apache.flink.streaming.runtime.tasks.StreamTask.checkpointState(StreamTask.java:872)
org.apache.flink.streaming.runtime.tasks.StreamTask.performCheckpoint(StreamTask.java:777)
org.apache.flink.streaming.runtime.tasks.StreamTask.triggerCheckpointOnBarrier(StreamTask.java:708)
org.apache.flink.streaming.runtime.io.CheckpointBarrierHandler.notifyCheckpoint(CheckpointBarrierHandler.java:88)
org.apache.flink.streaming.runtime.io.CheckpointBarrierAligner.processBarrier(CheckpointBarrierAligner.java:113)
org.apache.flink.streaming.runtime.io.CheckpointedInputGate.pollNext(CheckpointedInputGate.java:155)
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.pollNextNullable(StreamTaskNetworkInput.java:102)
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.pollNextNullable(StreamTaskNetworkInput.java:47)
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:135)
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:279)
org.apache.flink.streaming.runtime.tasks.StreamTask.run(StreamTask.java:301)
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:406)
org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:705)
org.apache.flink.runtime.taskmanager.Task.run(Task.java:530)
java.lang.Thread.run(Thread.java:748
两者入口不同,source 多了 SourceStreamTask,线程函数的入口是在SourceStreamTask.triggerCheckpoint;sink 的入口是在StreamTask.invoke,在processInput过程中,如果发现是CheckpointBarrier,则调用CheckpointBarrierAligner.processBarrier开始处理。两者最终都统一到了StreamTask.performCheckpoint,进而调用AbstractUdfStreamOperator.snapshotState一直到调用用户实现的snapshotState。
接下来从 Source 节点和非 Source 节点分别看下源码。
2. Task.triggerCheckpointBarrier
根据栈的日志,Source 节点入口在 Task.java:1155,对应triggerCheckpointBarrier函数,该函数定义了一个Runnable提交到一个线程单独运行。
Runnable runnable = new Runnable() {
@Override
public void run() {
...
try {
boolean success = invokable.triggerCheckpoint(checkpointMetaData, checkpointOptions, advanceToEndOfEventTime);
...
};
executeAsyncCallRunnable(
runnable,
String.format("Checkpoint Trigger for %s (%s).", taskNameWithSubtask, executionId));
invokable.triggerCheckpoint即SourceStreamTask.triggerCheckpointc,接下来StreamTask.triggerCheckpoint -> StreamTask.performCheckpoint。
performCheckpoint重点说下:
private boolean performCheckpoint(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
CheckpointMetrics checkpointMetrics,
boolean advanceToEndOfTime) throws Exception {
...
synchronized (lock) {
if (isRunning) {
// All of the following steps happen as an atomic step from the perspective of barriers and
// records/watermarks/timers/callbacks.
// We generally try to emit the checkpoint barrier as soon as possible to not affect downstream
// checkpoint alignments
// Step (1): Prepare the checkpoint, allow operators to do some pre-barrier work.
// The pre-barrier work should be nothing or minimal in the common case.
operatorChain.prepareSnapshotPreBarrier(checkpointId);
// Step (2): Send the checkpoint barrier downstream
operatorChain.broadcastCheckpointBarrier(
checkpointId,
checkpointMetaData.getTimestamp(),
checkpointOptions);
// Step (3): Take the state snapshot. This should be largely asynchronous, to not
// impact progress of the streaming topology
checkpointState(checkpointMetaData, checkpointOptions, checkpointMetrics);
...
可以看到先尝试持有 lock,这把锁实际上就是 kafka emitRecord 时的 checkpointLock,接下里注释比较清楚了,其中broadcastCheckpointBarrier往下游发送 barrier,checkpointState调用当前节点各个算子的snapshotState.
2.1. OperatorChain.broadcastCheckpointBarrier
创建CheckpointBarrier对象发送到下游(应该是所有的物理输出边?待确认)
public void broadcastCheckpointBarrier(long id, long timestamp, CheckpointOptions checkpointOptions) throws IOException {
CheckpointBarrier barrier = new CheckpointBarrier(id, timestamp, checkpointOptions);
for (RecordWriterOutput<?> streamOutput : streamOutputs) {
streamOutput.broadcastEvent(barrier);
}
}
2.2. StreamTask.checkpointState
创建CheckpointingOperation,调用executeCheckpointing,主要完成两个动作:
- 调用节点上所有 operator 调用
checkpointStreamOperator方法,这里会调用用户的 snapshotState 方法 - 异步线程等待 checkpoint 完成
public void executeCheckpointing() throws Exception {
startSyncPartNano = System.nanoTime();
try {
for (StreamOperator<?> op : allOperators) {
checkpointStreamOperator(op);
}
...
// we are transferring ownership over snapshotInProgressList for cleanup to the thread, active on submit
AsyncCheckpointRunnable asyncCheckpointRunnable = new AsyncCheckpointRunnable(
owner,
operatorSnapshotsInProgress,
checkpointMetaData,
checkpointMetrics,
startAsyncPartNano);
owner.cancelables.registerCloseable(asyncCheckpointRunnable);
owner.asyncOperationsThreadPool.execute(asyncCheckpointRunnable);
2.2.1. checkpointStreamOperator
private void checkpointStreamOperator(StreamOperator<?> op) throws Exception {
if (null != op) {
OperatorSnapshotFutures snapshotInProgress = op.snapshotState(
checkpointMetaData.getCheckpointId(),
checkpointMetaData.getTimestamp(),
checkpointOptions,
storageLocation);
operatorSnapshotsInProgress.put(op.getOperatorID(), snapshotInProgress);
}
}
这里也有一个snapshotState方法,不过参数和返回值跟用户看到的不同,存在两个snapshotState方法,同时这里类继承的层次较繁琐,因此我们直接用图来表示下整体重要的流程:
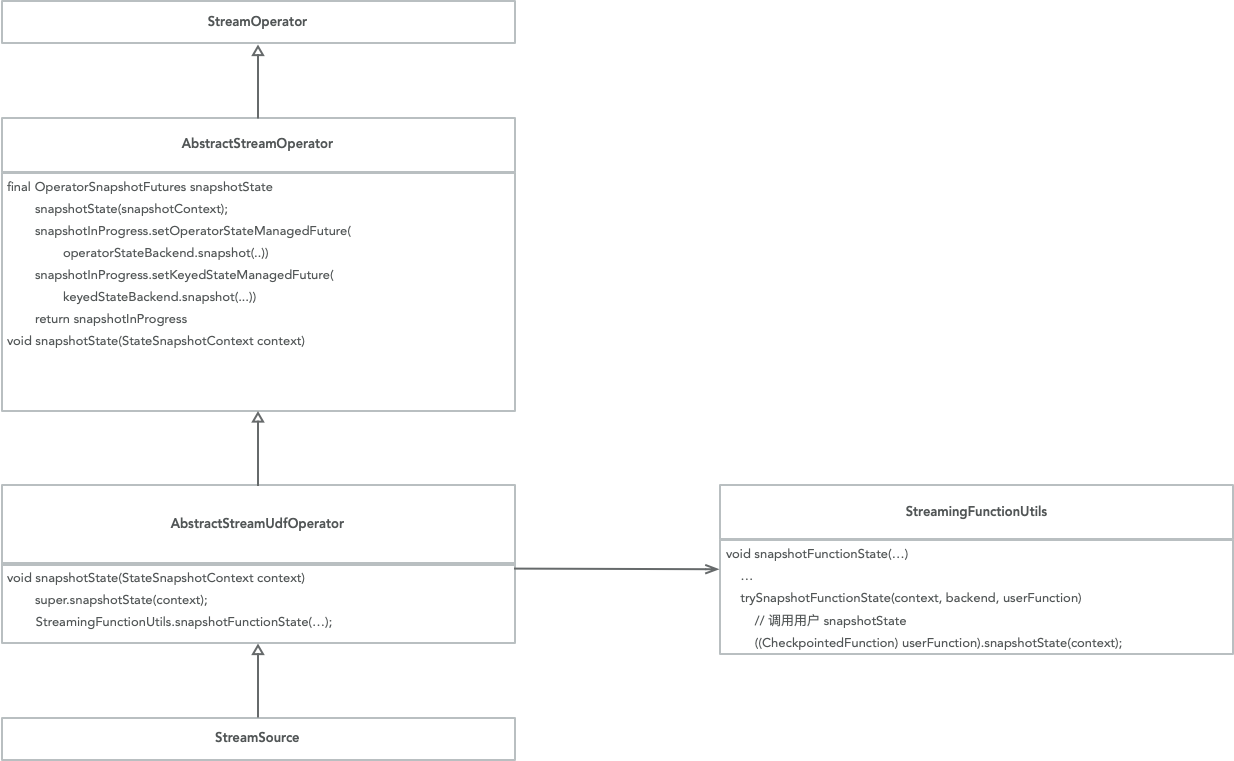
source 节点对应的是这个系列开篇时介绍的StreamSource,op.snapshotState对应的是AbstractStreamOperator.snapshotState,从这个函数入手再去看图里的流程会清晰一些。
我们自定义的snapshotState调用是在StreamingFunctionUtils,在这篇笔记开始的日志里也可以看到完整流程的栈信息。
而 state 真正的持久化是在调用operatorStateBackend.snaphost keyedStateBackend.snapshot,返回了一个 future.注:待确认😴,由于目前为止的这些函数调用都是在持有 checkpointLock 的情况下,而对 kafka-source,emitRecord 时同样需要持有这把锁,因此持久化不需要也不应该继续持有 checkpointLock.
2.2. AsyncCheckpointRunnable
异步等待返回的snapshotInProgress执行完成,之后回应 JobManager 本次 checkpointId 已完成。
3. StreamTask.processInput
非 Source 节点的入口在StreamTask.invoke,也是普通数据的处理入口,这也是我们上一篇笔记里看到snapshotState invoke是同一个线程的原因。对应的自定义的 Sink 实现也就会简单一些,不需要考虑checkpointLock的问题。
检测如果是CheckpointBarrier,则在CheckpointBarrierAligner.processBarrier里判断是否需要调用snapshotState,之后的调用就都是一致的了。
4. Summary
经过源码分析后,把上一篇的线程调用模型图再丰富一下:
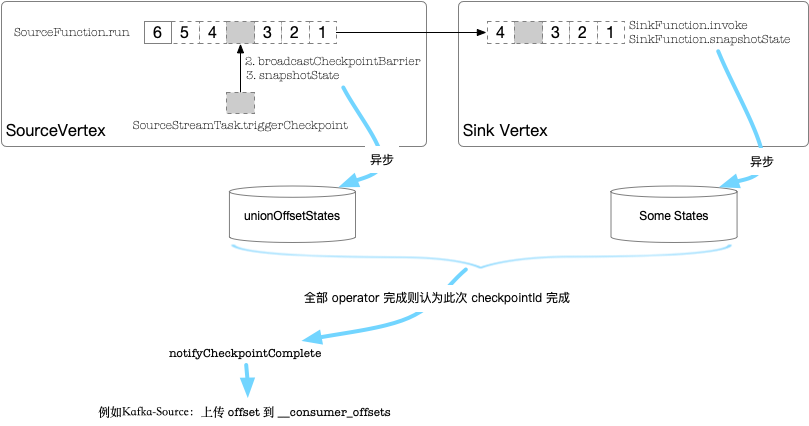
在 1.11 里貌似增加了类似 barrier 对齐之类的新的特性,不过整体的思路不会有大的变化。我们可以看到在流式处理时,仍然会有“批量”的需求,例如上传 kafka 的 offsets,不可能每条数据都上传一次;存储系统更希望批量写入,例如 redis 的 pipeline,hbase 的 mutation,在这点上 spark 的微批思想(一次性交给用户t时间的数据处理)更直观和实用一些。flink 的做法是在实时的同时,通过 CheckpointBarrier 引入了逻辑上的批次(t时间内,每收到一条数据就交给用户处理,时间截止时,通知用户该批次已完成),思想上更先进一些,但用户的理解成本和实现复杂度上,也自然的增加了一些。