年前开始接触 flink,到现在已经有三个月的时间了,除了最开始简单看了下 flink 的启动过程,最近一直被其 scala 及 SQL API 搞的很虚。这个假期得空,终于开始盘点下。
这篇笔记介绍下 transformations 的生成过程。
其实 flink 相关介绍网上比比皆是,为了避免拾人牙慧,本文主要介绍下自己的理解,参考文章附录在文末。
1. 开篇
以 flink 里的 Hello World 为例:
val text = env.socketTextStream("127.0.0.1", 8011)
text.flatMap(new FlatMapFunction[String, (String, Int)] {
override def flatMap(value: String, out: Collector[(String, Int)]): Unit = {
val tokens = value.toLowerCase().split("\\W+")
tokens.foreach(token => out.collect((token, 1)))
}
}).setParallelism(1)
.keyBy(0)
.sum(1).setParallelism(1)
.print()
对 API 的每一次调用,都会转换为对应的一个 Transformation,env 会记录所有的 Transformation。
public abstract class StreamExecutionEnvironment {
protected final List<Transformation<?>> transformations = new ArrayList<>()
例如示例代码会生成这样的链接关系:

每一个 Transformation,都记录了其唯一 id, name 等。具体需要执行的操作,通过对不同的 API 初始化不同的 Transformation 子类,或者相同子类的不同 operator 来实现。
这篇笔记主要就是介绍下,用户的 API 调用如何转换为 Transformation,这些 Transformation 在代码结构里又是如何存储的?
2. Transformation
class Transformation 是所有子类的基类,除了 id name,还有 outputType parallelism 等基础属性:
public abstract class Transformation<T> {
protected final int id;
protected String name;
protected TypeInformation<T> outputType;
private int parallelism;
这里先只列举下本文相关的子类关系
+----------------+
+---> Transformation <-----------------------+
| +----------------+ |
| |
| |
+-------------------+----+ +------------+------------+
| PhysicalTransformation <----------------------+ | PartitionTransformation |
+---------+-----------+--+ | +-------------------------+
^ ^ |
| | |
+--------------------+---+ +--+-------------------+ ++-------------------+
| OneInputTransformation | | SourceTransformation | | SinkTransformation |
+------------------------+ +----------------------+ +--------------------+
3. SourceTransformation
val text = env.socketTextStream("127.0.0.1", 8011) 返回了 text,类型为 DataStream。我们接下来对 text 的各种操作,例如 flatmap、keyBy…,会产生新的 DataStream、KeyedStream…,但是 stream 更多的是在充当 API “载体”的作用,其本质还是在构建出新的 Transformation.
对应的,DataStream 定义了 Transformation 成员变量:
public class DataStream<T> {
protected final StreamExecutionEnvironment environment;
protected final Transformation<T> transformation;
前面的图里可以看到,Transformation 是一个链表的结构,通过其 input 可以递归回溯到源头,源头子类为 SourceTransformation,负责数据的接入。
env.socketTextStream
return addSource(new SocketTextStreamFunction(hostname, port, delimiter, maxRetry),
SocketTextStreamFunction 继承自 SourceFunction,实现了 run 方法监听 socket,并且返回接收到的数据。
addSource 则构造了 SourceTransformation
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo)
...
final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function);
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
super(environment, new SourceTransformation<>(sourceName, operator, outTypeInfo, environment.getParallelism()));
this.environment = Preconditions.checkNotNull(environment, "Execution Environment must not be null.");
this.transformation = Preconditions.checkNotNull(transformation, "Stream Transformation must not be null.");
DataStreamSource 是 DataStream 的子类,初始化过程中就会构造 SourceTransformation,并且记录到DataStream.transformation 变量。
这就是 SourceTransformation 的构造过程,同时也可以看到类的 has-a 关系: SourceFunction ∈ StreamSource ∈ SourceTransformation ∈ DataStreamSource
4. Transformations
接下来就是各种数据变换的算子,这些算子有的会记录到 env.transformations,逐个介绍下:
4.1. flatMap
// 传入的 operator 为 StreamFlatMap
transform("Flat Map", outType, new StreamFlatMap<>(clean(flatMapper)));
跟 SourceTransformation 类似,从这行代码可以看到 FlatMapFunction ∈ StreamFlatMap ∈ OneInputTransformation 的类关系。
transform 函数在构造 Transformation 时经常用到,其主要作用为构造 operator 对应的 Transformation,添加到 transformations 列表 并且返回新的 DataStream.
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
// 传入 operator,构造 OneInputTransformation
// 注意第一个参数为 this.transformation,作为 resultTransform 的输入
// 这样就会形成一个链表的效果
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
// 返回 SingleOutputStreamOperator,即 DataStream
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
// 添加到 StreamExecutionEnvironment.transformations
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
4.2. keyBy
keyBy 传入 DataStream,构造出 KeyedStream,跟 Transformation 有关的是 ParitionTransformation,用于修改输入数据的 partitioning.
public KeyedStream(DataStream<T> dataStream, KeySelector<T, KEY> keySelector, TypeInformation<KEY> keyType) {
this(
dataStream,
new PartitionTransformation<>(
dataStream.getTransformation(),
new KeyGroupStreamPartitioner<>(keySelector, StreamGraphGenerator.DEFAULT_LOWER_BOUND_MAX_PARALLELISM)),
keySelector,
keyType);
}
类似的,PartitionTransformation 会将上一个 transformation 传进来作为自己的 input,不同点在于 partition 过程没有具体操作函数参与,其重点在于如何对流 Partition,例如我们这里是一个 KeyGroupStreamPartitioner.
4.3. KeyedStream.sum
该函数最后还是会调用到 DataStream.transform:
aggregate(AggregationType.SUM, position)
transform
resultTransform = new OneInputTransformation<>(
// keyBy 产出的 PartitionTransformation:
new PartitionTransformation<>(
dataStream.getTransformation(),
new KeyGroupStreamPartitioner<>(keySelector, StreamGraphGenerator.DEFAULT_LOWER_BOUND_MAX_PARALLELISM))
// "aggregation"
// StreamGroupedReduce
...
)
4.4. Print
Print 初始化 sinkFunction,并调用 addSink 传入
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
return addSink(printFunction).name("Print to Std. Out");
// sink 对应的 operator
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
// 同样先记录输入的 transformation
new SinkTransformation<T>(inputStream.getTransformation(), "Unnamed", operator, ...);
// 添加到 transformations
getExecutionEnvironment().addOperator(sink.getTransformation())
可以看到 flatMap sum print 过程中调用了addOperator。因此最终env.transformations包含3个元素:
// 1. OneInputTransformation{id=2, name='Flat Map', outputType=scala.Tuple2(_1: String, _2: Integer), parallelism=1}
// 2. OneInputTransformation{id=4, name='aggregation', outputType=scala.Tuple2(_1: String, _2: Integer), parallelism=1}
// 3. SinkTransformation{id=5, name='Print to Std. Out', outputType=GenericType<java.lang.Object>, parallelism=4}
这个数据结构将作为生成 StreamGraph 的基础。
对应到我们示例里的类关系,从这个角度看其实现的结构分层还是很清晰的:
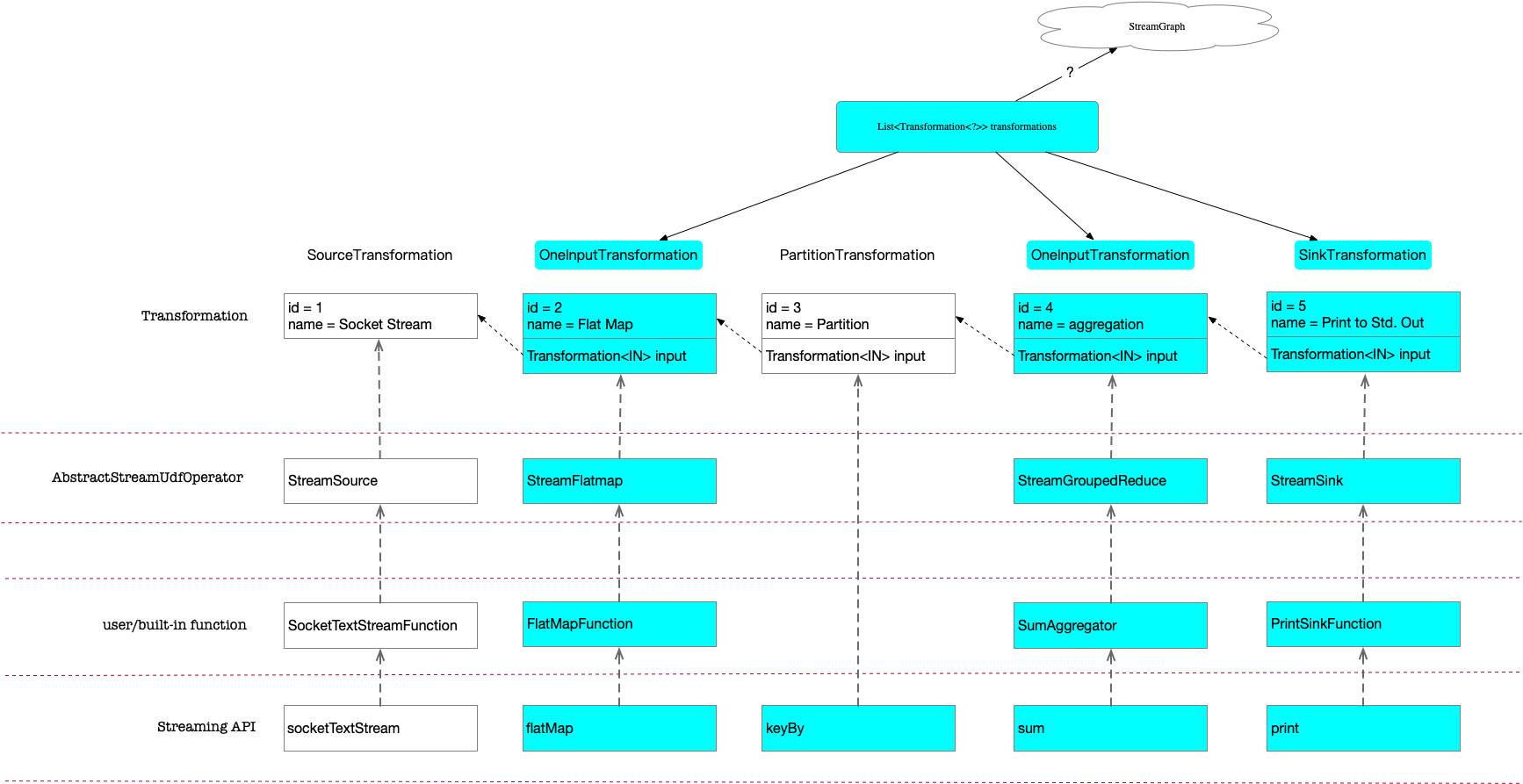
注意只有 id = 2 4 5 调用了addOperator添加到了 transformations 列表,为什么只加入了这三个节点,以及基于该列表如何生成 StreamGraph,会在下一篇笔记展开介绍。
5. 类关系
最开始看代码时,被 flink 类的命名绕的很晕,这里记录下:
DataStream API 会生成新的 DataStream,其相关的部分子类:
+------------+
+------------>+ DataStream +<----------------+
| +--------+---+ |
| ^ |
| | |
+-------------+-------------+ +---+---------+ +------+------+
|SingleOutputStreamOperator | | SplitStream | | KeyedStream |
+--+-------------------+----+ +-------------+ +-------------+
^ ^
| |
+---------+--------+ +------+-----------+
| IterativeStream | | DataStreamSource |
+------------------+ +------------------+
Transformation 里记录的 Operator:
+----------------+
| StreamOperator |
++--------+------+
^ ^
| |
+-----------------------++ ++-----------------------+
| AbstractStreamOperator | | OneInputStreamOperator +<-+
+----------------+ +--------+---------------+ +--------^---------------+ |
| SourceFunction | ^ | |
+-----------+----+ | | |
^ +--------------+------------+ | |
| | AbstractUdfStreamOperator <-------------------------------------+
| +--+------------------+-----+ | |
| ^ ^ | |
| | | | |
+-+---------+--+ +----------+----------+ +--------+------+ +------+-----+
| StreamSource | | StreamGroupedReduce | | StreamFlatMap | | StreamSink |
+--------------+ +---------------------+ +---------------+ +------------+
可以看到所有的 Operator 都继承自AbstractUdfStreamOperator,该类有一个成员变量
protected final F userFunction;
无论是我们自定义的函数,例如 FlatMapFunction,还是系统内置函数,例如 SocketTextStreamFunction PrintSinkFunction,都被记录到了这里,作为真正待执行的变换函数。