上一篇笔记介绍由 API 生成StreamExecutionEnvironment.transformations,接下来就是生成 StreamGraph.
StreamExecutionEnvironment.execute里包含了诸如 StreamGraph、JobGraph、?等流程。
具体在StreamGraphGenerator.generate:
StreamGraph generate() {
streamGraph = new StreamGraph(executionConfig, checkpointConfig);
...
alreadyTransformed = new HashMap<>();
for (Transformation<?> transformation: transformations) {
// 更新 streamGraph 的顶点和边
transform(transformation);
}
final StreamGraph builtStreamGraph = streamGraph;
...
return builtStreamGraph;
这段代码遍历 transformations,逐个元素调用 transform,返回构建好的 StreamGraph.
核心思想在于将 Transformation 转化为图节点,并且建立节点之间的边关系,在建立边关系的过程中,如果输入 Transformation 还没有转化为图节点,那么就递归首先创建上游节点。
1. StreamGraphGenerator.transform
StreamGraphGenerator.transform就是对前一篇笔记里介绍的不同的 Transformation 类型调用不同的方法。
private Collection<Integer> transform(Transformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
...
Collection<Integer> transformedIds;
if (transform instanceof OneInputTransformation<?, ?>) {
transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform);
} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {
transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);
} else if (transform instanceof SourceTransformation<?>) {
transformedIds = transformSource((SourceTransformation<?>) transform);
} else if (transform instanceof SinkTransformation<?>) {
transformedIds = transformSink((SinkTransformation<?>) transform);
} else if (transform instanceof UnionTransformation<?>) {
transformedIds = transformUnion((UnionTransformation<?>) transform);
} else if (transform instanceof SplitTransformation<?>) {
transformedIds = transformSplit((SplitTransformation<?>) transform);
} else if (transform instanceof SelectTransformation<?>) {
transformedIds = transformSelect((SelectTransformation<?>) transform);
} else if (transform instanceof FeedbackTransformation<?>) {
transformedIds = transformFeedback((FeedbackTransformation<?>) transform);
} else if (transform instanceof CoFeedbackTransformation<?>) {
transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);
} else if (transform instanceof PartitionTransformation<?>) {
transformedIds = transformPartition((PartitionTransformation<?>) transform);
} else if (transform instanceof SideOutputTransformation<?>) {
transformedIds = transformSideOutput((SideOutputTransformation<?>) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
...
return transformedIds;
}
例如对于对SourceTransformation调用 transformSource,对SinkTransformation调用transformSink,对OneInputTransformation调用transformOneInputTransform.
虽然 transformXXXX 实现不同,但是其本质上都在做一件事情:生成对应的节点(StreamNode)及边(StreamEdge) 添加到 StreamGraph.
2. 图(StreamGrpah)、节点(StreamNode)与边(StreamEdge)
StreamGraph 最主要的是由一系列节点(StreamNode)组成的,StreamNode 内部又记录了当前节点输入与输出的边。
class StreamGraph
Map<Integer, StreamNode> streamNodes
每个 StreamNode 记录了其输入边、输出边,以及该节点需要真正执行的操作函数(封装在operatorFactory,其内部即 AbstractUdfStreamOperator、StreamSource 等)
StreamNode
// 节点 id,即对应的 transform.id
private final int id;
private List<StreamEdge> inEdges = new ArrayList<StreamEdge>();
private List<StreamEdge> outEdges = new ArrayList<StreamEdge>();
// 该Node的执行函数
private transient StreamOperatorFactory<?> operatorFactory;
StreamEdge 起到了连接两个 StreamNode 的作用,自然的,记录了输入及输出节点的 id
class StreamEdge
private final int sourceId;
private final int targetId;
// partitioner 的方式,例如 hash 还是 forward
private StreamPartitioner<?> outputPartitioner;
额外的,有些 transform 不会生成StreamNode,例如keyBy产生的PartitionTransformation,实际上是在设置两个节点的连接方式,也就是边的属性(上游节点的数据是如何发送到下游节点)。因此在生成过程中,先生成临时节点,下游通过边连接到该节点时,转发给上游,起到连接上下游节点的作用。
这些临时节点在 StreamGraph 称为虚拟节点,使用 virtualXXXXNodes 存储:
class StreamGraph
private Map<Integer, Tuple2<Integer, List<String>>> virtualSelectNodes;
private Map<Integer, Tuple2<Integer, OutputTag>> virtualSideOutputNodes;
private Map<Integer, Tuple3<Integer, StreamPartitioner<?>, ShuffleMode>> virtualPartitionNodes;
3. addSource addSink addOperator
对应的,这 3 个函数负责创建节点,addOperator负责创建StreamNode,其调用addNode new 出 StreamNode(记录节点序号以及具体执行的操作),并且将该节点加入到StreamGraph.streamNodes
addSource addSink底层还是调用的addOperator,不过增加了记录输入源及输出汇的过程。
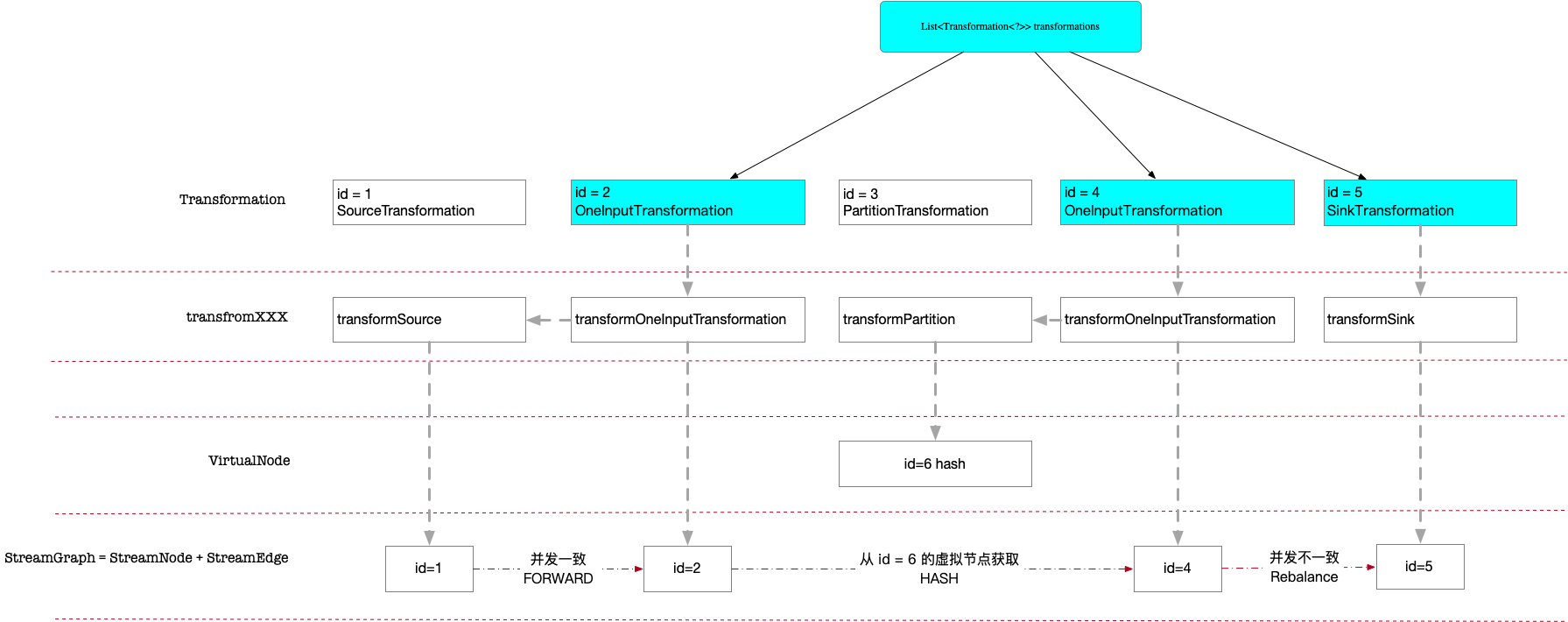
4. 例子流程
前面介绍了StreamNode、StreamEdge的定义以及具体的添加入口函数addOperator
这一节还是结合前一篇笔记的例子,具体说明下。
虽然 transformations 只记录了 id = (2, 4, 5),但是每个元素生成对应的 StreamNode 时,都会首先检查其输入元素是否已经转化为 StreamNode,例如对于 id = 2 的 FlatMap 操作:
4.1. transformOneInputTransform(id = 2)
private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) {
// 先查找输入对应的 StreamNode.id,即 transform.id = 1 对应的 StreamNode
Collection<Integer> inputIds = transform(transform.getInput());
// 创建节点
// transforma.id 作为节点的 StreamNode.id,同时也会作为该函数的返回值
streamGraph.addOperator
// 相比 SourceTransformation,OneInputTransformation 会构造 StreamEdge,并且分别增加到上游节点的出边和下游节点的入边
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}
// 返回节点 ID
return Collections.singleton(transform.getId());
注意第一行是一个递归操作,先需要 transform id = 1 的元素,即 SourceTransformation:
// 创建输入 Transformation 对应的 StreamNode,并且返回对应的 StreamNode.id
private <T> Collection<Integer> transformSource(SourceTransformation<T> source) {
// 传入了 sourceId = 1,source.getOperatorFactory 即包装了 AbstractUdfStreamOperator
streamGraph.addSource
addOperator(vertexID, slotSharingGroup, coLocationGroup, operatorFactory, inTypeInfo, outTypeInfo, operatorName);
sources.add(vertexID);
接着上一段代码第一行,返回的 id = 1 存储到了inputIds,之后 id = (1, 2) 对应的 StreamNode 都已经构建完成,接下来就是创建两个节点间边的关系,当前先忽略处理 virutalxxxxNodes 的相关代码,关注最后一个 else :
StreamGraph.addEdge
// 处理各种 virtualXXXXNodes
if ...
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
// 获取该虚拟节点的上游节点,例如通过 6 获取 2
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
// 获取了上游节点的 ID,partition,shuffle方式后,创建上游节点到下游节点的边
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode);
else
// 分别获取上游节点、下游节点
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// 当 partitioner 未设置时
// 如果两者 parallism 一致,则连接方式为 ForwardPartition,否则为 RebalancePartition
// 也就是说 partitioner 代表了上下游节点的并行度关系
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (shuffleMode == null) {
shuffleMode = ShuffleMode.UNDEFINED;
}
// new StreamEdge,包含了上下游节点及 partitioner
// 上游节点的 outEdges 增加下游节点
// 下游节点的 inEdges 增加上游节点
StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber, outputNames, partitioner, outputTag, shuffleMode);
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
4.2. transformOneInputTransform(id = 4)
接下来处理 id = 4,跟 id = 2 一样,入口为transformOneInputTransform,区别是其上游元素 id = 3 对应的是一个 VirtualPartitionNode,因此 addEdge 时会有区别
private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) {
// 先查找输入对应的 StreamNode.id,即 transform.id = 3 对应的 StreamNode
// 返回的 StreamNode.id = 6
Collection<Integer> inputIds = transform(transform.getInput());
// 构建 id=4 的 StreamNode
streamGraph.addOperator
// 相比 SourceTransformation,OneInputTransformation 会构造 StreamEdge,并且分别增加到上游节点的出边和下游节点的入边
for (Integer inputId: inputIds) {
// 由于 6 是 virtualPartitonNodes,因此 addEdge 其实是连接了 6 的上游节点2和下游节点4
// inputId=6, transform.getId()=4
streamGraph.addEdge(inputId, transform.getId(), 0);
}
// 返回节点 ID
return Collections.singleton(transform.getId());
代码第一行,id = 3 的元素类型为PartitionTransformation,因此调用transformPartition转换为节点
private <T> Collection<Integer> transformPartition(PartitionTransformation<T> partition) {
// 先获取 transform 的input,即 id = 2 的 OneInputTransformation
Transformation<T> input = partition.getInput();
List<Integer> resultIds = new ArrayList<>();
// 查找的输入对应的 StreamNode.id,即 id = 2
Collection<Integer> transformedIds = transform(input);
for (Integer transformedId: transformedIds) {
// virtualId = 6
int virtualId = Transformation.getNewNodeId();
streamGraph.addVirtualPartitionNode(
transformedId, virtualId, partition.getPartitioner(), partition.getShuffleMode());
resultIds.add(virtualId);
}
// 返回 veirtualId = 6
return resultIds;
可以看到这里没有添加 StreamNode,而是记录到了 virtualPartitonNodes,同时该节点记录了其上游节点 ID(=2)。同时注意这里指定了partitioner
addVirtualPartitionNode
记录到 virtualPartitionNodes:
含义为 6 的上游是 2 节点,partition 方式为 HASH
virtualId(6) -> (originalId=2, partitoner="HASH", shuffleMode="UNDEFINED")
接下来的代码跟上一节类似,区别是当下游节点跟该节点建立边关系的时候,实际上是获取对应的上游节点建立边,例如创建的不是 6->4 而是 2->4。
具体代码可以参考addEdge里的virtualPartitionNodes。
4.3. transformOneInputTransform(id = 5)
对应的是transformedIds = transformSink((SinkTransformation<?>) transform);
private <T> Collection<Integer> transformSink(SinkTransformation<T> sink) {
streamGraph.addSink(sink.getId(),
// sink 同样要记录边的关系
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId,
sink.getId(),
0
);
}
// 已经到结尾了,返回空列表
return Collections.emptyList();
可以看到对StreamExecutionEnvironment.transformations,都会调用addEdge产生对应的边关系。
5. 类关系
类似上一篇笔记,整体的调用流程可以归纳为:
如果我们打印出getExecutionPlan,放到 https://flink.apache.org/visualizer/ 这里来看的话,也是同样的 streamgraph 结构。

因为getExecutionPlan也是调用的StreamGrpah.getStreamingPlanAsJSON
6. 思考
- 为什么有这几层图结构?
- 为什么 transformations 只记录了 3 个节点? 首先可以看到这 3 个节点是足够用于生成 streamgraph 了,事实上我理解可能只传入尾节点元素也足够了,因为生成 streamgraph 的过程中也是一个先构建其上一个节点的过程。大概是代码的设计需要,或者当有多个输入边时的复杂情况。
- 如果打开 flink 的 DEBUG 日志,就会看到这个 transform 的过程
2020-05-02 18:05:11,108 DEBUG org.apache.flink.streaming.api.graph.StreamGraphGenerator - Transforming OneInputTransformation{id=2, name='Flat Map', outputType=scala.Tuple2(_1: String, _2: Integer), parallelism=1} 2020-05-02 18:05:11,108 DEBUG org.apache.flink.streaming.api.graph.StreamGraphGenerator - Transforming SourceTransformation{id=1, name='Socket Stream', outputType=String, parallelism=1} 2020-05-02 18:05:11,116 DEBUG org.apache.flink.streaming.api.graph.StreamGraph - Vertex: 1 2020-05-02 18:05:11,119 DEBUG org.apache.flink.streaming.api.graph.StreamGraph - Vertex: 2 2020-05-02 18:05:11,121 DEBUG org.apache.flink.streaming.api.graph.StreamGraphGenerator - Transforming OneInputTransformation{id=4, name='aggregation', outputType=scala.Tuple2(_1: String, _2: Integer), parallelism=1} ...