生成StreamGraph后,接下来就是构造 JobGraph 了,这一步主要的变化是将尽可能合并多个相邻的 StreamNode.
1. Why
在分布式计算中,多个节点交换数据都通过 rpc 完成,这其中就少不了网络传输、序列化与反序列化的一系列过程,如果能够优化为硬盘或者内存处理,例如对于map(...).filt(...),理论上完全可以在本地串行计算完成,避免全量传输map的结果,在性能上明显就会有提高。
Flink 从 StreamGraph 转化为 JobGrpah 的过程,主要就是这个目的。例如对于 A → B → C → D 的调用顺序,如果 A B 可以合并为本地处理,那么就可以生成 A’ → C → D 新的 DAG 图,这就是 StreamGraph → JobGraph 的过程。
2. StreamingJobGraphGenerator
跟class StreamGraphGenerator生成 StreamGraph 类似,StreamingJobGraphGenerator生成 JobGraph,而 JobGraph 由 JobVertex + JobEdge 组成。
public class StreamingJobGraphGenerator {
...
// StreamNode.id 对应的 JobVertex
private final Map<Integer, JobVertex> jobVertices;
private final JobGraph jobGraph;
private final Map<Integer, Map<Integer, StreamConfig>> chainedConfigs;
// StreamNode.id 对应的 StreamConfig,包含了 checkpoint,operator 等信息
private final Map<Integer, StreamConfig> vertexConfigs;
...
创建 jobGraph 的入口在createJobGraph
private JobGraph createJobGraph() {
// make sure that all vertices start immediately
jobGraph.setScheduleMode(streamGraph.getScheduleMode());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
// 从 stream.getSourceIDs() 开始,遍历所有的 StreamNode,创建对应该能的一个 hash值
// 接下来对节点的 chain 优化,都使用 hash 值标记,而不再使用递增的 NodeId,因为 hash 值能够确保 StreamNode 是否发生了改变
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
...
setChaining(hashes, legacyHashes, chainedOperatorHashes);
...
Flink 将这个合并的过程称为 chain,通过setChainning实现:
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes, Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes) {
for (Integer sourceNodeId : streamGraph.getSourceIDs()) {
createChain(sourceNodeId, sourceNodeId, hashes, legacyHashes, 0, chainedOperatorHashes);
}
}
主要就是遍历所有的源节点,调用createChain
3. createChain
合并节点的核心思想我理解其实就是一个贪心算法:
从首节点开始,尝试构造一条chain,将原来多个 StreamNode 合成一个;如果不能,则以新的节点为首节点,继续尝试构造一条chain,直到遇到尾结点。当所有的节点遍历完成,就构造出了一个优化后的调用链,达到上一节提到的目的。
对应的,createChain 是一个递归函数:
- startNodeId: 当前 chain 的初始节点ID
- currentNodeId: 当前节点 ID
- hashes/leagcyHashes: 输入参数,全部 StreamNode 节点的 hash 值
- chainIndex: chain 下标(从0开始)
- chainedOperatorHashes: Map结构,在执行过程中不断填充,大小与 chain 条数相同,
chain的初始节点ID -> [(hash, legacyHash)]
private List<StreamEdge> createChain(
Integer startNodeId,
Integer currentNodeId,
Map<Integer, byte[]> hashes,
List<Map<Integer, byte[]>> legacyHashes,
int chainIndex,
Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes) {
if (!builtVertices.contains(startNodeId)) {
// 记录需要用来建立 JobGraph 的边
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
// 遍历当前节点所有的出边
for (StreamEdge outEdge : currentNode.getOutEdges()) {
// 判断两个节点能否chain成为一个新的节点的条件,通过传入两个节点的边,在 isChainable 判断
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
// 如果该边可以 chain,对端节点就可以合并到当前首节点来
// 继续尝试对端节点的下1(N)个节点能否连接到该 chain 上
// 如果否,createChain 返回下条边,记录到 transitiveOutEdges,这些边作为新节点的出边。
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(startNodeId, chainable.getTargetId(), hashes, legacyHashes, chainIndex + 1, chainedOperatorHashes));
}
// 如果该边不可以 chain,当前 chain 到此结束.
// 当前边作为新节点的出边,记录到 transitiveOutEdges
// 同时以当前节点作为首节点,开启一段新的 chain
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(nonChainable.getTargetId(), nonChainable.getTargetId(), hashes, legacyHashes, 0, chainedOperatorHashes);
}
...
// 如果为首节点,创建 JobVertex 顶点,否则只需要创建对应的 StreamConfig 追加到对应的首节点即可
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes)
: new StreamConfig(new Configuration());
// 更新 config,例如真正执行任务的各类 opertor
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs);
if (currentNodeId.equals(startNodeId)) {
// 如果为首节点,初始化 chainStart chainIndex 等标记
config.setChainStart();
config.setChainIndex(0);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
config.setOutEdgesInOrder(transitiveOutEdges);
config.setOutEdges(streamGraph.getStreamNode(currentNodeId).getOutEdges());
// transitiveOutEdges 已经记录了需要的出边,这里建立对应的 JobEdge
for (StreamEdge edge : transitiveOutEdges) {
connect(startNodeId, edge);
}
// 记录该 chain 上其他节点的信息
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
// 如果不是首节点,则将信息记录到 chainedConfigs,在对应的首节点会用到
chainedConfigs.computeIfAbsent(startNodeId, k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}
总结下这个流程:
从输入节点开始,判断边的对端节点能否加入到该 chain,如果可以,则继续从对端节点执行扩展该 chain。否则,当前 chain 结束,以对端节点为初始节点,递归扩展新的chain。
判断两个节点能否chain成为一个新的节点的条件,通过传入两个节点的边,在 isChainable 判断。
如果当前节点为 chain 的首节点,那么就创建一个 JobVertex,否则创建 StreamConfig,记录到 chainedConfigs,由于调用链上后面的节点先创建,因此创建首节点的 JobVertex 时,就可以使用 chainedConfigs 记录的信息了。
如果 chain 到此结束,那么就可以使用该边作为上一个 chain 的出边。
递归结束条件为碰到尾结点。
创建 JobEdge 的过程引入了IntermediateDataSet,JobEdge实际上是消费的该结构。
JobVertex→IntermediateDataSet→JobEdge→JobVertex
// 创建 JobEdge,注意同时给上游节点建立了 IntermediateDataSet,edge消费该 dataset
public JobEdge connectNewDataSetAsInput(
JobVertex input,
DistributionPattern distPattern,
ResultPartitionType partitionType) {
// 输入节点创建 IntermediateDataSet
IntermediateDataSet dataSet = input.createAndAddResultDataSet(partitionType);
// source=dataSet, target=this
JobEdge edge = new JobEdge(dataSet, this, distPattern);
// 当前节点的 inputs 增加 jobEdge 作为输入源
this.inputs.add(edge);
// 输入节点记录 edge 作为消费端
dataSet.addConsumer(edge);
return edge;
}
4. isChainable
通过比较传入 edge 上下游节点的并发度等,用来判断这两个节点能否 chain 成为一个节点。
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
StreamOperatorFactory<?> headOperator = upStreamVertex.getOperatorFactory();
StreamOperatorFactory<?> outOperator = downStreamVertex.getOperatorFactory();
return downStreamVertex.getInEdges().size() == 1
&& outOperator != null
&& headOperator != null
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
&& (headOperator.getChainingStrategy() == ChainingStrategy.HEAD ||
headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS)
&& (edge.getPartitioner() instanceof ForwardPartitioner)
&& edge.getShuffleMode() != ShuffleMode.BATCH
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled();
}
注意 operatorFactory 底层使用的还是 Transformation 里记录的 Operator,各类 Operator 的 chainingStrategy 值不同,例如 StreamSource.chainingStrategy = HEAD、StreamFlatMap.chainingStrategy = ALWAYS、StreamSink.chainingStrategy = ALWAYS,事实上所有的 AbstractStreamOperator 的 chainingStrategy = HEAD,因此 StreamGroupedReduce 也是 HEAD。
ForwardPartitioner 如之前文章介绍,并发度一致时才会设置。
注:upStreamVertex.getParallelism() == downStreamVertex.getParallelism() 这个跟 ForwardPartitioner 是不是重复了?
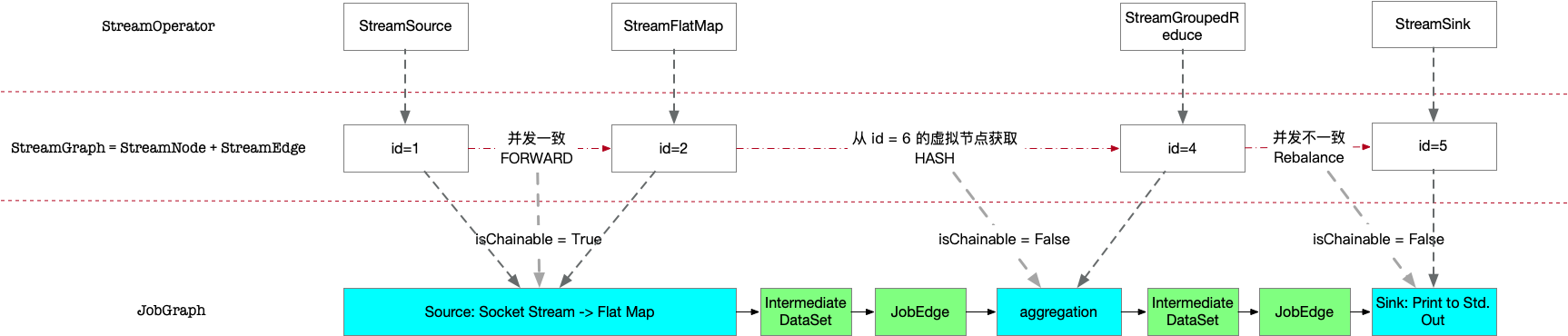
5. 示例
仍然以 WordCount 为例,StreamGraph一共有 3 条边关系:
1→2→4→5
对应的 isChainable 结果为:
- True: 满足条件
- False: StreamGroupedReduce.chainingStrategy = HEAD
- False: 并发度不同(本机 4核,因此对于 id = 5,默认并发为4)
所以经过 Chain 优化后,JobGraph 一共 3 个节点
对应的日志:
2020-05-04 20:15:30,962 DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash 'cbc357ccb763df2852fee8c4fc7d55f2' for node 'Source: Socket Stream-1' {id: 1, parallelism: 1, user function: org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction}
2020-05-04 20:15:30,963 DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash '7df19f87deec5680128845fd9a6ca18d' for node 'Flat Map-2' {id: 2, parallelism: 1, user function: WordCount$$anon$3}
2020-05-04 20:15:30,963 DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash '9dd63673dd41ea021b896d5203f3ba7c' for node 'aggregation-4' {id: 4, parallelism: 1, user function: org.apache.flink.streaming.api.functions.aggregation.SumAggregator}
2020-05-04 20:15:30,964 DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash '1a936cb48657826a536f331e9fb33b5e' for node 'Sink: Print to Std. Out-5' {id: 5, parallelism: 4, user function: org.apache.flink.streaming.api.functions.sink.PrintSinkFunction}
2020-05-04 20:15:30,966 DEBUG org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator - Parallelism set: 4 for 5
2020-05-04 20:15:31,020 DEBUG org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator - Parallelism set: 1 for 4
2020-05-04 20:15:31,056 DEBUG org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator - CONNECTED: RebalancePartitioner - 4 -> 5
2020-05-04 20:15:31,060 DEBUG org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator - Parallelism set: 1 for 1
2020-05-04 20:15:31,102 DEBUG org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator - CONNECTED: KeyGroupStreamPartitioner - 1 -> 4
这个 hash 值,我们在后面也会经常看到。