flink 提供多种消费 Kafka 数据的方式,由于不同层级接口支持的功能范围、粒度不同,同时 flink 版本迭代频繁,接口也在不断发生变化,因此使用起来容易混淆。
当我们定义了一个 Kafka 的 DDL,例如:
CREATE TABLE MyUserTable (
...
) WITH (
'connector.type' = 'kafka',
'connector.version' = '0.11'
...
)
在 DDL 背后都做了什么,使得我们能够通过 SQL 读写这张表?flink 如何组织其代码结构,如何复用 streaming 相关代码的?接口从 API 到 SQL,方式更加简洁的同时,又有哪些功能被忽略掉了?
这些疑问,在刚接触 flink-SQL 时就非常好奇,但是阿里很多文章都是介绍其优点而不提缺点。这篇笔记,记录下代码的结构层次,SQL 与 DataStream API 接口的关系,梳理下上述的疑问。
1. Table API Connectors
flink 的 API 分为多层,越低级能表达的含义越多,越高级使用起来越简洁。

SQL、Table API 都属于高级接口,使用成本很低,在我看来,这是一种偏配置化的接口,通过配置表达其意图。DDL 描述 Source/Sink,DML 描述计算逻辑。离线的计算逻辑可以统一到 SQL,说明 SQL 语法足够强大,因此实时计算选择 SQL 描述也就顺理成章了。当然,也可以使用 YAML 来描述 Source/Sink。
定义一个Table API Kafka Connector,可以使用 DDL、TableAPI、YAML 多种形式
# 1. DDL
CREATE TABLE MyUserTable (
...
) WITH (
'connector.type' = 'kafka',
'connector.version' = '0.11',
...
)
# 2. TableAPI
.connect(
new Kafka()
.version("0.11")
...
)
# 3. YAML
connector:
type: kafka
version: "0.11"
...
都是在表达一层含义,描述的属性,可以分为 3 类:
- connector:即要连接的物理存储本身,可以是文件系统,可以是 Kafka 这类消息队列,也可以是 Redis、ES 等存储,甚至是 Http-API 等,称为 connector.
- format:即数据的结构,可以是 csv、json 等明文,也可以是 Arvo 等序列化格式,称为 format.
- schema:即字段的格式,数据是由各个字段组成的,例如 id、 name、 age 等,称为 schema.
通过明确这 3 个元素,我们就可以将存储里相同格式的多条数据抽象为表,进而使用 SQL、Table API 来读写表。
2. Connectors - Kafka
如果要自定义 Source/Sink 的 Connector,需要继承TableFactory,实现requiredContext supportedProperties方法,指定在 DDL 里支持的参数(optional/required)。然后借助Java’s Service Provider Interfaces (SPI)让 flink 发现该子类。
例如对于 Kafka-0.11,实现Kafka011TableSourceSinkFactory记录到文件/resources/META-INF/services/TableFactory,如果 DDL 参数一致,就会通过该类一步步创建读写 Kafka 的对象。
从 DDL 到底层读写类,通过继承自不同的基类来实现:
- TableFactory: 入口类,声明支持的 DDL 参数
- StreamTableSource:根据表的描述构建出流
- RichParallelSourceFunction/SourceFunction:产出数据,作为流的输入源
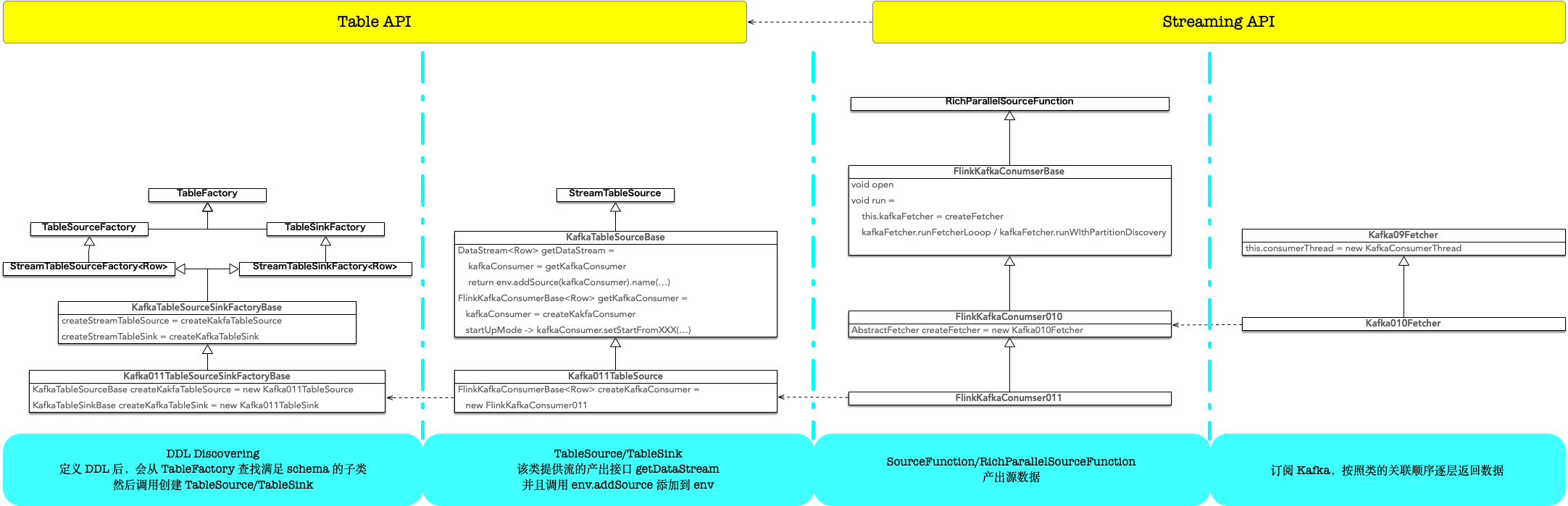
以 1.9 版本代码为例,Kafka 0.11 源表的接口关系如图:
具体的:
Kafka011TableSourceSinkFactoryBase声明支持的参数,例如required: (update-mode -> append), (connector.type -> kafka),optional: (connector.topic -> …),(connector.startup-mode -> …),如果 DDL 一致,则创建对应的StreamTableSourceKafka011TableSource创建 kafka consumer,通过env.addSource添加为SourceTransformation,可以看到这块跟代码部分已经一致了FlinkKafkaConsumer011继承自SourceFunction,在run的实现里委托KafkaXXXFetcher持续读取数据
注:实现上都提取到了基类完成,例如 Kafka011TableSource 里调用 env.addSource 是在 KafkaTableSourceBase,FlinkKafkaConsumer011的部分方法也抽象到了 FlinkKafkaConsumerBase
对应 flink API 的分层,Table API Connectors - Kafka基于DataStream Connectors - Kafka实现,数据的产出,本质上仍然是由SourceFunction.run完成的。
3. FlinkKafkaConsumerBase.run
this.kafkaFetcher = createFetcher(
...
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
kafkaFetcher.runFetchLoop();
} else {
runWithPartitionDiscovery();
}
runFetchLoop启动消费线程,自身则一直循环获取消费到的数据,调用SourceContext.collectWithTimestamp发送数据,因此该线程操作比较简单。
runWithPartitionDiscovery是在runFetchLoop的基础上,启动一个检测线程,轮询上游分区数是否变化。
4. KafkaConsumerThread
消费线程即KafkaConsumerThread:
public class KafkaConsumerThread extends Thread {
...
/** The handover of data and exceptions between the consumer thread and the task thread. */
private final Handover handover;
...
/** Reference to the Kafka consumer, once it is created. */
private volatile KafkaConsumer<byte[], byte[]> consumer;
这里仅列举了最重要的两个成员变量,到了KafkaConsumer就是 Kafka 的原生接口了,负责消费 topic 的数据,线程启动后会创建 consumer
@Override
public void run() {
...
// this is the means to talk to FlinkKafkaConsumer's main thread
final Handover handover = this.handover;
// This method initializes the KafkaConsumer and guarantees it is torn down properly.
// This is important, because the consumer has multi-threading issues,
// including concurrent 'close()' calls.
try {
this.consumer = getConsumer(kafkaProperties);
...
}
@VisibleForTesting
KafkaConsumer<byte[], byte[]> getConsumer(Properties kafkaProperties) {
return new KafkaConsumer<>(kafkaProperties);
}
在FlinkKafkaConsumerBase.run这个消费者线程里,KafkaConsumerThread又起到生产者的作用,Handover handover作为中间队列。
// 从 handover poll 数据
Kafka09Fetcher.runFetchLoop
...
while (running) {
// this blocks until we get the next records
// it automatically re-throws exceptions encountered in the consumer thread
final ConsumerRecords<byte[], byte[]> records = handover.pollNext();
// 向 handover push 数据
KafkaConsumerThread.run
...
try {
handover.produce(records);
records = null;
}
5. 使用
以上即大概流程,按照上面的介绍,说下使用时的几个 TIPS:
5.1. 配置Consumer/Producer
创建 DDL 时,除了第一节里提到的3类属性,我们可能还需要传入 Kafka 的自身属性,例如 Consumer 的 max.partition.fetch.bytes, Producer 的 batch.size linger.ms 等,即对应getConsumer方法的kafkaProperties参数。
该参数的来源在TableFactory:
private Properties getKafkaProperties(DescriptorProperties descriptorProperties) {
final Properties kafkaProperties = new Properties();
final List<Map<String, String>> propsList = descriptorProperties.getFixedIndexedProperties(
CONNECTOR_PROPERTIES,
Arrays.asList(CONNECTOR_PROPERTIES_KEY, CONNECTOR_PROPERTIES_VALUE));
propsList.forEach(kv -> kafkaProperties.put(
descriptorProperties.getString(kv.get(CONNECTOR_PROPERTIES_KEY)),
descriptorProperties.getString(kv.get(CONNECTOR_PROPERTIES_VALUE))
));
return kafkaProperties;
}
因此可以通过connector.properties.i.key connector.properties.i.value的形式传入,例如:
connector.properties.0.key = flink.partition-discovery.interval-millis
connector.properties.0.value = 60000
就可以生效到前面提到的自动发现分区数变化。可以看到这种 key/value 的形式配置还是很繁琐的,社区里有个提议未来会做优化。
5.2. 指定Offsets
DDL 同样可以配置 offsets,例如官网介绍:
'connector.startup-mode' = 'earliest-offset', -- optional: valid modes are "earliest-offset",
-- "latest-offset", "group-offsets",
-- or "specific-offsets"
-- optional: used in case of startup mode with specific offsets
'connector.specific-offsets.0.partition' = '0',
'connector.specific-offsets.0.offset' = '42',
'connector.specific-offsets.1.partition' = '1',
'connector.specific-offsets.1.offset' = '300',
按照上一节的介绍,这类非 properties.xxx 的配置是无法传入到FlinkKafkaConsumerBase的,因此感觉这块的实现有些丑了,主要就是创建FlinkKakfaConsumerBase后,再指定对应的 startup-mode、specific-offsets
protected FlinkKafkaConsumerBase<Row> getKafkaConsumer(
String topic,
Properties properties,
DeserializationSchema<Row> deserializationSchema) {
FlinkKafkaConsumerBase<Row> kafkaConsumer =
createKafkaConsumer(topic, properties, deserializationSchema);
switch (startupMode) {
case EARLIEST:
kafkaConsumer.setStartFromEarliest();
break;
case LATEST:
kafkaConsumer.setStartFromLatest();
break;
case GROUP_OFFSETS:
kafkaConsumer.setStartFromGroupOffsets();
break;
case SPECIFIC_OFFSETS:
kafkaConsumer.setStartFromSpecificOffsets(specificStartupOffsets);
break;
}
return kafkaConsumer;
}
相关的配置都是通过这段代码传入的,1.9版本还不支持 timestamp,最新的版本已经支持了。
kafkaConsumer.open 时,如果 startupMode 为 SPECIFIC_OFFSETS/TIMESTAMP,则直接设置对应的 offsets;否则仅做 Sentinel 标记,在KafkaConsumerThread.reassignPartitions时设置真实值。
因此,关于 offsets 的设置部分,总结下规则就是:
- 优先使用 startup-mode 设置的值,例如 earliest-offset group-offsets specific-offsets 等
- 当指定 specific-offsets 时,读取设置的 offsets;如果未设置,则该 partition 退化为使用 group-offsets
- 当指定 group-offsets 时,则使用该 group 存储的值,如果没有记录,此时’auto.offset.reset’生效
5.3. 读取和写入 Key
无论是对于ConsumerRecord还是ProducerRecord,都可能用到 T key 的成员变量
public final class ConsumerRecord<K, V> {
private final String topic;
private final int partition;
private final long offset;
private final K key;
private final V value;
...
public final class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final K key;
private final V value;
...
通过 SQL ,明显只能显示读写 value,在阿里云的 Blink 上可以在数据结果表 DDL 指定 PRIMARY KEY,开源版本则不支持。
分别说下读写时对应的代码部分:
5.3.1. ConsumerRecord
例如创建FlinkKafkaConsumer011时
public FlinkKafkaConsumer011(List<String> topics, DeserializationSchema<T> deserializer, Properties props) {
this(topics, new KafkaDeserializationSchemaWrapper<>(deserializer), props);
}
传入的反序列化跟 DDL 指定的format.type有关,KafkaDeserializationSchemaWrapper在其上面包装了一层,当Kafka09Fetcher.runFetchLoop获取到数据后,用来反序列化数据:
while (running) {
// this blocks until we get the next records
// it automatically re-throws exceptions encountered in the consumer thread
final ConsumerRecords<byte[], byte[]> records = handover.pollNext();
// get the records for each topic partition
for (KafkaTopicPartitionState<TopicPartition> partition : subscribedPartitionStates()) {
List<ConsumerRecord<byte[], byte[]>> partitionRecords =
records.records(partition.getKafkaPartitionHandle());
for (ConsumerRecord<byte[], byte[]> record : partitionRecords) {
final T value = deserializer.deserialize(record);
而deserialize的接口设计和实现里,都可以看到在这个过程中 key 已经被丢掉了
public class KafkaDeserializationSchemaWrapper<T> implements KafkaDeserializationSchema<T> {
...
@Override
public T deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
return deserializationSchema.deserialize(record.value());
}
5.3.2. ProducerRecord
例如创建FlinkKafkaConsumer011时
protected SinkFunction<Row> createKafkaProducer(
String topic,
Properties properties,
SerializationSchema<Row> serializationSchema,
Optional<FlinkKafkaPartitioner<Row>> partitioner) {
return new FlinkKafkaProducer011<>(
topic,
new KeyedSerializationSchemaWrapper<>(serializationSchema),
properties,
partitioner);
}
同样的,KeyedSerializationSchemaWrapper在对 value 的序列化上包装了一层,负责对 key/value 序列化,可以看到默认的实现里 key 是 null,不过这块的好处是至少我们可以实现新的子类,写入序列化后的 key 值,类似阿里云上 Blink.
public class KeyedSerializationSchemaWrapper<T> implements KeyedSerializationSchema<T> {
...
@Override
public byte[] serializeKey(T element) {
return null;
}
@Override
public byte[] serializeValue(T element) {
return serializationSchema.serialize(element);
}
}
5.4. 异常数据
上面提到 value 的反序列化,例如 json 对应的反序列化类JsonRowDeserializationSchema,同样是通过 TableFactory 的机制查找的,这块后面有时间会单独写篇笔记记录下。
不过有反序列化,就会有反序列化失败的异常处理,例如如果缺失某个字段,可以使用'format.fail-on-missing-field'='true'来决定是否结束程序,默认为 false.
如果数据不是 json 格式,则会直接异常退出:
public Row deserialize(byte[] message) throws IOException {
try {
final JsonNode root = objectMapper.readTree(message);
return (Row) runtimeConverter.convert(objectMapper, root);
} catch (Throwable t) {
throw new IOException("Failed to deserialize JSON object.", t);
}
}
感觉这个功能在生产环境是比较实用的,也有人提了 issue:
- Support to ignore parse errors for JSON format
- add failOnCastException Configuration to Json FormatDescriptor
不过尚未有计划支持。
5.5. 分区
5.5.1. 读取
前面提到了runWithPartitionDiscovery用于检测读取 topic 的分区是否有变化,通过flink.partition-discovery.interval-millis生效,当然也可以自动发现 topic 。
注意当读取分区数 < 并发数时,有些 tm 由于不会收到数据处于空跑的状态。
5.5.2. 写入
写入 topic 时默认的分区策略是FlinkFixedPartitioner,其分区计算公式为:
@Override
public int partition(T record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
Preconditions.checkArgument(
partitions != null && partitions.length > 0,
"Partitions of the target topic is empty.");
return partitions[parallelInstanceId % partitions.length];
}
parallelInstanceId其实就是 IndexOfThisSubtask.
因此如果并发数低于下游分区数时,部分分区不会写入数据,当然我们也可以实现自己的FlinkKafkaPartitioner来满足自定义的特殊场景。
如果 partition == null,而我们按照前面的方式指定了ProducerRecord.key,此时会基于 key 来选择分区,也就是 Kafka 里DefaultPartitioner的行为:
/**
* The default partitioning strategy:
* <ul>
* <li>If a partition is specified in the record, use it
* <li>If no partition is specified but a key is present choose a partition based on a hash of the key
* <li>If no partition or key is present choose a partition in a round-robin fashion
*/
public class DefaultPartitioner implements Partitioner
...