上篇学习笔记通过 Kafka Offsets 以及用户 Count 函数分别介绍了 OperatorState 以及 KeyedState,但当我们使用 flink-SQL 时无法Assigning Operator IDs ,而实际场景中总免不了要查看 state 的需求。
这篇笔记从这个实际需求出发,实现一个 demo 的解决方案,进而相比文档更深入的了解下 flink state 的设计。
1. Mock FlinkKafkaConsumerBase
在不想深入了解 flink state 实现细节的情况下,一个比较自然的想法是:既然Flinkkafkaconsumerbase可以从 state 恢复 offsets,那么我们不妨直接利用该类或者Mock该类去尝试读取 states.
class MockKafkaSource extends RichParallelSourceFunction[String] with CheckpointedFunction {
var unionOffsetStates: ListState[Tuple2[KafkaTopicPartition, java.lang.Long]] = _
override def run(sourceContext: SourceFunction.SourceContext[String]): Unit = {
Thread.sleep(300 * 1000)
}
override def cancel(): Unit = {}
override def initializeState(functionInitializationContext: FunctionInitializationContext): Unit = {
val stateStore = functionInitializationContext.getOperatorStateStore
unionOffsetStates = stateStore.getUnionListState(new ListStateDescriptor(
"topic-partition-offset-states",
createTypeInformation[Tuple2[KafkaTopicPartition, java.lang.Long]]
))
for (unionOffsetState <- unionOffsetStates.get()) {
println(s"f0:${unionOffsetState.f0} f1:${unionOffsetState.f1}")
println(s"stackTrace:\n${Thread.currentThread.getStackTrace.mkString("\n")}")
}
}
override def snapshotState(functionSnapshotContext: FunctionSnapshotContext): Unit = {
}
}
使用该输入源替代FlinkKafkaConsumer011,启动时-s指定从哪个 state 地址恢复。
遇到的第一个可能的报错:
Caused by: java.lang.IllegalStateException: Failed to rollback to checkpoint/savepoint hdfs://.../f00655787414517dbb3346fa5240009c/chk-191. Cannot map checkpoint/savepoint state for operator 77fec41789154996bfa76055dea29472 to the new program, because the operator is not available in the new program. If you want to allow to skip this, you can set the --allowNonRestoredState option on the CLI.
即77fec41789154996bfa76055dea29472这个 operator 对应的 state 无法映射到新的程序,增加--allowNonRestoredState后也可能无法映射到 Source Operator.因此不如直接修改源程序,在不影响原任务 offsets 的情况下通过直接启动任务查看 TM 日志来确认 state.
2. FsStateBackend
上篇笔记里我们使用了 FsStateBackend 作为 state 的后端存储,看下这个类的实现
public class FsStateBackend extends AbstractFileStateBackend implements ConfigurableStateBackend {
public <K> AbstractKeyedStateBackend<K> createKeyedStateBackend(...) {
...
return new HeapKeyedStateBackendBuilder<>(...).build();
}
public OperatorStateBackend createOperatorStateBackend(...) {
...
return new DefaultOperatorStateBackendBuilder(...).build();
}
我们先只关注 OperatorState,因此看下DefaultOperatorStateBackendBuilder.build:
public class DefaultOperatorStateBackendBuilder ... {
public DefaultOperatorStateBackend build() throws BackendBuildingException {
...
OperatorStateRestoreOperation restoreOperation = new OperatorStateRestoreOperation(
cancelStreamRegistry,
userClassloader,
registeredOperatorStates,
registeredBroadcastStates,
restoreStateHandles
);
try {
restoreOperation.restore();
} catch (Exception e) {
IOUtils.closeQuietly(cancelStreamRegistryForBackend);
throw new BackendBuildingException("Failed when trying to restore operator state backend", e);
}
return new DefaultOperatorStateBackend(...);
因此registeredOperatorStates是在restoreOperation.restore()初始化的:
public class OperatorStateRestoreOperation implements RestoreOperation<Void> {
public Void restore() throws Exception {
...
for (OperatorStateHandle stateHandle : stateHandles) {
...
FSDataInputStream in = stateHandle.openInputStream();
closeStreamOnCancelRegistry.registerCloseable(in);
ClassLoader restoreClassLoader = Thread.currentThread().getContextClassLoader();
try {
Thread.currentThread().setContextClassLoader(userClassloader);
OperatorBackendSerializationProxy backendSerializationProxy =
new OperatorBackendSerializationProxy(userClassloader);
backendSerializationProxy.read(new DataInputViewStreamWrapper(in));
List<StateMetaInfoSnapshot> restoredOperatorMetaInfoSnapshots =
backendSerializationProxy.getOperatorStateMetaInfoSnapshots();
// Recreate all PartitionableListStates from the meta info
for (StateMetaInfoSnapshot restoredSnapshot : restoredOperatorMetaInfoSnapshots) {
final RegisteredOperatorStateBackendMetaInfo<?> restoredMetaInfo =
new RegisteredOperatorStateBackendMetaInfo<>(restoredSnapshot);
...
PartitionableListState<?> listState = registeredOperatorStates.get(restoredSnapshot.getName());
if (null == listState) {
listState = new PartitionableListState<>(restoredMetaInfo);
registeredOperatorStates.put(listState.getStateMetaInfo().getName(), listState);
...
// Restore all the states
for (Map.Entry<String, OperatorStateHandle.StateMetaInfo> nameToOffsets :
stateHandle.getStateNameToPartitionOffsets().entrySet()) {
final String stateName = nameToOffsets.getKey();
PartitionableListState<?> listStateForName = registeredOperatorStates.get(stateName);
if (listStateForName == null) {
...
} else {
deserializeOperatorStateValues(listStateForName, in, nameToOffsets.getValue());
}
}
...
private <S> void deserializeOperatorStateValues(
PartitionableListState<S> stateListForName,
FSDataInputStream in,
OperatorStateHandle.StateMetaInfo metaInfo) throws IOException {
if (null != metaInfo) {
long[] offsets = metaInfo.getOffsets();
if (null != offsets) {
DataInputView div = new DataInputViewStreamWrapper(in);
TypeSerializer<S> serializer = stateListForName.getStateMetaInfo().getPartitionStateSerializer();
for (long offset : offsets) {
in.seek(offset);
stateListForName.add(serializer.deserialize(div));
}
}
}
}
从上面这段代码我们可以猜测 flink 读取 state 时代码封装的层次:
- 所有的 Operator States 分为多个
OperatorStateHandle来描述 - 通过
OperatorStateHandle获取后端的字节流 - 流的解析(or 序列化)由
OperatorBackendSerializationProxy完成,通过该类我们得到List<StateMetaInfoSnapshot>的结构,进一步填充到registeredOperatorStates,类型为Map<String, PartitionableListState<?>>,这里记录了 state 的 name,serializer 等信息 - 通过
stateHandle.getStateNameToPartitionOffsets获取 stateName 对应的 offsets - seek 到 offsets,使用 serializer 解析存储的 value
这个封装还是有点绕的,我们先不纠结这里实现的是否优雅,对于读取 state 的话,接下里就是解决stateHandles如何初始化的问题。
3. Savepoint
interface Savepoint里封装了该 savepoint 下所有 state,通过SavepointLoader.loadSavepoint接口初始化
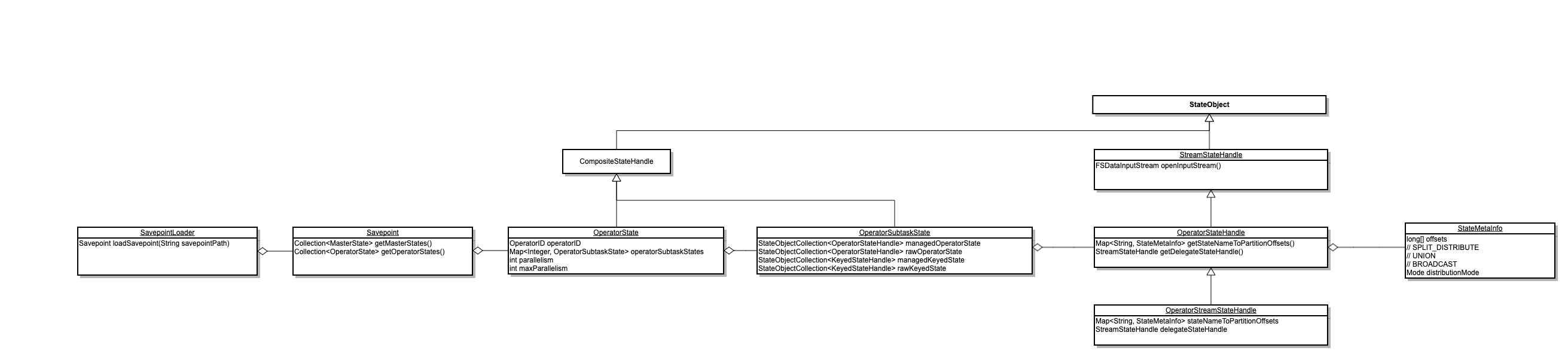
通过这个图我们可以看到比较清晰的结构:
- 一个 Savepoint 由各个 OperatorState 组成(~注意这里的 Operator 是 JobVertex~)
- 每个 OperatorState 由各个 subtask 的 OperatorSubtaskState 组成,同时包括该 Operator 的 OperatorID, 并发度等等
- 每个 OperatorSubtaskState 包含了文档里常说的(managed, raw) * (keyed, operator)
managedOperatorState、rawOperatorState暴露出来的就是上节的OperatorStateHanlde,通过 handle 可以进一步解析存储的 state.
到这里,我们就可以将这两节的内容连贯起来了。
4. StateViewer 扫描 managedOperatorState
根据前面两节的分析,实现了一个简单的 Operator 查看类
object StateViewer extends App {
val params = ParameterTool.fromArgs(args)
val env = ExecutionEnvironment.getExecutionEnvironment
val state = SavepointLoader.loadSavepoint(params.get("ckdir"))
println(s"version:${state.getVersion} checkpointId:${state.getCheckpointId}")
state.getOperatorStates.asScala.foreach{operatorState =>
println(s"\toperatorState:${operatorState}")
operatorState.getSubtaskStates.asScala.foreach{ case(subTaskIndex, subTaskState) =>
println(s"\t\tsubTaskIndex:${subTaskIndex}")
parseManagedOpState(subTaskState.getManagedOperatorState)
parseManagedKeyedState(subTaskState.getManagedKeyedState)
}
}
// unimplemented
def parseManagedKeyedState(managedKeyedState: StateObjectCollection[KeyedStateHandle]) = {
managedKeyedState.asScala.foreach{keyedStateHandle =>
val keyGroupsStateHandle = keyedStateHandle.asInstanceOf[KeyGroupsStateHandle]
val in = keyGroupsStateHandle.openInputStream()
val inView = new DataInputViewStreamWrapper(in)
val serializationProxy = new KeyedBackendSerializationProxy[Any](Thread.currentThread().getContextClassLoader)
// val serializationProxy = new KeyedBackendSerializationProxy[_](Thread.currentThread().getContextClassLoader)
serializationProxy.read(inView)
serializationProxy.getStateMetaInfoSnapshots
}
}
// copy from OperatorStateRestoreOperation.restore
def parseManagedOpState(managedOperatorState: StateObjectCollection[OperatorStateHandle]) = {
managedOperatorState.asScala.foreach{operatorStateHandle =>
val serializationProxy = new OperatorBackendSerializationProxy(Thread.currentThread().getContextClassLoader)
serializationProxy.read(
new DataInputViewStreamWrapper(operatorStateHandle.openInputStream())
)
val nameToSerializer = serializationProxy.getOperatorStateMetaInfoSnapshots().asScala.map{stateMetaInfoSnapshot =>
println(s"\t\t\t\tname:${stateMetaInfoSnapshot.getName} type:${stateMetaInfoSnapshot.getBackendStateType}")
// val restoredMetaInfo = new RegisteredOperatorStateBackendMetaInfo[_](stateMetaInfoSnapshot)
val restoredMetaInfo = new RegisteredOperatorStateBackendMetaInfo[Any](stateMetaInfoSnapshot)
restoredMetaInfo.getName -> restoredMetaInfo.getPartitionStateSerializer
}.toMap
val in = operatorStateHandle.openInputStream()
operatorStateHandle.getStateNameToPartitionOffsets.asScala.foreach{case (name, metaInfo) =>
val inView = new DataInputViewStreamWrapper(in)
val serializer = nameToSerializer.get(name).get
val offsets = metaInfo.getOffsets
println(s"\t\t\t\tname:${name} serializer:${serializer} offsets:${offsets.mkString("[", ",", "]")}")
offsets.foreach{offset =>
in.seek(offset)
println(s"\t\t\t\t\toffset:${offset} value:${serializer.deserialize(inView)}")
}
}
}
}
}
解析--ckdir传入的 state 地址,遍历所有的 OperatorState 下的 managedOperatorState,通过第二节的方法解析出存储的 offsets 值,可以看到解析出的还是一个KafkaTopicPartition结构:
version:2 checkpointId:191
operatorState:OperatorState(operatorID: d216482dd1005af6d275607ff9eabe2c, parallelism: 2, maxParallelism: 128, sub task states: 2, total size (bytes): 0)
subTaskIndex:0
subTaskIndex:1
operatorState:OperatorState(operatorID: 77fec41789154996bfa76055dea29472, parallelism: 2, maxParallelism: 128, sub task states: 2, total size (bytes): 2114)
subTaskIndex:0
subTaskIndex:1
operatorState:OperatorState(operatorID: f0bb9ed0d20321fef7413e1942e21550, parallelism: 2, maxParallelism: 128, sub task states: 2, total size (bytes): 0)
subTaskIndex:0
subTaskIndex:1
operatorState:OperatorState(operatorID: 64248066b88fd35e9203cd469ffb4a53, parallelism: 2, maxParallelism: 128, sub task states: 2, total size (bytes): 2470)
subTaskIndex:0
name:_default_ type:OPERATOR
name:topic-partition-offset-states type:OPERATOR
name:_default_ serializer:org.apache.flink.runtime.state.JavaSerializer@7e3060d8 offsets:[]
name:topic-partition-offset-states serializer:org.apache.flink.api.java.typeutils.runtime.TupleSerializer@3bf01a19 offsets:[1209]
offset:1209 value:(KafkaTopicPartition{topic='TestTopic', partition=1},17)
subTaskIndex:1
name:_default_ type:OPERATOR
name:topic-partition-offset-states type:OPERATOR
name:_default_ serializer:org.apache.flink.runtime.state.JavaSerializer@7e3060d8 offsets:[]
name:topic-partition-offset-states serializer:org.apache.flink.api.java.typeutils.runtime.TupleSerializer@3bf01a19 offsets:[1209]
offset:1209 value:(KafkaTopicPartition{topic='TestTopic', partition=0},18)
这里也可以看到第一节里报错的operatorID:77fec41789154996bfa76055dea29472,我们可以猜测这是countState的后端存储,大小为 2114,因为测试程序没有实现该类所以报了匹配失败的错误,即使添加了--allowNonRestoredState,也需要保证 source 的 operatorID 为 64248066b88fd35e9203cd469ffb4a53 才能匹配成功。而在该数据流的启动日志里
... DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash 'd216482dd1005af6d275607ff9eabe2c' for node 'Map-2' {id: 2, parallelism: 1, user function: org.apache.flink.streaming.api.scala.DataStream$$anon$4}
... DEBUG org.apache.flink.streaming.api.graph.StreamGraphHasherV2 - Generated hash 'f0bb9ed0d20321fef7413e1942e21550' for node 'Sink: Print to Std. Out-5' {id: 5, parallelism: 1, user function: org.apache.flink.streaming.api.functions.sink.PrintSinkFunction}
因此下一篇笔记,我们接着谈谈 Flink - JobGraph 再看看 flink 认为哪些元素会影响到生成这些唯一 ID。