如果要设计一套 Master-Worker 架构的任务调度系统,Master 的复杂度无疑更高一些。因为 Master 相当于系统的“大脑”,从宏观上管理着任务调度的准确性和稳定性。其中核心又在于需要准确的管理工作流的状态以及调度下一步的行为。
在了解 DolphinScheduler 的实现之前,我们不妨先思考几个任务调度的问题:
- 分布式的常见问题,例如如何避免同一个任务被不同 Master 实例分别启动?或者都没有启动任务?
- 工作流实例是由多个任务实例的 DAG 组成,先启动哪个?什么时候启动下一个?
- 任务应该发送到哪个 Worker 执行?发送 Worker 超时或者失败怎么处理,重试还是发送到其他 Worker?
- Worker 需要分组么?有什么好处?
- 任务之间是否有优先级?在哪里可以区分优先级?
当我们深入思考进去,类似的问题就会变得越来越多,比如任务的扩展性、Failover、数据库的优化、系统的可观察性等等。
然而千里之行始于足下,要讲清楚上述问题。我们不妨从最普遍、最正常的场景入手,即DolphinScheduler-3:工作流的生命周期的任务状态的第一步:
工作流是如何初始化和运行的?
总览
对于一个任务调度系统,任务的启动无外乎以下两个入口:
- 系统调度:例如用户配置的Crontab、上游依赖任务的触发、任务的容错
- 手动运行:例如任务测试、补数、重跑失败任务
启动后,Master 的执行过程可以简单分为三个阶段:
- 生成工作流实例
- 构造DAG,生成任务实例
- 分发任务实例
整体的代码流程如图:
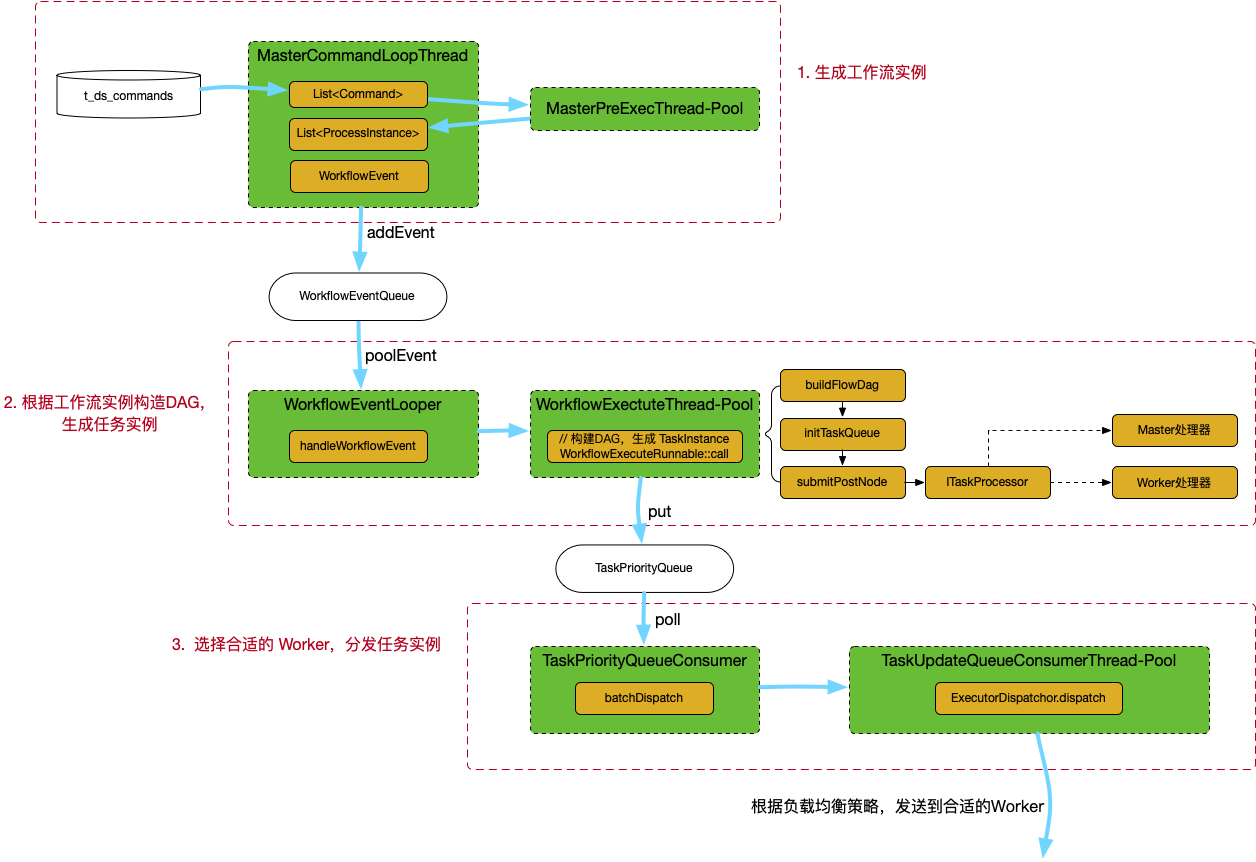
1. 生成工作流实例
这个过程是读取 t_ds_command 表,处理后写入 t_ds_process_instance 表,主要两方参与:
MasterSchedulerBootStrap: 轮询从 t_ds_command 表选出由且仅由该 master 实例处理的行,存储到List<Command>masterPrepareExecService: 线程池,将List<Command>转化为List<ProcessInstance>
注意:
- 是否 overload 在这一步判断,当前主要是基于 load average 和 mem。实际上 load average 不能直接对标 cpu idle:扯扯 cpu idle 与 load average
- Master 通过 ZK 判断当前实例的索引下标,只选取 t_ds_command 表主键取模后跟实例下标一致的行,避免重复调度
- 为了提高性能,在 Command -> ProcessInstance 时使用了线程池issue
ProcessInstance生成后,会封装到WorkflowExecuteRunnable,这个类的功能非常庞大,同时封装了后续的构造DAG、任务提交等一系列功能。
WorkflowExecuteRunnable对象会存储到ProcessInstanceExecCacheManager,该类内部维护一个ProcessInstance.id为 key 的 hash 结构,支持全局查找。id 也会被添加到WorkflowEventQueue这个队列,以触发下一步的计算。
2. 构造DAG,生成任务实例
workflowExecuteRunnable::call提交到WorkflowExecuteThreadPool这个线程池去执行,真正开始一个工作流。生成DAG、构造TaskInstance对象,都是在这个方法里实现的。运行在WorkflowExecuteThreadPool线程池,线程前缀名为”WorkflowExecuteThread-“.
DAG 的概念很常见,例如 Flink 里的 JobGraph。虽然跟 Dolphin 里的 DAG 在需求和实现上都相差巨大,但是两者都有一个共同点,就是要构建具体运行的算子实例及其关系。
Process 定义了算子及其依赖关系,而算子的真正执行是在 Task,例如 Shell、SQL、MapReduce、Flink 等任务类型。因此这一步主要是: 读取这个 ProcessInstance 下的所有 Task 实现,确定本次都需要启动哪些 Task,其先后顺序是什么。
DAG<String, TaskNode, TaskNodeRelation> dag对象存储了生成后的 DAG,包含需要运行的 Task 节点,以及节点之间的依赖关系。
然后提交任务到优先级队列中:
- 首先提交的是 DAG 的开始节点,例如没有前置依赖的节点、直接运行的节点等。前置节点运行结束后,再执行后续节点,函数命名
submitPostNode。后续的任务也会由该方法执行,具体可以查看Dolphin状态。 - 待提交的任务先添加到
readyToSubmitTaskQueue队列,然后遍历该队列,判断是否满足提交条件。如果满足,则调用submitTaskExec方法。 - 根据任务实例的不同类型,构造对应的
ITaskProcessor实例,例如CommonTaskProcessorDependentTaskProcessor等。实际处理的任务类型对应CommonTaskProcessor,逻辑任务对应DependentTaskProcessor。前者会将任务添加到TaskPriorityQueue<TaskPriority> taskUpdateQueue优先级队列继续分发,后者则在 master 模块完成计算。
3. 分发任务实例
该类是一个单线程,也是标准的 Producer-Consumer 模型。
对于CommonTaskProcessor类型,从优先级队列选取出任务实例后。多线程发送到配置的 Worker 节点。节点的选择、负载均衡都是在这一步完成的。
当 Worker 节点正常接收并且开始处理任务后,会发送消息通知对应的 Master 节点。工作流实例也就正式启动了。