1. 为什么要有任务依赖?
大数据的离线场景中,任务每次执行更新一个新的 Hive 分区,分区基本都是时间相关的,比如天、小时分区。
写入 ODS 表新分区的任务执行完成后,接着执行写入 DWD 表新分区的任务,因此任务之间是有严格的依赖关系的。因为 ODS 是 DWD 的输入,如果任务启动时间过早,DWD 任务就会读不到或者读到一个空分区导致任务失败/数据错误。
所以任务依赖是任务调度系统中非常重要的一环。
扩展任务类型,诸如 ShellTask、FlinkTask、SQLTask 等好比是兵器,多多益善,但是可以按需添加,积少成多。任务依赖、调度及时性则是基本功,一旦依赖计算不准确、调度不及时,就等于自废武功了。
2. 触发/轮询/Crontab
我们是否可以只基于任务事件触发构建调度系统呢?对应到系统实现上,上游任务成功发送消息,接收到消息后启动下游任务。这样既节省了轮询,又提高了时效性。
但实际上大部分调度系统里,任务都是通过 crontab 的时间属性触发的1 2.
我觉得主要原因有三个:
- 最上游的任务,是没有前置节点的,因此必须定时启动。
- 不同调度周期的任务依赖,例如周级任务依赖天级任务,需要 crontab 指定依赖周几的天级任务。
- 触发式增加了系统的复杂度,同时降低了易用性。比如 crontab 定时生成日志,离线开发人员容易理解,看日志方便。触发式一直不打印日志,可能是依赖未就绪,也可能是系统出问题了。
实际上,任务真正执行的时间是由 crontab 和上游依赖就绪共同决定的。crontab 是任务的初始时间,任务依赖是 DAG 的一部分。
基于此,任务依赖这个功能,看上去适合用触发消息实现,但是实际上轮询检查才是最合理的。
3. DS里的任务依赖
跟 ShellTask、FlinkTask 一样,DolphinScheduler 里的任务依赖是任务类型的一种。
实现上采用了轮询机制:
Master 模块每隔一段时间检查依赖的任务状态。
除了任务依赖外,Master 模块还实现了其他条件分支任务类型,例如 Condition、Switch 等,类似 if switch.
注:我觉得统一放到 Worker 更加合适,避免任务执行过多导致 Master 调度线程饱和。
比如任务 A 依赖了两个任务:shell_node、shell_task,可能两者全部成功才能执行 A ,也可能两者一个成功就可以执行 A 。因此依赖任务之间支持且、或的关系。
在 Dolphin 里可以这么配置: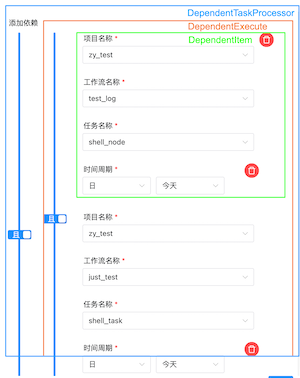
从图里还可以看到 Dolphin 支持了二级关系。
对应上述图里的标注,主要实现类有三个:
- 最外层的实现类是
DependentTaskProcessor,封装了任务依赖全部功能,类层次上等同于CommonTaskProcessor - 依赖的最小单元是
DependentItem,记录了依赖的项目、工作流、任务、依赖时间周期等 - 中间类是
DependentExecute,包含了多个DependentItem及其且或关系,计算任务实例获取对应状态都在这里实现
具体的:
// 任务依赖的最小单元
public class DependentItem {
private long projectCode;
private long definitionCode;
private long depTaskCode;
private String cycle;
private String dateValue;
private DependResult dependResult;
private TaskExecutionStatus status;
//唯一key
public String getKey() {...}
}
注意 DependentItem 的唯一 key = 工作流定义code + 任务定义code + 依赖周期 + 依赖时间范围,例如:
- 8934085496000-8934075119168-hour-last24Hours
- 9011030814144-0-day-last1Days
- 10845068737216-10845062002624-hour-last3Hours
多个DependentItem及其关系组合成了DependentExecute
public class DependentExecute {
/**
* depend item list
*/
private List<DependentItem> dependItemList;
/**
* dependent relation: AND OR
*/
private DependentRelation relation;
private Map<String, DependResult> dependResultMap = new HashMap<>();
多个DependentExecute进一步组合成了DependentTaskProcessor,也就是 Dependent 任务的实现类。
public class DependentTaskProcessor extends BaseTaskProcessor {
DependentParameters dependentParameters;
// 统一管理多个组合依赖:包含多个 DependentExecute,其关系存储在 dependentParameters.getRelation()
List<DependentExecute> dependentTaskList;
Date dependentDate;
private Map<String, DependResult> dependResultMap = new HashMap<>();
实现思路上,就是获取基础的DependentItem状态,然后根据且或关系计算整个 DependentTask 的结果。
同时应当尽可能在本地缓存任务查询结果,避免重复远程请求,造成服务端、DB的压力。
4. DependentTaskProcessor 的实现
对比来看,CommonTaskProcessor和 DependentTaskProcessor 的 submitTask 方法基本一致。区别在于前者逻辑实现在dispatchTask,后者在runTask。
因此我们主要看下runTask的实现:
4.1. runTask
public boolean runTask() {
if (!allDependentItemFinished) {
allDependentItemFinished = allDependentTaskFinish();
}
if (allDependentItemFinished) {
getTaskDependResult();
endTask();
}
return true;
}
分成了两步:
- 检查所有依赖任务的状态是否为已完成
- 如果已完成,根据任务状态计算 DependentTask 的结果
接下来分别看看这两步的实现。
4.2. allDependentTaskFinish
private boolean allDependentTaskFinish() {
boolean finish = true;
// 遍历所有的一级依赖 DependentExecute
for (DependentExecute dependentExecute : dependentTaskList) {
// 首先获取 dependentExecute 对象缓存的执行结果
for (Map.Entry<String, DependResult> entry : dependentExecute.getDependResultMap().entrySet()) {
// 缓存到自身的 dependResultMap
if (!dependResultMap.containsKey(entry.getKey())) {
dependResultMap.put(entry.getKey(), entry.getValue());
// save depend result to log
logger.info("dependent item complete, dependentKey: {}, result: {}, dependentDate: {}",
entry.getKey(), entry.getValue(), dependentDate);
}
}
// 其次判断 dependExecute 是否已结束, finish 方法会调用 DependentExecute.getModelDependResult()
if (!dependentExecute.finish(dependentDate)) {
finish = false;
}
}
return finish;
}
4.3. getTaskDependResult
private DependResult getTaskDependResult() {
List<DependResult> dependResultList = new ArrayList<>();
// 遍历所有的一级依赖 DependentExecute
for (DependentExecute dependentExecute : dependentTaskList) {
// 直接调用 DependentExecute.getModelDependResult() 方法
DependResult dependResult = dependentExecute.getModelDependResult(dependentDate);
dependResultList.add(dependResult);
}
// 所有依赖的检查结果 + 依赖关系 => 计算最终结果
result = DependentUtils.getDependResultForRelation(this.dependentParameters.getRelation(), dependResultList);
logger.info("Dependent task completed, dependent result: {}", result);
return result;
}
4.4. DependentExecute.getModelDependResult
该方法是实现获取任务状态的核心:
getModelDependResult(Date currentTime)
// 遍历所有依赖项
for dependentItem : dependItemList
dependResult = getDependResultForItem(dependentItem, currentTime)
// 更新到本地缓存
dependResultMap.put(dependentItem.getKey(), dependResult)
// 记录所有依赖的检查结果
dependResultList.add(dependResult)
// 所有依赖的检查结果 + 依赖关系 => 计算最终结果
DependentUtils.getDependResultForRelation(this.relation, dependResultList)
getDependResultForItem(...)
如果 dependResultMap 包含结果,直接返回,否则返回 getDependentResultForItem 的执行结果
// 根据当前时间 + 配置的 CycleTime,返回一个对应的时间区间列表,返回对应的任务结果
getDependentResultForItem(DependentItem dependentItem, Date currentTime)
List<DateInterval> dateIntervals = DependentUtils.getDateIntervalList(currentTime, dependentItem.getDateValue())
// 查询该依赖在 dataIntervals 所有区间上的运行实例结果
// 1. 如果某一个查询不到,则返回 WAITING
// 2. 如果某一个非 SUCCESS,则返回对应值
return calculateResultForTasks(dependentItem, dateIntervals)
calculateResultForTasks(dependentItem, dataIntervals)
for dataInterval : dataIntervals
// 调用 processService 获取该时间区间内的 last one process (所以如果前面执行成功,最后一次失败,视为失败?)
processInstance = findLastProcessInterval(...)
如果 processInstance 为 null,返回 WAITING
否则记录 process/task 的状态,如果 !SUCCESS,跳出循环后返回该状态
每一个DataInterval对应一个工作流/任务实例的运行结果,因此dateInvervals的计算非常重要。
假如 currentTime = 11:30,不同的 CycleTime 返回的区间不同:
- Last3Hours => [ [08:00, 08:59], [09:00, 09:59], [10:00, 10:59] ]
- Last24Hours => [ [01:00, 01:59], [02:00, 02:59], …, [23:00, 23:59], [00:00, 00:59] ],前面的时间区间都是前一天的
- Last1Days => [ [00:00, 23:59]],也就是前一天的时间区间
这部分的实际效果可以执行getDateIntervalList的单测观察,以确保符合预期。
注意计算时没有用到cycle而是只使用了dateValue,因此 cycle 只是方便前端选择不同的 dateValue,调度时不起作用。
5. 总结
代码上看,任务依赖支持了两级的结果关系计算,因此DependentTaskProcessor、DependentExecute都调用了DependentUtils.getDependResultForRelation方法。不过我个人觉得从实际使用上,不太会用到这么复杂的逻辑关系,甚至只支持任务一级依赖全部成功这一种场景就足够了。
同时,为了降低外部访问,都需要缓存任务查询结果,因此两个类都定义了同名的成员变量:
private Map<String, DependResult> dependResultMap = new HashMap<>();
但是DependentTaskProcessor.dependResultMap又没有实际用途。
DependentTask有点类似于编程语言里的if,但是DolphinScheduler 的实现里没有考虑 Short-circuit evaluation3,比如依赖了上游任务 A OR B,那即使 A 成功了,也需要能够查询到 B 的工作流实例。
这块的代码虽然不多,但是由于很难理解作者的思路,感觉代码可读性一般。
但是需要强调的是,理解任务依赖的配置对调度准确性是及其重要的,从阿里云的文档4复杂度也可以窥见一斑。