1. 任务状态
任务调度系统里,任务状态管理对准确性和可靠性至关重要。
- 准确性无需多言,例如工作流实例应该在何时初始化、DAG的算子应当是 WAIT(上游算子尚未完成) 还是 RUNNING(上游全部算子完成) 状态、工作流实例是否可以更新为 SUCCESS 状态。
- 可靠性主要是针对各种异常状态的管理:例如任务的容错、任务的重试。
在 Apache DolphinScheduler 的具体实现里,对于任务状态有明确的枚举值,状态之间的转换遵循固定规则。代码里也有类似 Trigger/Event/Action 等的概念,因此按照状态机的模型去阅读事半功倍。
2. DolphinScheduler里的任务状态
理论上,任务的状态有提交、运行、成功、失败等。
实际状态会复杂很多,比如:
- 系统外部角度看,「失败」往往指的是运行失败,系统内部则包含了提交失败、分发失败、结果回调失败等,稳定性的角度还需要考虑任务的容错状态。
- 在 DolphinScheduler 这类工作流调度系统中包含了 DAG,工作流实例的状态是由多个任务实例状态决定的,任务实例之间还有依赖关系,所以会更复杂。
我理解的比较重要的状态及转换如图所示:
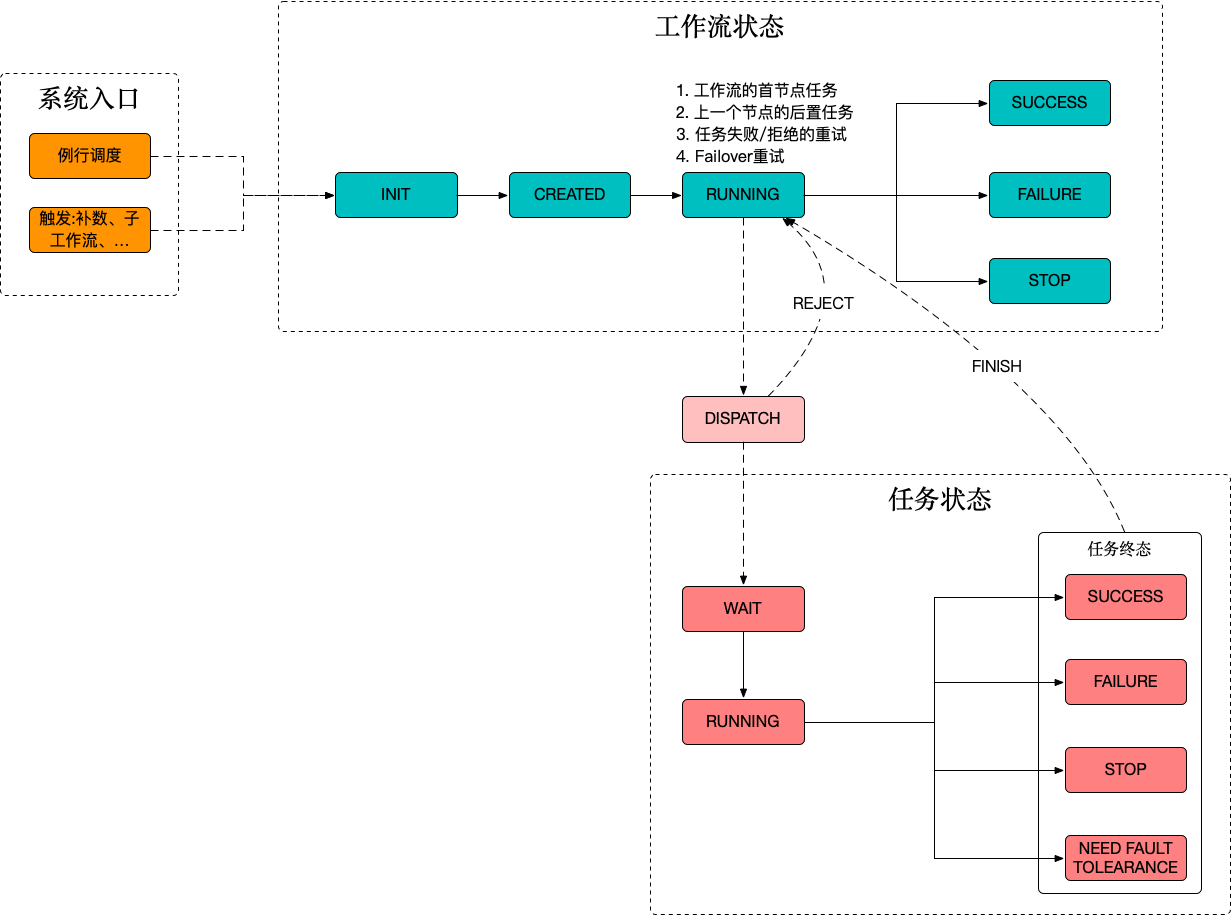
2.1. 系统入口
系统入口主要有:
- 例行调度:这是最常见的场景,类比于 crontab
- 手动执行:例如数据回溯场景的补数
注意任务恢复也会触发:主要是系统发起,针对前两种场景的任务可能的操作,例如容错场景、任务失败场景的重试
2.2. 工作流状态
工作流构建的第一步是构建 DAG,计算需要运行哪些任务及其依赖关系,筛选出任务的首节点。经过这一步,工作流就被分解成了包含依赖关系的多个任务。
Master 为任务选择合适的 Worker 实例,发送到该 Worker 处理,此时可能有多种情况:
- Worker 正常接收,回复ack
- Worker 实例正常但是此时任务饱和,回复 REJECT,Master 可以选择重试或者发送到其他 Worker
- Worker 实例 RPC 失败或者超时,Master 处理同上
注意即使 Worker 正常接收,在处理过程中也可能宕机,或者更新任务状态时与 Master 网络异常导致失联。无论是哪种原因,Master、Worker都面临了分区容错(Partition tolerance)的现状。
这里我们就面临一个经典的 CAP 的场景,Master 需要判断是否重新分配任务以满足可用性(A)还是等待 Worker 恢复以满足一致性(C)。
如果系统正常的话,工作流需要根据已经分配的任务实例状态,决定下一步的行为,例如工作流成功、工作流失败、继续分配DAG里的后置任务等等。
2.3. 任务状态
任务状态的处理相对简单一些,在一个优秀的任务调度框架中,任务处理应当是“单线程”的行为,即:
无需考虑锁和竞争,唯一关心的是输入以及输出
在 DolphinScheduler 中,任务处理在 Worker 模块实现,负责处理具体任务,例如执行Shell、发起HTTP请求、JDBC发起SQL执行等。任务处理完成的结果,无论成功或者失败,发送回 Master。
Master 负责更新任务状态,判断重试、忽略、报警等下一步的具体行为。
注:有一些逻辑处理,例如 dependent 等是在 Master 实现的,我个人觉得模糊了处理的边界,不太合理。
除了考虑前面描述的正常以及系统异常可能导致的状态,在实际系统中,还会有一些功能上导致状态复杂的场景,举几个常见的例子:
- 任务执行设置超时,Master 需要能够监控任务的执行时间,当达到超时阈值时更新任务状态。如果任务超时视为失败,则直接设置为失败。
- DAG 可以设置禁用某些节点,或者从某个节点开始执行,此时构建的 DAG 算子跟工作流定义就会存在 diff
- 串行对多个调度时间补数,取消是对当前工作流生效还是对后续所有待调度的补数工作流都生效
考虑系统正常、异常情况下任务的各种可能,以及结合上述功能设计任务状态变换,才能搭建扩展性足够好、对新人 less error-prone的任务调度系统。