Iterator 的思想在 stl 很常见,通过迭代器,可以实现算法和容器的解耦。当我们实现某个算法时,只需要关注迭代器的常见操作,例如++ --等,而不用关心作用的具体容器是 map 还是 vector.
在 leveldb 的代码里,迭代器的应用也非常普遍,接口上变成了next prev等,在我看来主要有两个好处:
- 通用的设计:我们已经都习惯了迭代器的使用,通过
Iterator来提供遍历数据的接口,学习成本低,protobuf里也在大量使用。
2.易于实现:在不同的数据上,实现相同的Iterator接口,使得在操作这些不同数据时,可以统一使用Iterator.这个跟 stl 里的思想是一致的。
正是由于大量的使用,理解leveldb 的Iterator,对通顺的阅读源码十分重要。
1. Iterator
Iterator是最原始的基类,定义在iterator.h
文档里的注释很全面,接口就不一一介绍了。
子类定义较多:
注:在SkipList里同样有一个SkipList::Iterator定义,跟本文内容无关.
2. leveldb::Block::Iter
leveldb::Block::Iter用于 block 的读取,例如 sstable 里的 data-block index-block meta-index-block 等
3. leveldb::MemTableIterator
leveldb::MemTableIterator用于 memtable 的读取
4. MergingIterator
MergingIterator用于文件多路归并,记录每一个 sstable 的 iterator,非常像 stl 里的merge.
初始化时,传入多个Iterator*
MergingIterator(const Comparator* comparator, Iterator** children, int n)
: comparator_(comparator),
children_(new IteratorWrapper[n]),
n_(n),
current_(nullptr),
direction_(kForward) {
for (int i = 0; i < n; i++) {
children_[i].Set(children[i]);
}
}
多个Iterator记录到children_,n_表示其大小。
以Seek为例:
virtual void Seek(const Slice& target) {
for (int i = 0; i < n_; i++) {
children_[i].Seek(target);
}
FindSmallest();
direction_ = kForward;
}
首先是所有Iterator*都查找target,然后通过FindSmallest找到最小的那个,记录到current_
void MergingIterator::FindSmallest() {
IteratorWrapper* smallest = nullptr;
for (int i = 0; i < n_; i++) {
IteratorWrapper* child = &children_[i];
if (child->Valid()) {
if (smallest == nullptr) {
smallest = child;
} else if (comparator_->Compare(child->key(), smallest->key()) < 0) {
smallest = child;
}
}
}
current_ = smallest;
}
后续每次Next都是current_++;FindSmallest()的过程,其实就是 mergesort 的指针操作了。
key()/value()返回的是current_->key()/value(),因此不断Next就可以有序获取到全部文件的数据。
Prev则恰好相反,direction_记录当前是Next/Prev,用于调整指针位置。
4. leveldb::Version::LevelFileNumIterator
LevelFileNumIterator接收一个有序的文件列表,支持查找 target 可能存在于哪个文件,以及遍历文件列表。
// 接收一个有序的文件列表,支持遍历
// key: 文件的largest key encode 后的值
// value: 文件的number && size encode 后的值
class Version::LevelFileNumIterator : public Iterator {
public:
LevelFileNumIterator(const InternalKeyComparator& icmp,
const std::vector<FileMetaData*>* flist)
: icmp_(icmp),
flist_(flist),
index_(flist->size()) { // Marks as invalid
}
还是以Seek为例:
//index_指向可能存在 target 的文件
virtual void Seek(const Slice& target) {
index_ = FindFile(icmp_, *flist_, target);
}
FindFile我们会在二分法里专门介绍下。
key存储文件的 largest,value存储文件的number + file_size,通过这两个值,我们就可以进一步使用Table::Open打开文件了。
Slice key() const {
assert(Valid());
return (*flist_)[index_]->largest.Encode();
}
Slice value() const {
assert(Valid());
EncodeFixed64(value_buf_, (*flist_)[index_]->number);
EncodeFixed64(value_buf_+8, (*flist_)[index_]->file_size);
return Slice(value_buf_, sizeof(value_buf_));
}
5. leveldb::TwoLevelIterator
leveldb::TwoLevelIterator顾名思义,是由两层的 iterator 实现的。
class TwoLevelIterator : public Iterator {
...
private:
...
BlockFunction block_function_;
void* arg_;
const ReadOptions options_;
Status status_;
IteratorWrapper index_iter_;
IteratorWrapper data_iter_; // May be nullptr
// If data_iter_ is non-null, then "data_block_handle_" holds the
// "index_value" passed to block_function_ to create the data_iter_.
std::string data_block_handle_;
}
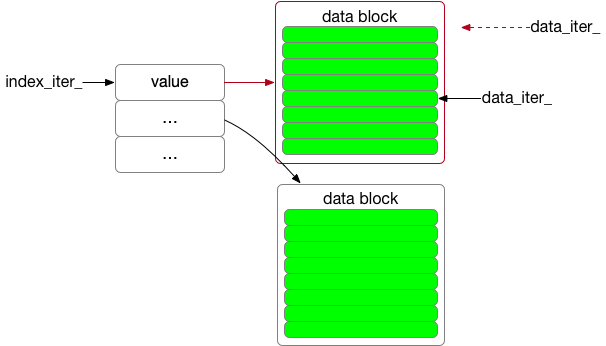
第一层 index_iter_ 指向索引
第二层 data_iter_ 指向数据
5.1. Table读取
Iterator* Table::NewIterator(const ReadOptions& options) const {
return NewTwoLevelIterator(
//传入index_block的iterator
rep_->index_block->NewIterator(rep_->options.comparator),
&Table::BlockReader, const_cast<Table*>(this), options);
}
table的读取为例,说明下Seek接口下两层 iterator 移动的方式。
// 先在 index block 找到第一个>= target 的k:v, v是某个data_block的size&offset
index_iter_.Seek(target);
// 根据v读取data_block,data_iter_指向该data_block内的k:v
InitDataBlock();
if (data_iter_.iter() != nullptr) data_iter_.Seek(target);
SkipEmptyDataBlocksForward();
可以看到是两个 iterator 逐次 Seek 同一个 target 的过程。
InitDataBlock通过index_iter_.value()定位到数据块,使用注册的block_function_解析该数据块,并且返回一个Iterator,赋值到data_iter_。
void TwoLevelIterator::InitDataBlock() {
if (!index_iter_.Valid()) {
SetDataIterator(nullptr);
} else {
Slice handle = index_iter_.value();
if (data_iter_.iter() != nullptr && handle.compare(data_block_handle_) == 0) {
// data_iter_ is already constructed with this iterator, so
// no need to change anything
} else {
// 返回该data block对应的iterator
Iterator* iter = (*block_function_)(arg_, options_, handle);
// 记录block的size&offset
data_block_handle_.assign(handle.data(), handle.size());
SetDataIterator(iter);
}
}
}
void TwoLevelIterator::SetDataIterator(Iterator* data_iter) {
if (data_iter_.iter() != nullptr) SaveError(data_iter_.status());
data_iter_.Set(data_iter);
}
此时,data_iter_只是刚初始化与数据块关联,还未指向任何数据,data_iter_.Seek(target)后,”可能”指向了target。
此时,就可以调用keyvalue接口来判断了(返回data_iter_.key()/value()):
virtual Slice key() const {
assert(Valid());
return data_iter_.key();
}
virtual Slice value() const {
assert(Valid());
return data_iter_.value();
}
two_level_iterator的设计,是单纯的二层 iterator 模型,实际上不止用于读取 table.
5.2. sst文件merge
考虑前面介绍的MergingIterator
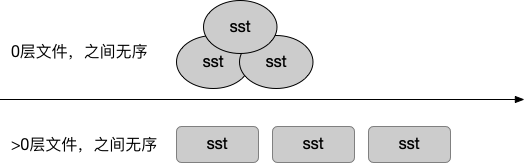
对 level 0,sstable files 之间数据是有 overlap 的,因此每次都需要判断current_指向哪个文件。
而对于 > 0 的 level,我们可以继续优化一些,因为 sstable files 之间数据是完全有序的,我们实际上可以用一个 iterator 来实现遍历。同时,先定位到文件,再定位到具体 key,也是一个二层 iterator 的模型。
// Create concatenating iterator for the files from this level
list[num++] = NewTwoLevelIterator(
// 遍历文件列表的iterator
new Version::LevelFileNumIterator(icmp_, &c->inputs_[which]),
&GetFileIterator, table_cache_, options);
第一层 iterator 就是前面介绍的Version::LevelFileNumIterator
第二层 iterator 由GetFileIterator返回,实际上就是用于 sstable 读取的TwoLevelIterator
6. 总结
可以看到 iterator 贯穿了整个 leveldb,memtable block sstable 等,而在 merge 时可以同时操作不同类型的 iterator,这种“神奇”效果的产生,就来源于对不同操作的抽象。