1. 简介
前面介绍了 sstable,包括 sstable 的结构组成及写入的源码分析,本文主要介绍下对应的读取过程,能够帮助读者更深入的理解一个 sstable 的数据格式。
2. 基本过程
sstable 的读取过程,简单总结就是四个字:按图索骥。
各个索引在这个过程发挥了很大的作用。
首先是 seek 到文件末尾读取固定48个字节大小的 footer,这也是为什么footer是定长的原因.
然后解析出 meta_index_block 以及 index_block。
通过 meta_index_block 解析出 filter block,通过 index_block 解析出 data_block.
查找时,先通过 filter block 查找是否存在,然后通过 data_block 解析出对应的 value.
3. 源码解析
源码位于table.cc.
相关类图:
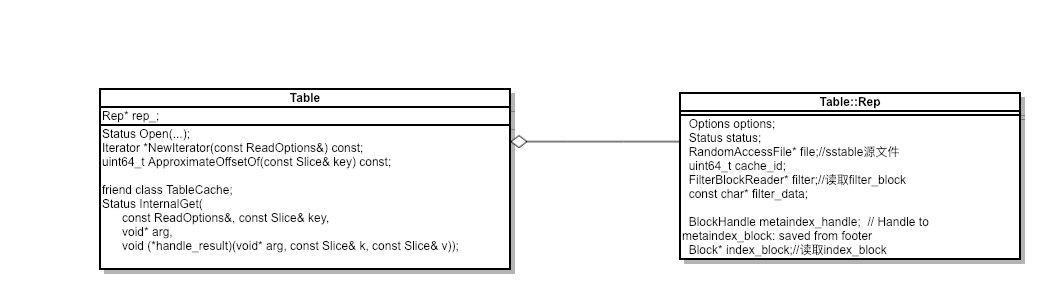
可见,Table对外接口比较简单:
Open是一个 static 函数,用于打开 sstable 文件并且初始化一个Table*对象。
NewIterator返回读取该 sstable 的 Iterator,用于读取 sstable.
实现部分都交给了Table::Rep这个结构体(Rep在 leveldb 源码里多次见到,类似于 pimpl 的设计,不过一直没想到是什么缩写)。
3.1. Open
Open接口声明为:
static Status Open(const Options& options,
RandomAccessFile* file,
uint64_t file_size,
Table** table);
options用于后续的文件 checksums,filter policy名字查找等判断时使用。
file提供了文件读取的接口。
file_size对应file的文件大小。
table是一个输出参数,通过调用该对象就可以实现查找/遍历 sstable 了。
首先读取文件末尾固定长度的48个字节,反序列化到Footer footer
char footer_space[Footer::kEncodedLength];
Slice footer_input;
//读取最后kEncodedLength个字节,即Footer大小,存储到footer_input
Status s = file->Read(size - Footer::kEncodedLength, Footer::kEncodedLength,
&footer_input, footer_space);
if (!s.ok()) return s;
Footer footer;
//从footer_input解析出footer
s = footer.DecodeFrom(&footer_input);
if (!s.ok()) return s;
从footer.index_handle指示的 size&offset 读取 index block 对应的 buffer
// Read the index block
// footer里存储了index block的offset&size,即index_handle
// 读取对应的内容,内容存储到index_block_contents
BlockContents index_block_contents;
if (s.ok()) {
ReadOptions opt;
if (options.paranoid_checks) {
opt.verify_checksums = true;
}
s = ReadBlock(file, opt, footer.index_handle(), &index_block_contents);
}
数据解析到rep->index_block。然后读取 filter block,记录到rep_->filter,之后就主要通过这两个类的接口定位 sstable 内的数据了。
3.2. NewIterator
考虑下 sstable 的数据格式,不考虑 filter 的话,查找是一个二层递进的过程:
先查找 index block,查看可能处于哪个 data block,然后查找 data block,找到对应的 value,因此需要两层的 iterator,分别用于 index block && data block。
Iterator* Table::NewIterator(const ReadOptions& options) const {
return NewTwoLevelIterator(
//传入index_block的iterator
rep_->index_block->NewIterator(rep_->options.comparator),
&Table::BlockReader, const_cast<Table*>(this), options);
}
第一个参数传入 index block 的 iterator,用于第一层查找。查找到的 value 会传递给第二个参数(函数指针),该函数支持解析 value 的 data block,第三、四个参数都在函数调用时使用。
NewTwoLevelIterator实际上是返回TwoLevelIterator
Iterator* NewTwoLevelIterator(
Iterator* index_iter,
BlockFunction block_function,
void* arg,
const ReadOptions& options) {
return new TwoLevelIterator(index_iter, block_function, arg, options);
}
TwoLevelIterator继承自Iterator,实现了Seek/Prev/Next/key/value等一系列接口。
接下来分别介绍下TwoLevelIterator以及Table::BlockReader
3.2.1 TwoLevelIterator
正如其名,由两个 iter 组成,分别指向 index block,以及某个 data block.(注:IteratorWrapper封装了Iterator,可以先简单认为是等价的。)
IteratorWrapper index_iter_;
IteratorWrapper data_iter_; // May be nullptr
举一个Seek的例子:
void TwoLevelIterator::Seek(const Slice& target) {
// 先在 index block 找到第一个>= target 的k:v, v是某个data_block的size&offset
index_iter_.Seek(target);
// 根据v读取data_block,data_iter_指向该data_block内的k:v
InitDataBlock();
if (data_iter_.iter() != nullptr) data_iter_.Seek(target);
SkipEmptyDataBlocksForward();
}
先通过index_iter_找到第一个 >= target 的 key, 对应的 value 是某个 data block 的 size&offset,接下来继续在该 data block 内查找。
为什么可以直接在这个 data block 内查找?我们看下原因。
首先,(index_iter_ - 1).key() < target,而index_iter_ - 1对应的 data block 内所有的 key 都满足 <= (index_iter_ - 1)->key(),因此该 data block1 内所有的 key 都满足< target.
其次,index_iter_.key() >= target,而index_iter_对应的 data block2 内所有的 key 都满足 <= index_iter_->key()。
同理,index_iter + 1对应的 data block3 内所有的 key 都满足 ` > (index_iter_ + 1)->key()`.
而 data block123是连续的。
因此,如果 target 存在于该 sstable,那么一定存在于index_iter_当前指向的 data block.
注:
- 如果
index_iter_指向第一条记录,那么index_iter - 1无效,但不影响该条件成立。 - 关于
index_iter_的 key 的取值,参考[leveldb-sstable r->last_key]的介绍
之后就是调用InitDataBlock初始化,使得data_iter_指向该 data block,其中就用到了传入的block_function,注意调用时的第三个参数即index_iter_.value().
void TwoLevelIterator::InitDataBlock() {
if (!index_iter_.Valid()) {
SetDataIterator(nullptr);
} else {
Slice handle = index_iter_.value();
if (data_iter_.iter() != nullptr && handle.compare(data_block_handle_) == 0) {
// data_iter_ is already constructed with this iterator, so
// no need to change anything
} else {
// 返回该data block对应的iterator
Iterator* iter = (*block_function_)(arg_, options_, handle);
// 记录block的size&offset
data_block_handle_.assign(handle.data(), handle.size());
SetDataIterator(iter);
}
}
}
接着使用data_iter->Seek就定位到实际的 {key:value} 了。
3.2.2 Table::BlockReader
block_function即Table::BlockReader,搞清楚传入的参数之后就比较直观了,就是解析 data block ,返回对应的 Iterator.实现里缓存相关操作可以参考leveldb笔记之12:LRUCache的使用
.
3.3. InternalGet
Table声明了友元TableCache,主要用于直接调用InternalGet这个函数,查找过程跟NewIterator很像,只是多了 filter 的过程,如果filter->KeyMayMatch显示不存在,那么直接返回。
跟BlockReader一样,注释比较详细,就不一一展开了。
4. 例子
调用Table的接口可以直接解析 leveldb 产出的原始 sst 文件,当然,也包括我们之前TableBuilder例子里生成的数据。
主要就是通过NewIterator接口返回的迭代器遍历,看了之后相信读者会有一个更直观的解释。
void scan_by_table_iterator() {
leveldb::Table* table = nullptr;
std::string file_path = "./data/test_table.db/000005.ldb";
// std::string file_path = "./table_builder.data";
//New RandomAccessFile
leveldb::RandomAccessFile* file = nullptr;
leveldb::Status status = leveldb::Env::Default()->NewRandomAccessFile(
file_path,
&file);
std::cout << "NewRandomAccessFile status:" << status.ToString() << std::endl;
//New Table
struct stat file_stat;
stat(file_path.c_str(), &file_stat);
status = leveldb::Table::Open(
leveldb::Options(),
file,
file_stat.st_size,
&table);
std::cout << "leveldb::Table::Open status:" << status.ToString() << std::endl;
leveldb::Iterator* iter = table->NewIterator(leveldb::ReadOptions());
iter->SeekToFirst();
while (iter->Valid()) {
std::cout << iter->key().ToString() << "->" << iter->value().ToString() << std::endl;
iter->Next();
}
delete iter;
delete file;
delete table;
}
完整代码例子参见table_test.