本文主要介绍 leveldb 入门例子,基于例子里的各个接口介绍下基本架构。
1. 例子
leveldb 的接口使用十分简单,看一个读和写的例子:
#include <assert.h>
#include <iostream>
#include "leveldb/db.h"
int main() {
leveldb::DB* db = NULL;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "./data/test.db", &db);
std::cout << status.ToString() << std::endl;
std::string key = "name";
#if defined(WRITE_MODE)
std::string value = "Jeff Dean";
//写入key, value
status = db->Put(leveldb::WriteOptions(), key, value);
std::cout << "write key:" << key << " value:" << value << " " << status.ToString() << std::endl;
#else
std::string db_value;
status = db->Get(leveldb::ReadOptions(), key, &db_value);
std::cout << "read key:" << key << " value:" << db_value << " " << status.ToString() << std::endl;
#endif
return 0;
}
根据WRITE_MODE宏分别生成 read/write
$ g++ -o write_test test.cpp ../build/libleveldb.a -I ../build/include -I ../include -I .. -std=c++11 -g -DLEVELDB_PLATFORM_POSIX -DLEVELDB_HAS_PORT_CONFIG_H -lpthread -DWRITE_MODE
$ g++ -o read_test test.cpp ../build/libleveldb.a -I ../build/include -I ../include -I .. -std=c++11 -g -DLEVELDB_PLATFORM_POSIX -DLEVELDB_HAS_PORT_CONFIG_H -lpthread
# 第一次读 NotFound
$ ./read_test
OK
read key:name value: NotFound:
# 写入 OK
$ ./write_test
OK
write key:name value:Jeff Dean OK
# 第二次读 OK
$ ./read_test
OK
read key:name value:Jeff Dean OK
同时本地生成了几个数据库文件
$ ls data/test.db/
000007.ldb 000008.log CURRENT LOCK LOG LOG.old MANIFEST-000006
leveldb 提供的接口十分简洁,主要有:
Put //写入
Delete //删除
Write //批量写入
Get //读取
Put/Delete/Write本质上都是一个写入流程,Get用于获取数据,可以指定 snapshot ,即获取某个历史时刻的镜像值。
2. 架构
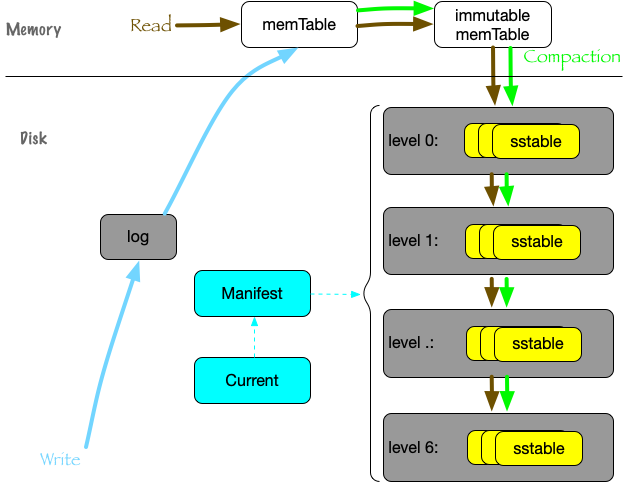
leveldb 主要由以下组件组成:
- log: write-ahead logging是数据库的一种常见手段,数据按照 ->log->mem 的顺序更新,由于数据已经持久化到磁盘,因此即使进程异常也能够保证数据的完整性,同时这里是追加写,因此写性能极高。
- memtable: 最近写入的 key-value 数据,内存存储,读取数据首先从这里查找。
- immutable memtable: 为了限制内存大小,当 memtable 达到一定大小后,会转换为immutable memtable。后台线程会把immutable memtable 持久化到硬盘,持久化的文件称为 level-0 sstable,这个过程称为 minor compact.
- sstable: 由上层(or上上层)的 sstable 合并成新的sstable,并写入到下一层,这个过程称为 major compact,因此层数越小,数据越新,层数越大,数据越久远。
- manifest: read/compaction 过程可能是同时进行的,因此需要能记录对应的文件集合,manifest就是起到记录各阶段文件集合信息的,为了更快速的查找,可能还会记录一些附加信息,例如文件大小、最大最小 key 等。
leveldb 提供的接口在 db.h,我们从接口来看下这几个组件的必要性:
首先,可靠的单机数据库需要做到的是,当用户调用写入接口返回成功后,进程重启(甚至部分原因的机器宕机)都不会导致丢失数据。
因此,写入数据时,需要先更新数据到 log,再写入内存,然后返回用户写入结果。内存数据结构需要满足高效的查找和插入, leveldb 将这个数据结构称之为 memtable,其底层则用 skiplist 来实现,数据是有序的。
内存不可能无限增长,因此 leveldb 提供了一种类似双 buffer 的机制来管理 memtable:
当 memtable 增加到一定大小后,会转为只读不写的 memtable,称为 immutable memtable,并且 new 一个新的 memtable 供写入时更新。同时,后台线程会持久化 immutable memtable到磁盘。
持久化后的文件,就称为sstable,位于level 0,由于 memtable 是有序的,持久化后的单个文件内数据也是有序的。
而对于读操作,自然的,需要从 memtable、immutable memtable、level-0 sstable里查找。
当level 0的文件越来越多,查找会越来越慢,占用的磁盘空间也越来越大,因此,需要对这些文件进行多路归并,归并后的好处有两个:
- level 0多个文件的数据有交集,而多路归并后的N个新文件,可以是有序而且没有交集的,提高查找效率
- 节省磁盘空间,降低存储占用
归并后的新文件,格式也是 sstable,称之为 level 1 sstable,因为基于全局数据进行归并,所以这一层的 sstable 不仅文件内有序,文件之间也是有序的,数据没有交集。
level 1的文件也可能很快越来越多,也需要继续归并产出新的 sstable 文件,这些文件称为 level 2 sstable,以此类推,最大一直到 level 6.
数据从level 0,逐渐 compact 到 level 6,有点类似于数据在逐渐merge沉淀的过程,一层层下降,也是 leveldb 名字的由来。
对照 compact 的流程,数据新旧程度按照这几个组件排序
memtable -> immutable memtable -> level 0 sstable -> ... -> level 6 sstable
因此对于读操作,需要按照这个顺序读取,如果读到了就返回,不需要再读下一层的数据。也就是为什么我们说 leveldb 适合于读取最近写入的数据的场景。
完成上面 compact 流程的是一个后台线程。
leveldb 的整体架构基本就是上述这样,但是脱离了细节,想要理解 leveldb 还是很困难,比如后台线程是怎么触发 compact 的?log/memtable/sstable 存储的数据格式什么样子?Put/Get 流程都会发生什么?多路归并是怎么做的?snapshot 功能怎么做到的?例子里的几个本地文件都是什么用?
诸如此类,也是我刚接触 leveldb 时非常好奇的问题,希望接下来的一系列笔记能够介绍清楚。当逐步了解之后,对 leveldb 会有一个全面清晰的认知。