声明:本站点文章内容均为古法手作,仅用 AI 辅助,没有使用 AI 生成(代码、图片、公式、格式化除外)。
1. 记忆
大模型是无状态,不会记住任何先前的对话内容。
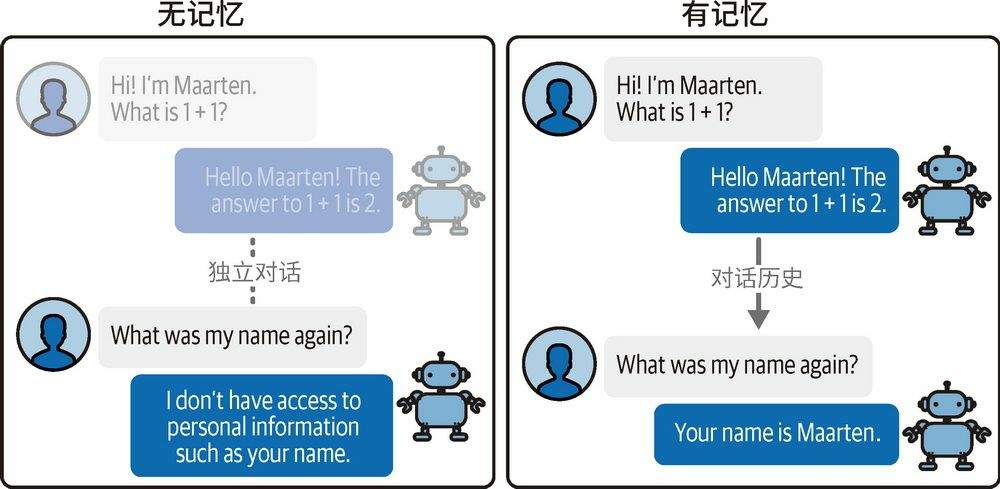
注意书里介绍的是短期记忆
常见记忆方式有两种:
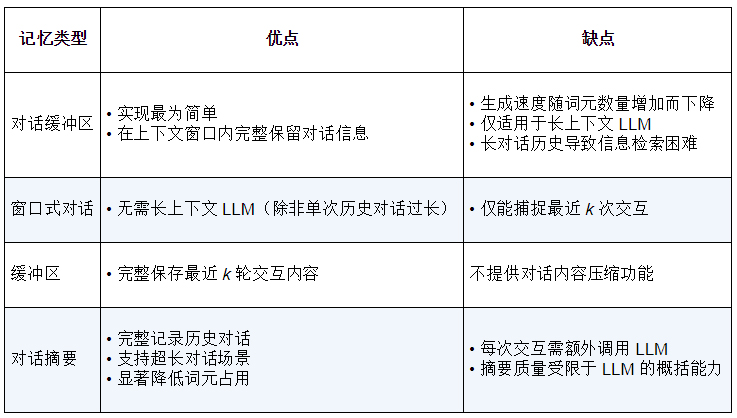
- 对话缓冲区
- 对话摘要
1.1. 对话缓冲区
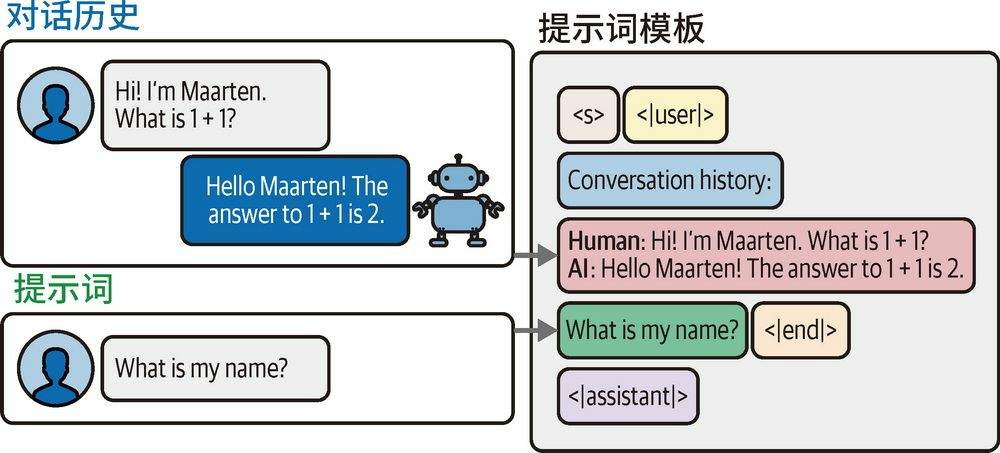
LangChain 框架使用ConversationBufferMemory ConversationBufferWindowMemory实现,原理上就是将每轮对话的user system都发给大模型,上限则通过对话轮数或者 tokens 个数控制。
1.2. 对话摘要
如果不控制上限,对话缓冲区随着对话内容持续增长,并逐渐逼近模型的词元限制;如果控制上限,又可能丢失较早的对话内容。
对话摘要用来解决这个问题。
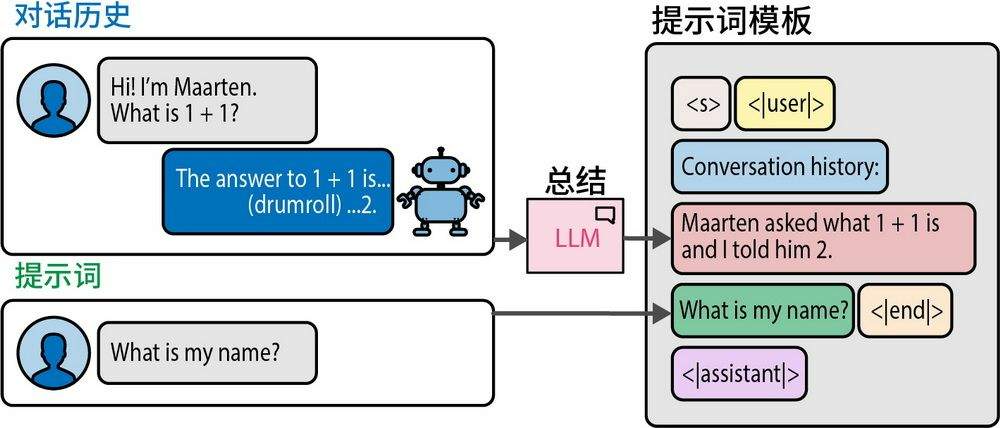
即将历史对话转为摘要。提取摘要的过程,依赖 LLM 参与,例如可能的提示词:
# 创建摘要提示词模板
summary_prompt_template = """<s><|user|>Summarize the conversations and update
with the new lines.
Current summary:
{summary}
new lines of conversation:
{new_lines}
New summary:<|end|>
<|assistant|>"""
summary_prompt = PromptTemplate(
input_variables=["new_lines", "summary"],
template=summary_prompt_template
)
输入是Nth 轮之前的 summary、N 轮之后的对话,输出则是新的 summary
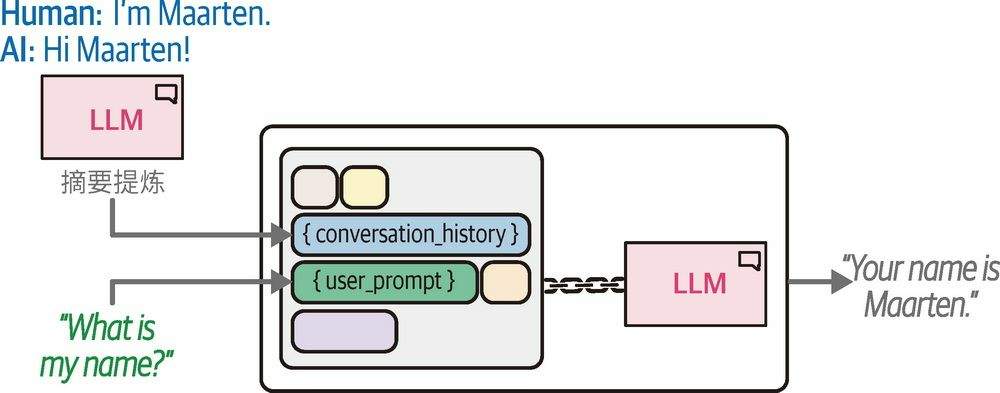
1.3. 记忆总结
实际工程里用到的记忆框架,例如 Mem0、MemOS 等,要复杂的多,但是我觉得本质还是一回事,区别是给自己扩大了 scope.
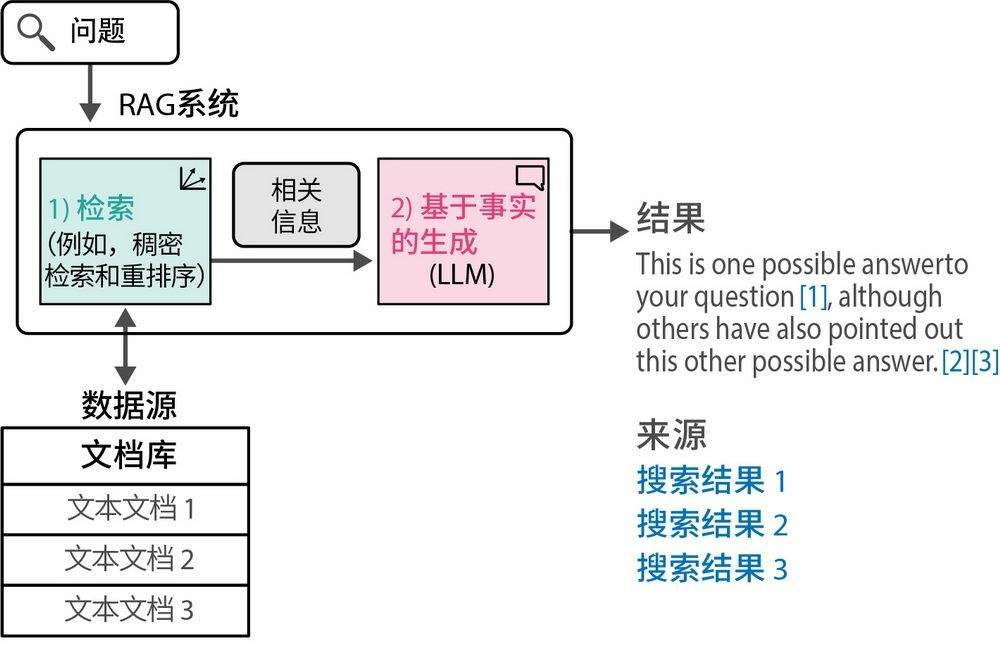
2. RAG
通过 RAG 里的知识库,解决了 LLM 知识过时、没有专业知识的问题。
2.1. 向量化
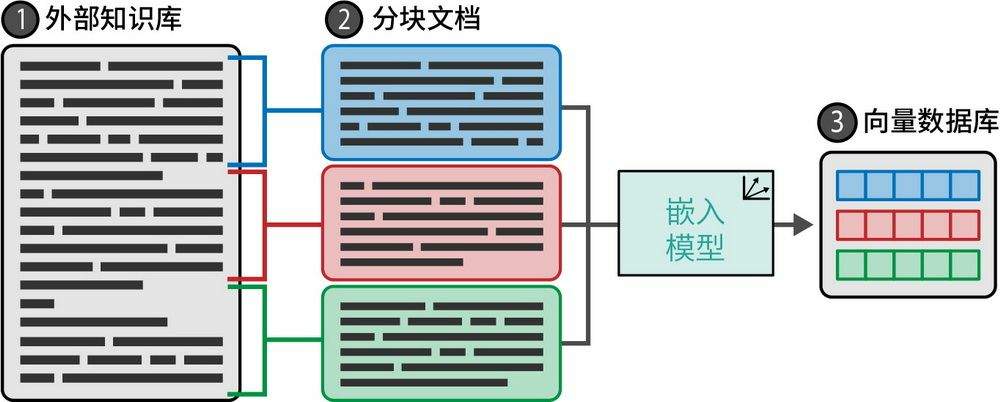
- 文档分块
- 各分块通过嵌入模型转化为向量表示
- 存储在向量数据库中以备检索
2.2. 长文本分块策略
这里一个很大的挑战是 LLM 有 tokens 上限。
有两个解决思路:
- 单文档单向量
- 单文档多向量

单文档单向量,需要能够提取出代表性的段落,忽略剩余内容。例如标题、文章前几段等。这里让我想起来构建搜索系统时,spider 系统抓取到网页后,需要能够基于模型提取标题、过滤低质的广告内容等。基于加工后的数据建库,才能起到好的搜索效果。
单文档多向量,则是把长文本分块,解决单个分块太大导致 LLM 无法处理或者丢失重点。
常见的分段方式有:

目前看到的大部分智能体平台,都是丢给用户一个页面,让用户输入分隔符、分段长度、是否重叠等等,而这里对最后的召回效果影响极大,如何能够提早针对搜索效果,优化这个建库的过程,应该是非常值得做的方向。
实际应用到生产,很可能是上述两种思路的结合:
- 即使是单文档多向量,也需要先采用单文档提取的方式,过滤低质、提取重点,然后再经过不同方式分段。对每个分段,也保留文章的核心信息,这样才能避免分段后缺失整体文章重点的问题。
- 作者的观点:“随着稠密检索技术的持续演进,更多创新的分块策略正在涌现——部分方案已开始利用LLM实现动态智能分块,以生成语义连贯的文本单元。”