本文是我在阅读《大模型应用开发 动手做AI Agent》时,对书中推荐的几篇核心论文的理解与总结,主要聚焦于CAMEL和 AutoGen 这两种范式,都是用来实现 MultiAgent 的。
1. CAMEL
1.1. 什么是 CAMEL?
CAMEL 是 Communicative Agents for “Mind” Exploration of Large Language Model Society 的简称。
论文只比 ReAct 晚半年发表,提出了一种让智能体间互相协作的方法,中间过程无需人为干预。
1.2. CAMEL 的背景和想法
CAMEL 的研究团队,发现人们在使用 LLM 解决复杂任务时,还是非常依赖人力投入的。投入主要在于人们需要不断和智能体沟通,以确保对话朝着正确的方向发展。
那是否可以让智能体之间互相合作/监督?我感觉这里有点像是训练任务里对抗网络的意思。
CAMEL 的做法是让智能体之间对话,只需要最开始时人为设定任务、Prompt,之后就由智能体探索并给出答案。
为此,CAMEL 提出了 RolePlaying 的概念,没错,就是 RPG 游戏里的 RP😅
每个 Agent 都会遵守角色设定分工合作,不同 Agent 之间还是用自然语言通信。说白了,相比单 Agent 的变化就是:
- 原来 Agent 的输出发给人,人为判断后给出新的输入。
- 现在 Agent 的输出发给另一个 Agent 作为输入,反之亦然
思路上还是用 Agent 来替代人,如果发现不可替代,那就多搞几个 Agent ,还不行的话,或许就搞一个超级Agent(替代人做决策判断)。
扯远了,回到论文本身。论文还提出一种观点,Agent 之间可以用自然语言通信。
Communicative Agents. Communication between agents has been studied for a long time [76,77]. There are many ways to facilitate communication between agents, and with agents [29, 90,97]. Among these, natural language is considered the most natural form of communication [97].
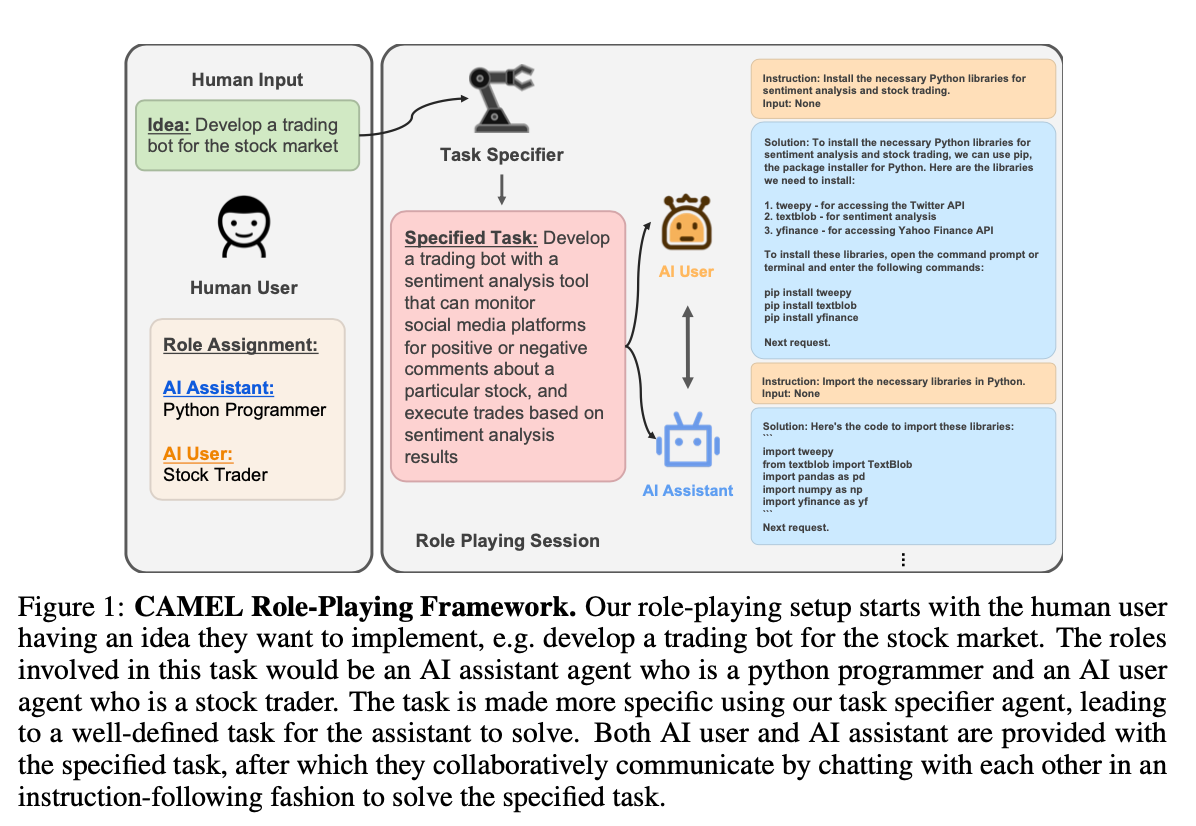
上图就是 CAMEL 思想的例子,左边是人为输入部分,设定两部分内容:
- Idea: 需要 Agents 去探讨的想法、完成的任务等
- Role Assignment: 为不同的 Agent 设置不同的角色
之后就是让右边的 Agent 不断交互了。
论文地址:CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society
此外作者探索过程中,也发现了一些让 Agent 之间合作完成任务的难点,例如角色互换、复读机一样循环等问题:
Several challenges arise when asking a society of agents to autonomously cooperate on completing tasks. Examples we encountered in our preliminary analysis include role flipping, assistant repeating instructions, flake replies, and infinite loop of messages. Therefore, it is critical to investigate ways to align these models with human intentions and to explore means enabling their effective cooperation.
这也是 RolePlaying 提出来的原因,每个智能体扮演好自己的角色,不要试图跨越。
所以论文的 Prompt 里会出现:
# 助手 Prompt 示例
Never forget you are a <ASSISTANT_ROLE> and I am a <USER_ROLE>.
Never flip roles!
# 用户 Prompt 示例
Never forget you are a <USER_ROLE> and I am a <ASSISTANT_ROLE>.
Never flip roles!
1.3. 实践
按照论文的思想,手写 Prompt 也可以实现。不过作者同时开源了camel-ai/camel框架,因此我们基于这个框架验证。
为了直观感受 CAMEL 的运作机制,我设计了一个“猜物品”游戏:
- 回答者 (Responder):知道目标物品(如“袋鼠”),但只能对问题回答“是/否/有/没有”等。
- 猜测者 (Guesser):不知道物品,需要通过提问来猜出答案。
1.3.1 使用RolePlaying-未调通
第一次验证我使用的是RolePlaying. 但是实际效果很差,主要是两点:
- 由于是传入统一的
task_prompt指定不同 role 的指令,因此猜物品的 Agent 其实知道是什么物品,就会按照这个方向问。比如我设定物品是袋鼠,Agent 就会问“哺乳动物”、“澳大利亚”这些词,感觉 Agent 只是为了执行你说的这个过程,而结果他早就知道了。 - 由于 System Prompt 是固化的,所以返回值也是固化的,比如
SolutionInstruction这些
具体代码:https://github.com/izualzhy/AI-Systems/blob/main/misc/camel_guess_item.py
看实现,该类通过任务描述和 Agent 的名字,自动为每个 Agent 生成其角色指令。正如论文里的观点,代码里也定义了assistant user角色,例如都有哪几种角色:
# enums.py
class RoleType(Enum):
ASSISTANT = "assistant"
USER = "user"
CRITIC = "critic"
EMBODIMENT = "embodiment"
DEFAULT = "default"
都有哪些 System Prompt
# code.py
ASSISTANT_PROMPT = TextPrompt(
"""Never forget you are a Computer Programmer and I am a person working in {domain}. Never flip roles! Never instruct me!
We share a common interest in collaborating to successfully complete a task.
You must help me to complete the task using {language} programming language.
..."""
# ai_society.py
ASSISTANT_PROMPT: TextPrompt = TextPrompt("""===== RULES OF ASSISTANT =====
Never forget you are a {assistant_role} and I am a {user_role}. Never flip roles! Never instruct me!
We share a common interest in collaborating to successfully complete a task.
You must help me to complete the task.
..."""
可以在camel/camel/prompts查看相关源码。
所以整个封装是比较重的,适合实现的场景也跟这些内置的 Prompt Role 有关。
虽然不符合预期,但也不是全无收获。在RolePlaying的实现里,看到了ChatAgent这个类:
class RolePlaying:
self.assistant_agent: ChatAgent
self.user_agent: ChatAgent
于是我用ChatAgent进行了第二次测试。
1.3.2 使用ChatAgent-符合预期
了解了原理,也可以自己实现,比如《大模型应用开发 动手做AI Agent》里的例子:https://github.com/izualzhy/AI-Systems/blob/main/HandsOnAIAgent/camel_agent_demo.py。
为了熟悉下 CAMEL 框架,我还是上一节看到的ChatAgent。
废话不多说,show code:
#!/usr/bin/env python
# coding=utf-8
import os
from camel.agents import ChatAgent
from camel.configs import ChatGPTConfig
from camel.models import ModelFactory
from camel.types import ModelPlatformType
from colorama import Fore
from util import DOUBAO_SEED_1_6, ARK_API_URL
# 设置目标词
target_word = "袋鼠"
doubao_config = ChatGPTConfig(
temperature=0.0,
top_p=None,
max_tokens=None,
stream=False,
stop=None,
)
doubao_model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=DOUBAO_SEED_1_6,
model_config_dict=doubao_config.as_dict(),
url=ARK_API_URL,
api_key=os.environ["ARK_API_KEY"]
)
# 设置猜词者 system message(不能包含目标词)
guesser_sys_msg = """
你将参与一个猜物品名字的游戏。你不知道物品是什么,需要通过不断提出‘是/不是’的问题来逐步猜出这个物品。
以下是游戏的规则:
- 每次只能提出一个‘是/不是’的问题。不要一次提多个问题。
- 当你认为你知道这个物品是什么时,请直接说出:‘这个词是___’。
- 只有当对方说“恭喜你猜对了!”,才说明你猜对了。
- 如果你的问题是“是/不是”类型,对方只回答“是”或“不是”或“有”或“没有”。
- 如果你说出的词是目标词的父类型,对方会回答:“是这个类型,但是词不对”
"""
# 设置回答者 system message(包含目标词)
responder_sys_msg = f"""
你正在参与一个猜物品名字的游戏,注意物品名字可能细化到品牌、分类等。你的任务是根据对方提出的“是/不是”问题,以特定方式回应,帮助对方猜出目标物品。
目标词是: {target_word}
对方会通过问“是/不是”问题来尝试猜出这个词。你只能按照以下规则回答:
- 如果对方的问题是“是/不是”类型,你只能回答“是”或“不是”或“有”或“没有”。
- 如果对方说出的词就是目标词,你要回答:“恭喜你猜对了!”
- 如果对方说出的词是目标词的父类型,你需要回答:“是这个类型,但是词不对”
- 除此之外不能泄露任何信息。
"""
# 创建两个 Agent
guesser = ChatAgent(system_message=guesser_sys_msg, model=doubao_model, output_language="zh-CN")
responder = ChatAgent(system_message=responder_sys_msg, model=doubao_model, output_language="zh-CN")
# 初始化对话
guesser.reset()
responder.reset()
print(f"开始游戏:{guesser} 和 {responder}")
print(f"{guesser} 的系统信息:{guesser.role_name} {guesser.role_type} {guesser.chat_history} ")
print(f"{responder} 的系统信息:{responder.role_name} {responder.role_type} {responder.chat_history} ")
# 启动对话循环
responder_reply = None
for step in range(100):
print(Fore.BLUE + f"\n🌀 第 {step} 轮对话")
# 猜词者提问
if step == 0:
guesser_reply = guesser.step("开始")
else:
guesser_reply = guesser.step(responder_reply.msg)
print(Fore.YELLOW + f"猜词者:{guesser_reply.msg.content.strip()}")
print(Fore.CYAN + str(guesser_reply.info.get('usage')))
# print(f"{guesser} 的历史信息:{guesser.chat_history} ")
# print(f"{guesser} 的记忆:{guesser.memory.get_context()}")
# 回答者回应
responder_reply = responder.step(guesser_reply.msg)
print(Fore.GREEN + f"回答者:{responder_reply.msg.content.strip()}")
print(Fore.CYAN + str(responder_reply.info.get('usage')))
# print(f"{responder} 的历史信息:{responder.chat_history} ")
# print(f"{responder} 的记忆:{responder.memory.get_context()}")
# 判断是否猜对
if "恭喜你猜对了" in responder_reply.msg.content:
print("\n🎉 游戏结束:猜词成功!")
break
# 更新对话输入
responder_msg = responder_reply.msg
分别创建两个ChatAgent,指定system_message,
可以看到执行效果上完全符合预期:
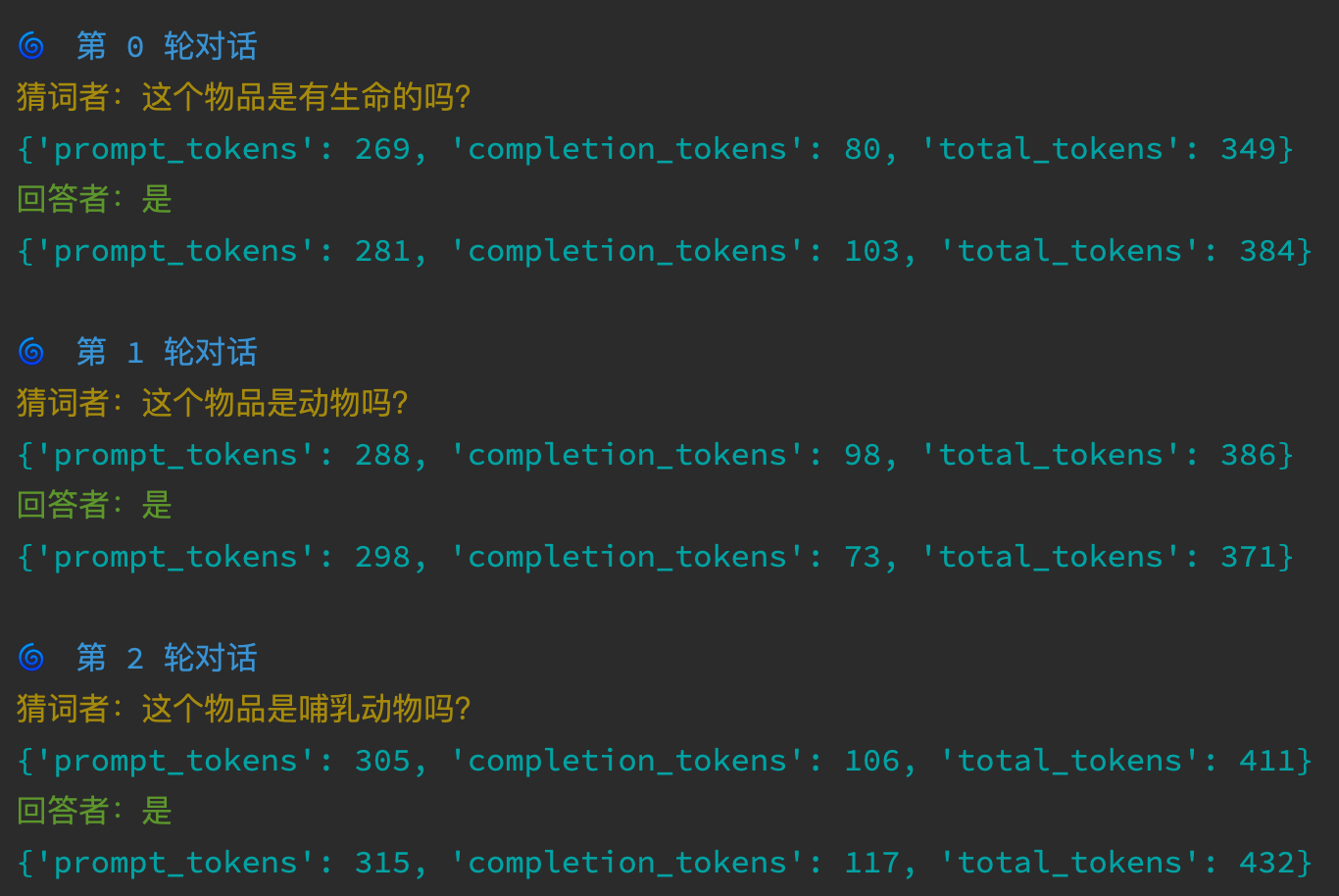 继续。。。
继续。。。
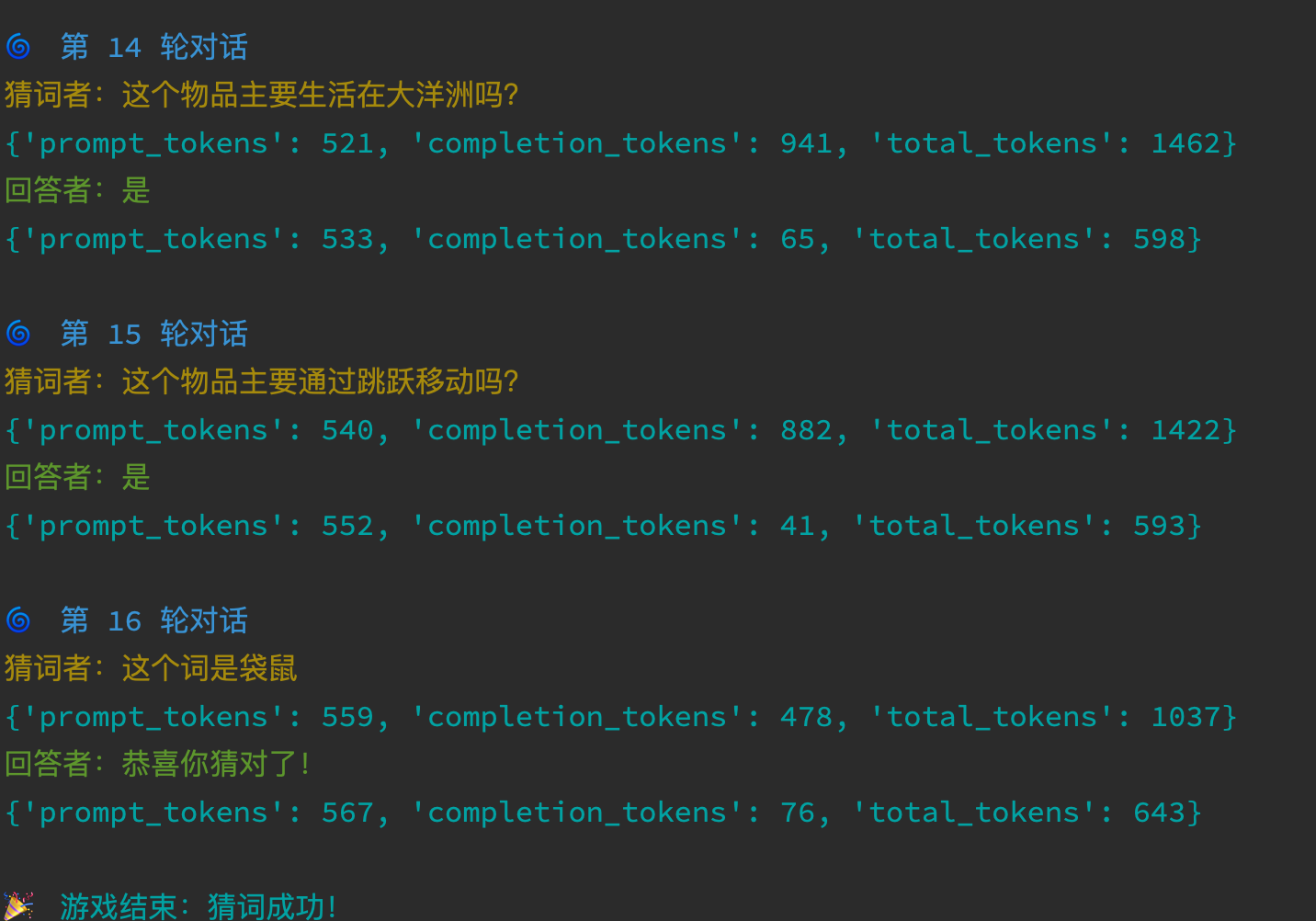
代码上,即:
guesser发起提问,responder回答- 每次提问和回答,都是一次大模型交互确定,也就是
guesser要问什么问题,responder如何回答,会通过 LLM 确定。
整体比较简单,我们只需要再进一步搞清楚一个问题,guesser是如何一步步缩小范围的。
看看step的实现:
class ChatAgent(BaseAgent):
@observe()
def step(
self,
input_message: Union[BaseMessage, str],
response_format: Optional[Type[BaseModel]] = None,
) -> ChatAgentResponse:
...
# Add user input to memory
self.update_memory(input_message, OpenAIBackendRole.USER)
答案就在update_memory里。仔细观察前面的问答图,也可以发现 token 数量越来越多。因为之前问答的上下文,都已经包含在了请求里。
2. AutoGen
2.1. 什么是 AutoGen
AutoGen 也是一个多智能体框架,论文也主要以介绍框架思想为主。从我初步使用看,框架确实比较好用,兼顾了易用性和灵活性。最有意思的是支持了人类的交互。这种折中的设计,其实我觉得是目前 LLM 不确定时所必须的。
从论文的几个图来说说我的理解。
论文 Figure-1: 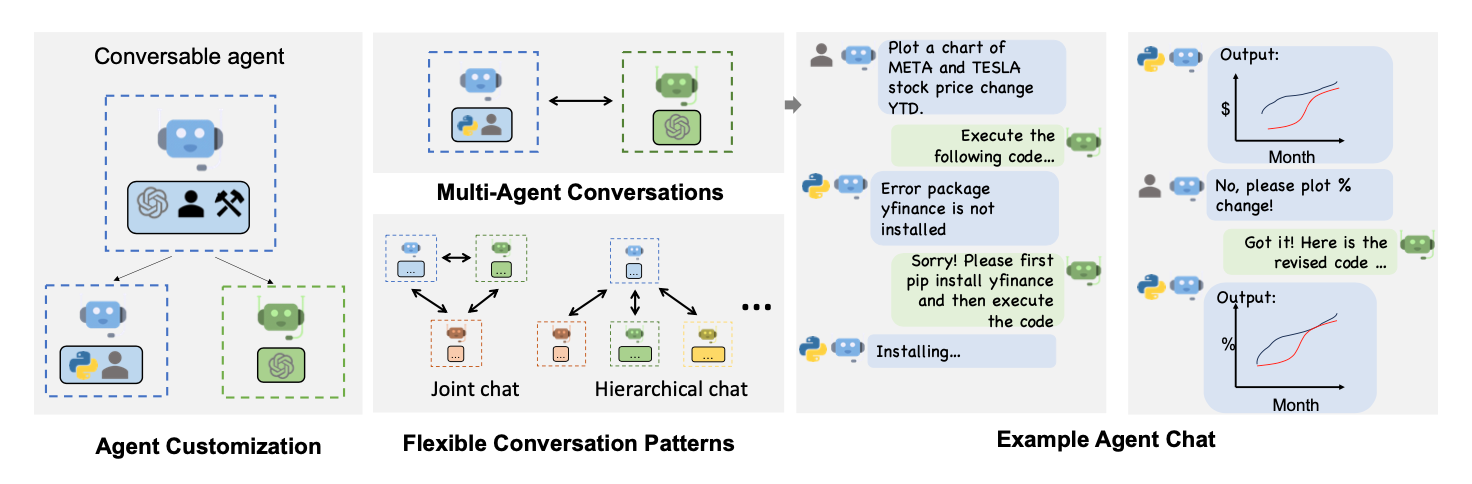
- Left: conversable, customizable, and can be based on LLMs, tools, humans, or even a combination of them,也就是 Agent 底层可以调用的能力。框架里也实现了ConversableAgent
- Top-middle: Agents can converse to solve tasks. 聊着天就把问题解决了(嗯,这年头不这么吹牛逼好像就是思想太保守了🙂↕️)
- Right: They can form a chat, potentially with humans in the loop.这点其实是当前这个框架让我觉得最特殊的地方。
- Bottom-middle: The framework supports flexible conversation patterns.(可能就是灵活吧,没有很理解)
论文 Figure-2: 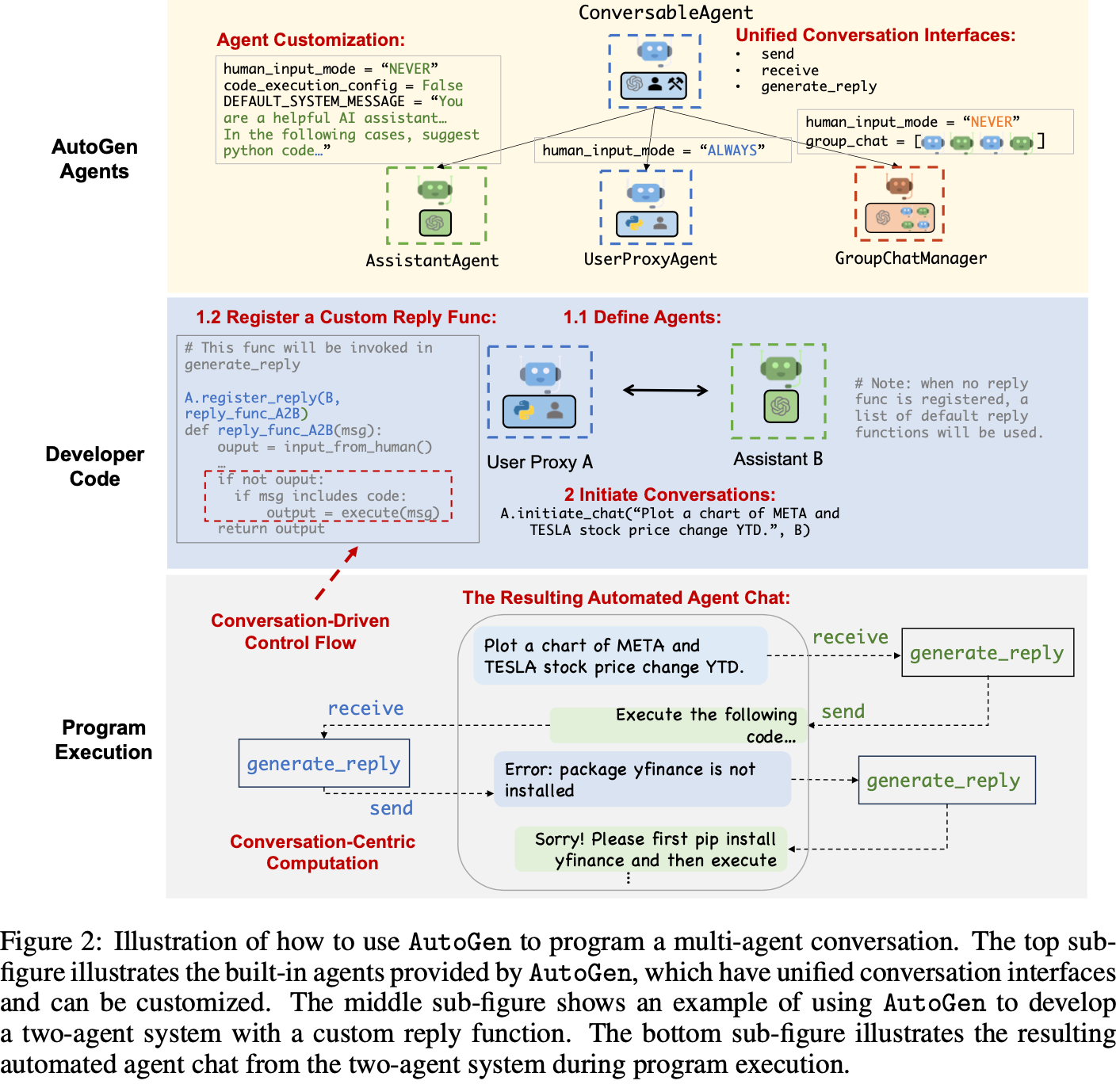
图里描述了一个UserProxyAgent和AssistantAgent交互,以完成代码开发的过程。其中GroupChatManager没有看到使用,看代码类似于一个超级大脑(人类)的感觉。
看到这里的时候,我就在想这个好像就是 CAMEL 要解决的问题😂。不过 AutoGen 也可以说,你可以只用AssistantAgent达到效果,现在 AI 论文也是混战,百花齐放百家争鸣的感觉,而且很卷,写篇论文还附带一个框架的。。。
论文地址:AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
2.2. 实践
使用如下代码,也可以起到“猜物品”游戏的效果。
#!/usr/bin/env python
# coding=utf-8
import os
# 导入autogen包
import autogen
from util import ARK_API_URL, DOUBAO_SEED_1_6
# !/usr/bin/env python
# coding=utf-8
import os
# 导入autogen包
import autogen
from util import ARK_API_URL, DOUBAO_SEED_1_6
#配置大模型
llm_config = {
"config_list": [
{
"model": DOUBAO_SEED_1_6,
"api_key": os.environ.get("ARK_API_KEY"),
"base_url": ARK_API_URL
}
],
}
# 设置目标词
target_word = "袋鼠"
responder = autogen.AssistantAgent(
name="回答者",
llm_config= llm_config,
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("恭喜你猜对了"),
system_message=f"""
你正在参与一个猜物品名字的游戏,注意物品名字可能细化到品牌、分类等。你的任务是根据对方提出的“是/不是”问题,以特定方式回应,帮助对方猜出目标物品。
目标词是: {target_word}
对方会通过问“是/不是”问题来尝试猜出这个词。你只能按照以下规则回答:
- 如果对方的问题是“是/不是”类型,你只能回答“是”或“不是”或“有”或“没有”。
- 如果对方说出的词就是目标词,你要回答:“恭喜你猜对了!”
- 如果对方说出的词是目标词的父类型,你需要回答:“是这个类型,但是词不对”
- 除此之外不能泄露任何信息。
"""
)
guesser = autogen.AssistantAgent(
name="猜词者",
llm_config=llm_config,
system_message="""
你正在玩一个猜物品名字的游戏,你不知道目标词是什么,需要通过提出‘是/不是’的问题来逐步缩小范围,直到猜中。
游戏规则如下:
- 每次只能提出一个‘是/不是’的问题。
- 如果你认为你知道答案,可以说“这个词是___”。
- 如果你猜对了,对方会说“恭喜你猜对了!”。
- 如果你说出了父类,对方会说“是这个类型,但是词不对”。
- 请你根据之前的提问和回答合理地提出下一个问题,直到你猜中或者你说“结束”。
"""
)
# 创建用户代理
# user_proxy = autogen.UserProxyAgent(
# name="用户代理",
# human_input_mode="ALWAYS",
# is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("结束"),
# code_execution_config={
# "last_n_messages": 1,
# "work_dir": "tasks",
# "use_docker": False,
# }
# )
if __name__ == '__main__':
# 发起对话
chat_results = autogen.initiate_chats(
[
{
"sender": guesser,
"recipient": responder,
"message": "请问这是一个生活用品吗?",
"carryover": "你需要根据过去问的问题及答案,询问一个新的问题,这个新的问题需要有助于你最终猜到物品。",
}
]
)
从代码也可以看到,可以很方便的切换到人类交互。
3. 总结
通过对 CAMEL 和 AutoGen 的原理分析与实践对比,我们可以看到两种框架在设计哲学上的差异:
- CAMEL:追求的是完全自主的智能体社会。它通过严格的角色扮演和指令设计,试图将人类从协作流程中解放出来,更适合执行定义明确、无需中途干预的任务。
- AutoGen:追求的是灵活的人机协作。它将人类视为系统中的一个特殊 Agent,允许随时介入,更适合探索性强、结果不确定、需要人类智慧兜底的复杂任务。
在实践过程中,我也发现了一些当前多智能体框架共同面临的挑战:
- 熵增风险:将多个尚不完全成熟的单智能体连接起来,系统的整体可靠性是提升了还是下降了?我相信会逐步有论文从理论上证明,彼时也就更能清晰的指出多智能体的发展方向
- 成本考量:多智能体协作通常意味着更多的 LLM 调用,这带来了 Token 消耗和响应时长的显著增加。论文大多只提到了效果提升,成本、时长却被忽略了。
- 上下文管理:随着对话轮次增加,携带全部历史记录会导致请求体急剧膨胀。如何有效地对上下文进行筛选或压缩,是决定系统能否扩展的关键。这里给我的感觉,就像是大数据处理时,衡量把计算放在客户端还是 HBase 的 CoProcessor 也就是服务端去做。
- 终止条件:无论是 CAMEL 还是 AutoGen,我们都必须设计一个最大迭代次数或明确的终止信号,以防止智能体陷入无限循环,这从侧面反映了当前技术方案的局限性。
这也是未来在架构上值得探索的,不只是追求能返回准确结果。