1. Mem0 是什么
mem0ai/mem01的官网介绍:
Mem0 (“mem-zero”) enhances AI assistants and agents with an intelligent memory layer, enabling personalized AI interactions. It remembers user preferences, adapts to individual needs, and continuously learns over time—ideal for customer support chatbots, AI assistants, and autonomous systems.
现在看,记忆层已是智能体的基础设施,而 Mem0 简言之,则是提供了一套框架,可以方便的将上下文更新为记忆,同时提出了响应延迟的明确指标。
了解 Mem0 的过程中,我发现其可以方便的对接各种接口的模型服务、向量存储。这一点或许以后是各种记忆框架、智能体脚手架等的标配。
2. Mem0 能干什么
Mem0 在源码里提供了两种记忆的使用方式2:
- OpenSource: Self-hosted, full control
- Platform: Managed, hassle-free
官网主推的自然是第二种,一适合我们理解记忆处理的过程,二功能更强大。
2.1. oss
我们使用 chroma 向量库,重点介绍 add search 两个接口是如何工作的。
2.1.1. Add Memory
代码里,由于写入 Vector 与 Graph 要提取的结构化数据不同,实际在 LLM 之前,流程就分为两道了。
class Memory:
def add(
...
):
...
with concurrent.futures.ThreadPoolExecutor() as executor:
future1 = executor.submit(self._add_to_vector_store, messages, processed_metadata, effective_filters, infer)
future2 = executor.submit(self._add_to_graph, messages, effective_filters)
concurrent.futures.wait([future1, future2])
messages 写入存储是在_add_to_vector_store,处理流程共四步:
- LLM 提取本次记忆:prompts3 + messages,返回
{ { "facts" : [] } }结构的数据。如果有自定义prompt,也是在该阶段生效。 - 相似记忆检索:根据本次提取出的记忆查询向量库,找到已经存在的相似记忆。
- LLM 决策记忆更新内容:prompts3 + 新记忆 + 旧的相似记忆,返回
{"memory": [{"id": , "text": , "event": }]}的数据结构,其中 event 有 ADD UPDATE DELETE NONE,对应后续不同的向量库操作 - 向量化及存储:调用 Embeddings 服务生成向量,执行向量库操作
说着复杂,其实就是简单的 HTTP 调用和向量库读写。
注意:
- 旧的相似记忆,源码里最多提取 5 个,可能会存在历史记忆未更新、删除的情况
- 效果强依赖 LLM 的指令遵从能力
- 用户 prompt 效果有限,格式、提取内容上还是以内置 prompt 为准,如果想要达到完全自定义的效果,需要修改内置 prompt
2.1.2. Search Memory
search 的比较简单,根据 query 生成 Embeddings,查询向量库里的相似数据返回。
2.1.3. 代码
测试代码如下,完整的代码我放到了github4上
def test_mem0_opensource():
mem_client = Memory.from_config(config)
user_id = 'user_' + str(random.randint(1, 999999999))
messages = [
{"role": "assistant", "content": "你好呀!能先告诉我你叫什么名字吗?"},
{"role": "user", "content": "我叫李明。今年30岁了。"},
{"role": "assistant", "content": "很高兴认识你,李明!看您资料是来自北京对吧?为了能更好地为您服务,想了解一下您的饮食偏好,比如您吃辣吗?"},
{"role": "user", "content": "是休闲旅游。我穿衣嘛,平时基本都穿黑色或灰色的衣服,比较喜欢简约休闲的风格,舒服最重要。"}
]
result = mem_client.add(messages, user_id=user_id)
print(f"1st result:\n {result}")
messages = [
{"role": "assistant", "content": "你好呀!能先告诉我你叫什么名字吗?"},
{"role": "user", "content": "我叫白给。今年31岁了。"},
]
result = mem_client.add(messages, user_id=user_id)
print(f"2nd result:\n {result}")
all_memories = mem_client.get_all(user_id=user_id)
print(f"all_memories for {user_id}:\n {all_memories}")
# results = mem_client.search("What do you know about me?", filters={"user_id": f"{user_id}"})
results = mem_client.search("What do you know about me?", user_id=f"{user_id}")
print(results)
第一次 add 的结果:
[
{ "id": "6cdb0d6f-897a-4072-b16c-857ae071dcc0", "memory": "名字叫李明", "event": "ADD" },
{ "id": "04fcb35a-8361-4f3e-8b0e-f06286435e73", "memory": "今年30岁", "event": "ADD" },
{ "id": "ff5107af-57b0-43d3-8813-cbfb92a95d06", "memory": "平时基本都穿黑色或灰色的衣服", "event": "ADD" },
{ "id": "35473a97-81e3-483c-9c17-8e74a6a5a217", "memory": "喜欢简约休闲的风格", "event": "ADD" },
{ "id": "8bc75701-9913-4a47-b9a3-c8cee969645b", "memory": "认为舒服最重要", "event": "ADD" }
]
第二次 add 的结果:
[
{
"id": "6cdb0d6f-897a-4072-b16c-857ae071dcc0", "memory": "名字叫白给", "event": "UPDATE", "previous_memory": "名字叫李明" },
{ "id": "04fcb35a-8361-4f3e-8b0e-f06286435e73", "memory": "今年31岁", "event": "UPDATE", "previous_memory": "今年30岁" }
]
即对记忆的新增、更新、删除,search结果就是查询向量库的返回,不再赘述。
实际应用里,则需要结合用户问题+LLM+记忆,给出用户更合适的回答。
因为记忆是基础设施,所以在接口设计上,add 支持了 user_id agent_id run_id 来支持上层应用。分别用于标记:
- user_id: 用户级别的所有记忆
- agent_id: 智能体记忆级别的所有记忆,例如不同的工作流、技能等等
- run_id: 单次运行的记忆,类似压缩后的本次会话的上下文内容
关于图搜索了解不多,从 Mem0 Paper6看
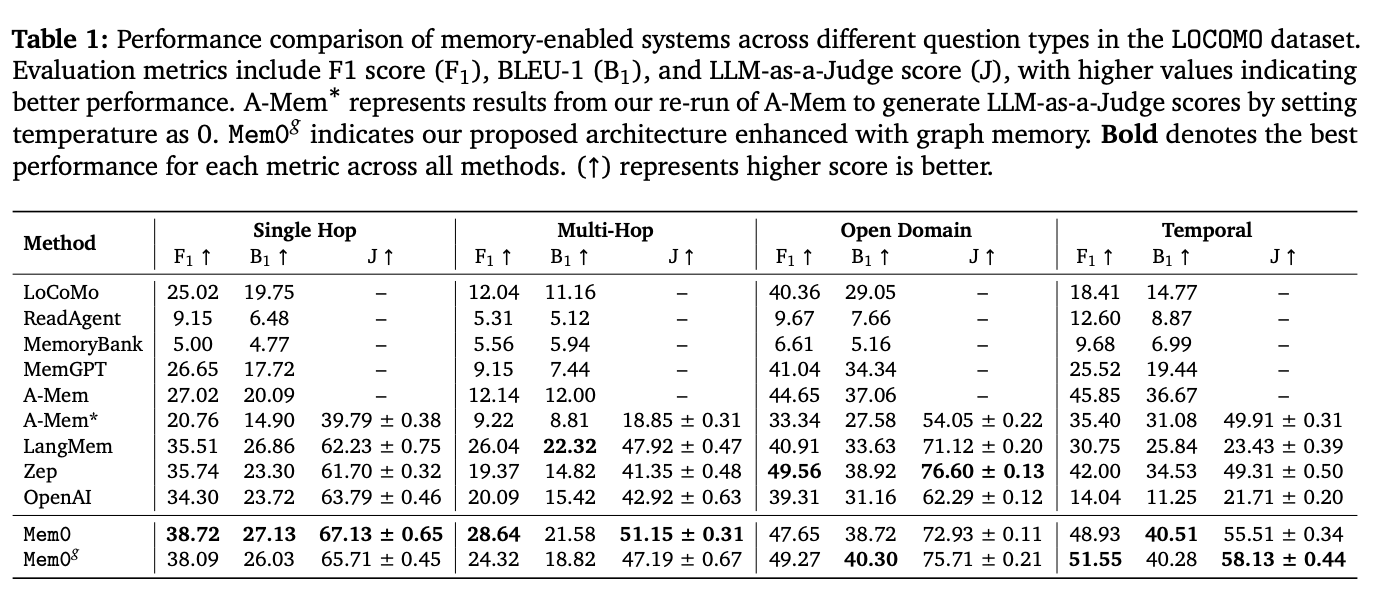
图搜确实能带来提高,但是 Graph Memory is not Always Better.
2.2. platform
使用 platform ,记忆的处理都是在平台侧服务完成的,本地class MemoryClient封装了 HTTP Client.
def test_mem0_platform():
from mem0 import MemoryClient
mem0_api_key = os.environ.get('MEM0_API_KEY')
print(f"mem0_api_key: {mem0_api_key}")
client = MemoryClient(api_key=mem0_api_key)
user_id = 'user_' + str(random.randint(1, 999999999))
print(f"user_id: {user_id}")
messages = [
{"role": "assistant", "content": "你好呀!能先告诉我你叫什么名字吗?"},
{"role": "user", "content": "我叫李明。今年30岁了。"},
{"role": "assistant", "content": "很高兴认识你,李明!看您资料是来自北京对吧?为了能更好地为您服务,想了解一下您的饮食偏好,比如您吃辣吗?"},
{"role": "user", "content": "是休闲旅游。我穿衣嘛,平时基本都穿黑色或灰色的衣服,比较喜欢简约休闲的风格,舒服最重要。"}
]
result = client.add(messages, user_id=user_id)
print(f"1st result:\n {result}")
input("Press Enter to continue...")
messages = [
{"role": "assistant", "content": "你好呀!能先告诉我你叫什么名字吗?"},
{"role": "user", "content": "我叫白给。今年31岁了。"},
]
result = client.add(messages, user_id=user_id)
print(f"2nd result:\n {result}")
input("Press Enter to continue...")
results = client.search("What do you know about me?", filters={"user_id": f"{user_id}"})
# results = client.search("What do you know about me?", user_id=f"{user_id}")
print(results)
例如第一次添加记忆后,返回:
1st result:
{'results': [{'message': 'Memory processing has been queued for background execution', 'status': 'PENDING', 'event_id': '75390ae1-8ecd-4791-9a97-e095efd25b05'}]}
查看平台上新插入的记忆:
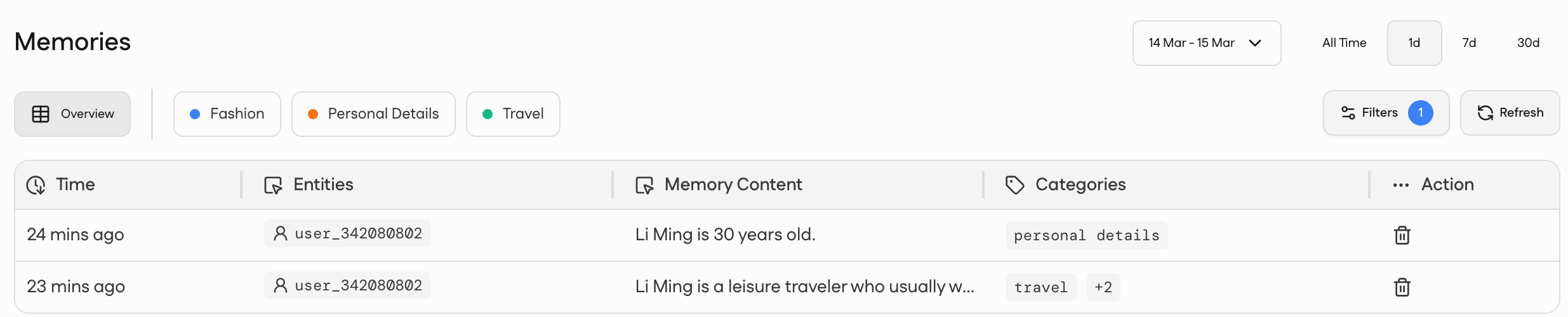
2nd result:
{'results': [{'message': 'Memory processing has been queued for background execution', 'status': 'PENDING', 'event_id': 'cb0eebc8-6f33-4089-8c39-2abfaa45b3e0'}]}
查看平台上更新的记忆:

search 返回的结果跟:
{'results': [{'id': '09852838-55ac-4603-90f1-1813942cf478', 'memory': '白给 is 31 years old.', 'user_id': 'user_342080802', 'metadata': None, 'categories': None, 'created_at': '2026-03-14T20:15:42-07:00', 'updated_at': '2026-03-14T20:15:42-07:00', 'expiration_date': None, 'score': 0.9, 'structured_attributes': {'year': 2026, 'month': 3, 'day': 15, 'hour': 3, 'minute': 15, 'day_of_week': 'sunday', 'week_of_year': 11, 'day_of_year': 74, 'quarter': 1, 'is_weekend': True}}]}
平台相比于开源,多了 Categories、筛选等能力。
完全依赖向量库,做筛选、排序还是比较费劲的,猜测平台版本可能用了向量库+关系数据库双写的方式。
Mem0 Platform 支持了 Conversation、Session、User、Organizational Memory , Organizational 是为了在多人间共享记忆所做的探索。
2.3. 火山云 Mem0
火山云上同样有一款基于 Mem0 的记忆产品5,是在去年12月推出的。我感觉主要区别是有记忆提取策略的概念,系统内置了 3 种,同时也支持用户自定义提取策略:
- 系统内置有:总结类记忆、语义类记忆、用户偏好类记忆
- 自定义:通过配置 prompt 的方式实现,效果上就是解决自定义提取的内容,比如我们可以定义日程提取的策略。
描述里都是 SummaryMemoryStrategy SemanticMemoryStrategy UserPreferenceMemoryStrategy ,可能是底层实现的类名?😅
使用方式和 Mem0 接口一样,我的测试代码4,在上一节测试例子的基础上,增加了一段日程描述(用于验证我自定义的 strategy)。
add 的接口返回:
{"results": [{"message": "the request was successful, and the memory will be completed asynchronously within 3 minutes. Please check the status later.", "status": "PENDING", "event_id": "17f2e7_RVOC20260315122630_mp-cnlffmeo78zs4c5rzqgpp6jurkpc"}]}
add 是异步的,返回提示记忆更新失效在 3 分钟。从使用情况看,记忆更新耗时都在几十秒左右,确实很慢。
第一次添加,可以看到有重复项,主要是不同的 strategy 导致的:
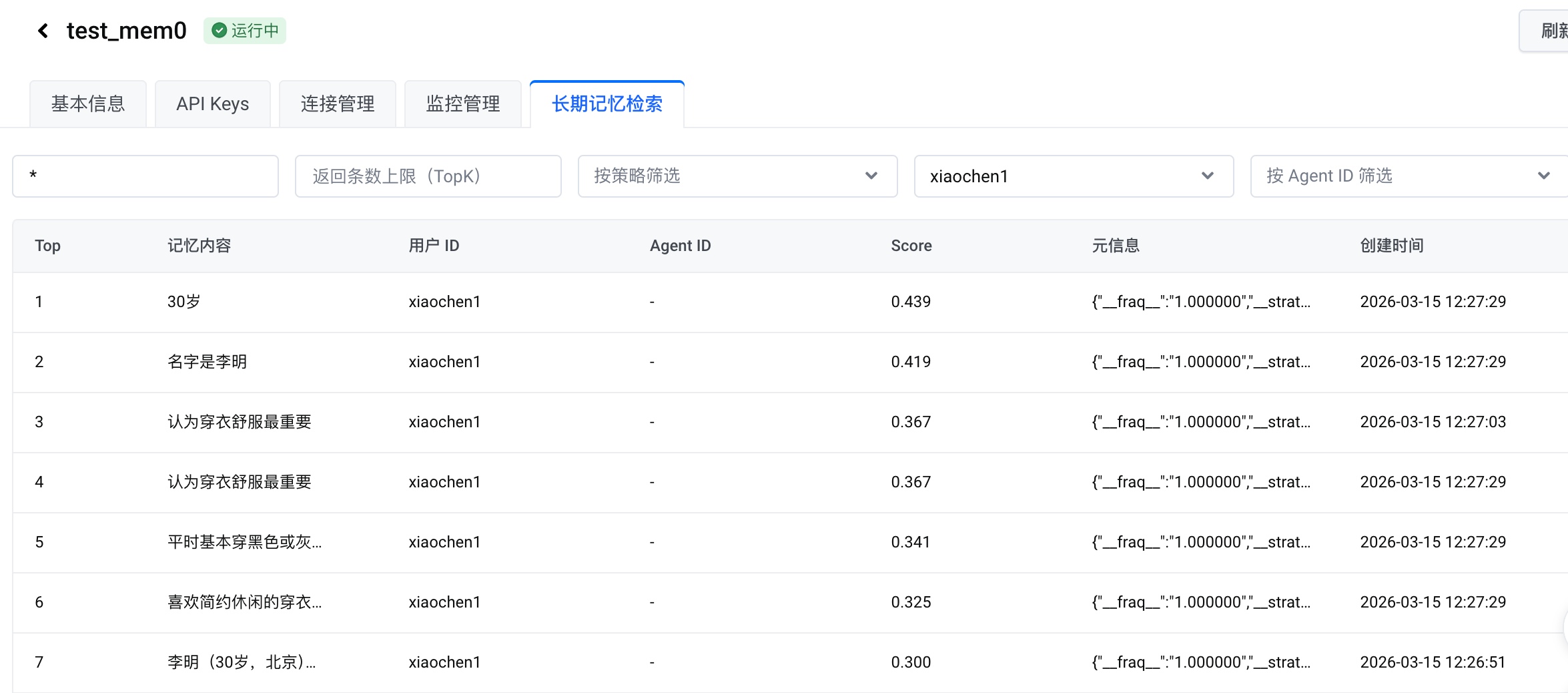
如果只按照用户偏好类记忆查看还可以,没有重复内容了:
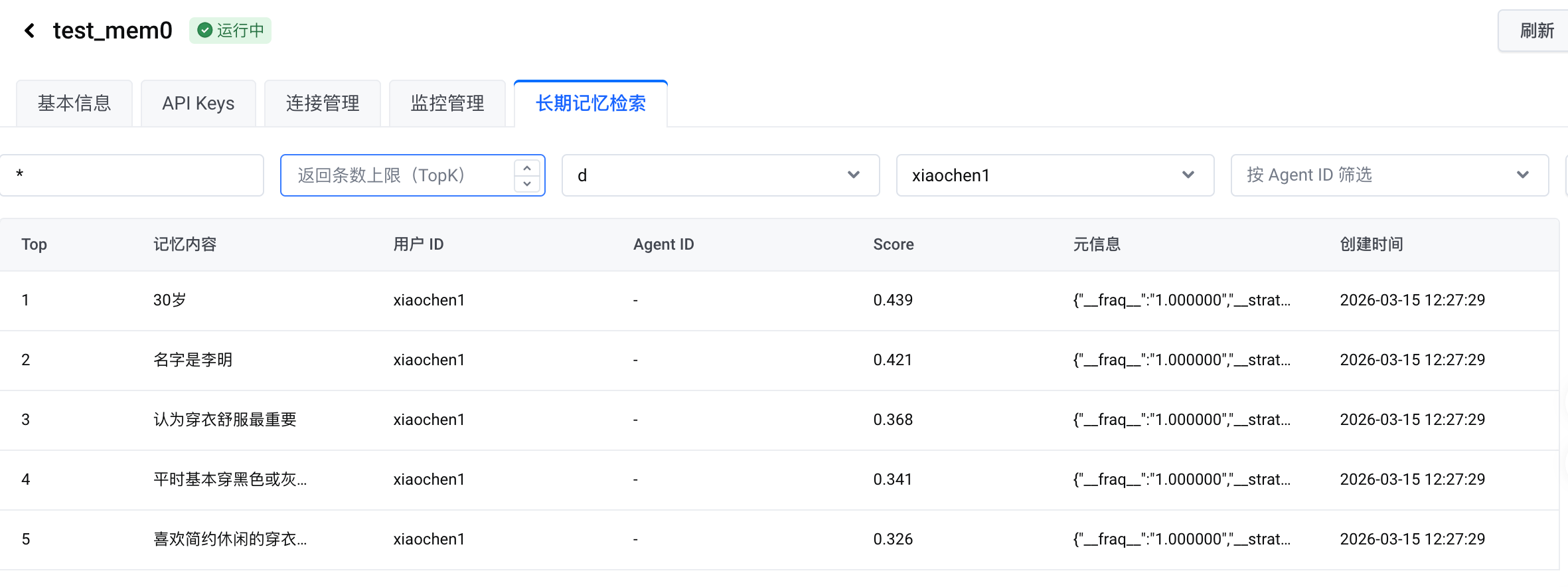
第二次添加,新的名字已经加入记忆。但是比较奇怪的是已经错误(名字是李明)的记忆居然没有删除:
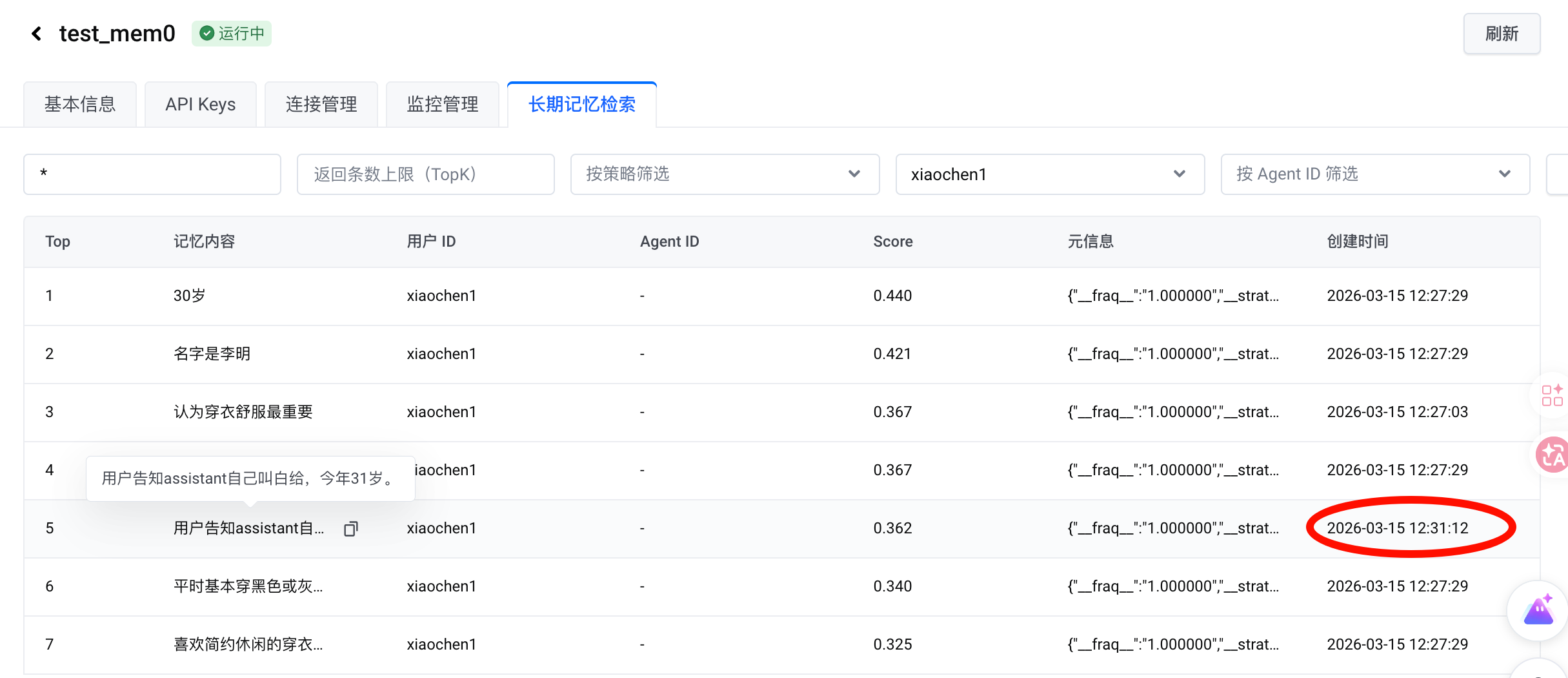
第三次添加,可以看到包括日程提取在内的 strategy 的都生效了:
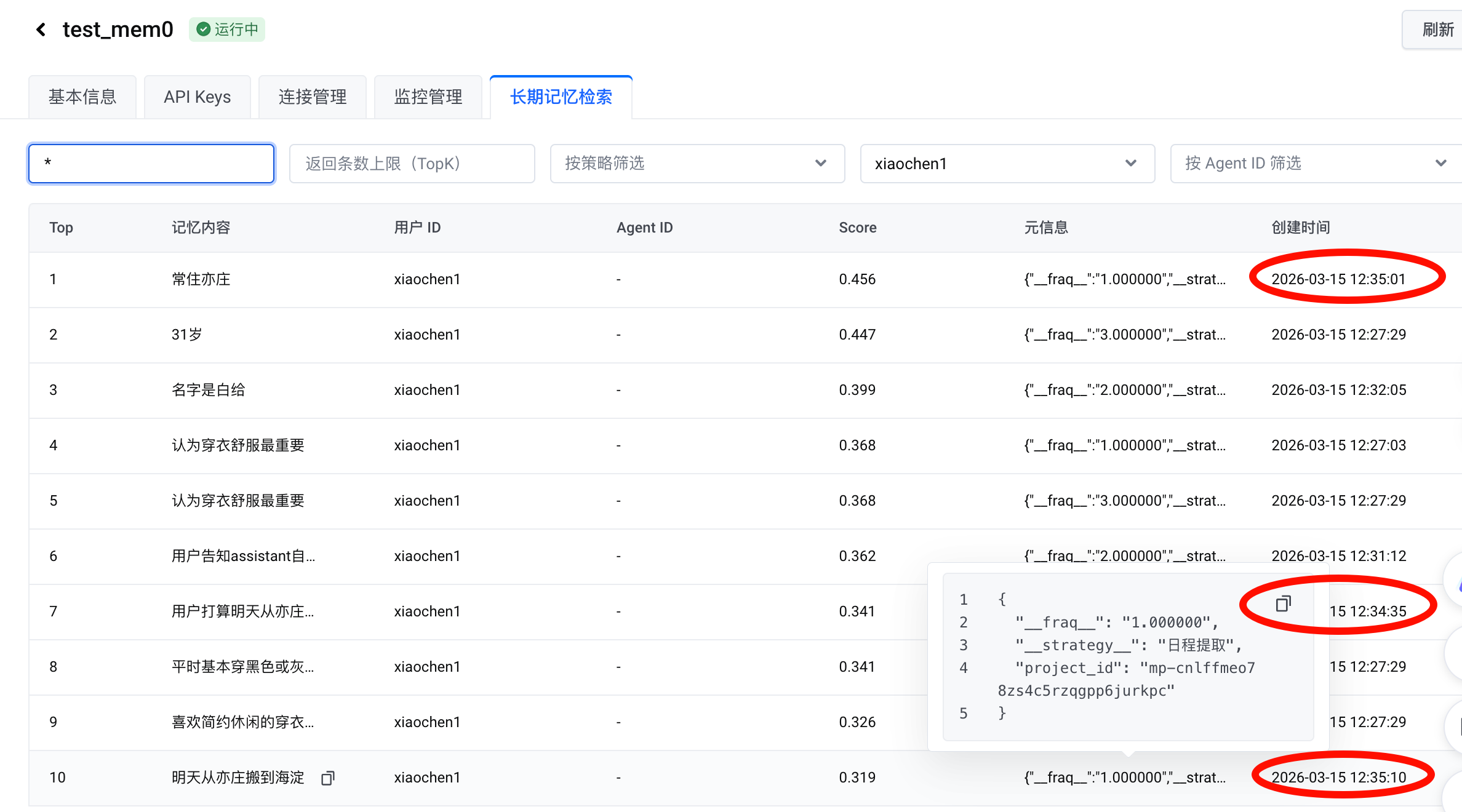
这款产品给我的印象,是核心优势是定位在支持用户自定义策略上,但是我用着效果一般,可能产品还是偏探索尝试阶段。
3. 我理解的记忆
现在看来,记忆已经是智能体的核心之一。但是整体还是偏供给侧,即作为基础设施提供出来,上层比如智能体按照需求规划如何使用。
但我觉得记忆应该更前一步,作为需求侧的核心设施存在,因为无论未来是单个智能体的多个会话、多个智能体之间,都会存在记忆共享的需求。我对于记忆的需求,是能够有办法沉淀下来,成为自己的 SKILL,然后在多个使用场景里按需加载。
比如我最近看算法,在思考二分、后缀数组等问题,而之前则对 LevelDB 里的 SkipList、BloomFilter 研究较多,就会希望将自己原来的理解加载到上下文里,再去咨询 LLM 关于后缀数组怎么优化的问题。这些 LevelDB 里关于算法的理解的记忆,能将其作为我定义的的 SKILL 加载到上下文. 这点是通用的 SKILL 无法满足的。
因此,一款真正好用的记忆产品,其核心特性应该包括记忆的整理和筛选能力。整理是离线的,不断的分类、汇总;筛选是用户自发的,将某些记忆沉淀,后续使用时可以分类加载。
对应到产品和技术上,大致应该包含:直观的 Dashboard、手动与自动管理记忆、筛选能力、一句话总结、能够按需被需求侧加载等等。
对比上述几款产品:
| 特性 | Mem0 开源版 (OSS) | Mem0 官方平台 (Platform) | 火山云 Mem0 产品 |
|---|---|---|---|
| 部署与维护 | 完全私有化部署,需自行维护向量库、LLM 等基础设施,控制力强。 | SaaS 服务,开箱即用,无需关心底层维护,省心省力。 | SaaS 服务,深度整合火山云基础设施,免维护。 |
| 核心功能 | 提供基础的记忆增删改查,支持简单的 ID 过滤,适合学习和基础研究。 | 功能丰富,提供 Dashboard、记忆分类、高级筛选、结构化属性等,适合生产环境。 | 引入“提取策略”,内置多种策略并支持自定义,但可能导致记忆重复。 |
| 定制化能力 | 最高。可直接修改源码和内置 prompt,但技术门槛和维护成本高。 | 有限。通过平台提供的接口和配置进行,无法深入底层。 | 核心是策略定制。通过 prompt 实现灵活的信息提取,但其他方面定制性未知。 |
| 易用性 | 较低。需要开发者具备较高的技术能力来搭建和整合。 | 高。提供封装好的 Client 和管理后台,对开发者友好。 | 中等。接口与 Mem0 类似,但策略概念增加了理解成本,且异步更新慢。 |
| 成熟度与稳定性 | 依赖于自身搭建,但核心逻辑相对简单透明。 | 较高。作为官方主推的商业产品,功能和稳定性有保障。 | 较低。从试用体验看,存在更新慢、数据不一致等问题,产品尚在探索阶段。 |
| 成本 | 开源免费,但有人力和基础设施的隐性成本。 | 付费服务,按用量或订阅计费(推测)。 | 商业化产品,公测免费。 |
一句话总结的话:
- Mem0 开源版:基本能用,但是实际场景会严重不足,需要针对生产环境、易用功能做较多开发
- Mem0 官方平台:比较成熟,现有场景似乎基本够用,但是英文版、自定义 prompt 等较弱
- 火山云 Mem0:一个有趣的“探索”,但从目前的产品形态看,还不成熟,更适合作为技术尝鲜