
1 Chapter7: Stateful Operators And Applications
1.1 Implementing Stateful Functions
Keyed State:
ValueState[T]: single value. The value can be read usingValueState.value()and updated withValueState.update(value: T)ListState[T]: list of elements. 常用接口有add addAll get updateMapState[K, V]: map of keys and values.get put contains removeReducingState[T]: 类似ListState, 但是不存储全部 list,而是 immediately aggregates value using aReduceFunctionAggregatingState[I, O]: 类似 reduce 和 aggregate 的关系,更加通用化
val sensorData: DataStream[SensorReading] = ???
// partition and key the stream on the sensor ID
val keyedData: KeyedStream[SensorReading, String] = sensorData
.keyBy(_.id)
// apply a stateful FlatMapFunction on the keyed stream which
// compares the temperature readings and raises alerts
val alerts: DataStream[(String, Double, Double)] = keyedData
.flatMap(new TemperatureAlertFunction(1.7))
class TemperatureAlertFunction(val threshold: Double)
extends RichFlatMapFunction[SensorReading, (String, Double, Double)] {
// the state handle object
private var lastTempState: ValueState[Double] = _
override def open(parameters: Configuration): Unit = {
// create state descriptor
val lastTempDescriptor =
new ValueStateDescriptor[Double]("lastTemp", classOf[Double])
// obtain the state handle
lastTempState = getRuntimeContext.getState[Double](lastTempDescriptor)
}
override def flatMap(
reading: SensorReading,
out: Collector[(String, Double, Double)]): Unit = {
// fetch the last temperature from state
val lastTemp = lastTempState.value()
// check if we need to emit an alert
val tempDiff = (reading.temperature - lastTemp).abs
if (tempDiff > threshold) {
// temperature changed by more than the threshold
out.collect((reading.id, reading.temperature, tempDiff))
}
// update lastTemp state
this.lastTempState.update(reading.temperature)
}
}
- State 存储时使用 Flink 的TypeInformation(序列化、反序列化)
- StateDescriptor 是函数从 StateBackend 获取/注册 State 的描述符
Operator List State: 可以继承
public interface ListCheckpointed<T extends Serializable> {
List<T> snapshotState(long checkpointId, long timestamp) throws Exception;
void restoreState(List<T> state) throws Exception;
}
注意:该接口已经标记 @Deprecated, 建议使用 CheckpointedFunction
Broadcast State: 典型的场景是:a stream of rules and a stream of events on which the rules are applied, 即 事件流 和 规则流。
val sensorData: DataStream[SensorReading] = ???
val thresholds: DataStream[ThresholdUpdate] = ???
val keyedSensorData: KeyedStream[SensorReading, String] = sensorData.keyBy(_.id)
// the descriptor of the broadcast state
val broadcastStateDescriptor =
new MapStateDescriptor[String, Double](
"thresholds", classOf[String], classOf[Double])
val broadcastThresholds: BroadcastStream[ThresholdUpdate] = thresholds
.broadcast(broadcastStateDescriptor)
// connect keyed sensor stream and broadcasted rules stream
val alerts: DataStream[(String, Double, Double)] = keyedSensorData
.connect(broadcastThresholds)
.process(new UpdatableTemperatureAlertFunction())
注意 Broadcast events 可能乱序。
CheckpointedFunction, CheckpointListener跟 checkpoint 紧密相关,前者在触发 checkpoint 时调用,可以定义各类 State,例如ValueState ListState等,后者则注册了 checkpoint 完成时的回调。
1.2 Enabling Failure Recovery for Stateful Applications
1.3 Ensuring the Maintainability of Stateful Applications
任务会经常变动:Bugs need to be fixed, functionality adjusted, added, or removed, or the parallelism of the operator needs to be adjusted to account for higher or lower data rates.
为了确保任务的可维护性,关于 state 有两点需要注意:
- Specifying Unique Operator Identifiers : 最好从程序开始就为每个 operator 指定
- Defining the Maximum Parallelism of Keyed State Operators:
setMaxParallelism在这里更确切的作用是setCountOfKeyGroups1.4 Performance and Robustness of Stateful Applications
- StateBackend: MemoryStateBackend, the FsStateBackend, and the RocksDBStateBackend.
- 使用 RocksDBStateBackend 时,不同 State 类型性能差别较大。比如
MapState[X, Y]比ValueState[HashMap[X, Y]]性能更高,ListState[X]比ValueState[List[X]]更适合频繁追加数据的场景。 - 滥用 state 会导致 state 过大的问题,比如 KeyedStream.aggregate 而 key 无限制,典型的比如统计用户行为时的 sessionId. 使用 timer 清理 state,确保 state 不会引发问题。例如:
class SelfCleaningTemperatureAlertFunction(val threshold: Double)
extends KeyedProcessFunction[String, SensorReading, (String, Double, Double)] {
// the keyed state handle for the last temperature
private var lastTempState: ValueState[Double] = _
// the keyed state handle for the last registered timer
private var lastTimerState: ValueState[Long] = _
override def open(parameters: Configuration): Unit = {
// register state for last temperature
val lastTempDesc = new ValueStateDescriptor[Double]("lastTemp", classOf[Double])
lastTempState = getRuntimeContext.getState[Double](lastTempDescriptor)
// register state for last timer
val lastTimerDesc = new ValueStateDescriptor[Long]("lastTimer", classOf[Long])
lastTimerState = getRuntimeContext.getState(timestampDescriptor)
}
override def processElement(
reading: SensorReading,
ctx: KeyedProcessFunction
[String, SensorReading, (String, Double, Double)]#Context,
out: Collector[(String, Double, Double)]): Unit = {
// compute timestamp of new clean up timer as record timestamp + one hour
val newTimer = ctx.timestamp() + (3600 * 1000)
// get timestamp of current timer
val curTimer = lastTimerState.value()
// delete previous timer and register new timer
ctx.timerService().deleteEventTimeTimer(curTimer)
ctx.timerService().registerEventTimeTimer(newTimer)
// update timer timestamp state
lastTimerState.update(newTimer)
// fetch the last temperature from state
val lastTemp = lastTempState.value()
// check if we need to emit an alert
val tempDiff = (reading.temperature - lastTemp).abs
if (tempDiff > threshold) {
// temperature increased by more than the threshold
out.collect((reading.id, reading.temperature, tempDiff))
}
// update lastTemp state
this.lastTempState.update(reading.temperature)
}
override def onTimer(
timestamp: Long,
ctx: KeyedProcessFunction
[String, SensorReading, (String, Double, Double)]#OnTimerContext,
out: Collector[(String, Double, Double)]): Unit = {
// clear all state for the key
lastTempState.clear()
lastTimerState.clear()
}
}
1.5 Evolving Stateful Applications
- Updating an Application without Modifying Existing State: compatible
- Changing the Input Data Type of Built-in Stateful Operators: not compatible
- Removing State from an Application: 默认 avoid losing state,可以关闭
- Modifying the State of an Operator: 比如
ValueState[String]修改为ValueState[Double],兼容不全,尽量避免。
1.6 Queryable State
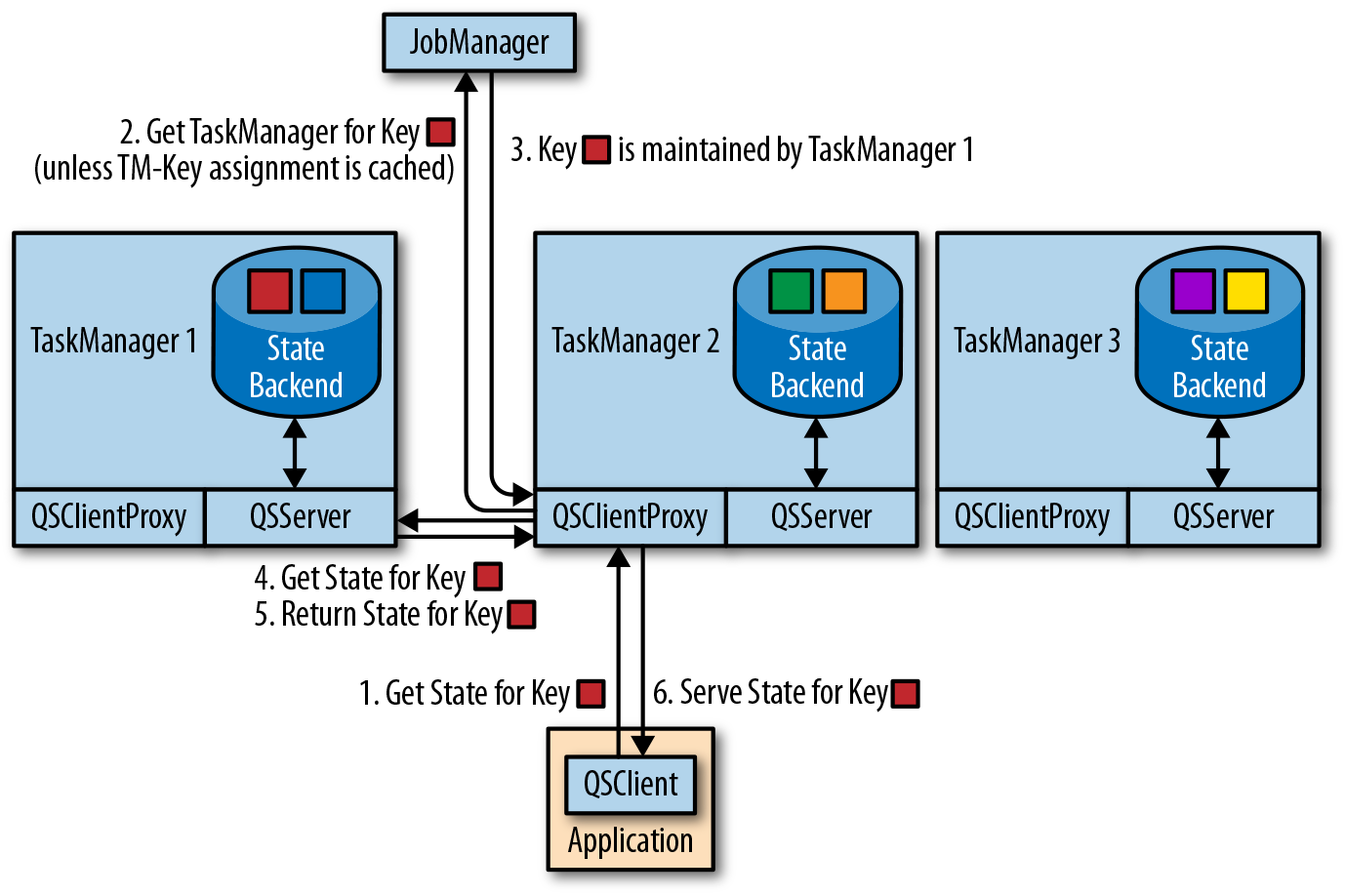 支持 state 的点查和读取,依赖 flink-queryable-state-client-java.
注:之前调研 flink 时,这个功能看上去非常强大,不过目前在官网已经看不到相关文档了。
支持 state 的点查和读取,依赖 flink-queryable-state-client-java.
注:之前调研 flink 时,这个功能看上去非常强大,不过目前在官网已经看不到相关文档了。
2 Chapter8: Reading From and Write to External Systems
2.1 Application Consistency Guarantees
如果想不丢数据,source 需要是 resettable 的,例如读文件时 File ByteStream 的 offset,读 kafka 时 TopicPartition 的 offset. 但是如果想要 end-to-end exactly-once, sink connectors 还需要支持 idempotent writes or transactional writes. 后者比如 write-ahead-log (WAL) sink , two-phase-commit (2PC) sink.
| Nonresettable source | Resettable source | |
|---|---|---|
| Any Sink | At-most-once | At-least-once |
| Idempotent sink | At-most-once | Exactly-once* (temporary inconsistencies during recovery) |
| WAL sink | At-most-once | At-least-once |
| 2PC sink | At-most-once | Exactly-once |
注意 WAL sink 即使仅在 checkpoint complete 完成的时候 sink,也无法作答 Exactly-once.s
2.2 Provided Connectors
Kafka, Filesystem, etc. 官网比书里已经更详细了。
2.3 Implementing a Custom Source Function
- SourceFunction and RichSourceFunction can be used to define nonparallel source connectors—sources that run with a single task.
- ParallelSourceFunction and RichParallelSourceFunction can be used to define source connectors that run with multiple parallel task instances. 注:接口后来有变化
当 checkpoint 进行的时候,需要记录此时的 offset, 就需要避免SourceFunction.run()emit data.
换句话说CheckpointedFunction.snapshotState和该方法,只能同时在执行一个。
需要注意 sourceFunction 某个 parallelism idle 时不会发出 watermark,可能导致整个任务在等待的情形。
2.4 Implementing a Custom Sink Function
- Idempotent Sink Connectors: 要求结果数据有 deterministic (composite) key,存储支持
- Transactional Sink Connectors:
GenericWriteAheadSink: 先写 WAL,收到 CheckpointCompleted 时写入到存储。听上去似乎很完美,但是实际上只能做到 At-least-once,有两种情况:存储的批量写入不是原子的;存储写入成功,但是 commit checkpoint 时失败。TwoPhaseCommitSinkFunction- sink operator 收到 checkpoint barrier:persists its state, prepares the current transaction for committing, and acknowledges the checkpoint at the JobManager.
- JobManager 收到所有 task instances 的 successful checkpoint notifications
- sink operator 收到 checkpoint completed 消息:commits all open transactions of previous checkpoints.
- 我理解 commit 确保了持久化, 如果 commit 失败的话,preCommit 的操作会被回滚,确保不会对 storage system 产生影响,因而保证了 Exactly-once 语义。书里有一个
TransactionalFileSink的例子,很直观。当然支持该语义带来的问题也需要注意,一是 checkpoint 完成后数据才可见;二是对 kafka transaction timeout 调优,避免一直 commit 失败导致可能的数据丢失。
2.5 Asynchronously Accessing External Systems
异步查询词典的场景
3 Chapter9: Setting Up Flink for Streaming Applications
3.1 Deployment Modes
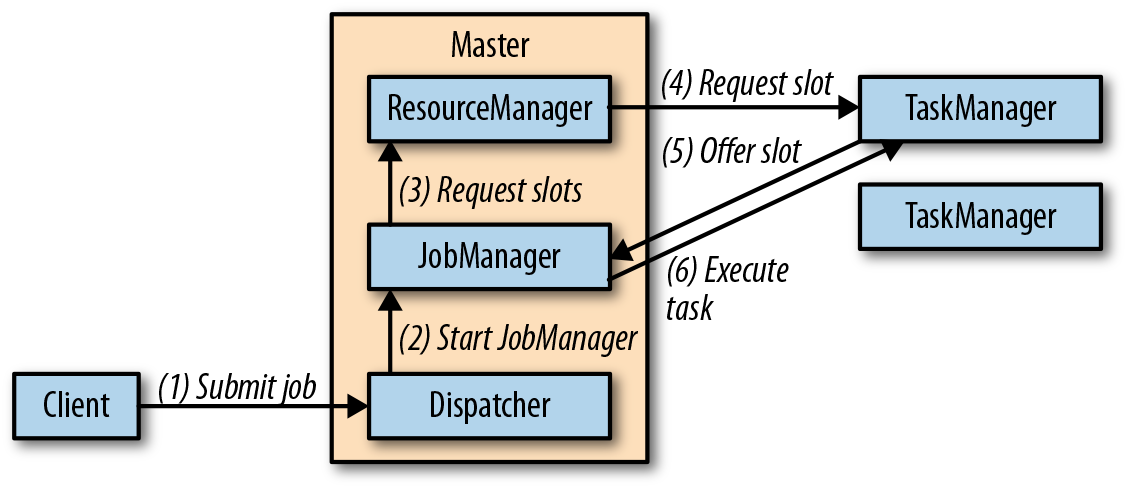
- Standalone Cluster:
- 启动:
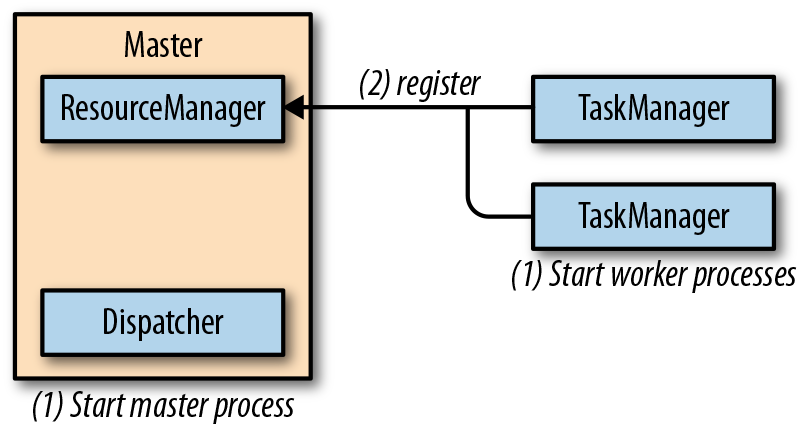
- 提交:
- 启动:
- Docker
- YARN:
- JobMode:
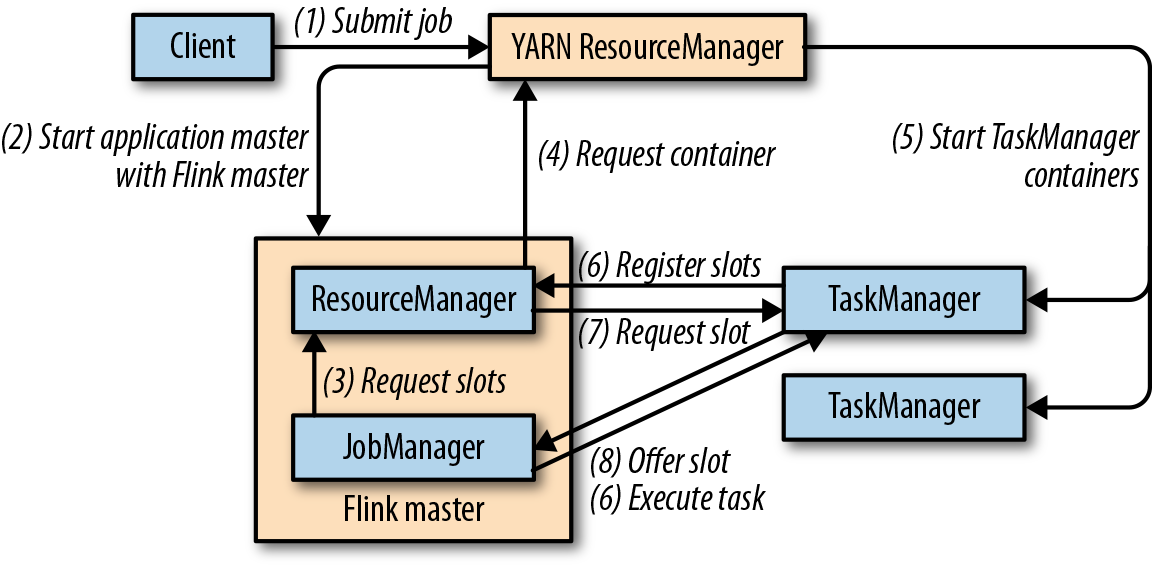
- SessionMode:
- 启动:
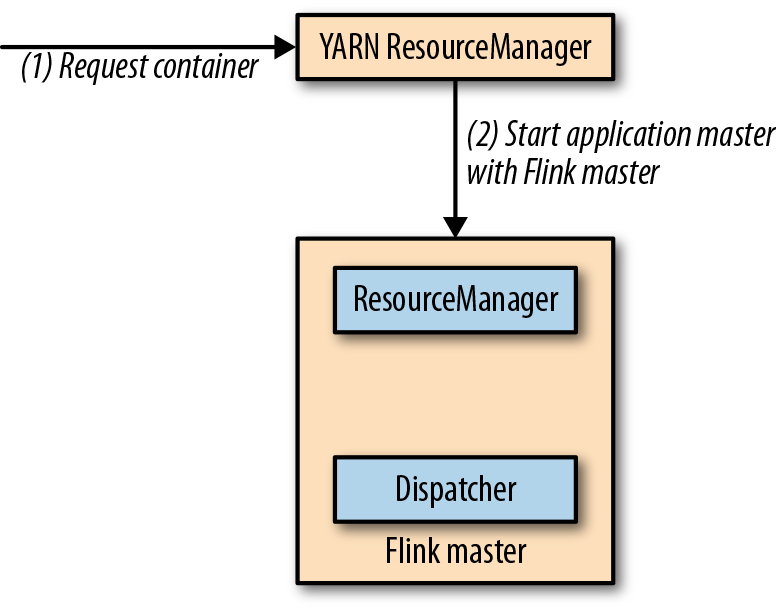
- 提交:
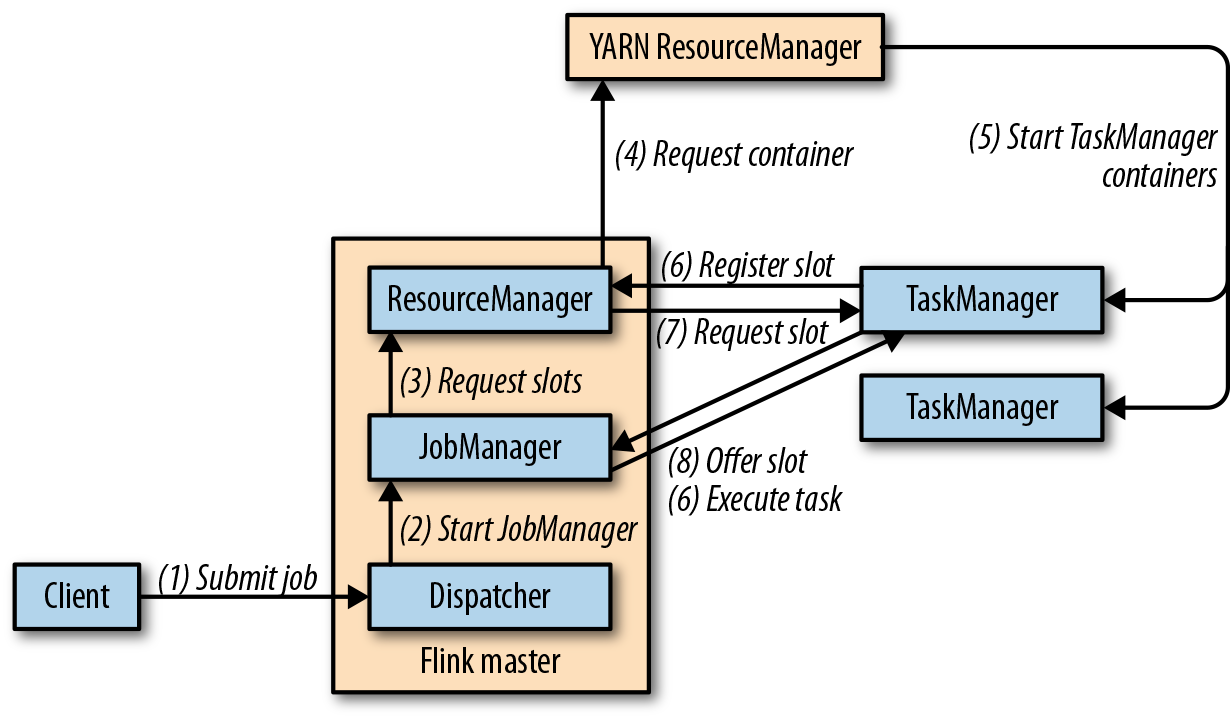
- 启动:
- 注:ApplicationMode
- JobMode:
- Kubernetes: 生产环境的目标状态应当还是容器化部署
3.2 Highly Available Setups
HA 的目的是 as little downtime as possible. TaskManager 失败可以由 ResourceManager 恢复,JobManager 失败则依赖于 HA 部署。 HA 需要考虑的存储有:JAR file, the JobGraph, and pointers to completed checkpoints.
书里介绍了 ZooKeeper HA Services,当前还有 Kubernetes HA Services. 实践经验里看还是有些坑的,尤其是 Yarn 相关参数。
3.3 Integration with Hadoop Components
3.4 Filesystem Configuration
3.5 System Configuration
- Java and Classloading: Flink 提供了 User-code class loaders, 注意 classloader.resolve-order 相关的配置。
- CPU: task 在 TaskManager 的线程运行,以 slot 的方式对外提供。
- Main Memory and Network Buffers: JM TM 内存重点不同,额外注意 network buffer 和 rocksdb backend.
- Disk Storage
- Checkpointing and State Backends
- Security
4 Chapter10: Operating Flink and Streaming Applications
4.1 Running and Managing Streaming Applications
这节提到了“maintaining streaming applications is more challenging than maintaining batch applications”,我个人觉得对于 streaming applications,maintaining 比 develop 更具挑战性。maintaining = start, stop, pause and resume, scale, and upgrade.
操作 flink 任务可以使用 CLI 或者 REST API. savepoint 相关功能最好通过uid()定义 Unique Operator IDs.
Kubernetes 相关的内容已经过时,建议直接参考文档。
4.2 Controlling Task Scheduling
Task Chaining 可以将网络通信转为线程内方法的直接调用,因此 Flink 默认开启,如有必要可以通过disableChaining, startNewChain调优。
Slot-Sharing Groups 允许用户自己协调计算密集和 IO 密集的 task:
// slot-sharing group "green"
val a: DataStream[A] = env.createInput(...)
.slotSharingGroup("green")
.setParallelism(4)
val b: DataStream[B] = a.map(...)
// slot-sharing group "green" is inherited from a
.setParallelism(4)
// slot-sharing group "yellow"
val c: DataStream[C] = env.createInput(...)
.slotSharingGroup("yellow")
.setParallelism(2)
// slot-sharing group "blue"
val d: DataStream[D] = b.connect(c.broadcast(...)).process(...)
.slotSharingGroup("blue")
.setParallelism(4)
val e = d.addSink()
// slot-sharing group "blue" is inherited from d
.setParallelism(2)
如上代码,不同 task 分配的效果: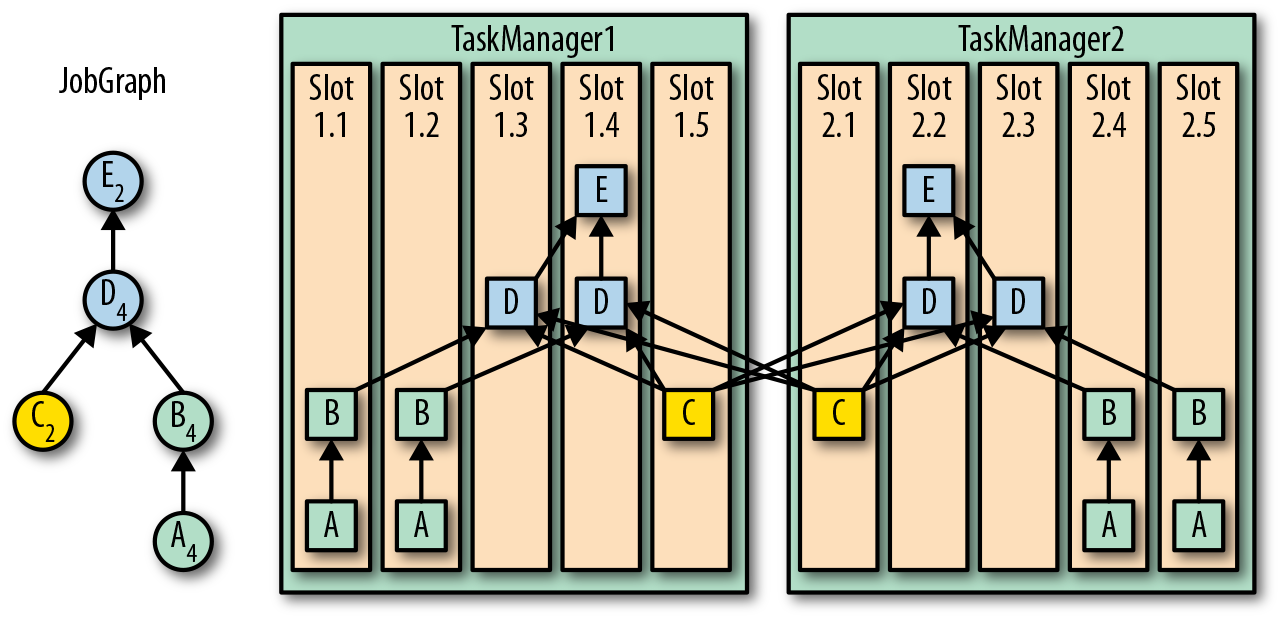
4.3 Tuning Checkpointing and Recovery
重要配置:
- 间隔、minPause、超时时间、
- 程序退出时是否删除
- 选择合适的 backend
- Restart strategies
4.4 Monitoring Flink Clusters and Applications
Flink WebUI 可以用来初步分析任务:日志、metrics 等。如果要深入分析,则依赖 metrics systems.
4.5 Configuring the Logging Behavior
5 Chapter11: Where to Go from Here?
批处理、TableAPI、SQL、CEP 等