
1 Chapter1: Introduction to Stateful Stream Processing
2 Chapter2: Stream Processing Fundamentals
介绍了 Parallel、Time、State 等概念
- Processing Streams in Parallel
- Latency and Throughput: 延迟、吞吐的关系
- Operations on DataStreams: 输入输出、算子、聚合、窗口
- Time Semantics: processing time 适合对数据延迟、乱序不敏感的场景;event time 适合对结果要求准确且唯一的场景,引入了 watermark 避免一直等待。
- State And Consitency Models: 批的 failover 可以依赖回放数据,但是流不可以;真实世界使用最多的是 At-least-once,如何保证?一个方案是确保保存数据,直到所有 task 都返回了 ACK
3 Chapter3: The Architecture of Apache Flink
3.1 System Architecture
Components of a Flink Setup: 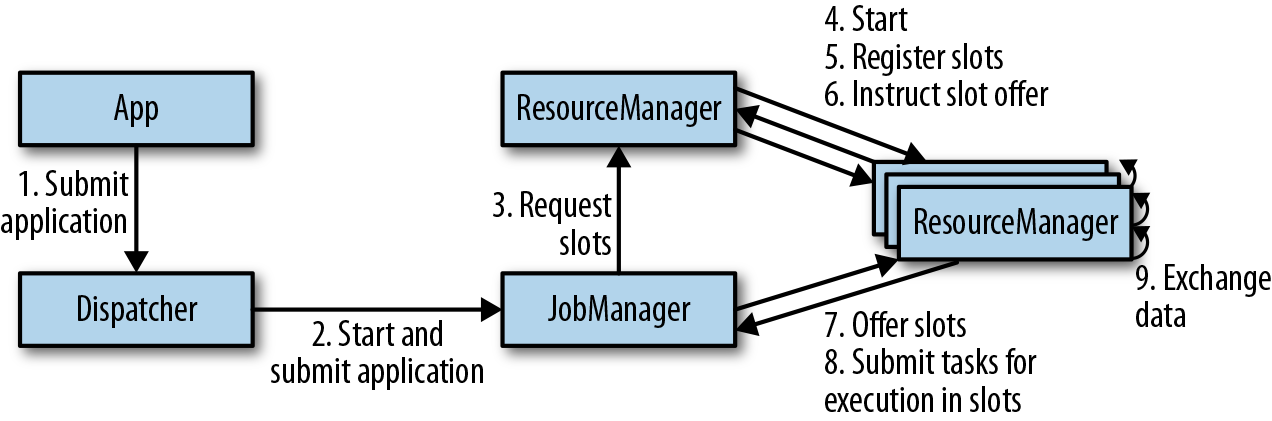
JobManager(生成和分配ExecutionGraph、任务协调);ResourceManager(跟 resource provider 交互,申请和回收 taskmanager 资源); TaskManager(实际的 worker process);Dispatcher(Rest). 根据环境不同,有的 components 可能跑在一个 JVM Process 上。注意跟现在的已经不一样了
Task Execution: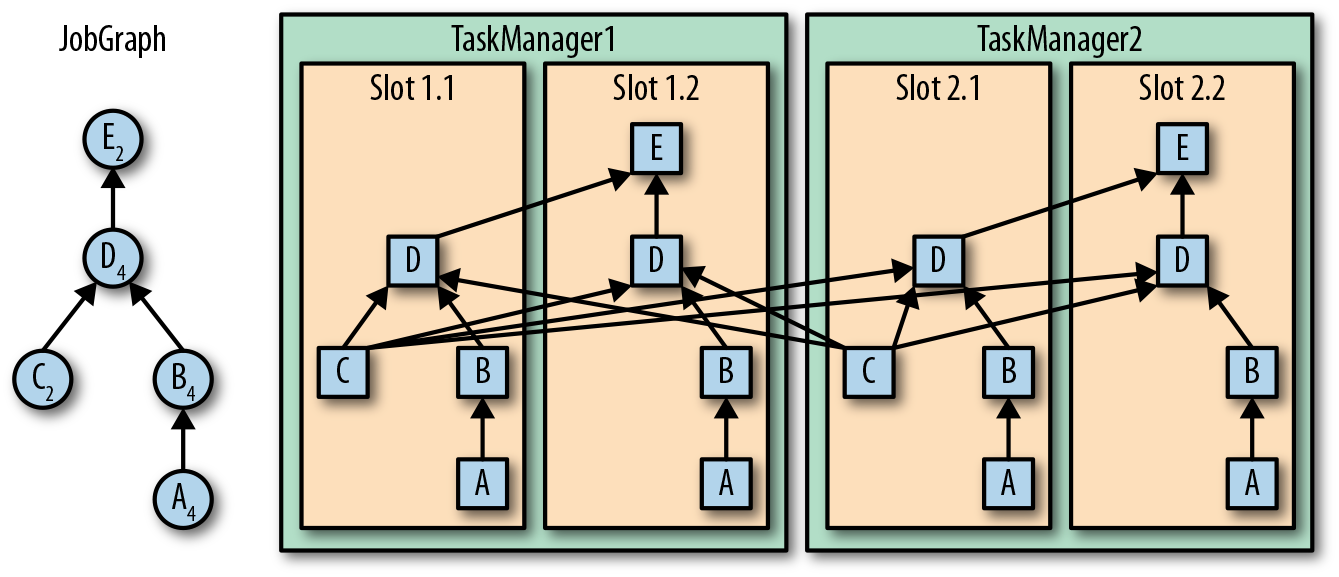
taskmanager 多个 slot,上下游 operator 的 parallelism 不同时,就会发生数据的 exchange.
High Available Setup:
- TaskManager failures: JobManager 跟 ResourceManager 申请新的 slot
- JobManager failures: 数据持久化到 storage,pointer 存储到 zk,新的 JM 通过 zk 上的 latest complete checkpoint 恢复任务
3.2 Data Transfer In Flink
Task Chaining:
用户定义 : 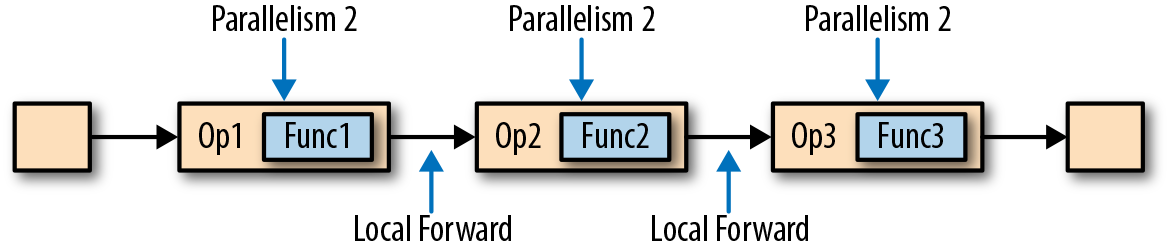
chain 为函数间的调用关系 : 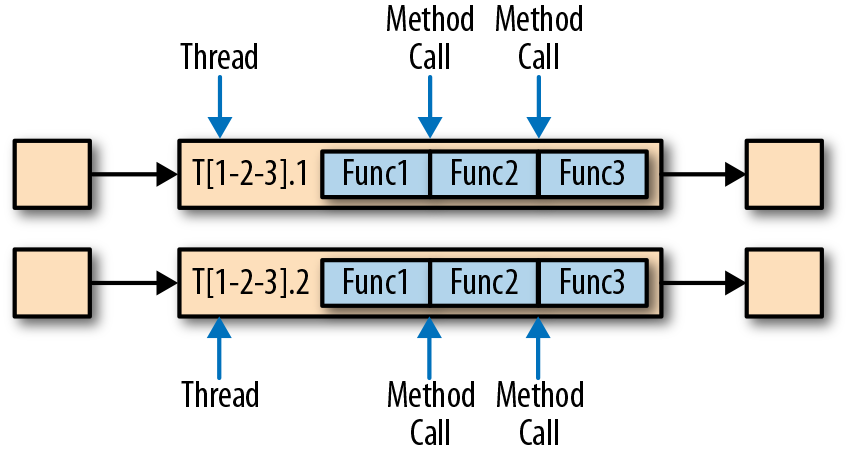
有时也会希望在多个线程间执行 : 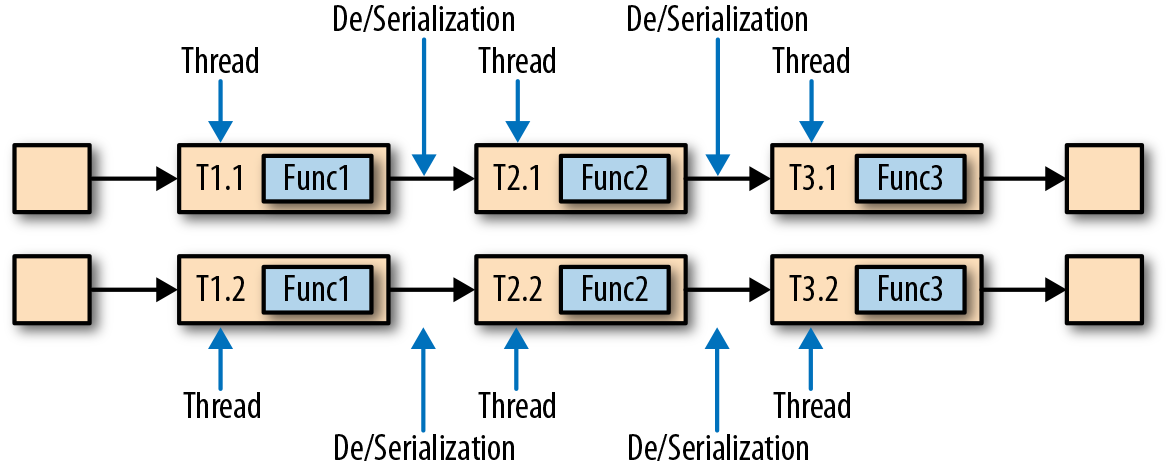
t1=0.1s t2=0.8s t3=0.2s,1 个线程 1qps,因此 10 个线程 10qps;也可以 f1 1 个线程,f2 8个,f3 1个(不过我没想清楚区别在哪)
3.3 Event-Time Processing
相比 Processing-Time 的流系统,实现上更加复杂
- Timestamps: 事件的元数据
- Watermarks: 如果收到了 T 时间戳的 watermark,则表示 T 之前的数据都已经到达。后续如果有违反该约定的数据,成为 Late Record.在 Handling Late Data 一节分析。合适的 watermark 是在 latency 和 completeness tradeoff.
- Watermark Propagation and Event Time: 多流的场景,不同流的 watermark 有快有慢,更加复杂
- Timestamp Assignment and Watermark Genearation: timestamp、watermark 显示设置,有三种方式: Source Function、AssignerWithPeriodicWatermarks、AssignerWithPunctuatedWatermarks,从 record 提取 timestamp,同时结合配置计算当前的 watermark. 后两者有对应的子类实现。
3.4 State Management:
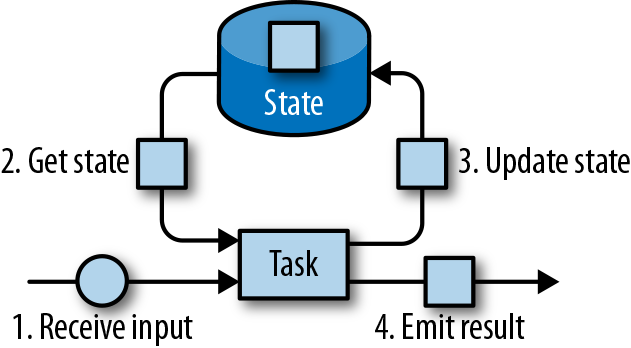
- Operator State:
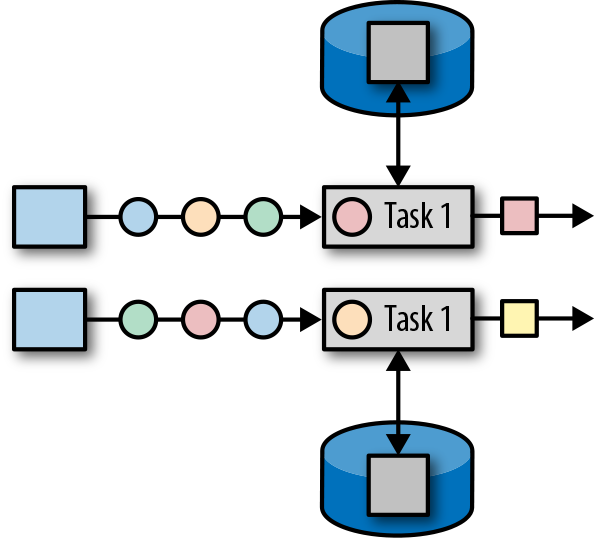 ,有 ListState、UnionListState、BroadcastState
,有 ListState、UnionListState、BroadcastState - Keyed State:
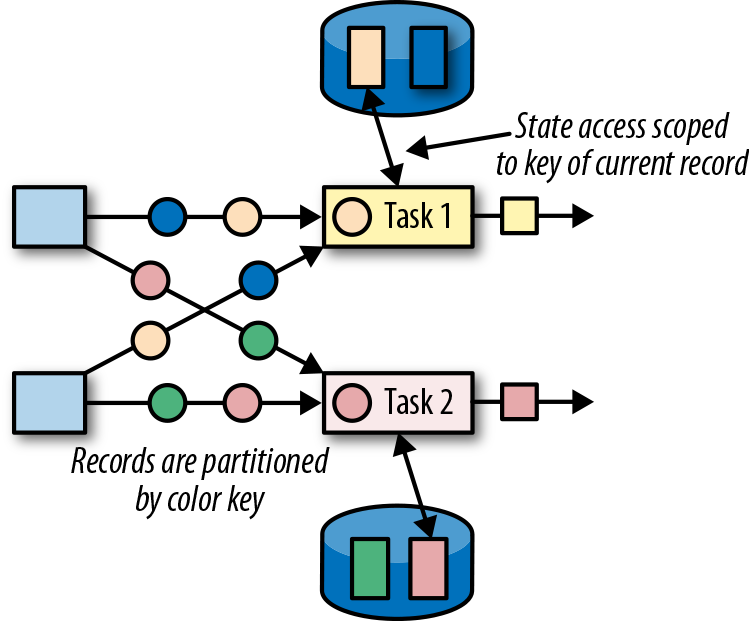 ,有 ValueState、ListState、MapState
,有 ValueState、ListState、MapState - State Backend:state 的读写速度影响 latency
- Scaling Stateful Operators:
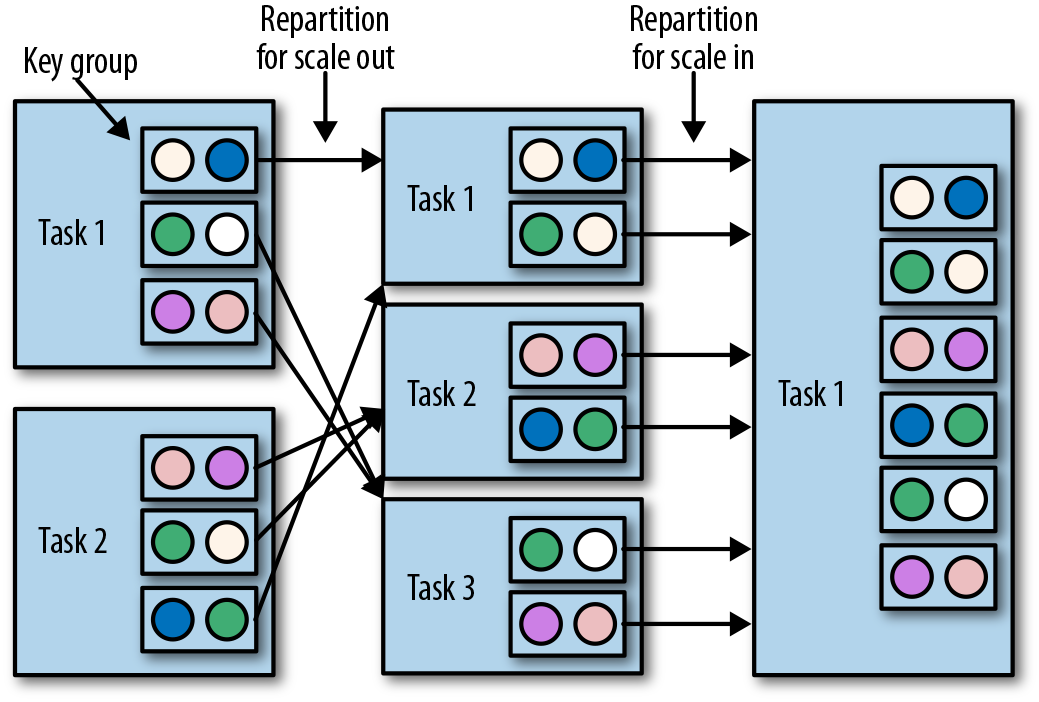 ,scale out、scale in 都按照 key group,而不是 redistribute.
,scale out、scale in 都按照 key group,而不是 redistribute.
- Operator list state :
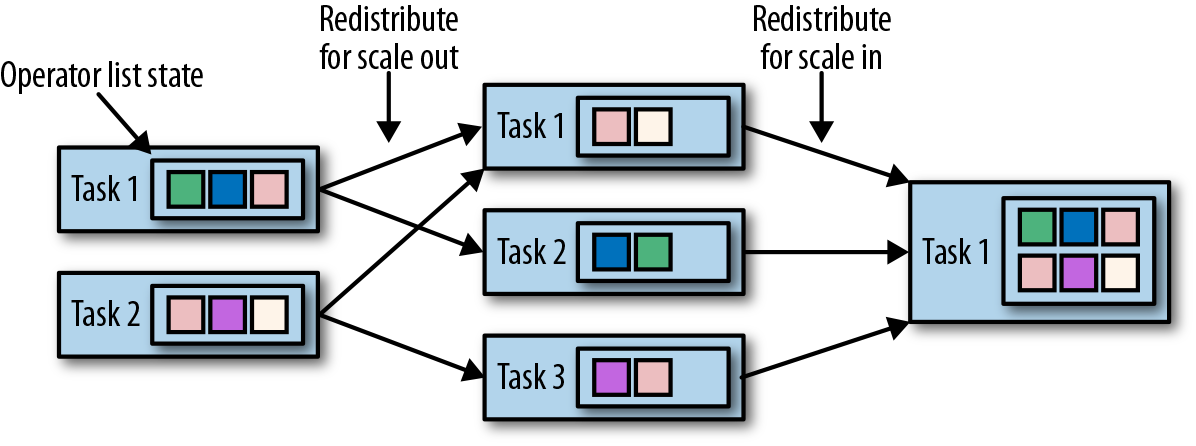
- Operator union list state:
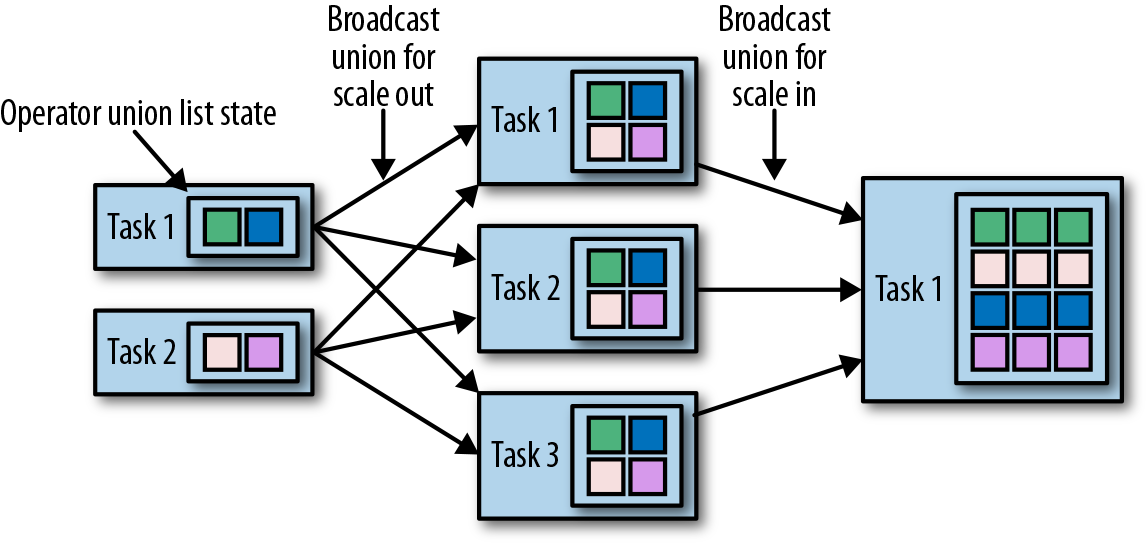
- Operator broadcast state:
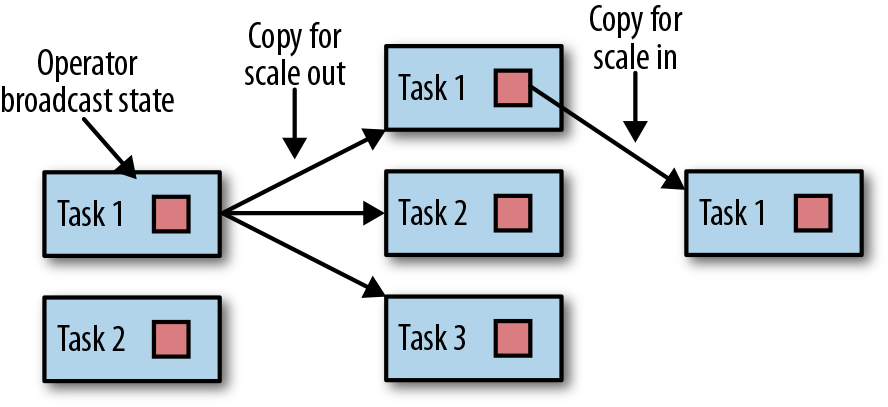
- Operator list state :
3.5 Checkpoints, Savepoints, and State Recovery
Consistent Checkpoints: naive mechanism 需要暂停数据输入,待所有 in-flight 的数据都处理完成后再 resume,但是 flink 采用了更 sophisticated 的方法:
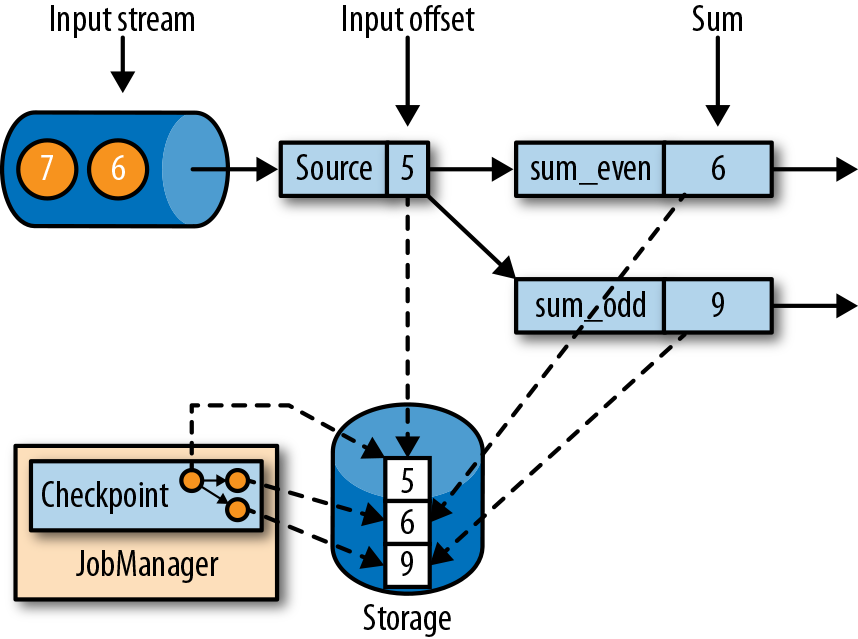 ,Source 产生 1,2,3,… 的数据,在图中的时刻,checkpoint 记录了 Source offset = 5, 而奇数和偶数的 sum 分别为 9 和 6.
,Source 产生 1,2,3,… 的数据,在图中的时刻,checkpoint 记录了 Source offset = 5, 而奇数和偶数的 sum 分别为 9 和 6.- Recovery From a Consistent Checkpoint:
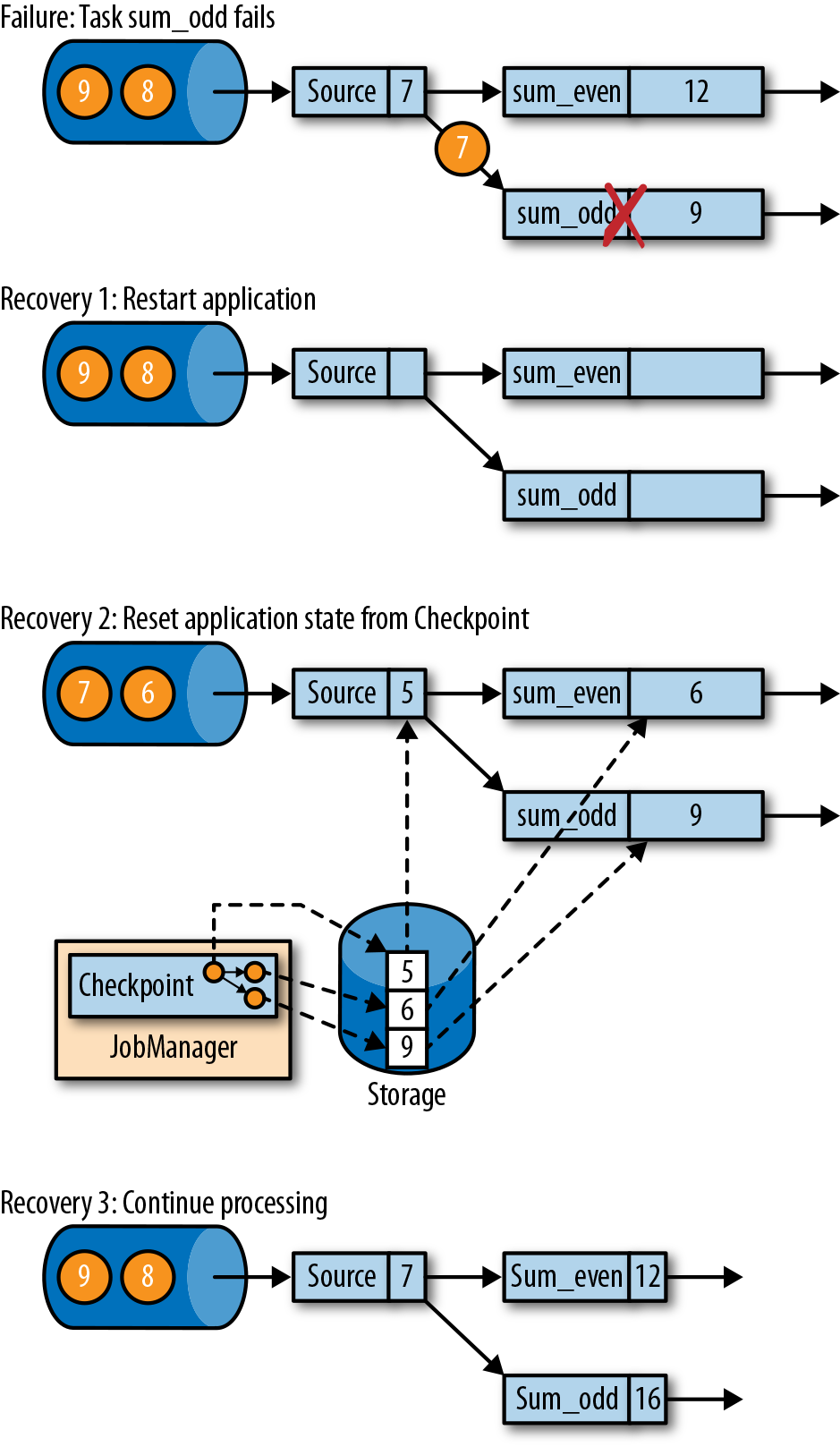 , task 失败从 checkpoint 恢复时,从 5 之后继续消费,数据是正确且一致的。注意 sink operators 可能收到多条。
, task 失败从 checkpoint 恢复时,从 5 之后继续消费,数据是正确且一致的。注意 sink operators 可能收到多条。
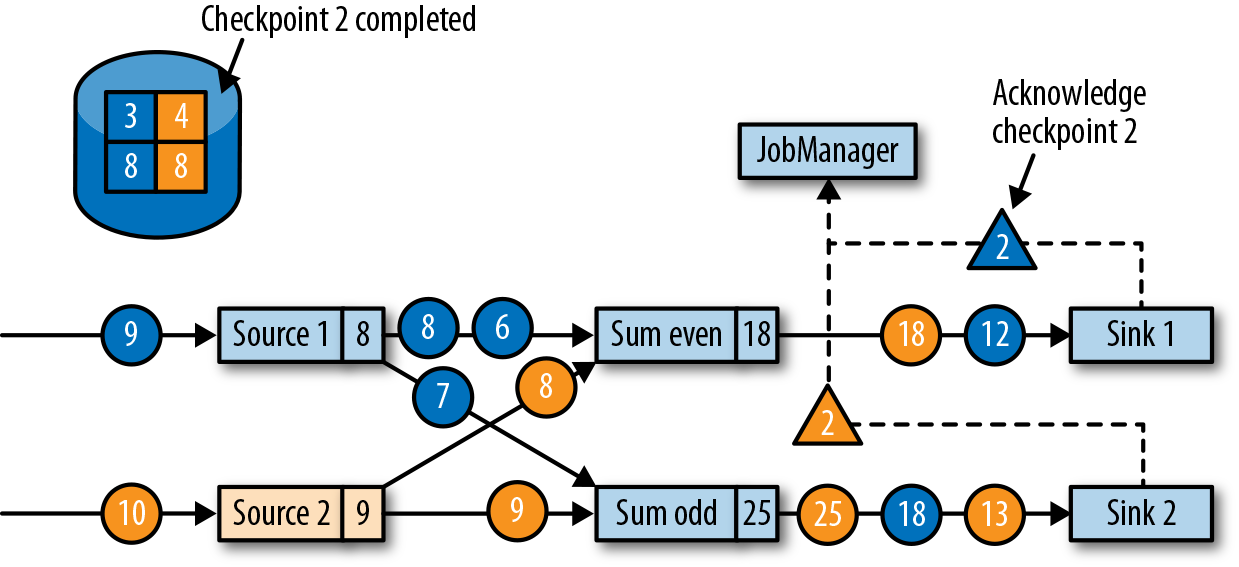
Flink’s Checkpointing Algorithm : Flink 没有使用 pause-checkpoint-resume 的做法,而是基于 Chandy-Lamport algorithm for distributed snapshots.
例如这个过程:
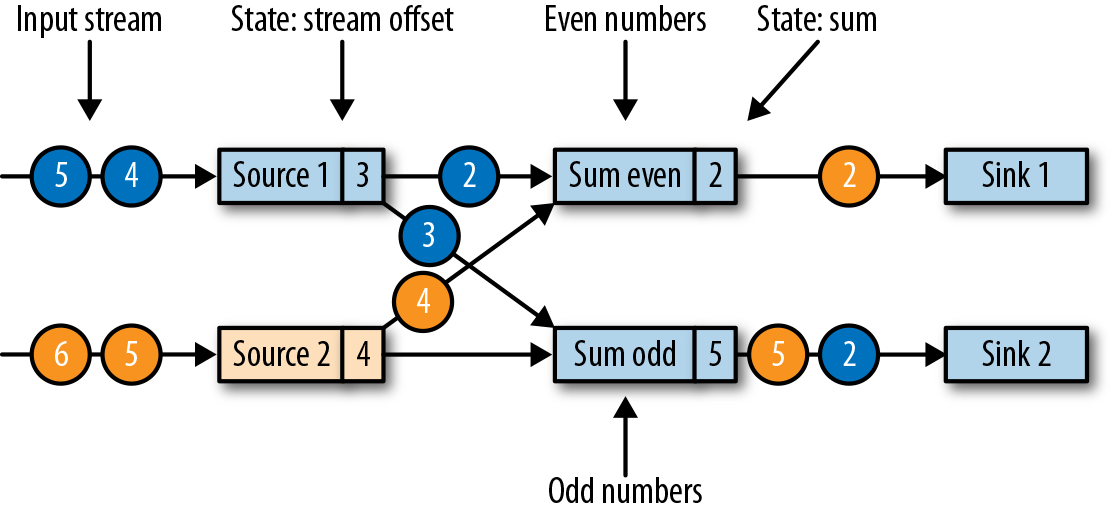
- source 分为两部分,每部分都生成递增的数字,当前状态如图所示:
- 此时 JobManager 触发 checkpointID=2(三角形):
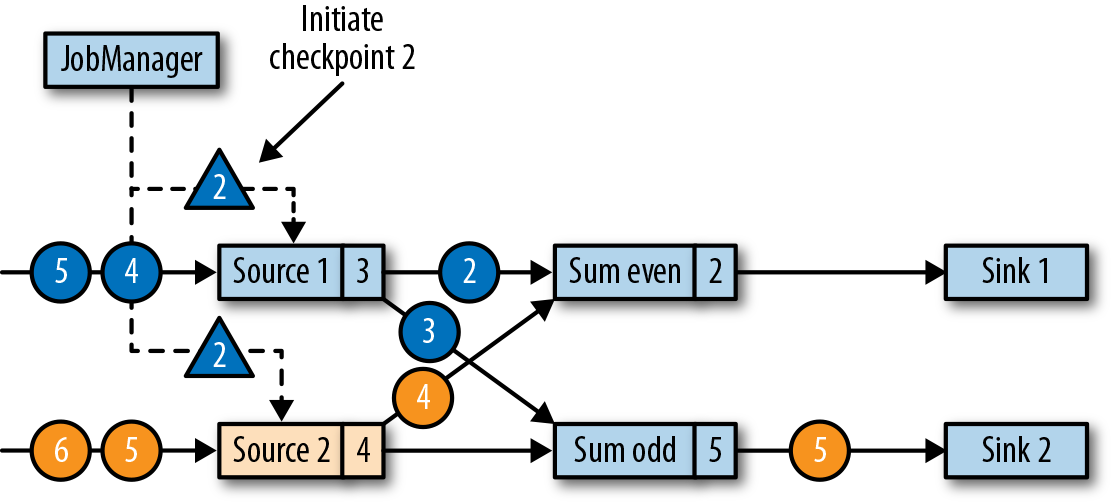
- Source 收到后,记录此时 source 的 offset(3, 4),并在当前位置插入 checkpoint barrier(ID=2),跟普通数据一样,发送到下游算子:
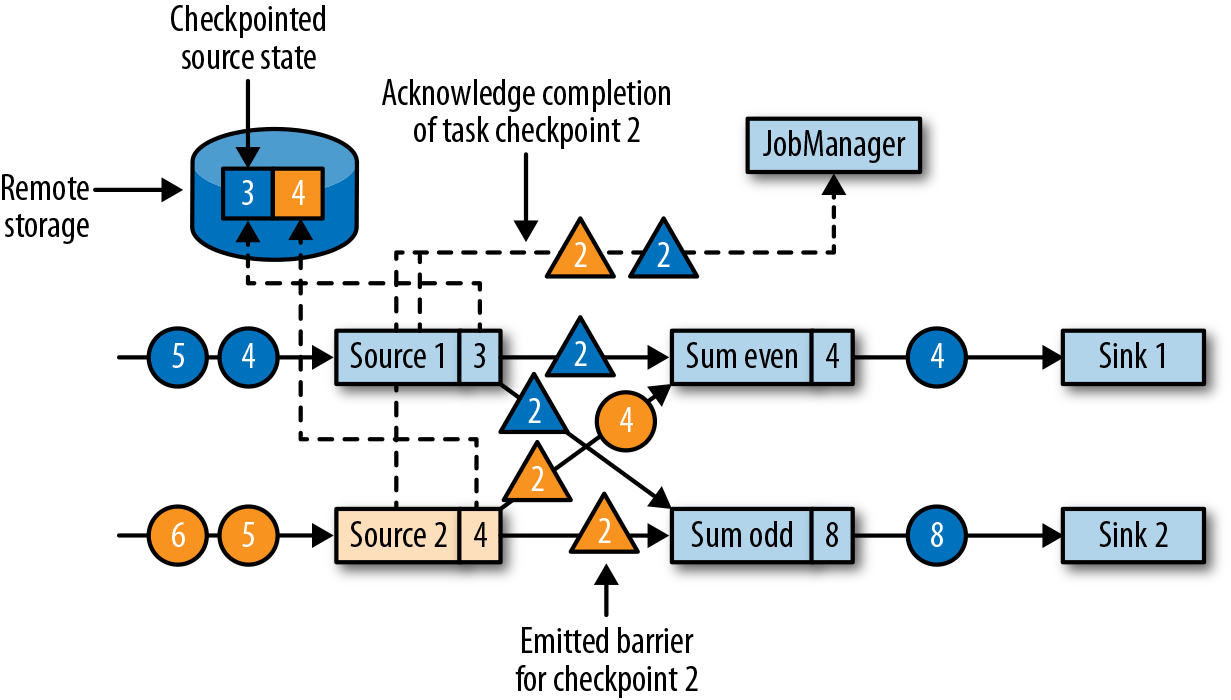
- 下游算子收到后,等待所有上游算子实例的 ID=2 的 barrier:
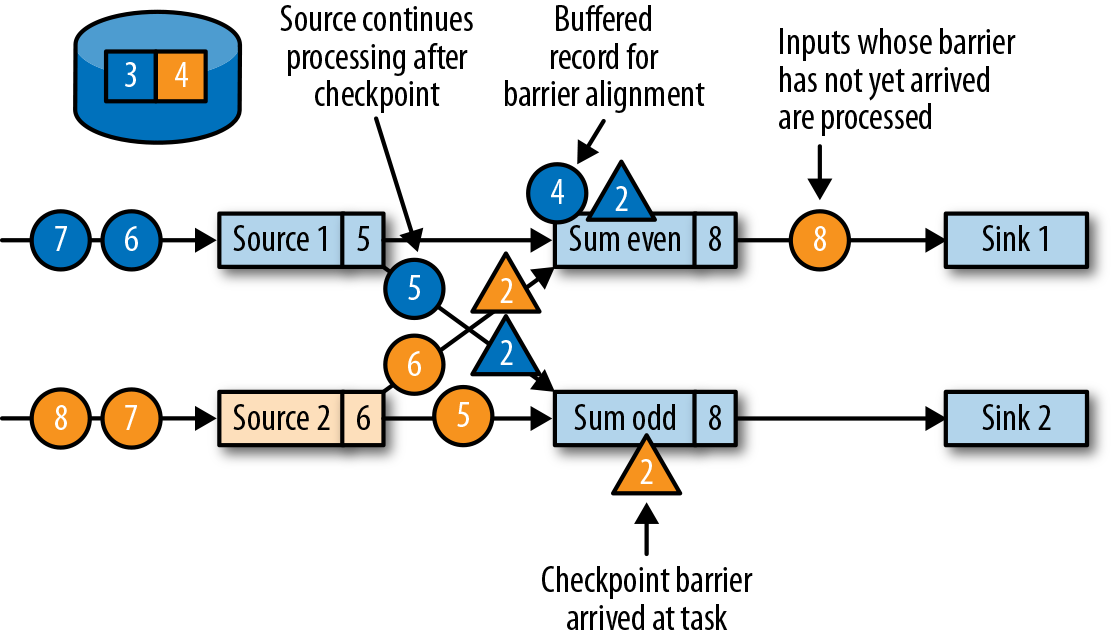 ,此时上游算子仍然在产生数据,当前算子也缓存着晚于 barrier 的数据(例如 Source1 产生的蓝色圆圈4)
,此时上游算子仍然在产生数据,当前算子也缓存着晚于 barrier 的数据(例如 Source1 产生的蓝色圆圈4) - 当所有 ID=2 的 barrier 到达后,该算子也写入 checkpoint 数据(8, 8),
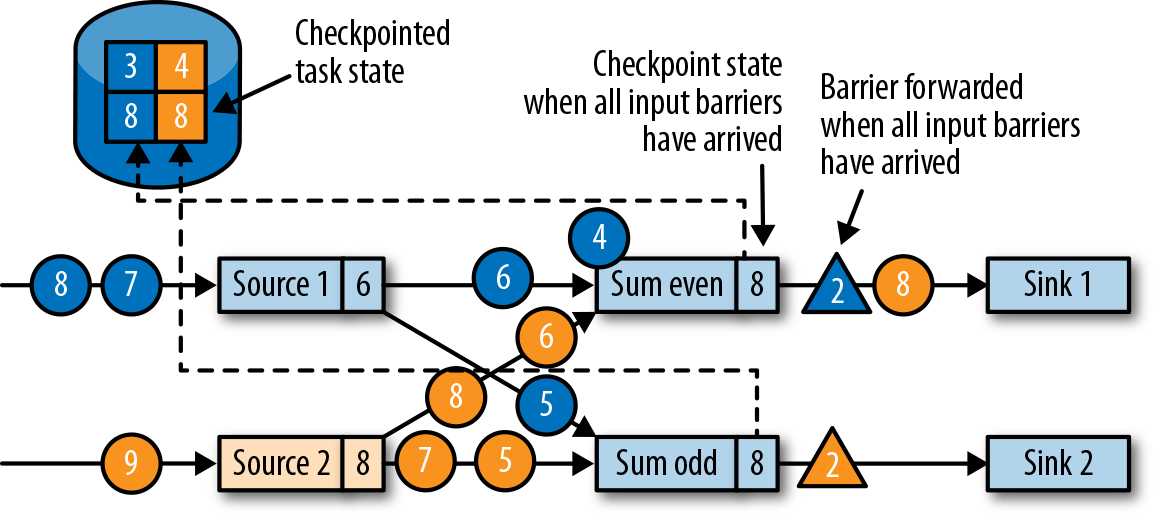
- 待当前算子发送所有 ID=2 的 barrier 后,处理缓存的数据并发送:
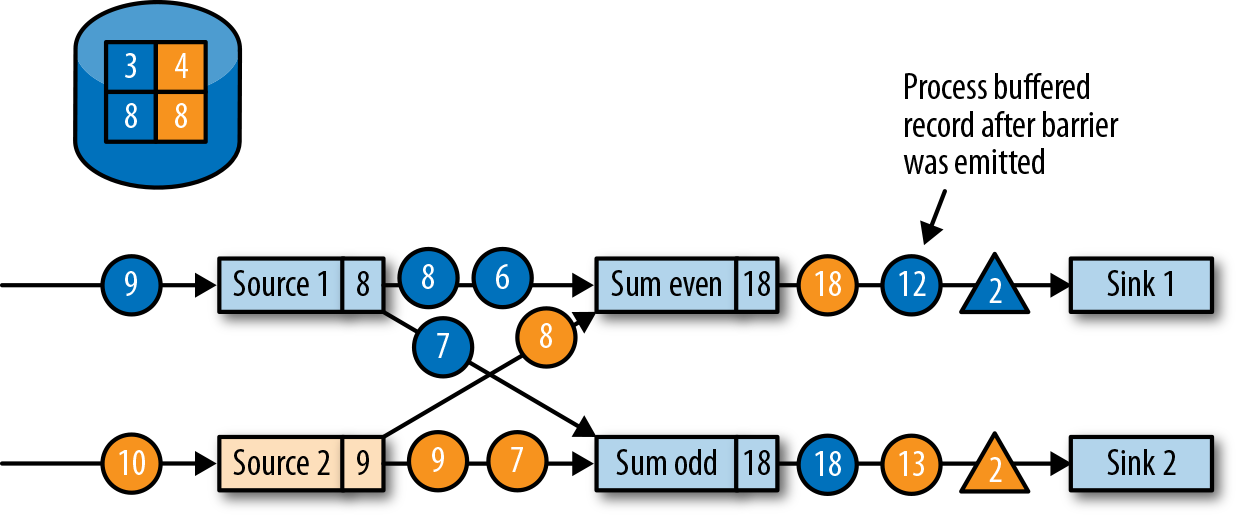
- 当 sink operators 也 ACK checkpoint 后,就认为 ID=2 的 checkpoint 全部完成
Performance Implications Of Checkpointing: 异步的将 local snapshot to the remote storage;不强制等待 barrier 对齐,而是继续处理并发送数据到下游(代价是恢复时只能 exactly-once,以及随着非对齐增多导致 state 变大?)
Savepoints: checkpoints 主要用于失败恢复的场景,但是 consistent snapshots 实际上有更多的用途。Using savepoints:比如 fix bugs and reprocesss 的场景,或者 A/B tests,不过需要 application 前后兼容。修改并发、修改集群、pause-resume.
Starting an application from a savepoint : 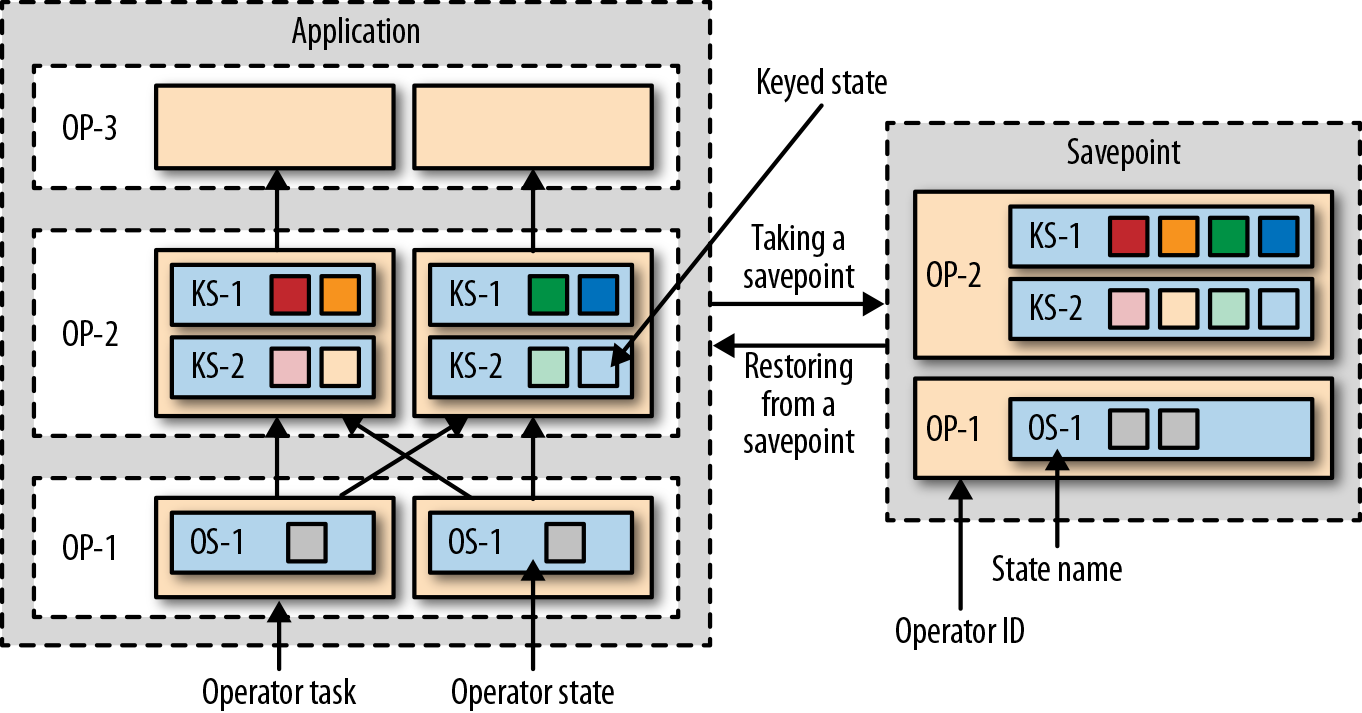
4 Chapter4: Setting Up a Development Environment for Apache Flink
主要介绍在 IDE 上运行 Flink 任务,注意有些 issue 例如 ClassLoader 跟实际环境是不同的
5 Chapter5: The DataStream API(v1.7)
Hello, Flink: 构建一个 flink application 有 5 步:
- Set Up the Execution Environment
- Read An Input Stream
- Apply Transformations
- Output the result
- Execute
Transformations:
- Basic Transformations: on individual events, Map/Filter/FlatMap
- KeyedStream Transformations: in context of a key
- keyBy: convert DataStream into KeyedStream
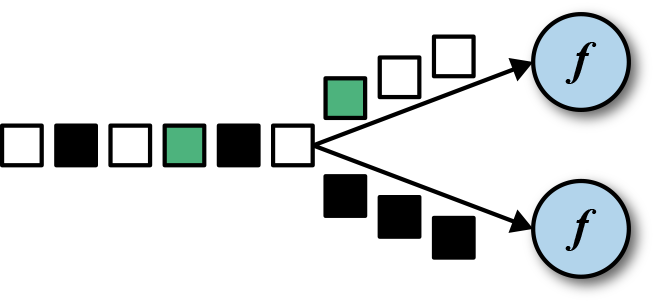
- Rolling aggregations: sum/min/max/minBy/maxBy
- Reduce
- keyBy: convert DataStream into KeyedStream
MultiStream Transformations: merge into one or split into multiple
- Union:
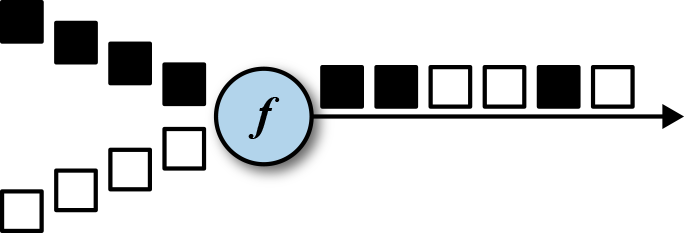
- Connect, coMap, and coFlatMap: DataSteam 的数据是随机处理的,因此 ConnectedStream 常用于两个 KeyedStream、DataStream + Broadcast 以确保结果的确定性,因此用到了 keyedState.
- Split and select: split 与 union 相反 :
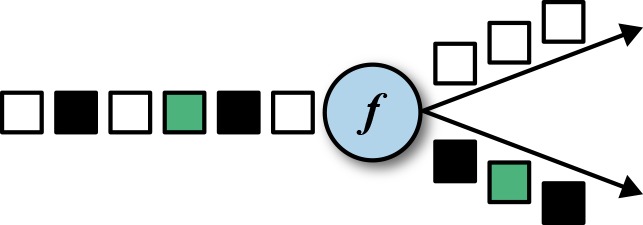 ,返回 SplitStream, 通过 select 方法返回不同的 DataStream
,返回 SplitStream, 通过 select 方法返回不同的 DataStream
Distribution Transformations: 普通情况下是由 operation semantics and parallelism 决定的,不过也支持 shuffle/rebalance/rescale(rebalance vs rescale: 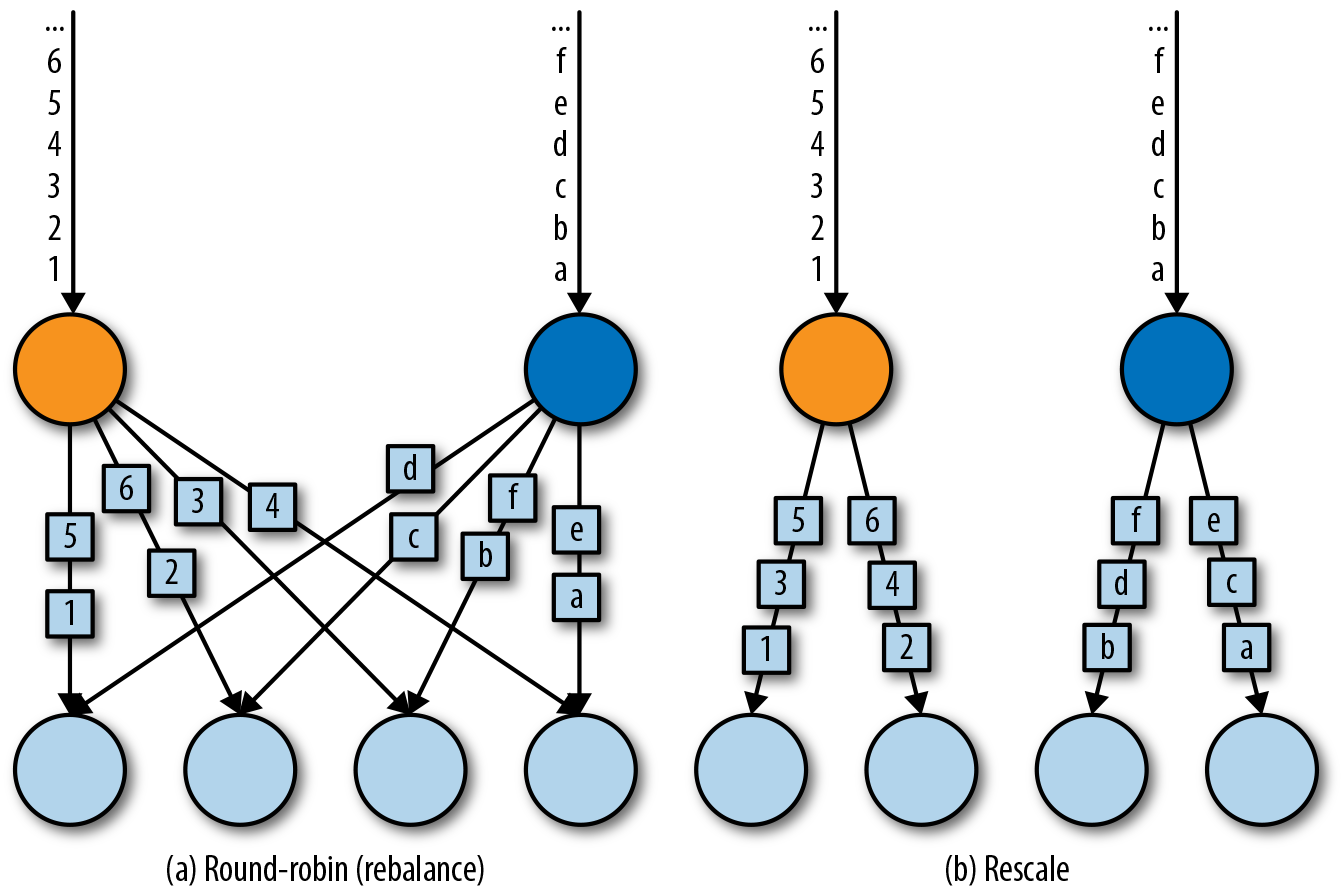 /broadcast/global/partitionCustom(自定义)
/broadcast/global/partitionCustom(自定义)
Setting the Parallelism: application 和 opertor 级别
Types: 网络传输、读写 statebackend 都会用到 Types; 统一各语言的 type diff,例如 scala 和 java 的 tuple (seg-1)、语言特有的,比如 scala case class
- Supported Data Types 包括 Primitives、Java and Scala tuples、Scala case classes、POJOS, including classes generated by Apache Arvo、Some special types, 其他类型则 fallback 到 Kryo serialization framework.
- Creating Type Information for Data Types: type system 的核心类是 TypeInformation,flink 为支持的各种数据类型,都提供了对应的子类实现,例如 NumericTypeInfo 封装了 Integer Long Double Byte Short Float Character 类。
- Explicitly Providing Type Information: 自动提取 TypeInformation 失败的场景(例如 java 里的 erasing generic type information),此时就需要显示指定 return 的 TypeInformation 了。
Defining Keys and Referencing Fields : 可以按照 pos、字段名(literal)、KeySelector
Implementing Functions : Function 应当是 Serializable,如果存在 non-serializable field,需要 override RichFunction.open 方法
6 Chapter6: Time-Based And Window Operators
6.1 Configuring Time Characteristics
6.1.1 Assigning Timestamp and Generating Watermarks
DataStream.assignTimestampsAndWatermarks 的参数类型可以为 AssignerWithPeriodicWatermarks 或者 AssignerWithPunctuatedWatermarks,两者都继承自 TimestampAssigner.
其中:
- TimestampAssigner.extractTimestamp: 定义了提取 timestamp 的接口
- Watermark checkAndGetNextWatermark/ Watermark getCurrentWatermark() :定义了提取 watermark 的接口
AssignerWithPeriodicWatermarks: Watermark getCurrentWatermark() ,watermark 跟 timestamp 有关的场景
# timestamp 为 SensorReading.timestamp
# watermark 为当前收到的maxTimestamp - 1min
# env.getConfig.setAutoWatermarkInterval(5000) => 每 5s 调用一次 getCurrentWatermark 方法
class PeriodicAssigner
extends AssignerWithPeriodicWatermarks[SensorReading] {
val bound: Long = 60 * 1000 // 1 min in ms
var maxTs: Long = Long.MinValue // the maximum observed timestamp
override def getCurrentWatermark: Watermark = {
// generated watermark with 1 min tolerance
new Watermark(maxTs - bound)
}
override def extractTimestamp(
r: SensorReading,
previousTS: Long): Long = {
// update maximum timestamp
maxTs = maxTs.max(r.timestamp)
// return record timestamp
r.timestamp
}
}
明确事件时间递增的前提下,简化为 assignAscendingTimeStamps,相当于使用了内置的 AscendingTimestampExactor implements AssignerWithPeriodicWatermarks ;另外一种常用的内置 AssignerWithPeriodicWatermarks 则是 BoundedOutOfOrdernessTimeStampExtractor.
AssignerWithPunctuatedWatermarks: Watermark checkAndGetNextWatermark,watermark 跟 event 自身有关的场景
# sensor_1 携带着 watermark
class PunctuatedAssigner
extends AssignerWithPunctuatedWatermarks[SensorReading] {
val bound: Long = 60 * 1000 // 1 min in ms
override def checkAndGetNextWatermark(
r: SensorReading,
extractedTS: Long): Watermark = {
if (r.id == "sensor_1") {
// emit watermark if reading is from sensor_1
new Watermark(extractedTS - bound)
} else {
// do not emit a watermark
null
}
}
override def extractTimestamp(
r: SensorReading,
previousTS: Long): Long = {
// assign record timestamp
r.timestamp
}
}
6.1.2 Watermarks, Latency and Completeness
Watermarks are used to balance latency and result completenes,
6.2 Process Functions
相比之前介绍的 MapFunction,process functions 是一组 low-level transformation,能够读取到 timestamp, watermark, register timers. 例如:ProcessFunction, KeyedProcessFunction, CoProcessFunction,ProcessJoinFunction, BroadcastProcessFunction,KeyedBroadcastProcessFunction, ProcessWindowFunction, and ProcessAllWindowFunction.
比如 KeyedProcessFunction 提供的接口,支持获取 TimerService,该类支持获取当前的 timestamp, watermark,同时注册基于时间的回调方法:
processElement(v: IN, ctx: Context, out: Collector[OUT])
onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])
由于使用了回调,注意线程和 cpu 的使用:
- 例子
TempIncreaseAlterFunction:接收到的温度数据里,如果持续升高温度超过 1s,则在 timer 发出数据;如果期间温度降低,则取消 timer. - 例子
FreezingMonitor:使用了 OutputTag[X] 输出到多个 stream - 例子
ReadingFilter: 使用了 CoProcessFunction 来处理两个 stream 协同的场景
6.3 Window Operator
window 的作用,即将 events 归到一个 bucket,然后基于 bucket 内有限的数据计算。
- Tumbling Windows:
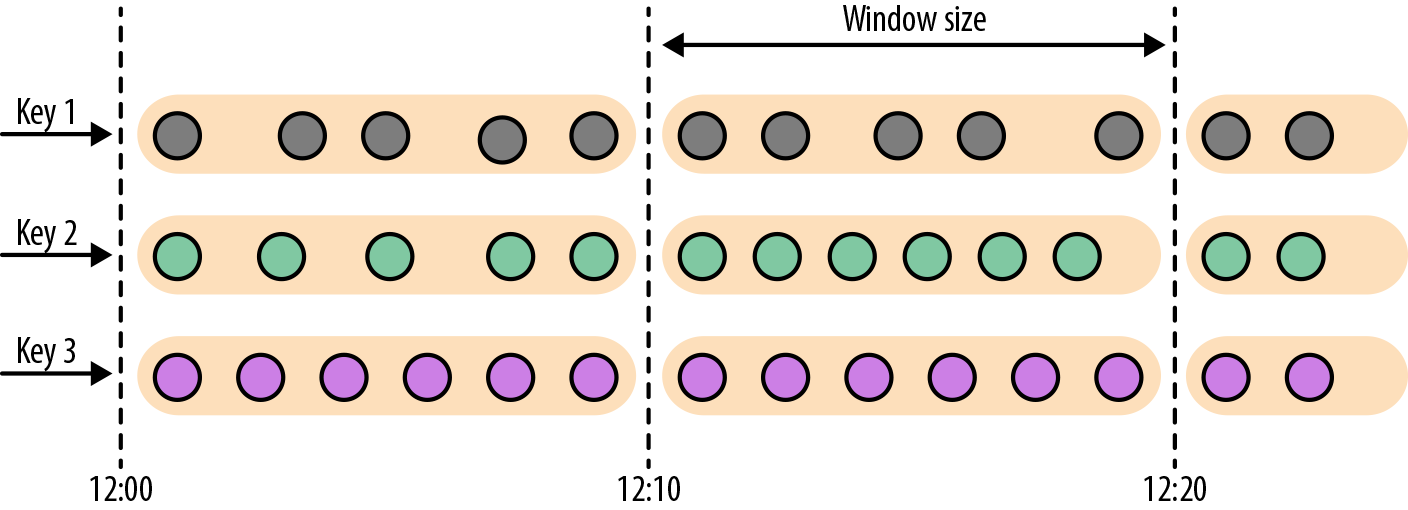 ,
,TumblingEventTimeWindows.of TumblingProcessingTimeWindows.of, 默认对齐到 epoch,也可以指定 offset 参数。 - Sliding Windows:
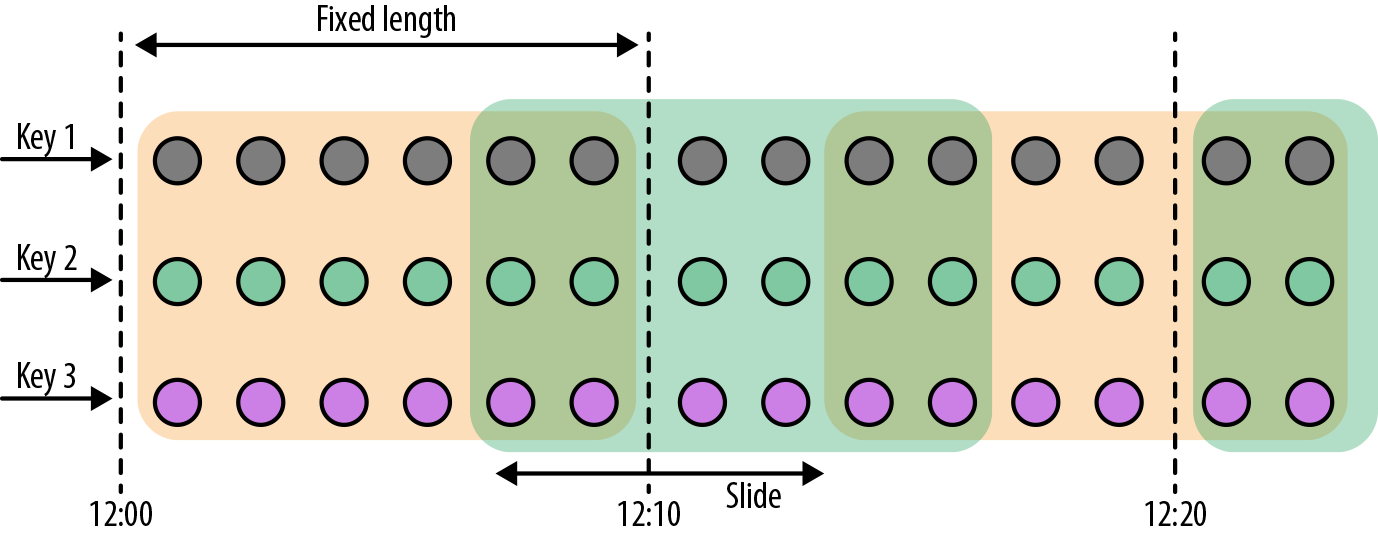 ,
, SlidingEventTimeWindows.of SlidingProcessingTimeWindows.of - Session Window:
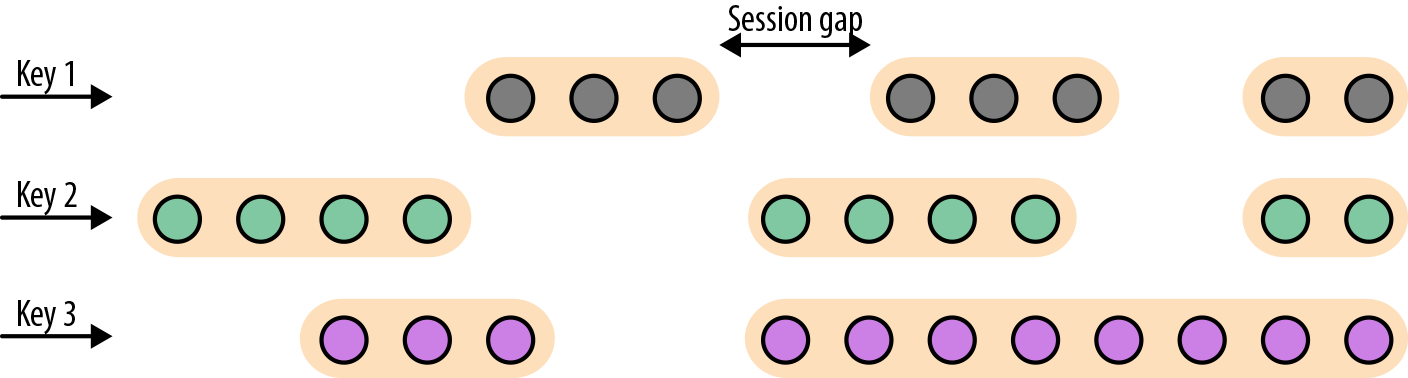 ,
, EventTimeSessionWindows.withGap ProcessingTimeSessionWindows.withGap
作用于 window 的 function 主要有三类:
ReduceFunction: 比如计算窗口里的最大值、最小值等AggregateFunction: 相比 1 更加灵活,不再限制数据类型,子类需要 override 创建初始值、累加、获取结果、merge 方法. 1 2对 state 使用都较小,因为记录的都是 aggregate 的值。ProcessWindowFunction: 如果要计算一个窗口内的中间值,就依赖遍历 window 的数据了;所有数据在底层通过 ListState 存储,因此可能变的非常大,最好想办法变成 incrementally aggregated.
自定义 window 由三部分组成:assigner, trigger, evictor
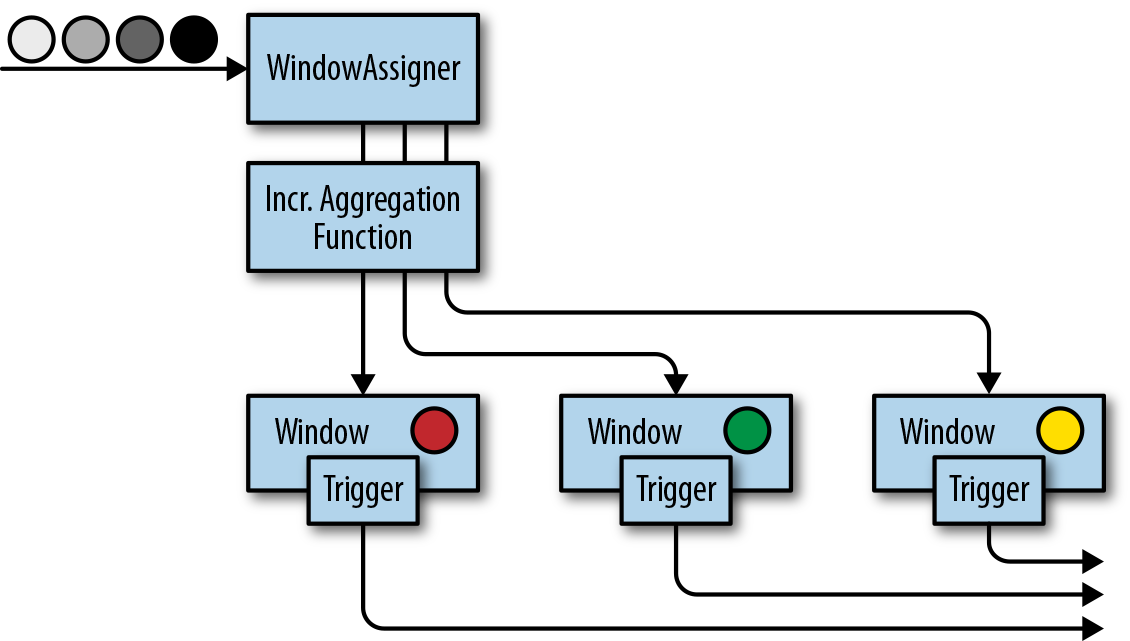
- incremental aggregation function(记录 aggregation 值):
- full window function(记录全部 event,使用 ListState):
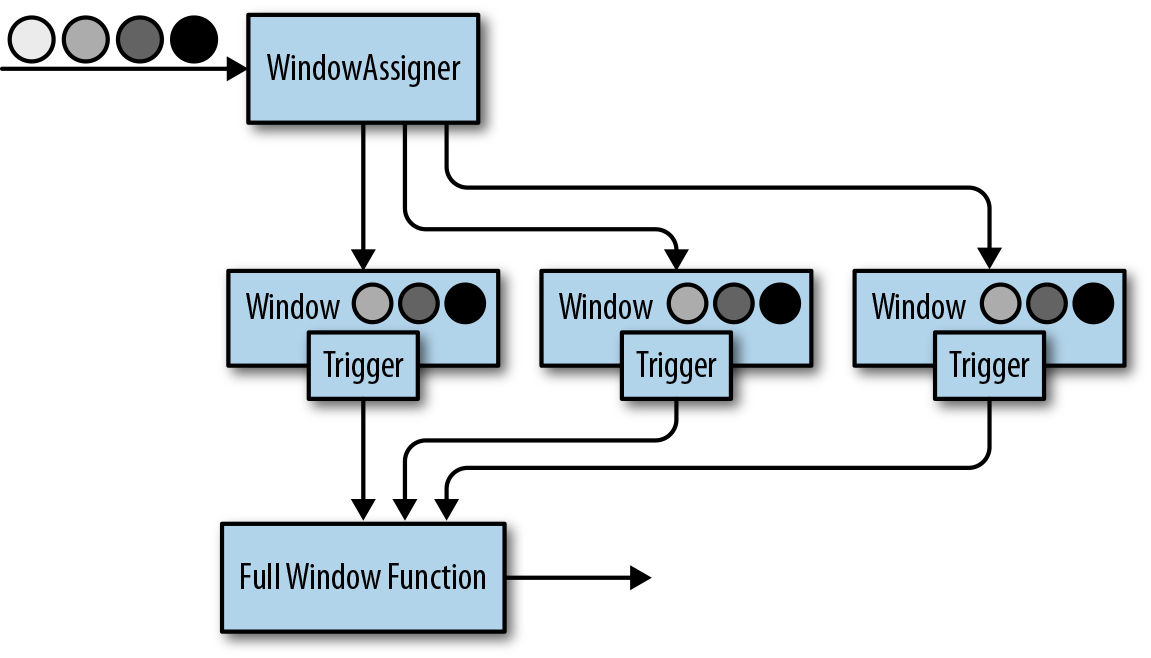 ){:width=”300”}
){:width=”300”} - mix:
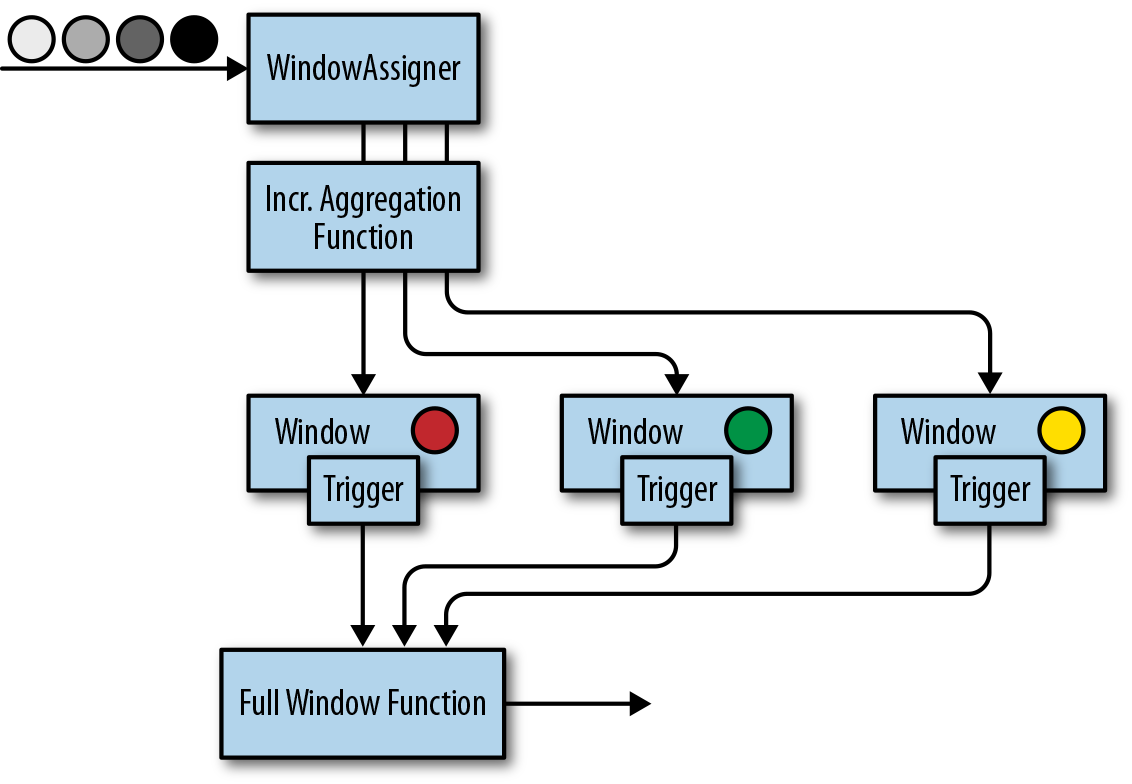
可以通过
- extends WindowAssigner 实现自定义的窗口范围;
- extends Trigger 用于触发窗口数据的计算和结果返回,
onElement onEventTime onProcessingTime返回TriggerResult,CONTINUE, FIRE, PURGE, FIRE_AND_PURGE等枚举值,可以参考内置的class EventTimeTrigger extends Trigger<Object, TimeWindow>实现。 - Evictor 是可选项,似乎仅在 Non Incremental Aggregation Function 里才有意义,没太看懂,具体可以翻翻
TopSpeedWindowing的例子代码。
6.4 Joining Stream on Time
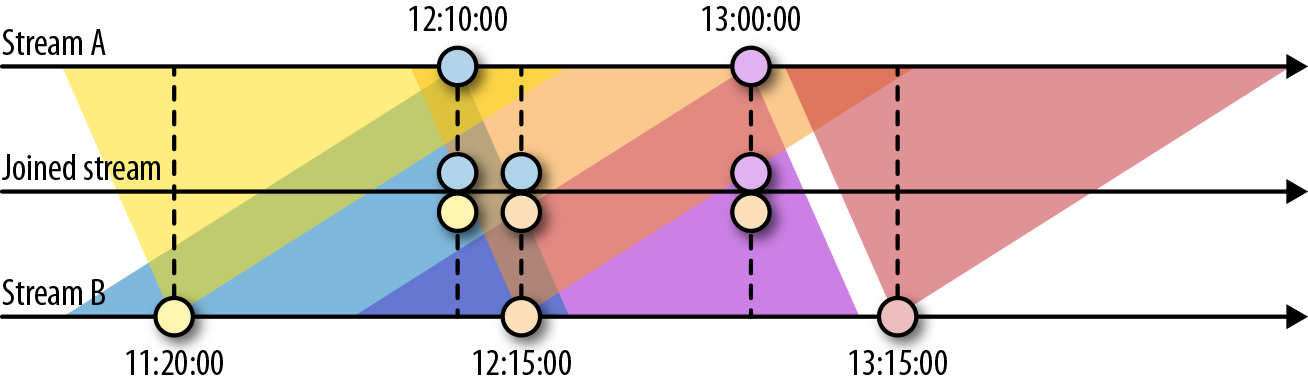
Interval Join:INNER JOIN 的语义,且仅支持 Event Time.
 ){:width=”300”}
){:width=”300”}
如图,表示 A 会选择 B 里 [-1hour, +15min] 时间范围,相同 key 的数据;如果 JOIN 不到,则忽略该数据。对应代码实现形如:
input1
.keyBy(…)
.between(<lower-bound>, <upper-bound>) // bounds with respect to input1
.process(ProcessJoinFunction) // process pairs of matched events
B 也是对称的行为,即 JOIN A 对应时间范围内的数据。 按照上述行为,State 里就需要存储:
- A 里 >= CurrentWatermark - 15Min 的数据(B 可能会 JOIN)
- B 里 >= CurrentWatermark - 1Hour 的数据(A 可能会 JOIN) 如果两者的 watermark 对不齐,那则取决于更慢的那条流。注:此时 State 可能会遇到读写、大小的瓶颈
Window Join: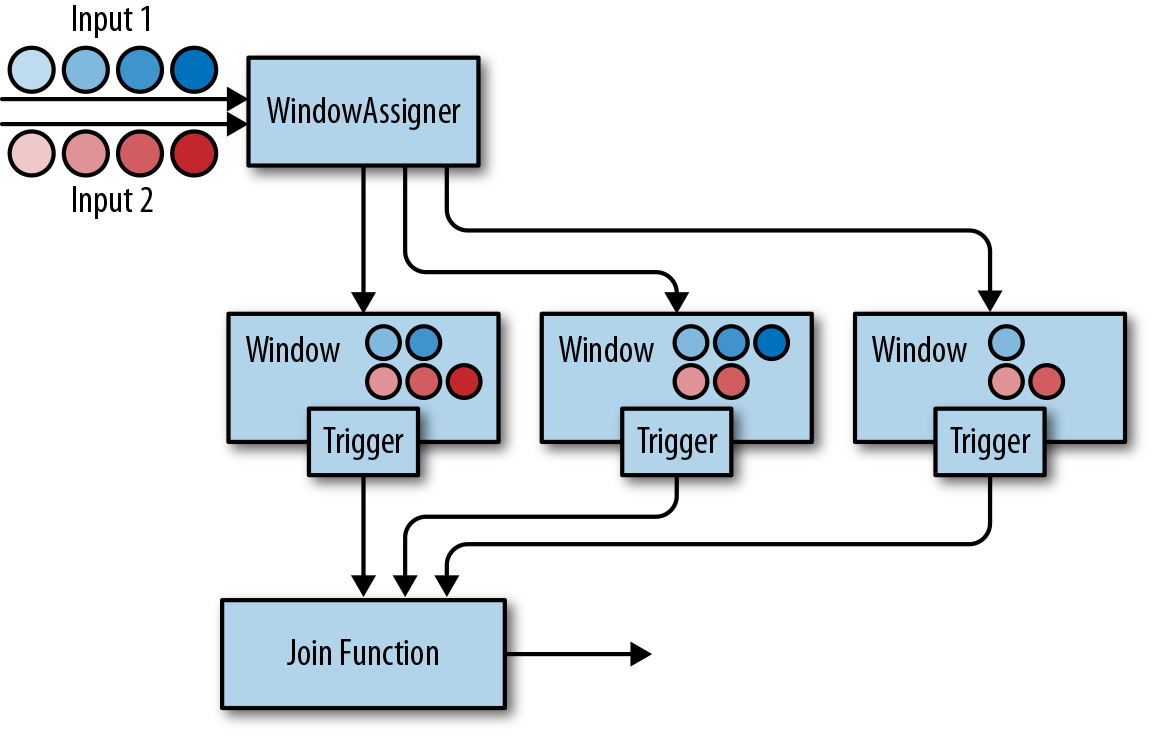
Tumbling Window Join 的效果: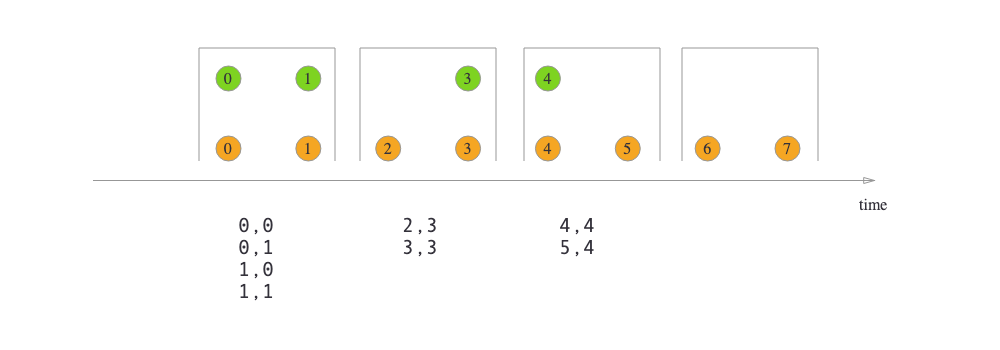
6.5 Handling Late Data
处理迟到的数据有三种方式:Drop, Redirecting, Updating Results By Including Late Events.
Redirecting 主要依赖 Side-Output feature:
- Window Operator With Side-Output:
.timeWindow.sideOutputLateData - 在 ProcessFunction 里比较:
class LateReadingsFilter
extends ProcessFunction[SensorReading, SensorReading] {
val lateReadingsOut = new OutputTag[SensorReading]("late-readings")
override def processElement(
r: SensorReading,
ctx: ProcessFunction[SensorReading, SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
// compare record timestamp with current watermark
if (r.timestamp < ctx.timerService().currentWatermark()) {
// this is a late reading => redirect it to the side output
ctx.output(lateReadingsOut, r)
} else {
out.collect(r)
}
}
}
allowedLateness允许迟到的数据再次参与 window 的计算(潜在行为即 window 的数据保留时间更长)