skiplist,即跳表是由William Pugh在1989年发明的,允许快速查询一个有序连续元素的数据链表,搜索、插入、删除的平均时间复杂度均为O(lgn)。
本文介绍下对于skiplist的理解,包括背景、推导过程、伪代码以及复杂度的证明。
1. 背景
有序数组的好处是可以通过二分实现O(lgn)的高效查找,然而插入元素时,为了保证有序性,时间复杂度是O(n)的。链表则刚好相反,插入数据是O(1),查找元素则是O(n)的。即使链表数据是有序的,查找元素仍然是O(n)的,因为本质上,链表不支持random access.
那么,是否存在一种链表,既支持高效的数据插入,又可以实现高效的查找?
介绍skiplist前,我们先举一个坐火车的例子。
假设公司组织出去bui,我们居住在城市A,想要到城市H去,其中城市A到H有两趟车:
一趟慢车:
A -> B -> C -> D -> E -> F -> G -> H -> I -> J -> K -> L -> M -> N
此外还有一趟快车,经过H的上个城市G
A -> C -> E -> G -> I -> K -> M
bui自然要尽快去吃喝玩乐,那么怎么能尽快的到达城市H呢?很直观的,我们会这么选择
- 先乘坐快车 A -> C -> E -> G
- 再乘坐慢车 G -> H
假设把火车的路线想象为一个链表,那么这个链表明显是有序的,每个城市都是链表上一个节点,去到城市H相当于找到H这个节点,可以看到:
通过乘坐快车,我们能够更快的开始bui
即
通过使用数据量更少(子集)的辅助有序链表,我们能够实现更快速的查找
这就是跳表最朴素的想法(really pretty simple👏 so young so naive.)
2. 推导
2.1. 两个列表
接着上面的快车、慢车的想法,我们先抽象两个列表的情况分析下。
假设慢车链表为L2,元素个数为n,快车链表为L1,那么第一个问题就是L1应该取多少节点?可以达到最低的时间复杂度?
推导过程:
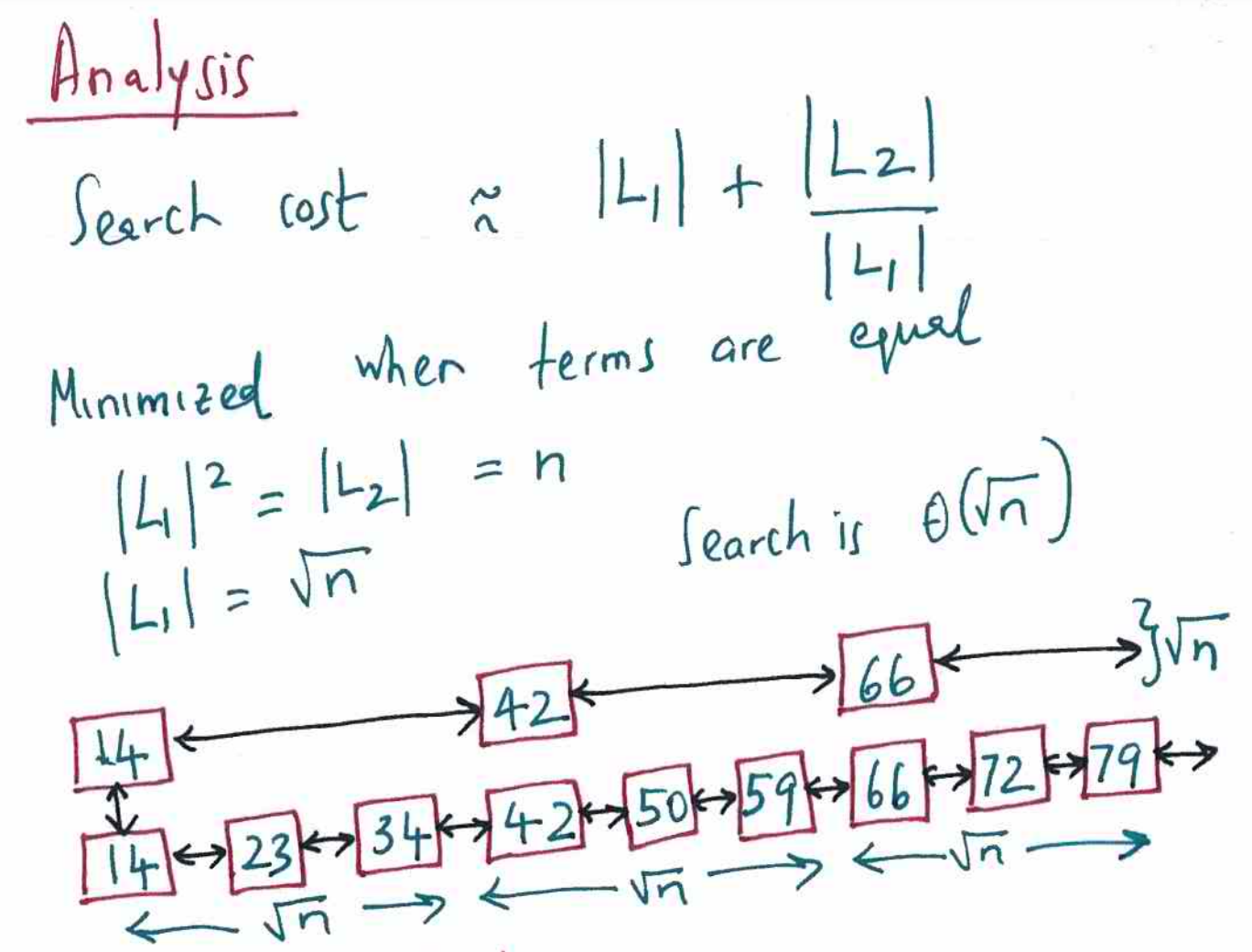
不等式疑问的可以回顾下数学里的基本不等式。
因此得到结论:查找的时间复杂度为sqrt(n),当且仅当L1的长度 = sqrt(n)时成立,也就是L1存在sqrt(n)个节点并且均分L2的情况下。
2.2. 多个列表
很明显,多个列表可以优化查找的时间复杂度,那么第二个问题就是需要多少个列表才能达到O(lgn)的时间复杂度?
看下推导过程:
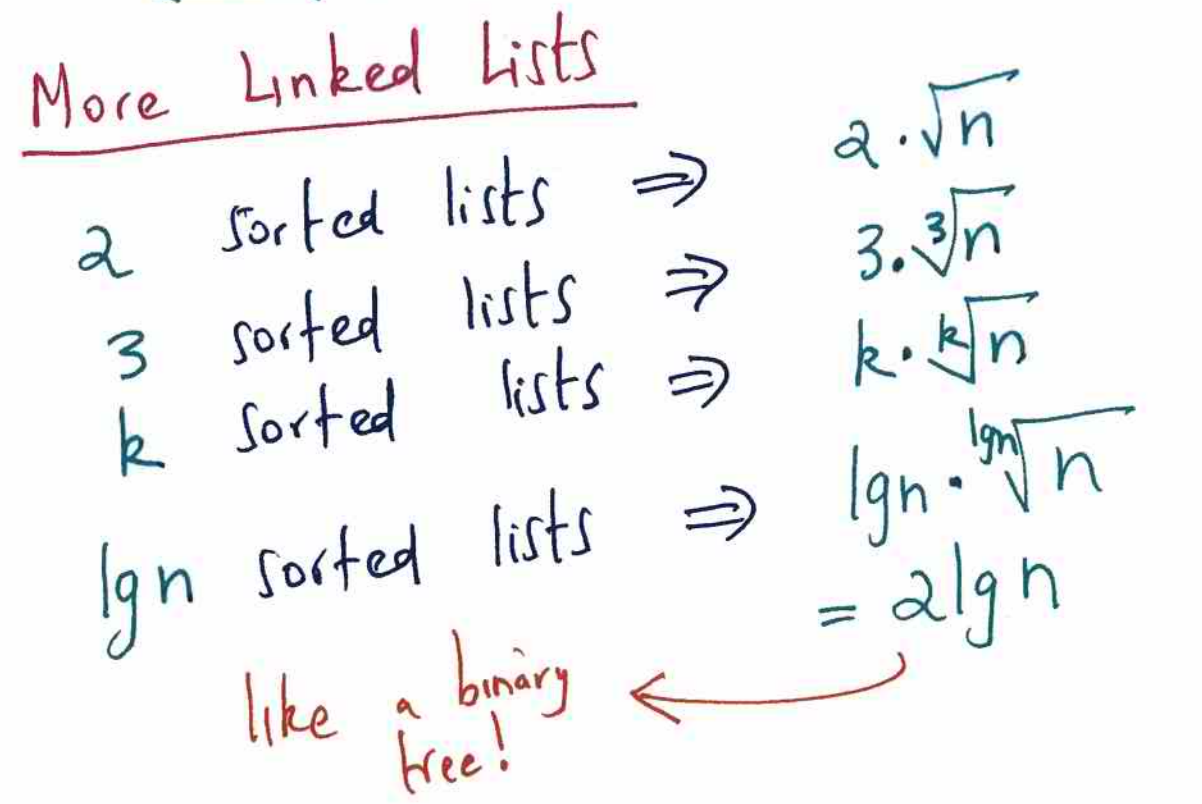
因此得到结论:当存在lg(n)个链表时,查找元素的时间复杂度为2lgn,即O(lgn),此时相邻的两个链表,底层链表每2个元素生成一个高层链表,一共lgn层。例如:

但要维护这么一个理想的skip list,当需要插入元素x时,需要逐个遍历确认都有哪些列表可以插入x,可以想像insert的操作是十分复杂的。
2.3. skiplist的做法
上面提了理想skiplist是每隔两个元素,则该元素会在下一个链表出现,但维护这么一个性质操作太复杂了。
实际实现里采用了概率论的做法,有时候数学家的做法就这么简单可依赖:我们用抛硬币来解决吧😱。
如果硬币朝上,那就认为元素x应当产出到下一个链表,因此是否会在下个列表出现的概率为p = 1/2。
因此,假设初始n个元素的列表为level-0,平均的:
1/2的元素会在level-1列表出现
1/4的元素会在level-2列表出现
1/8的元素会在level-3列表出现
etc.
经过这样的处理,我们可以得到一个神奇的结论,从期望值上看:
| 空间 | O(n) |
| 高度 | O(lgn) |
| 查找 | O(lgn) |
| 插入 | O(lgn) |
| 删除 | O(lgn) |
其中skiplist满足如下条件

+∞ -∞定义是为了实现上的方便性。
3. 具体实现
3.1. search
比如要查找skip list里值为x的元素,search操作的步骤为:
- 从top-list的第一个元素开始,也就是-∞
- 在当前位置p,比较x与p的下一个元素的值y:如果x == y,返回p的下一个元素;如果x > y,p在本层向前移动一个位置(scan forward);如果 x < y,向下一层(drop down)。
- 如果尝试在最底层继续向下一层,说明值为x的元素不存在。
具体图示如:

3.2. insertion
记录每一行最后一个小于x的元素,然后插入到这些元素后面
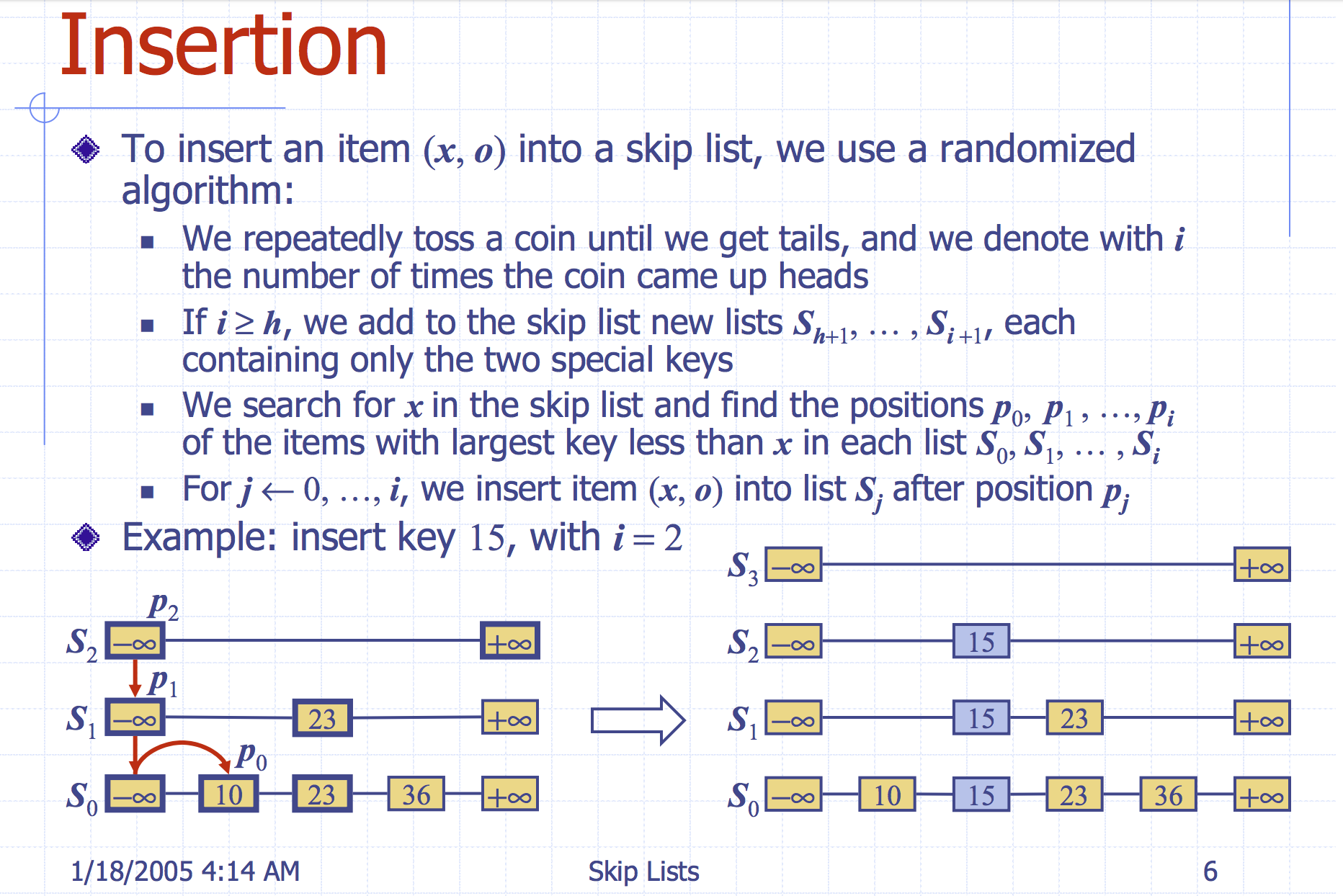
3.3. deletion
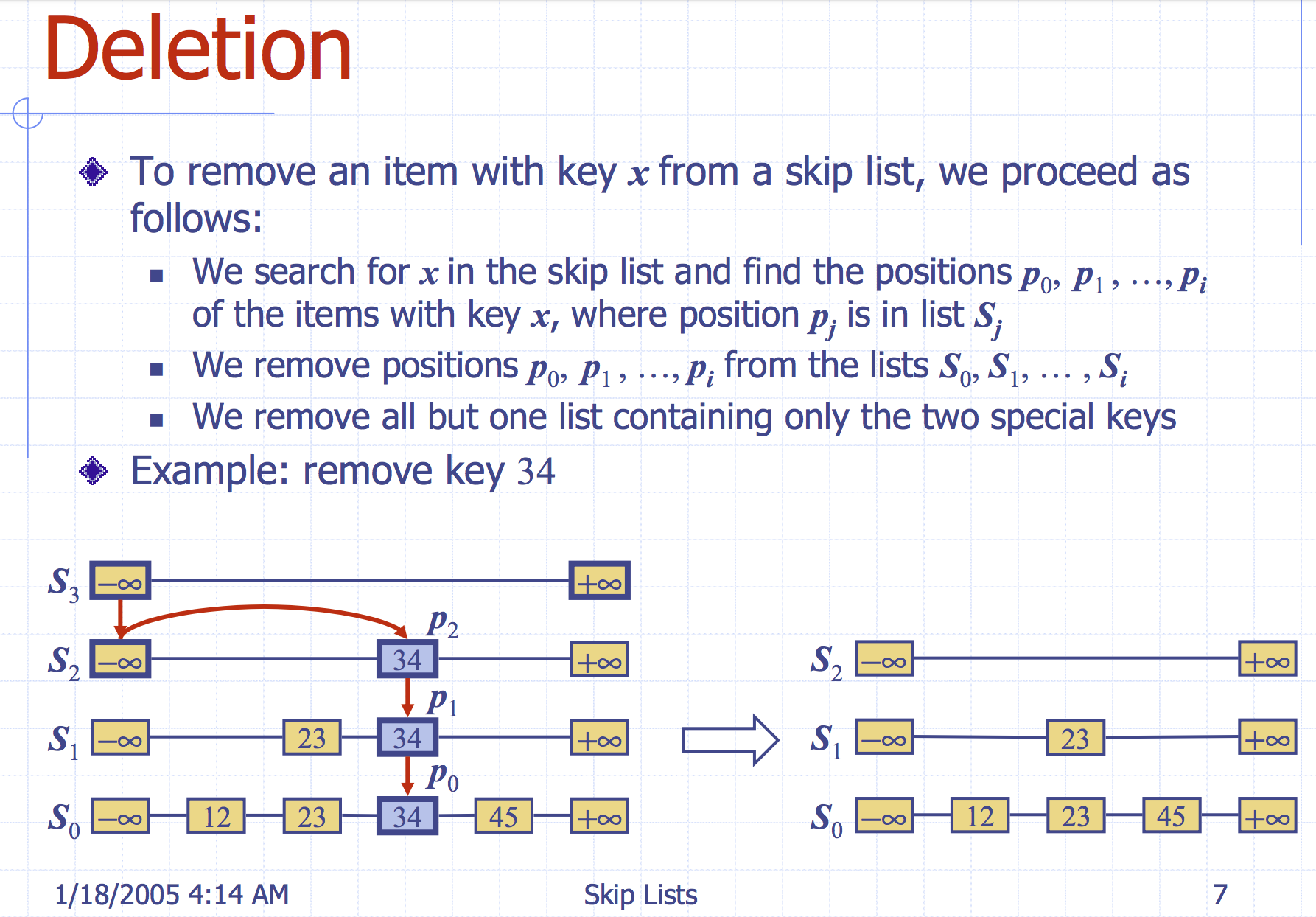
4. 证明
本节我们试着证明下上面的各个复杂度
4.1. 空间复杂度
每个元素在下层出现的概率p = 1/2,因此我们可以得到:
- level-0层元素个数为n
- level-1层元素个数为n/2
- level-2层元素个数为n/4
- …
所以空间复杂度为
# 等比数列求和
n + n/2 + n/4 + n/8 + ... = 2n = O(n)
4.2. 高度
对level-i的列表,每个元素出现的概率为2i,那么先看下至少有一个元素出现的概率。
根据Boole’s inequality ,我们可以得到
P{至少一个元素出现}
= P{元素0出现 U 元素1出现 U 元素2出现 U ... U 元素n出现}
<= P{元素0出现} + P{元素1出现} + P{元素2出现} + ... + P{元素n出现}
= n /2^i
也就是:
对level-i的列表,至少一个元素出现的概率至多为 n / 2^i
假设i=c*lgn,其中c是一个常数,那么至少一个元素出现的概率至多为 n / 2^clgn = n / n ^ c = 1 / n^(c-1),例如对于c=3,概率为1 / n^2。
也就是说,高度不超过3*lgn的概率为 1 - 1/n^2,这是一个很高的概率,而实际上高概率的定义为
with high probability(w.h.p.)if, for any a >= 1, there is an appropriate choice of constants for which E occurs with probability at least 1 - O(1/n^a)。
因此高度高概率下的值为O(lgn)。
关于高度的期望值,参考资料里这么证明如下:
对每层来说,它会向上增长的概率为1/2,则第m层向上增长的概率为1/2m;n个元素,则在m层元素数目的期待为Em = n/2m;当Em = 1,m = log2n即为层数的期待。故其高度期待为 Eh = O(log n)。
4.3. search and update
因此,search的时间复杂度与两个操作有关:scan forward && drop down.
其中drop down的期望与高度有关,也就是O(lgn).
根据公式:
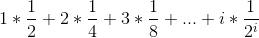
scan forward的期望大小为2,因此search的时间复杂度为O(lgn)。
insert/delete的分析与search类似,不再赘述,详细的实现在代码一节里介绍。
可以看到,通过抛硬币的做法,在高概率的情况下,各项复杂度与理想的skip-list是一致的,因此我们称之为一个概率数据结构。正如Skip_list所说:
A skip list does not provide the same absolute worst-case performance guarantees as more traditional balanced tree data structures, because it is always possible (though with very low probability) that the coin-flips used to build the skip list will produce a badly balanced structure.
但在实际工作中,可以工作的很好。
5. 论文补充
skiplist 相比 balanced trees的优势
For many applications, skip lists are a more natural representation than trees, also leading to simpler algorithms. The simplicity of skip list algorithms makes them easier to implement and provides significant constant factor speed improvements over balanced tree and self-adjusting tree algorithms. Skip lists are also very space efficient. They can easily be configured to require an average of 1 1/3 pointers per element (or even less) and do not require balance or priority information to be stored with each node.
建议同时设置一个 MaxLevel
Determining MaxLevel Since we can safely cap levels at L(n), we should choose MaxLevel = L(N) (where N is an upper bound on the number of elements in a skip list). If p = 1/2, using MaxLevel = 16 is appropriate for data structures containing up to 216 elements.