统计语言模型的发展路线:
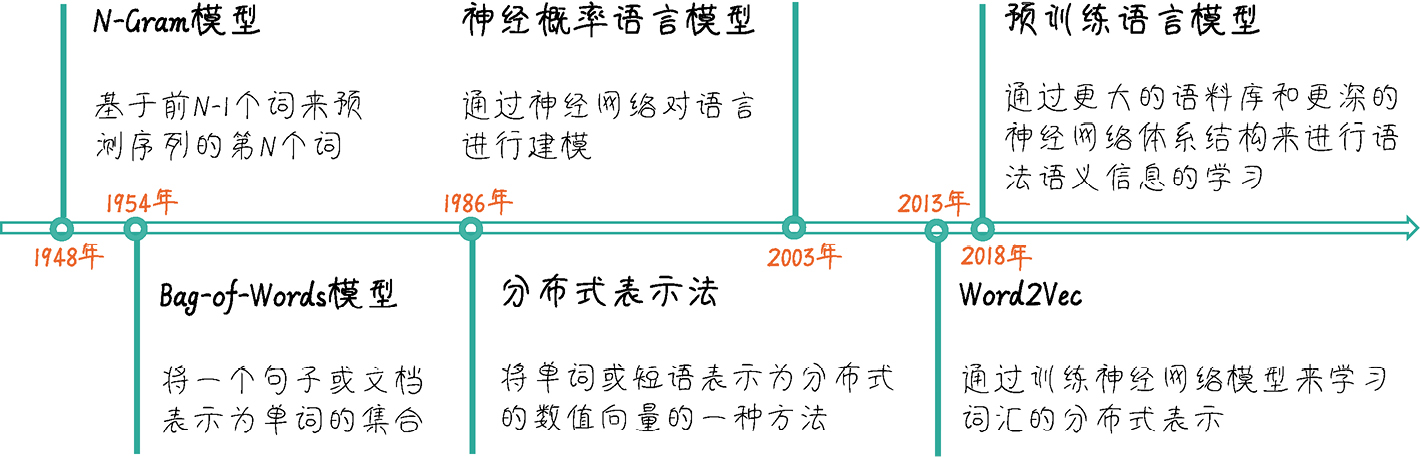
核心:N-Gram → NPLM → RNN → LSTM/GRU → Transformer → BERT/GPT
这篇笔记主要记录:
- N-Gram: 统计前 n-1 个词出现的概率,计算 \( P(\text{word}n \mid \text{word}{n-1}, \text{word}_{n-2}) \),不具备泛化能力。
- NPLM: 引入 embedding(词向量),具备了 泛化 能力,但仍然是固定窗口
- RNN/LSTM: 引入 hidden state 递归,支持了 变长 序列,不再是固定 n_step 的前文词长度
1. N-Gram 和 Bag-of-Words
N-Gram 模型是一种简化的概率模型,它通过计算前 N 个词的联合概率来预测下一个词,因此适用于文本生成的场景。
基础流程为:
- 对每个 N-Gram ,统计紧跟其后的第一个 token 数:
{$ngram : {$next-token-1: cnt-1, $next-token-2: cnt-2, ...}} - 基于1,就可以计算 $ngram 之后 $next-token-1 $next-token-2 等的概率
- 基于2,当给定初始语句,就可以一直按照概率采样选择 next-token-x,预测新的句子
该模型是基于以下两个假设:
- 贾里尼克假设:一个句子是否合理,取决于其出现在自然语言中的可能性的大小
- 一阶马尔可夫假设:任意一个词出现的概率只同它前面的那一个词有关
虽然现在的语言模型基本不再基于假设 2,但是从 N-Gram 到 Infini-Gram 还是一直有探索,比如 Tiny Infini-Gram,基于超大的 token 统计,通过已有前缀选择下一个词,效果上类似“混搭”了多个来源的数据集。
Bag-of-Words 对每个句子,记录了词汇表中每个词出现的次数,能够计算句子间的相似度,因此适用于计算文本相似度的场景
基础流程为:
- 分词( jieba etc.)
- 建立词汇表,每个词给定唯一下标
- 遍历全部句子逐个处理,生成
m*n的结果,其中 m 是句子个数,n 是词汇表大小 - 单个句子的处理逻辑:用长度为 n 的向量,如果句子包含该词,则在对应下标处记录词频
- 计算不同向量的余弦相似度,即等价于这两个句子的相似程度
注意 N-Gram 是指连续的 token 序列,不是单纯的字母、单词、字
- 英文: “playing”可以切分为
["play", "##ing"], “unstoppable”可以切分为["un", "##stop", "##able"] - 中文: 孙悟空三打白骨精,可能是白骨精是一个 gram
而 token 如何划分,则由 tokenizer 决定,例如:WordPiece、BPE、SentencePiece 等。
总结:
1. N-Gram 是一种基于统计的语言模型, 通过统计连续 token 序列的条件概率, 利用前 N-1 个 token 预测下一个 token。
2. Bag-of-Words 是一种基于词频统计的文本表示方法, 不考虑词序, 常用于文本分类和相似度计算。
2. Word2Vec:CBOW模型和Skip-Gram模型
Word2Vec(Word to Vector)是一种词向量学习算法,通过上下文预测任务学习词的稠密向量表示。其核心思想是:语义相近的词, 其上下文分布也相近,因此在向量空间中会更加接近。
Word2Vec 和 BoW 都属于文本/词表示学习方法,但 BoW 基于词频统计,而 Word2Vec 通过上下文预测学习。在表示结果上,BoW 的 One-Hot 编码是稀疏的,有1 个 1 ,其余都是 0,而 Word2Vec 学习的向量是稠密的,能够捕捉到更多信息。
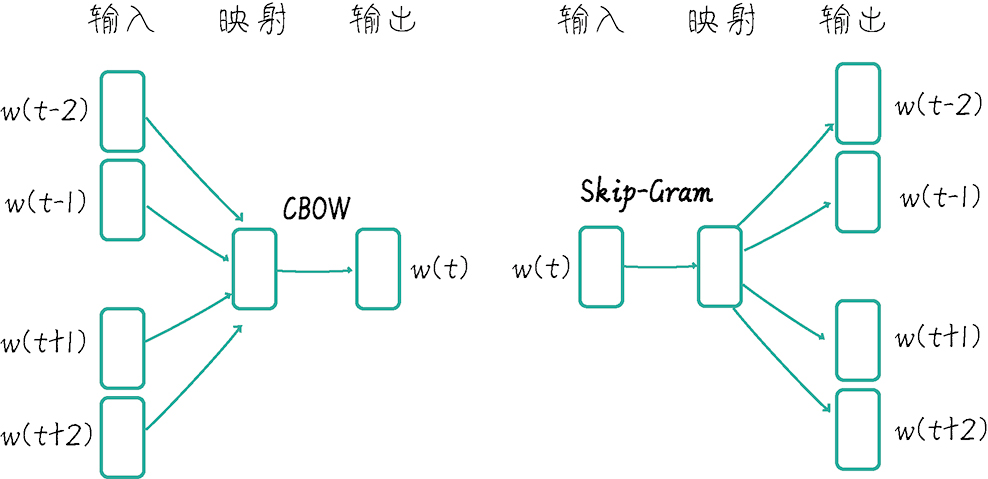
Word2Vec 里主要有两种实现方式:
- Skip-Gram:输入中心词,预测上下文
- Continuous Bag of Words:输入上下文,预测中心词
Skip-Gram 模型示例代码:
# 定义 Skip-Gram 类
import torch.nn as nn # 导入 neural network
class SkipGram(nn.Module):
def __init__(self, voc_size, embedding_size):
super(SkipGram, self).__init__()
# 从词汇表大小到嵌入层大小(维度)的线性层(权重矩阵)
self.input_to_hidden = nn.Linear(voc_size, embedding_size, bias=False)
# 从嵌入层大小(维度)到词汇表大小的线性层(权重矩阵)
self.hidden_to_output = nn.Linear(embedding_size, voc_size, bias=False)
def forward(self, X): # 前向传播的方式,X 形状为 (batch_size, voc_size)
# 通过隐藏层,hidden 形状为 (batch_size, embedding_size)
hidden = self.input_to_hidden(X)
# 通过输出层,output_layer 形状为 (batch_size, voc_size)
output = self.hidden_to_output(hidden)
return output
embedding_size = 2 # 设定嵌入层的大小,这里选择 2 是为了方便展示
skipgram_model = SkipGram(voc_size, embedding_size) # 实例化 Skip-Gram 模型
print("Skip-Gram 模型:", skipgram_model)
CBOW 模型示例代码:
# 定义 CBOW 模型
import torch.nn as nn # 导入 neural network
class CBOW(nn.Module):
def __init__(self, voc_size, embedding_size):
super(CBOW, self).__init__()
# 从词汇表大小到嵌入大小的线性层(权重矩阵)
self.input_to_hidden = nn.Linear(voc_size,
embedding_size, bias=False)
# 从嵌入大小到词汇表大小的线性层(权重矩阵)
self.hidden_to_output = nn.Linear(embedding_size,
voc_size, bias=False)
def forward(self, X): # X: [num_context_words, voc_size]
# 生成嵌入:[num_context_words, embedding_size]
embeddings = self.input_to_hidden(X)
# 计算隐藏层,求嵌入的均值:[embedding_size]
hidden_layer = torch.mean(embeddings, dim=0)
# 生成输出层:[1, voc_size]
output_layer = self.hidden_to_output(hidden_layer.unsqueeze(0))
return output_layer
embedding_size = 2 # 设定嵌入层的大小,这里选择 2 是为了方便展示
cbow_model = CBOW(voc_size,embedding_size) # 实例化 CBOW 模型
print("CBOW 模型:", cbow_model)
实际场景里,input_to_hidden通常使用nn.Embedding. 例子里nn.Linear是通过 one-hot × W1 取出对应行,nn.Embedding则是通过 Embedding 直接索引取出对应行,两者是等价的,只是后者更加高效。
在 Word2Vec(Skip-Gram / CBOW)中,通过“预测词”的训练任务,学习得到参数矩阵 W1,其中每一行就是对应词的向量表示(通常作为词向量使用)。 即词向量不是“直接学出来的目标”,而是“为了完成预测任务而学到的中间表示”。
3. NPLM 和 RNN/LSTM
这一章回到语言模型。
神经概率语言模型(Neural Probabilistic Language Model) 是一种早期神经语言模型。它通过 embedding 将离散 token 转换为连续向量,再通过 MLP(多层感知机)根据前 n_step 个词预测下一个词。
NPLM 和 Word2Vec 都会学习词向量 embedding,但两者目标不同:
- Word2Vec 的核心目标是学习词表示;
- NPLM 的核心目标是预测下一个词(语言建模)。
NPLM 基础流程为:
- 根据语料构建词汇表
- 使用滑动窗口生成训练样本:前 n_step 个词作为输入(input_batch),第 n_step+1 个词作为目标(target_batch)
- 定义 NPLM 模型,由 nn.Embedding 和多个 nn.Linear 组成
- 训练过程中,将 input_batch 输入模型,输出词表上的 logits,并通过 CrossEntropyLoss 计算预测结果与 target_batch 的差距,反向传播不断降低
- 训练完成后,模型可以根据前面的 n_step 个词预测下一个词
对应代码:
import torch.nn as nn # 导入神经网络模块
# 定义神经概率语言模型(NPLM)
class NPLM(nn.Module):
def __init__(self):
super(NPLM, self).__init__()
self.C = nn.Embedding(voc_size, embedding_size) # 定义一个词嵌入层
# 第一个线性层,其输入大小为 n_step * embedding_size,输出大小为 n_hidden
self.linear1 = nn.Linear(n_step * embedding_size, n_hidden)
# 第二个线性层,其输入大小为 n_hidden,输出大小为 voc_size,即词汇表大小
self.linear2 = nn.Linear(n_hidden, voc_size)
def forward(self, X): # 定义前向传播过程
# 输入数据 X 张量的形状为 [batch_size, n_step]
X = self.C(X) # 将 X 通过词嵌入层,形状变为 [batch_size, n_step, embedding_size]
X = X.view(-1, n_step * embedding_size) # 形状变为 [batch_size, n_step * embedding_size]
# 通过第一个线性层并应用 tanh 激活函数
hidden = torch.tanh(self.linear1(X)) # hidden 张量形状为 [batch_size, n_hidden]
# 通过第二个线性层得到输出
output = self.linear2(hidden) # output 形状为 [batch_size, voc_size]
return output # 返回输出结果
使用该模型预测新词,model(input_batch).data 返回一个矩阵: n × m , 其中
n = 样本个数(batch_size)
m = 词汇表大小(voc_size)
矩阵中的元素(i, j) 表示:第 i 个样本 → 预测为第 j 个词的“分数(logit)”
总结:NPLM 是 固定窗口 + 全连接 的.
- 核心思想: 前面 n_step 个词组成一个固定长度特征向量
- 代码: 对前 n_step 个 token 做 embedding,然后 flatten 成一个大向量, 再送入 MLP(Linear)。n_step 决定了能利用的前面词的个数,因此无法处理长距离依赖。也是固定窗口(n_step)和全连接(flatten)的由来
- 形状变化:\( [\text{batch_size}, n_{step}] \rightarrow [\text{batch_size}, n_{step}, e] \rightarrow [\text{batch_size}, n_{step} \times e] \rightarrow \text{Linear层} \)
循环神经网络(Recurrent Neural Network)可以看作一个具有“记忆”的神经网络,RNN 通过 hidden state 递归传递历史信息, 从而支持变长序列(NPLM 里固定 n_step)。之所以叫做循环,是指当前时间步会使用上一个时间步的隐藏状态(hidden state)作为输入的一部分。
但普通 RNN 仍然存在长期依赖困难, 因此后来出现了 LSTM。
这里使用 LSTM 作为 RNN 的一种实现:
import torch.nn as nn # 导入神经网络模块
# 定义神经概率语言模型(NPLM)
class RNNLM(nn.Module):
def __init__(self):
super(RNNLM, self).__init__() # 调用父类的构造函数
self.C = nn.Embedding(voc_size, embedding_size) # 定义一个词嵌入层
# 用 LSTM 层替代第一个线性层,其输入大小为 embedding_size,隐藏层大小为 n_hidden
self.lstm = nn.LSTM(embedding_size, n_hidden, batch_first=True)
# 第二个线性层,其输入大小为 n_hidden,输出大小为 voc_size,即词汇表大小
self.linear = nn.Linear(n_hidden, voc_size)
def forward(self, X): # 定义前向传播过程
# 输入数据 X 张量的形状为 [batch_size, n_step]
X = self.C(X) # 将 X 通过词嵌入层,形状变为 [batch_size, n_step, embedding_size]
# 通过 LSTM 层
lstm_out, _ = self.lstm(X) # lstm_out 形状变为 [batch_size, n_step, n_hidden]
# 只选择最后一个时间步的输出作为全连接层的输入,通过第二个线性层得到输出
output = self.linear(lstm_out[:, -1, :]) # output 的形状为 [batch_size, voc_size]
return output # 返回输出结果
总结: RNN/LSTM 语言模型是基于递归状态传递的序列建模
- 核心思想: 当前 token + 历史 hidden state 逐步更新上下文表示。注意区别,不再是“完整无损地保存所有 token”,而是整个历史的压缩表示
- 代码:按时间顺序逐 token 输入, hidden state 递归携带历史信息, 最后使用最后时间步 hidden state 预测下一个词
- 形状变化:\( [\text{batch_size}, n_{step}] \rightarrow [\text{batch_size}, n_{step}, e] \rightarrow [\text{batch_size}, n_{step}, h] \rightarrow [\text{batch_size}, h] \rightarrow \text{Linear层} \)
- 循环(Recurrent)的含义:当前时间步会使用上一个时间步的隐藏状态(hidden state)作为输入的一部分
当然,因为 token_t 依赖 token_(t-1),RNN/LSTM 无法像 Transformer 那样完全并行计算, 这也是 Transformer 希望解决的问题: 既提升并行计算能力, 又增强长距离依赖建模能力。