这篇笔记主要记录:
- 注意力机制中的 Q K V: 注意力机制中的 QKV 代表了什么以及为什么.
- 多头注意力、掩码: 多头注意力使用多个子空间捕捉不同的特征;掩码则手动把不需要关注的信息权重设为近似“0”
1. 注意力机制中的 Q K V
以Seq2Seq及点积注意力第 3 节的流程图为例: rnn_output → Query,enc_output → Key,enc_output → Value
逻辑上这么理解:
- Query: 找什么,作为搜索条件
- Key: token 用于被匹配的特征
- Value: 需要读取的信息,即内容
我读到这里时,最大的困惑是 Key Value 既然含义不同,怎么还都能用 enc_output 表示?这里还是例子为了入门简化带来的误解。实际情况 QKV 是由经过不同的矩阵变换得到的,所以才能够表述上述不同的特征。
QKV 变换的过程:
- \( QK^T \) 得到相似度分数(raw scores / raw weights)
- softmax(raw_weights) 得到注意力权重(attention weights): \( \text{attn} = \text{softmax}(QK^T) \)
- attn_weights @ V 得到新的上下文表示(context vector / attention output): \( \text{output} = \text{attn} \cdot V \)
整体公式(省略缩放因子 \( \sqrt{d_k} \) 以简化表达):
\[\text{Attention}(Q, K, V) = \text{softmax}(QK^T) \cdot V\]假定初时形状: \( Q.\text{shape} = (\text{batch_size}, Q_y, Q_z) \) \( K.\text{shape} = (\text{batch_size}, K_y, K_z) \) \( V.\text{shape} = (\text{batch_size}, V_y, V_z) \)
那么根据如上过程就存在如下约束:
- \( \text{attn} = \text{softmax}(QK^T) \): attn.shape = (batch_size, Qy, Ky), 要求 \( Q_z = K_z \),即 Q K 的特征维度相同
- \( \text{output} = \text{attn} \cdot V \): 要求 \( K_y = V_y \),即 K V 的序列长度维度相同
如果 QKV 来自于同一个输入序列,就是自注意力(self-attention)机制,则天然满足 \( Q_y = K_y = V_y \)。
那为什么不直接使用 x,而是要引入 3 个线性层?
比如对应句子: The animal didn’t cross the street because it was tired. 我们需要知道:it -> animal 而不是 street ,但是显然 Embedding 后:x_it x_animal x_street 只是普通向量,没有产生这个联系。
那就会希望 Q K V 能够学出来:
- Q(it) ≈ [正在寻找“可指代对象”, 单数名词, 有生命]
- K(animal) ≈ [单数名词, 有生命, 可被代词指代]
- K(street) ≈ [地点, 无生命]
就可以满足:Q(it) · K(animal) >> Q(it) · K(street)
同时希望 V 能学到:V(animal) ≈ [动物语义, 生物属性, 主语信息, 上下文信息]
Q K V 不同,所以即使是相同来源,也要经过不同的变换,使得矩阵能够学到不同的特征。
2. 多头注意力、掩码
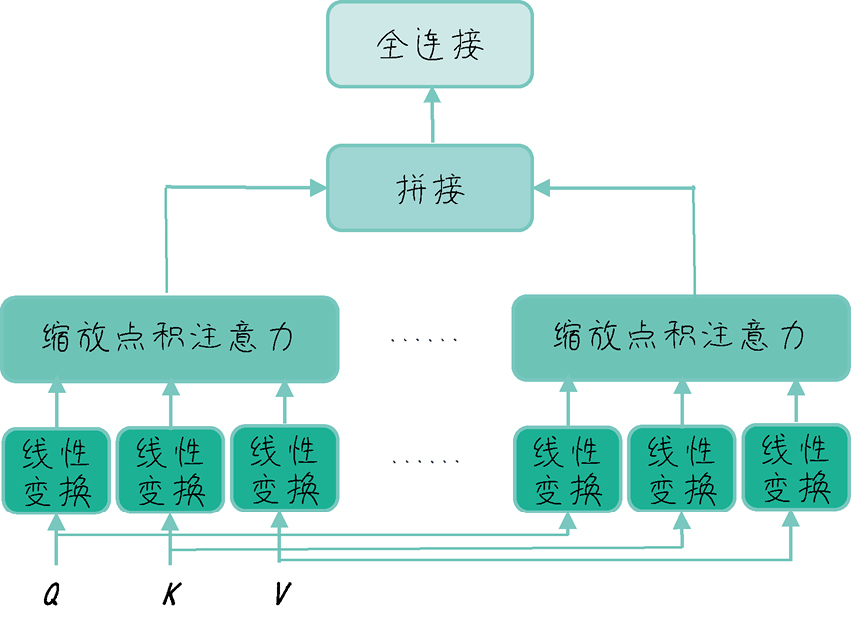
多头注意力,就是先分成多个子空间再合并。其中每个子空间有单独的 QKV,本质上还是刚才的注意力代码。
我的疑问是为什么不是一个空间更高维度,而是多个子空间?
关于这点没有实战经验,chatgpt 的解释我觉得还是可以说通的:
- 不同子空间,容易衍生出不同的 attention matrix,直白的理解就是能从不同角度学习
- 过高维度不容易梯度优化
当然也可能出现多个子空间最后都学成一样的情况,叫做 attention head collapse,但通常不会,因为初始参数完全是随机的。
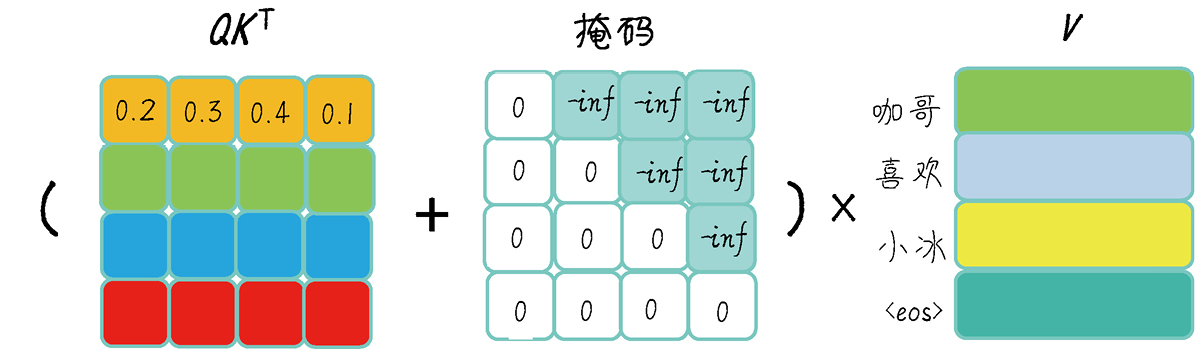
掩码,则是把不需要关注的信息权重设为近似”0”
为什么这么做? 有些位置不重要,比如 <pad> ,可能也还有其他 mask
怎么做的::在 softmax 前人为降低某些位置分数(接近负无穷),softmax 后接近 0
我理解使用矩阵有两个原因:多种 mask 相加方便、矩阵计算适合张量并行优化