这篇笔记介绍下写入和读取过程,前面已经铺垫了很多基础组件,写入介绍起来相对简单一些了。
1. Put
先用一张图片介绍下:
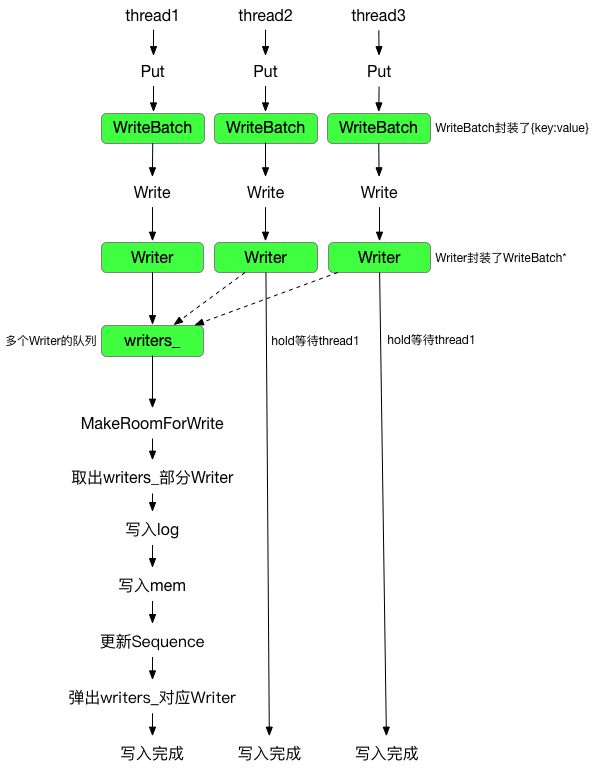
写入的key value首先被封装到WriteBatch
// Default implementations of convenience methods that subclasses of DB
// can call if they wish
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
//key,value数据更新到batch里
batch.Put(key, value);
return Write(opt, &batch);
}
WriterBatch封装了数据,DBImpl::Writer则继续封装了 mutex cond 等同步原语
// Information kept for every waiting writer
struct DBImpl::Writer {
Status status;
WriteBatch* batch;
bool sync;
bool done;
port::CondVar cv;
explicit Writer(port::Mutex* mu) : cv(mu) { }
};
写入流程实际上调用的是DBImpl::Write
//调用流程: DBImpl::Put -> DB::Put -> DBImpl::Write
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
//一次Write写入内容会首先封装到Writer里,Writer同时记录是否完成写入、触发Writer写入的条件变量等
Writer w(&mutex_);
w.batch = my_batch;
w.sync = options.sync;
w.done = false;
数据被写入到writers_,直到满足两个条件:
- 其他线程已经帮忙完成了
w的写入 - 抢到锁并且位于
writers_首部
MutexLock l(&mutex_);//多个线程调用的写入操作通过mutex_串行化
writers_.push_back(&w);
//数据先放到queue里,如果不在queue顶部则等待
//这里是对数据流的一个优化,wirters_里Writer写入时,可能会把queue里其他Writer也完成写入
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
//如果醒来并且抢到了mutex_,检查是否已经完成了写入(by其他Writer),则直接返回写入status
if (w.done) {
return w.status;
}
接着查看是否有足够空间写入,例如mem_是否写满,是否必须触发 minor compaction 等
// May temporarily unlock and wait.
Status status = MakeRoomForWrite(my_batch == nullptr);
取出writers_的数据,统一记录到updates
uint64_t last_sequence = versions_->LastSequence();//本次写入的SequenceNumber
Writer* last_writer = &w;
if (status.ok() && my_batch != nullptr) { // nullptr batch is for compactions
//updates存储合并后的所有WriteBatch
WriteBatch* updates = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);
//WriterBatch写入log文件,包括:sequence,操作count,每次操作的类型(Put/Delete),key/value及其长度
status = log_->AddRecord(WriteBatchInternal::Contents(updates));
bool sync_error = false;
if (status.ok() && options.sync) {
//log_底层使用logfile_与文件系统交互,调用Sync完成写入
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
//写入文件系统后不用担心数据丢失,继续插入MemTable
if (status.ok()) {
status = WriteBatchInternal::InsertInto(updates, mem_);
}
写入完成后,逐个唤醒等待的线程:
//last_writer记录了writers_里合并的最后一个Writer
//逐个遍历弹出writers_里的元素,并环形等待write的线程,直到遇到last_writer
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal();
}
if (ready == last_writer) break;
}
// Notify new head of write queue
// 唤醒队列未写入的第一个Writer
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
2. Sequence
批量写入接口DB::Write(const WriteOptions& options, WriteBatch* updates)调用也是DBImpl::Write。
批量写入一个典型问题就是一致性,例如这么调用:
leveldb::WriteBatch batch;
batch.Put("company", "Google");
batch.Put(...);
batch.Delete("company");
db->Write(write_option, &batch);
我们肯定不希望读到company -> Google这个中间结果,而效果的产生就在于sequence:versions_记录了单调递增的sequence,对于相同 key,判断先后顺序依赖该数值。
写入时,sequence递增的更新到 memtable,但是一次性的记录到versions_:
uint64_t last_sequence = versions_->LastSequence();//本次写入的SequenceNumber
...
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);
...
versions_->SetLastSequence(last_sequence);
对于Get操作(参考本文 Get 一节),看到的 sequence 只有两种可能:
<= last_sequence>= last_sequence + Count(updates)
因此读取时不会观察到中间状态。
3. WriteBatch
第一节介绍,写入的key/value数据,都记录到了WriteBatch,更具体的,记录到了:
//rep_存储了所有Put/Delete接口传入的数据
//按照一定格式记录了:sequence, count, 操作类型(Put or Delete),key/value的长度及key/value本身
std::string rep_; // See comment in write_batch.cc for the format of rep_
rep_数据组织如下:
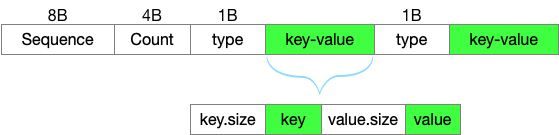
4. Get
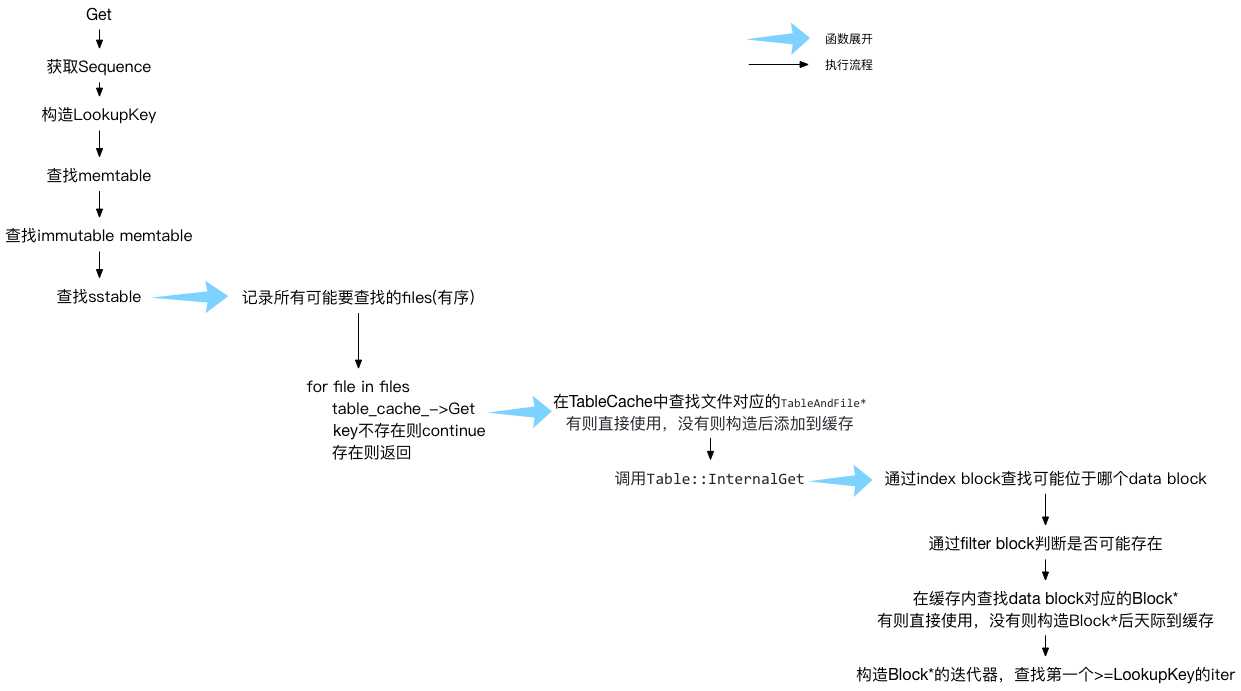
读取分为 snapshot 读和普通读取,两者的区别只是前面介绍的 sequence 不同。
按照mem -> imm -> sstable files的顺序读取,读不到则从下一个介质读取。因此 leveldb 更适合读取最近写入的数据。
// Unlock while reading from files and memtables
{
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
// 查找时需要指定SequenceNumber
LookupKey lkey(key, snapshot);
//先查找memtable
if (mem->Get(lkey, value, &s)) {
// Done
//再查找immutable memtable
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
// Done
} else {
//查找sstable
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
mutex_.Lock();
}
GetStats则记录了第一个 seek 但是没有查找到 key 的文件,之后major compaction之筛选文件会用到。
struct GetStats {
FileMetaData* seek_file;
int seek_file_level;
};
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction();
}
用一张图来表示流程的话: