最近由于工作原因,又重新接触了一番数据湖。如果按照英文直译,数据湖(DataLake)是一个非常早的概念,在 Data Lake Wiki1里引用的最早一篇文章是Pentaho 的创始人兼 CTO James Dixon 发表的这篇博客:《Pentaho, Hadoop, and Data Lakes》2,发表在 2010 年。
而最近两年数据湖的文章,明显多了起来。这篇文章记录下我对数据湖的理解。
1. 流批一体
提到数据湖,就不得不说流批一体。刚接触大数据的时候,常听到的一个名词就是「流批一体」。背景可以用这样一张图表示:
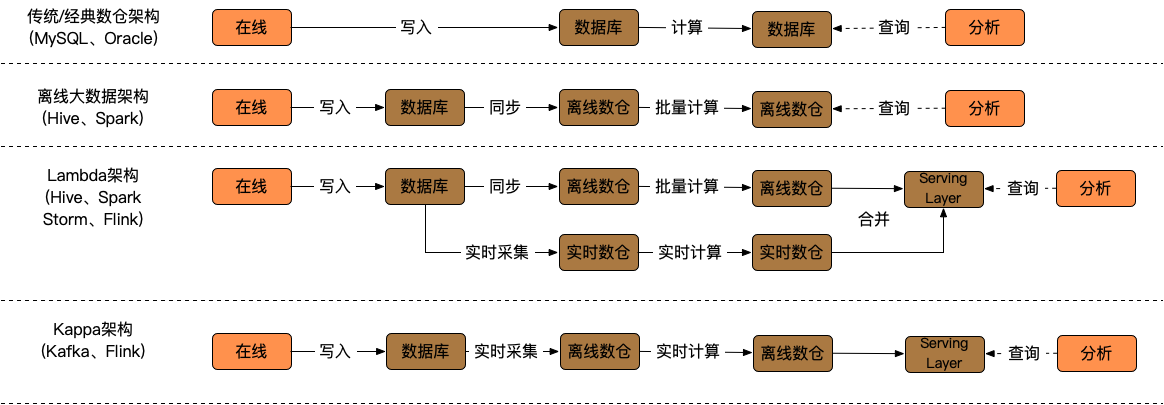
最传统的数仓架构,其实也是最简单、最经典的。
随着数据量变大、时效性需求不同,逐步衍生出了后续的几种架构,当然,链路也更加复杂。复杂的链路自身,在如何保障准确性、一致性、可观测性时,又会衍生出一系列新的问题。
当面对 Lambda 架构时,「流批一体」的设想就变的非常自然:如果只有一条链路,没有一致性的问题,那该多么美好?
在《流批一体技术在天猫双11的应用》3里提到了是这么实现流批一体的:
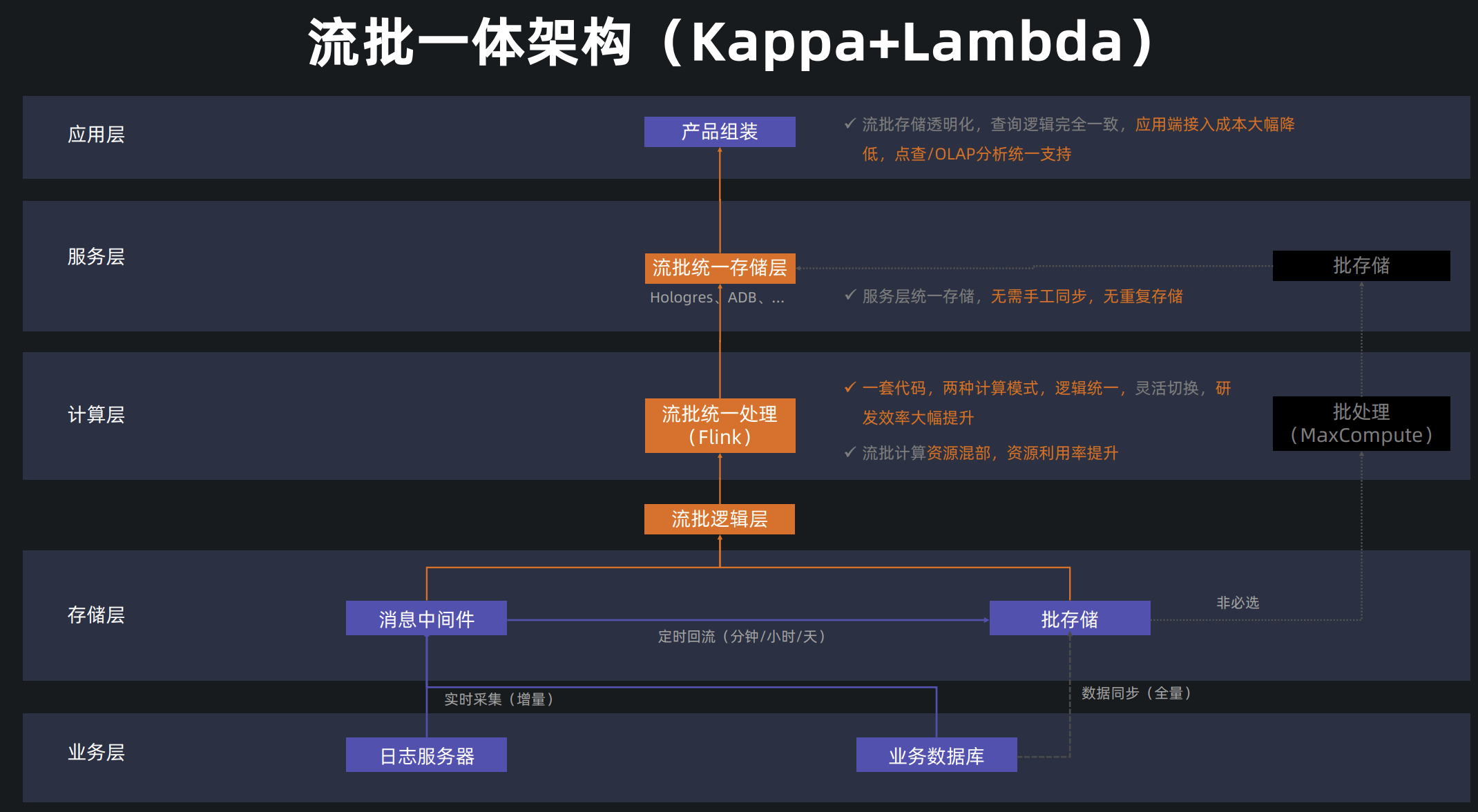
也就是一套代码可以灵活解释为两种执行模式,底层不同的存储在逻辑层做了统一。
还有一个类似的案例是《流批一体在京东的探索与实践》4:
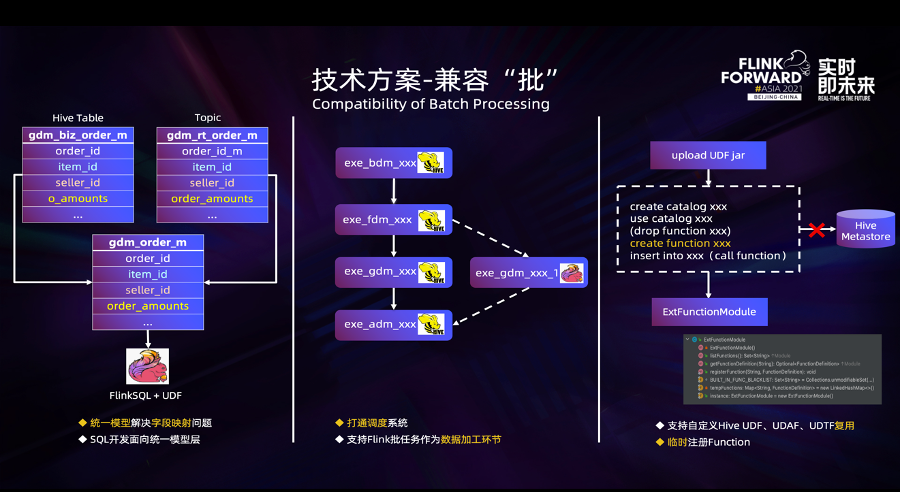
可以看到这类探索和应用的核心,是引入统一的逻辑表、SQL面向逻辑表开发的思路。只需要一套 SQL,开发效率自然高了。但是会有两个疑问:
**1. 统一逻辑层的困难:面对不同计算模型(全量/增量)、不同存储(Kafka/Hive)时,底层所有表是否能够统一? **
**2. 底层终究是两条链路,链路自身的复杂度还在 **
回过头去看的话,Kappa 架构的提出,也是源于对 Lambda 架构重复计算的质疑:Questioning the Lambda Architecture5.其思路不是依赖逻辑表,而是统一存储解决,只是从成本、吞吐上,Kafka 都不是 Kappa 架构下的理想存储。
同时,需要注意的是,现实场景并不是所有公司都需要一套 SQL 在实时、离线灵活切换。对于中小公司,与其花上一年构建这样一套复杂度变高(引入了逻辑层)的架构,还不如有临时需求时让员工 996 上几天完成。当无法判断这类需求的多少时,收益就不明显,是一个非常现实的问题。
2. 数据湖是什么
2.1. 数据湖的历史
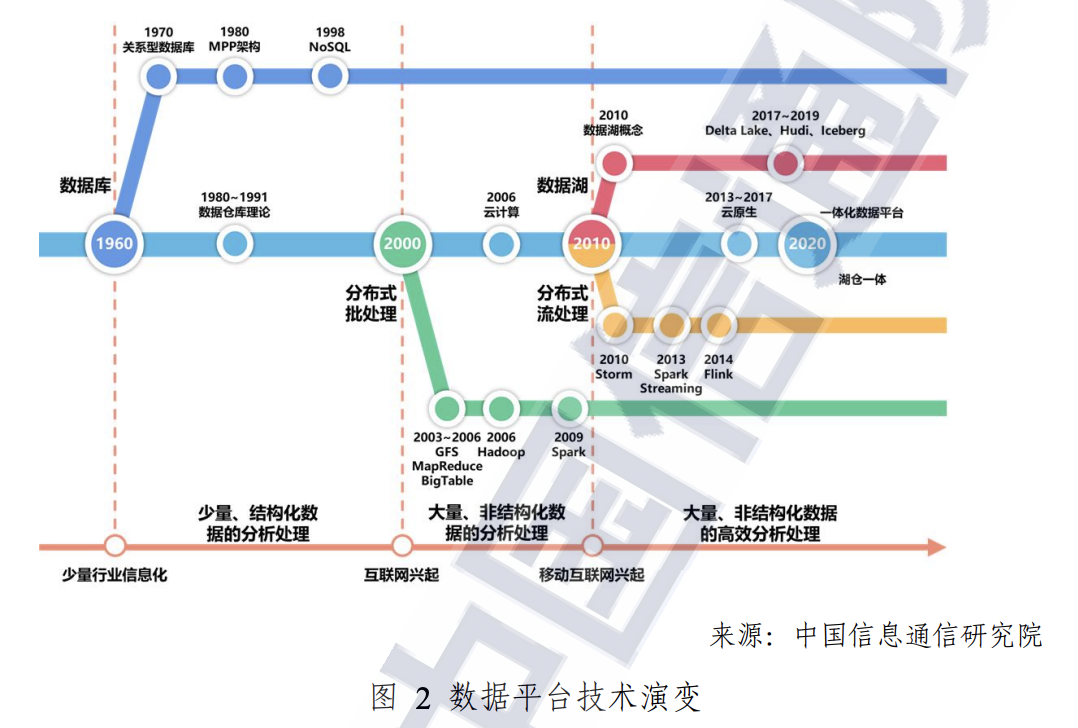
让我们再扯远一点看看大数据的历史,Hadoop Releases6是在 2008 年,《Pentaho, Hadoop, and Data Lakes》这篇文章提出 Data Lake 是在 2010 年,提出 Data Lake 目的或多或少是为了推广自家的 Hadoop.
那个阶段数据湖的定位更多是在 ODS 层。
从2010年开始,业界逐渐将ODS、采集的日志以及其他存放在Hadoop上的非结构或半结构化数据统称为数据湖
所以数据湖和数据仓库,在当时主要是设计理念的区别:数据湖(Hadoop)有能力并且希望存储更多半结构、非结构化数据来支持更多场景,数据仓库希望数据是结构化的、规范、统一的 Schema。
那时候 AI 场景需求不多,再加上不限制的数据接入只会导致数据沼泽的出现,因此数据湖提的并不多。
发展到现在,背景悄然发生了变化:
- Hadoop 早已成为了大数据的标配
- 在存算分离的思想下,AWS S3 成为存储的新宠,而且相比 HDFS 成本更低
- 国内云厂商也都有了类似 S3 的对象存储服务
中国信通院 2021 年发布的大数据白皮书8里,清晰的描述了 2010 年之后数据湖以及背景的变化:
Google Cloud 是这么定义9数据湖的:
数据湖提供了一个可伸缩的安全平台,使企业能够:以任何速度从任何系统中提取任何数据,无论数据来自本地、云还是边缘计算系统;以全保真的方式存储任何类型或数量的数据;实时或批量处理数据;使用 SQL、Python、R 或任何其他语言、第三方数据或分析应用分析数据。
AWS 也是类似10:
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
因此,数据湖随着背景发生了几处变化:
- 部署在低成本的对象存储而不是 Hadoop 上11,不再仅作为数仓 ODS 层,而是参与以及重塑数仓的构建过程
- 随着云厂商的加入和支持,基于数据湖能够提供更多、更全的解决方案(数据存上去了,实时/离线/各种时效性计算能力)
- 随着 AI 场景的需求增多,保存全部的数据变的更加有意义
比如 AWS 数据湖的介绍:
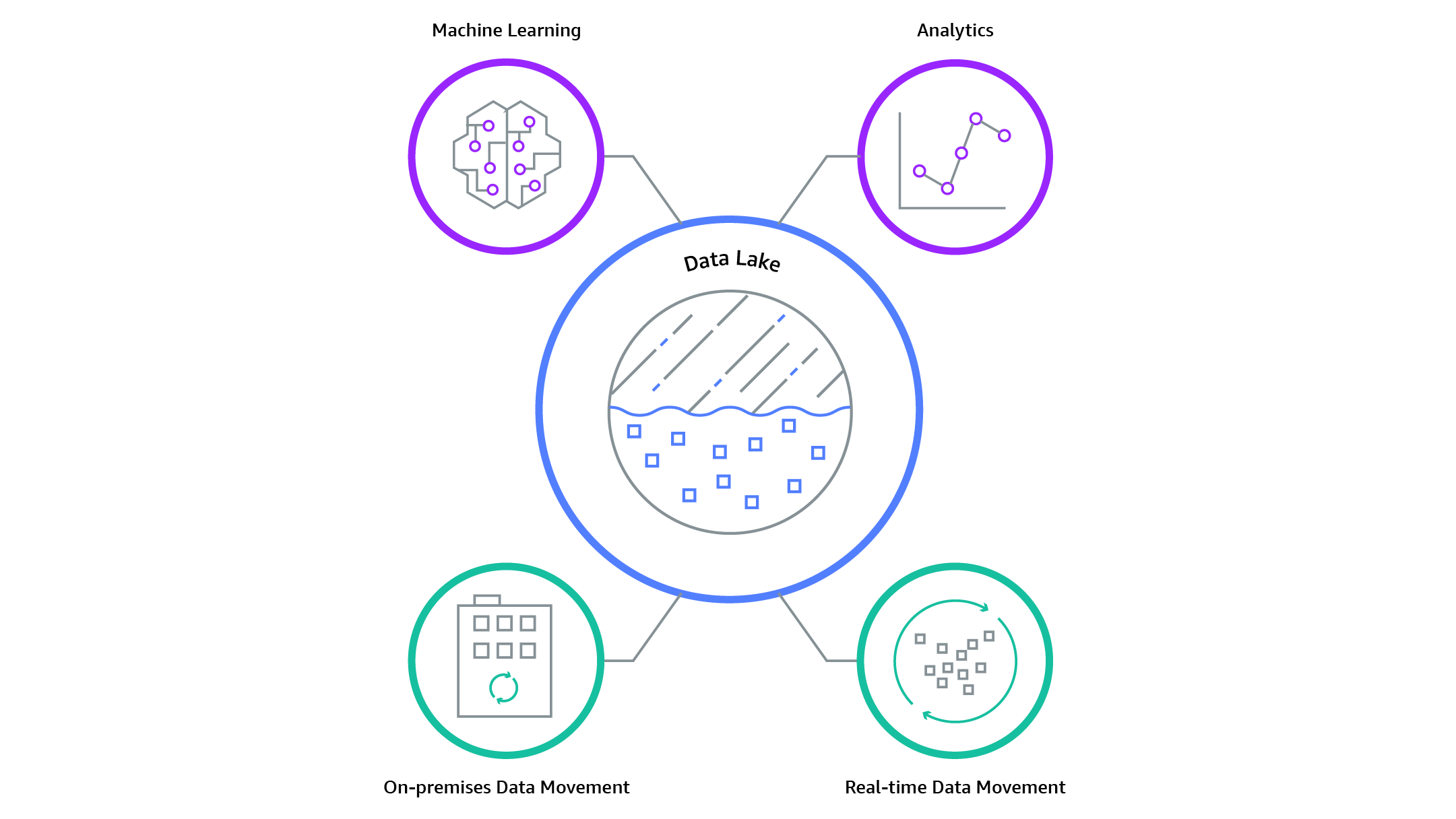
一个公司的数据,在当下早已不只是服务于 BI,而是 AI + BI。当数据湖支持存储更多原始数据,同时构建数仓的计算引擎(Spark Flink),都开始提供自己的 MLLib,数据湖也就有了提供 Machine Learning 的能力。
注:相比数仓的 Schema 管控,引入原始数据支持 AI 会让数据治理变的更加复杂,当然如何避免数据沼泽又是另外一个话题了。
2.2. 数据湖 VS 数据仓库之争 => 湖仓一体
数据湖的理念超前,但在当前,传统数仓才是决定了数据对于企业的价值。个人觉得这两年数据湖突然又变的热门,是因为数据湖开始逐步有能力重塑数仓。
上半年的时候看过一篇文章《数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体》12,当时看了一半看不下去,感觉就是阿里云在推销自己的云产品。今天重新阅读,才感觉是一篇深度总结的文章。
湖仓一体,是数据湖重新热门的原因
- 数仓支持数据湖访问
- 数据湖支持数仓能力
当然,这个理念就像「流批一体」一样,怎么落地并不具体,同时也难免要跟随云厂商的步伐。文章提到核心要解决三个问题:
- 湖和仓的数据/元数据无缝打通,且不需要用户人工干预
- 湖和仓有统一的开发体验,存储在不同系统的数据,可以通过一个统一的开发/管理平台操作
- 数据湖与数据仓库的数据,系统负责自动caching/moving,系统可以根据自动的规则决定哪些数据放在数仓,哪些保留在数据湖,进而形成一体化
我的理解:
- Hive 的元数据存储在 metastore,而湖,比如阿里的 Delta ,元数据存储在 DLF。元数据问题的背后,还有权限、分区等问题。
- 真的能有统一的开发体验么?统一开发体验,湖的优势还能应用到么?在应用时,对哪些字段建 Z-Order、如何管理 Z-Order 任务?如何避免湖的成本,能控制在实时、离线的成本中间,并能满足不同的时效性要求?
- 这个系统是临时的,还是一直存在的?
3. 数据湖干什么
既然数据湖如今最为人看中的还是数据湖支持数仓能力,那具体的,数据湖究竟能干什么?
要回答这个问题,我重新去看了 Hudi Delta 的背景
3.1. Hudi
云、中台、大数据-读《云原生数据中台:架构、方法论与实践》这篇笔记里,也提到了 Uber 为什么依赖 Hudi 搭建了第三代大数据平台:
- HDFS 的可扩展性:这个对应了前面提到的更低成本、扩展性更高的云存储
- Hadoop 的数据需要快速更新:更多的时效性场景,目前大部分公司都是 T+1 或者实时这两种极端,没有一个中间态
- 支持 Hadoop 数据的更新和删除:避免 Merge 文件
- 更快的 ETL 构建过程
3.2. Delta
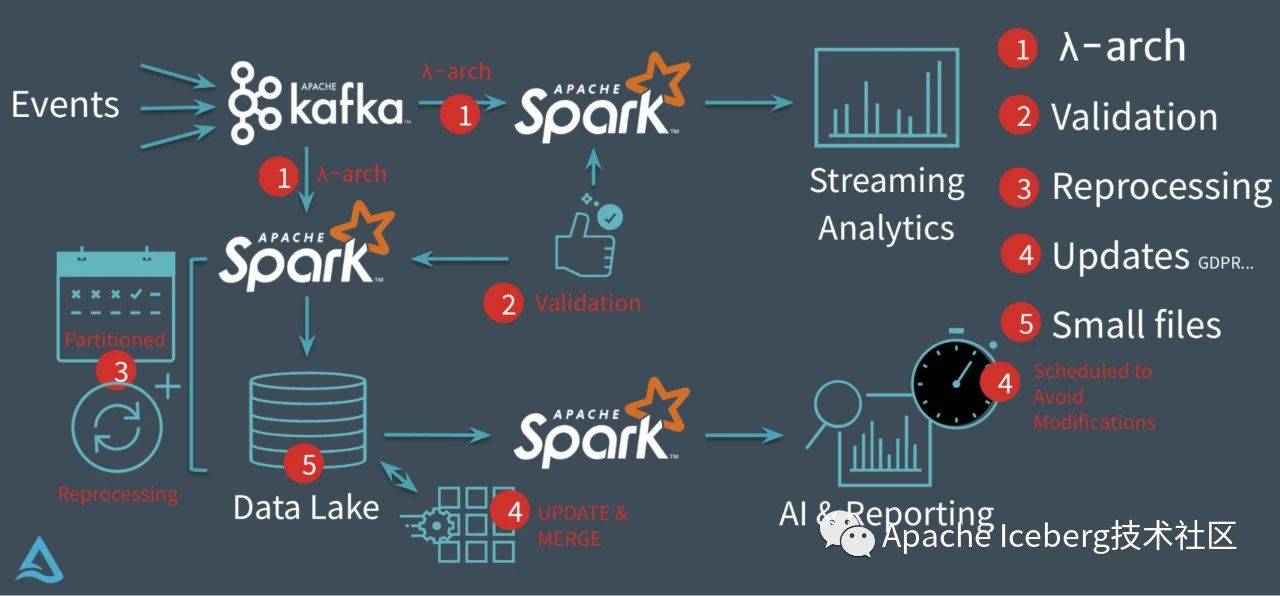
DataBricks 开发 Delta 是源于客户常见的四个问题:
- Lambda 架构下的重复计算
- 数据校验
- 如何刷历史数据
- 数据如何快速更新
3.3. 总结
在国内的应用上,揭秘|字节跳动基于Hudi的数据湖集成实践13里,典型的两个 UserCase 是


这两种场景重点应用了两点,一个是加速构建,即 Upsert 的能力;另一个加速查询:元数据加速、bucket/zorder 加速。但是个人经验上看,在生产实践上,这两个能力都还不够易用,例如文章里提到的:
比如我们未来计划将查询的谓词直接下推到元数据系统当中,让这个引擎在scan阶段无需访问系统,直接去跳过无效文件来提升查询的性能。
那我们接下来计划将这个数据湖加速服务不断地去打磨成熟,用来做实时数据的交换和热数据的存储,以解决分钟级到秒级的最后一公里问题。智能加速层面临的最大的挑战是批流数据写入的一致性问题,这也是我们接下来重点要解决的问题。例如在这种端到端的实时生产链路中,如何在提供秒级延时的前提下解决类似于跨表事务的问题。
同时我们接下来也会非常注重二级索引的支持,因为二级索引的支持可以延伸湖上数据的更新能力,从而去加速非主线更新的效率
我们接下来会通过一套表优化服务来实现智能优化,因为对于两个类似的查询能否去提供一个稳定的查询性能,表的数据分布是一个关键因素。而从用户的角度来看,用户只要查询快、写入快,像类似于compaction或clustering、索引构建等一系列的表优化的方式,只会提升用户的使用门槛。而我们的计划是通过一个智能的表优化服务分析用户的查询特征,去同时监听这个数据湖上数据的变化,自适应的去触发这个表的一系列的优化操作,可以做到在用户不需要了解过多细节的情况下,做到智能的互加速。
这些问题会造成在非典型技术驱动公司里难以大规模推广使用,而这些瓶颈突破前,湖仓一体或许只会造成不湖不仓的尴尬局面。
这里值得一提的是 ZOrder,原理参见之前的笔记14。笔者所在的公司也有自行实现的,虽然易用性、效果加速上都比数据湖较差,但是定向场景解决,反而可以忽略上述这些问题。虽然前面没有提及,但是之后 Z-Order、BloomFilter、二级索引这些技术,是否又会发展成为数据的基础底座之一?
从后端转到大数据以来,感觉大数据总是在出一些新的概念,比如低代码平台,也是在这两年重新流行起来,是美好生活之路还是托拉拽重现江湖16?
总结来看的话,使用云存储替换 HDFS 势在必行,另外比较好的应用点是多时效性场景的需求,例如分钟级时效性、Kappa 架构的中间层实时查询等,但是无论对于实时(Kafka)谈流批一体,还是离线(Hive)谈湖仓一体,个人感觉还不成熟。
参考资料
- Data Lake Wiki
- James Dixon’s Blog
- 流批一体技术在天猫双11的应用
- 流批一体在京东的探索与实践
- Questioning the Lambda Architecture
- Hadoop Releases
- 《云原生数据中台:架构、方法论与实践》
- 中国信通院 大数据白皮书-2021
- 什么是数据湖?
- 数据湖是什么_数据湖和数据仓库的差别_数据湖架构-AWS云服务
- 抛弃 Hadoop,数据湖才能重获新生
- 数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体
- 揭秘 - 字节跳动基于Hudi的数据湖集成实践
- 干货 - 实时数据湖在字节跳动的实践
- 数据湖笔记之一:Z-Order
- 低代码平台