上篇笔记介绍了 Checkpoint 相关的代码, 关于源码的分析网上文章很多,通过断点调试也能大概了解 Checkpoint 的实现。
Checkpoint 的原理,在 Lightweight Asynchronous Snapshots for Distributed Dataflows 里有系统的描述,思路来源于最开始的这篇文章:Chandy-Lamport algorithm,没错,就是发明 Paxos 算法的那位。
这篇笔记希望以简单易懂的方式介绍下我理解的 why checkpoint 以及解决思路。
1. Why
存储系统里的 snapshot,记录的是某个时间点存储的状态,存储可以恢复到这个时间点,用户也可以指定读取这个时间点时的存储内容。不同的 snapshot 可以用时间戳区分,也可以用版本的逻辑概念,比如leveldb compact 的 version.
流式计算系统里的 snapshot 同样记录了某个时间点系统里所有参与者的状态,同样的,系统可以恢复到这个时间点,用户也可以指定读取这个时间点各个参与者的状态。不过相比于存储系统在写入数据时可以由 leader 确定时间戳(版本),流式系统的各个参与者无法共享一个全局的时间戳,正如 Lamport 的论文里提到的:
We assume that processes do not share clocks or memory. The problem is to devise algorithms by which processes record their own states and the states of communication channels so that the set of process and channel states recorded form a global system state.
先从简单的场景出发,一步步说明 checkpoint 要解决的问题是什么。
1.1. 单机单线程
先忘掉流式计算、分布式系统里的各个复杂的名词,假定我们实现了一个单机单线程的程序,读取 Kafka 的数据,经过计算后写入下游存储。
线程顺序调用 3 个方法: Read Process Write,随着时间推进,线程处理数据的状态:
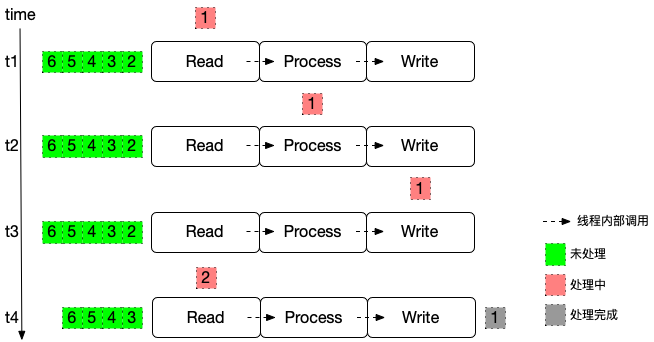
Read Process Write 虽然是不同的方法,但是都在同一个线程执行,这种情况下要保证数据不丢,基于以下两个前提条件并不复杂:
- 同一时刻只在处理一条数据
- Write 写入完成后,线程可以调用 Read 里的对象记录 offset:“记录”可以是上传到 Kafka 元数据,也可以是持久化到文件系统
这里需要重点考虑的就是避免每处理一条数据就记录一次 offset,那样元数据压力太大,因为存储本身对批处理是更友好的,可以考虑按照时间、数据条数触发。也就是 Stream Process + Batch Snapshot 结合的方式,确保数据不丢(At Least Once)。
注:如果要保证数据不重,也就是 Exactly-once,需要实现二阶段提交End-to-End Exactly-Once Processing in Apache Flink,经验不多不展开说了。
1.2. 多机多进程
随着数据量变大,各个算子需要部署到不同机器上。Read Process Write 不再是在同一个线程里顺序调用,而是通过 RPC 的形式互相访问。为了区别,我们换一个名词 Source Process Sink 来说明下。
虽然在逻辑图上只是把数据流向从线程内部调用修改为RPC访问:
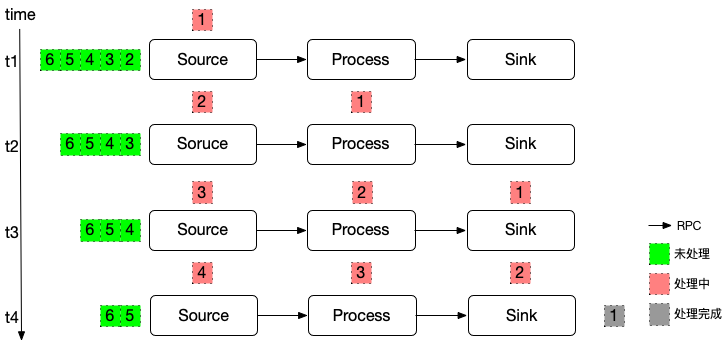
但是问题复杂度明显变高了,对比主要有几个问题:
- 同一时刻不同算子在处理不同的数据:RPC不可避免的会使用网络缓存,不同框架叫做 pool/queue/channal/buffer 的都有,本质上是一回事。Source 在处理元素3的时刻,其他算子在处理不同的N个元素。
- Sink 不清楚如何记录 offset:因为 offset 在数据传输过程中已经丢了。
1.3. 思路1 - 透传offset
关于问题2,一个比较直观的想法是数据应该一直携带着自身的元信息(例如 offset),Sink 负责记录 offset.
数据流形如:
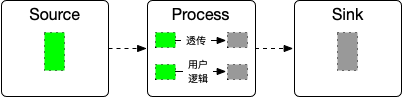
框架层把收到的数据分为两部分,一部分例如 offsets 用于透传,用户不可见;一部分业务字段交给用户逻辑处理。这两部分结果再 merge 成为一个大的数据结构发送到下游算子。当 Sink 算子处理完成该条数据后,记录数据对应的 offset.
这个思路需要考虑几个问题:
- Sink 算子能拿到 offsets,但是还需要构造对应的对象。例如对于 Kafka,还需要构造 KafkaConsumer,依赖 broker.server、topic、group.id、partition 等信息
- Sink 算子处理 offset 的数据后,是否能够说明 offset 之前的数据已经处理完成?
考虑多个实例的情况:
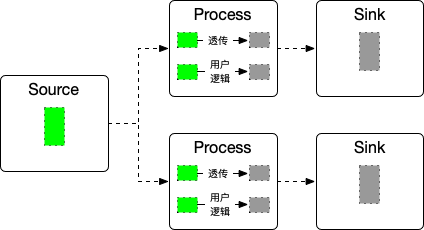
假定 Source 顺序产出了 a b 两条数据,按照图里的拓扑关系,a b 分别发给了上下两个 Sink 实例处理,先处理完成 b。
此时无法上传 offset.那就还需要一个 Coordinator 的角色来判断之前的数据已经处理完成?
以及比如 Process 聚合数据、列转行返回多条数据等的场景如何解决?
1.4. 思路2 - 输入输出持久化
参考一个简化的后端业务架构:
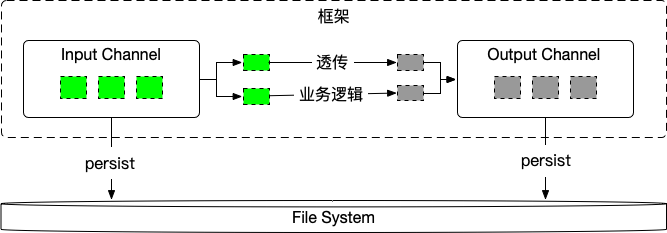
相比思路1,主要是支持所有算子输入输出队列写入到文件系统。
框架封装了 Input/Output,Input 收到数据后反序列化,Output 序列化后发送数据,按照一定的策略持久化。持久化的好处是不丢数据,同时能够打平流量的波峰波谷。一条数据只有下游算子返回对应的 ack 了才能删除。
同样的,数据分为两部分,透传字段例如 logid, traceid 等(类比到这里就是上一节的 offset),业务侧负责实现业务逻辑部分,实现里不需要考虑锁竞争、failover等情况。
注意每一个 Source Process Sink 实例都是这样的结构。
其实对于多个 Flink 作业,我们就是这么串联的,只是把 Input/Output 持久化的目标从文件系统替换为消息队列。但是对一个 Flink 作业内部的多个算子之间,这种方式则略重了些,因为相比内存交换数据,持久化一定会带来性能影响。更轻量级的做法是一层层反压,一直到最初的消息队列。
流式计算,下游堵了,上游就先别放水了。
1.5. 正版思路 - Lightweight Asynchronous Snapshots
思路2有些接近了,只是太暴力,正版思路里算法则非常巧妙。
首先引入 barrier 的概念:

原文解释的非常清楚了:
A core element in Flink’s distributed snapshotting are the stream barriers. These barriers are injected into the data stream and flow with the records as part of the data stream. Barriers never overtake records, they flow strictly in line. A barrier separates the records in the data stream into the set of records that goes into the current snapshot, and the records that go into the next snapshot. Each barrier carries the ID of the snapshot whose records it pushed in front of it. Barriers do not interrupt the flow of the stream and are hence very lightweight. Multiple barriers from different snapshots can be in the stream at the same time, which means that various snapshots may happen concurrently.
我在这里说下我对 barrier 的理解:
- 当需要 checkpoint 时,就在数据流源头某条数据后插入一个 barrier,处理上跟普通数据一样,都是顺序的。通过周期性的注入 barrier,实际上把数据分批了,只是这个是通过数据标记在逻辑上区分而不是像 SPARK 读取了一批数据物理区分。
- 每一个 barrier 会将数据分为两部分:在 barrier 之前的数据,在 barrier 之后的数据
这两条结合起来得到一个结论:当处理到某个 barrier 时,那么该 barrier 之前的数据一定已经处理完成了。
流在某一瞬间的状态,可能会有多个 barrier,主要有两个原因:
- 前面说系统会有很多 on-fly 的数据,barrier 自然也是
- 算子在物理上,可能对应了多个上游,每个上游都会发出 barrier。也就是需要收到所有上游发出来的对应本次checkpoint 的 barriers,数据才是完整的。
因此为了区分,每次 checkpoint 对应的所有 barrier 需要有个共同的 ID
比如对于这里的 Operator,有两个上游实例:

‘1’ ‘e’ 之前的 barrier 是同一次 checkpoint 发出的,因此 ID 相同,当该 Operator 收到相同 ID 的所有 barrier,才表示已经收到了 barrier 之前的全部数据。对应的,当该 Operator 处理完成该 barrier,则表示承诺已经处理完成 barrier 之前的全部数据。这个处理完成,可以是数据都发送到了下游算子/存储,也可以是写入到了文件系统。
当系统里所有 Operator 都承诺已经处理完成 barrier,此时 Source 算子就可以记录该 barrier 之前一条数据对应的 offset,记录完成后意味着整条流的 checkpoint 完成。
相比思路2,可以看到这里的解决方案非常轻量级。
每次 Checkpoint 完成,就意味着产生了流式系统里的一个 snapshot。流式系统可以从任意一个 snapshot 恢复:Source 消费对应 barrier 之后第一条数据,其他算子也从处理该 barrier 之前最后一条数据时恢复,流的整体效果自然也就是从 snapshot 恢复。
因此可以看到整体机制也会依赖于输入的可回溯,正如State Persistence提及的:
For this mechanism to realize its full guarantees, the data stream source (such as message queue or broker) needs to be able to rewind the stream to a defined recent point. Apache Kafka has this ability and Flink’s connector to Kafka exploits this.
2. How
总结下 1.5 里的思路,会有两个比较重要的时机:
- 什么时候触发 checkpoint?
- 是么时候全部算子完成 checkpoint
因此需要引入一个 Coordinator 的角色,自然也就依赖 Master-Worker 的架构。
例如 1.1 里的单线程的情况,按照数据条数触发 snapshot 是有风险的,最后几条数据可能迟迟无法触发 snapshot。如果依赖时间触发,那么就不可避免的需要引入多线程。
单机多线程的解法也不复杂,通过加锁来解决竞争:
lock 的作用就是确保 data + offset 的一致性。
注:这里的风险是避免某个线程迟迟无法获取锁
这个模型在多进程下仍然保持以下条件:
Barriers never overtake records, they flow strictly in line.
串行处理数据本身和 barrier 也就天然规避了锁的问题
3. Implement
每次提到流式系统里的 checkpoint 时,总是绕不开 barrier 这个概念。 通过前面的分析可以看到,如果所有的 operator chain 成为一个 task,也就是同一个进程包含了 Source Process Sink,其实是不需要 barrier 的。
示例代码在参考资料2
3.1. Single Task
env.setParallelism(1)
...
env.addSource(new TestSourceFunction).name("test-source")
.addSink(new TestSinkFunction).name("test-sink")
函数栈的调用关系:
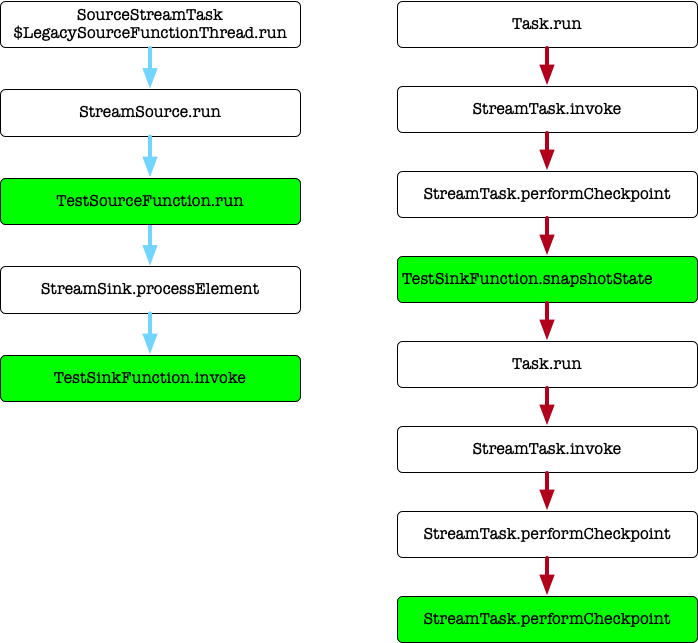
由于 Operator chain 到了一起,Source Sink 处理在同一线程,snapshot在同一线程。
3.2. Multiple Task
env.setParallelism(1)
...
env.addSource(new TestSourceFunction).name("test-source")
.keyBy(i => i)
.addSink(new TestSinkFunction).name("test-sink")
函数栈的调用关系:
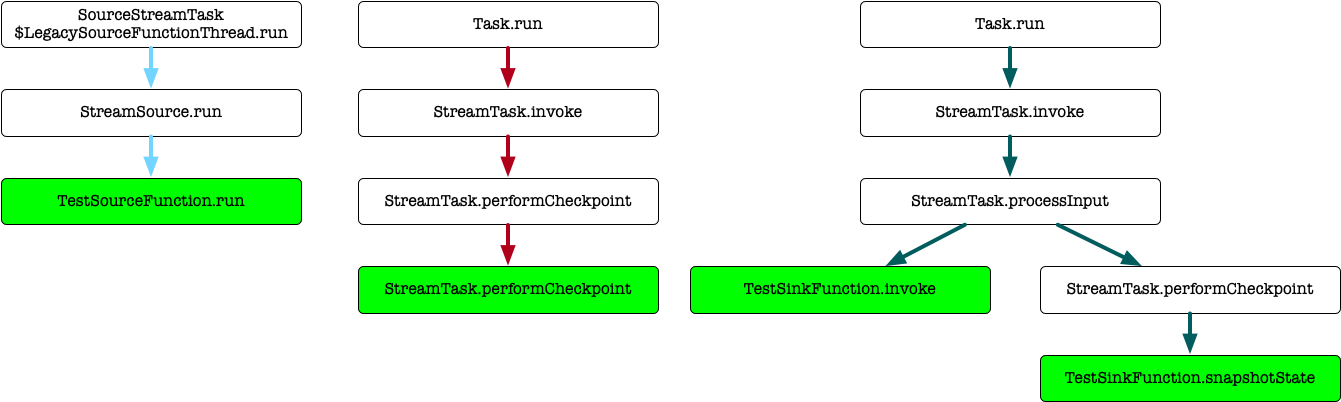
Source Sink没有 chain 到一起,Sink 的处理数据和处理 barrier 在同一线程。processInput方法根据 input 是数据还是 barrier 决定调用方法