1. 容错的必要性
分布式系统使用集群提高了算力,也天然需要面对和解决单机不稳定的问题,比如常说的宕机、掉盘、网络抖动等。
Jeff Dean 多年前在斯坦福有过一个分享1,其中一些数字我觉得应该是架构谨记的:
Typical first year for a new cluster:
- ~1 network rewiring (rolling ~5% of machines down over 2-day span)
- ~20 rack failures (40-80 machines instantly disappear, 1-6 hours to get back)
- ~5 racks go wonky (40-80 machines see 50% packetloss)
- ~8 network maintenances (4 might cause ~30-minute random connectivity losses)
- ~12 router reloads (takes out DNS and external vips for a couple minutes)
- ~3 router failures (have to immediately pull traffic for an hour)
- ~dozens of minor 30-second blips for dns
- ~1000 individual machine failures
- ~thousands of hard drive failures
slow disks, bad memory, misconfigured machines, flaky machines, etc.
Long distance links: wild dogs, sharks, dead horses, drunken hunters, etc.
因此,单机可能存在各种异常,必须依赖软件设计来容错。
2. DolphinScheduler 的容错
DolphinScheduler 采用 Master-Worker 的设计,其中 Master 之间是对等的,这点在官方文档里有说明2,不再赘述。
对等的设计,使得 Master 能够横向扩展,同时在容错能力上,Master 又天然互为主备。
系统容错需要解决的问题有两个:
- 当单个 Master 挂掉时,确保其他 Master 实例能够检测到,接管原工作流。同时避免 split-brain,也就是某个工作流同时被两个 Master 接管。
- 当单个 Worker 挂掉时,确保该 Worker 实例上的任务能够回收(重试或者等待执行完成)。同样的,需要避免某个任务实例同时被两个 Worker 执行。
先说第一个,Master 可以通过监听其他 Master 的状态解决。异常 Master 上的工作流实例,通常有两种处理方式:
- 全部 Master 实例平均分配,比如按照DS工作流的启动里 hash 取模的方式
- 单个 Master 全部接管
1的好处是逻辑保持一致,但是不同 Master 观察到的实例总个数瞬时值不一致,因此不推荐。
2的好处是逻辑简单,需要确保只能有一个 Master 接管,这点可以通过加 failover 锁实现,只有抢到该锁才能接管任务。其他实例则保持抢锁,以避免新接管的 Master 实例在接管过程中异常。YARN、HDFS也都使用了类似的方式以确保高可用3。
Worker 实例异常相对简单,工作流实例状态异常,只要工作流实例对应的 Master 负责 failover 就可以了。
基本思路如图所示:
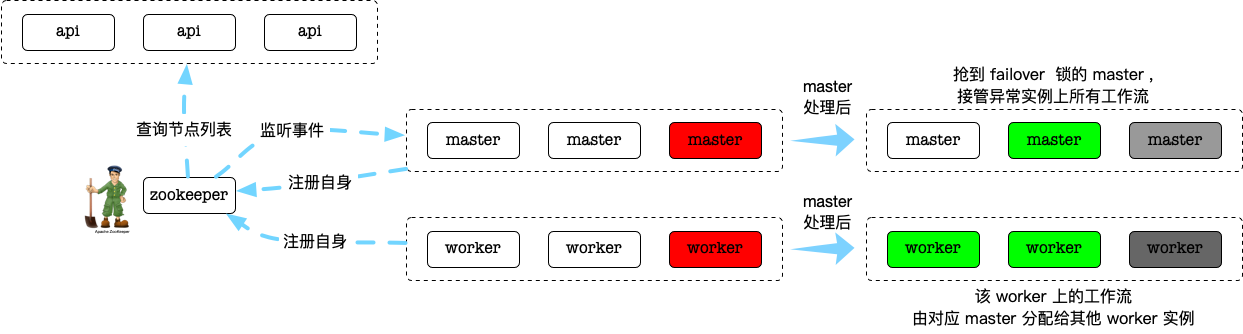
当然这只是一个分布式里通用的容错方式,具体细节比如failover工作流的判断、处理逻辑、如何降低网络抖动对系统的影响等,则是调度系统重要且独有的逻辑,接下来在代码分析时说明。
3. 容错的实现-ZK
容错是通过 ZK 实现的,这也是大部分分布式系统首选的方式,框架使用 Curator4
Master、Worker 启动时,都会注册自身到 ZK,路径为
- /dolphinscheduler/nodes/master
- /dolphinscheduler/nodes/worker
同时 Master 会 watch path=/dolphinscheduler/nodes 。
ZK 在 DolphinScheduler 主要提供了以下能力:
- 服务发现: 例如 API 模块对 worker 分组
- 负载均衡: Master 分发任务时,根据 worker 节点更新的 heartbeat 信息(存储在 value),实现 LowerWeight 的负载均衡方式
- 容错: Master watch zk节点,当发生节点 REMOVE 时,恢复对应模块实例的工作流
核心代码是在RegistryClient,该类在 API、Master、Worker 模块里都有使用。
以 Master 模块为例,MasterServer在启动时:
public class MasterServer implements IStoppable {
@Autowired
private MasterRegistryClient masterRegistryClient;
...
@PostConstruct
public void run() throws SchedulerException {
// self tolerant
this.masterRegistryClient.start();
this.masterRegistryClient.setRegistryStoppable(this);
...
其中MasterRegistryClient封装了RegistryClient,主要有三部分功能:
- 注册
- watch连接状态
- watch节点状态
watch节点状态时,节点变更又分为 Master Worker 两种情况。
3.1. 注册
注册为临时节点,同时单线程不断更新。节点 path 主要用于容错,value 则保存了节点信息用于负载均衡。Master Worker 更新的 Value 分别为:
public class MasterHeartBeat implements HeartBeat {
private long startupTime;
private long reportTime;
private double cpuUsage;
private double memoryUsage;
private double loadAverage;
private double availablePhysicalMemorySize;
private double maxCpuloadAvg;
private double reservedMemory;
private double diskAvailable;
private int processId;
}
public class WorkerHeartBeat implements HeartBeat {
private long startupTime;
private long reportTime;
private double cpuUsage;
private double memoryUsage;
private double loadAverage;
private double availablePhysicalMemorySize;
private double maxCpuloadAvg;
private double reservedMemory;
private double diskAvailable;
private int serverStatus;
private int processId;
private int workerHostWeight; // worker host weight
private int workerWaitingTaskCount; // worker waiting task count
private int workerExecThreadCount; // worker thread pool thread count
}
3.2. watch 连接状态
当检测到 zk 连接断开时,执行清理动作。为了避免网络抖动导致的服务抖动,因此忽略了 Curator 的 SUSPENDED 状态,只需要关注 RECONNECTED/DISCONNECTED.
这一步实现了模块的优雅退出,代码封装在MasterConnectionStateListener、WorkerConnectionStateListener。不过我们不能强依赖该动作,避免模块异常退出时资源没有及时释放。
3.3. watch Master节点状态
Master 实例的容错实现在MasterFailoverService.failoverMaster:
public void failoverMaster(String masterHost) {
String failoverPath = Constants.REGISTRY_DOLPHINSCHEDULER_LOCK_FAILOVER_MASTERS + "/" + masterHost;
try {
registryClient.getLock(failoverPath);
doFailoverMaster(masterHost);
} catch (Exception e) {
LOGGER.error("Master server failover failed, host:{}", masterHost, e);
} finally {
registryClient.releaseLock(failoverPath);
}
}
主要流程:
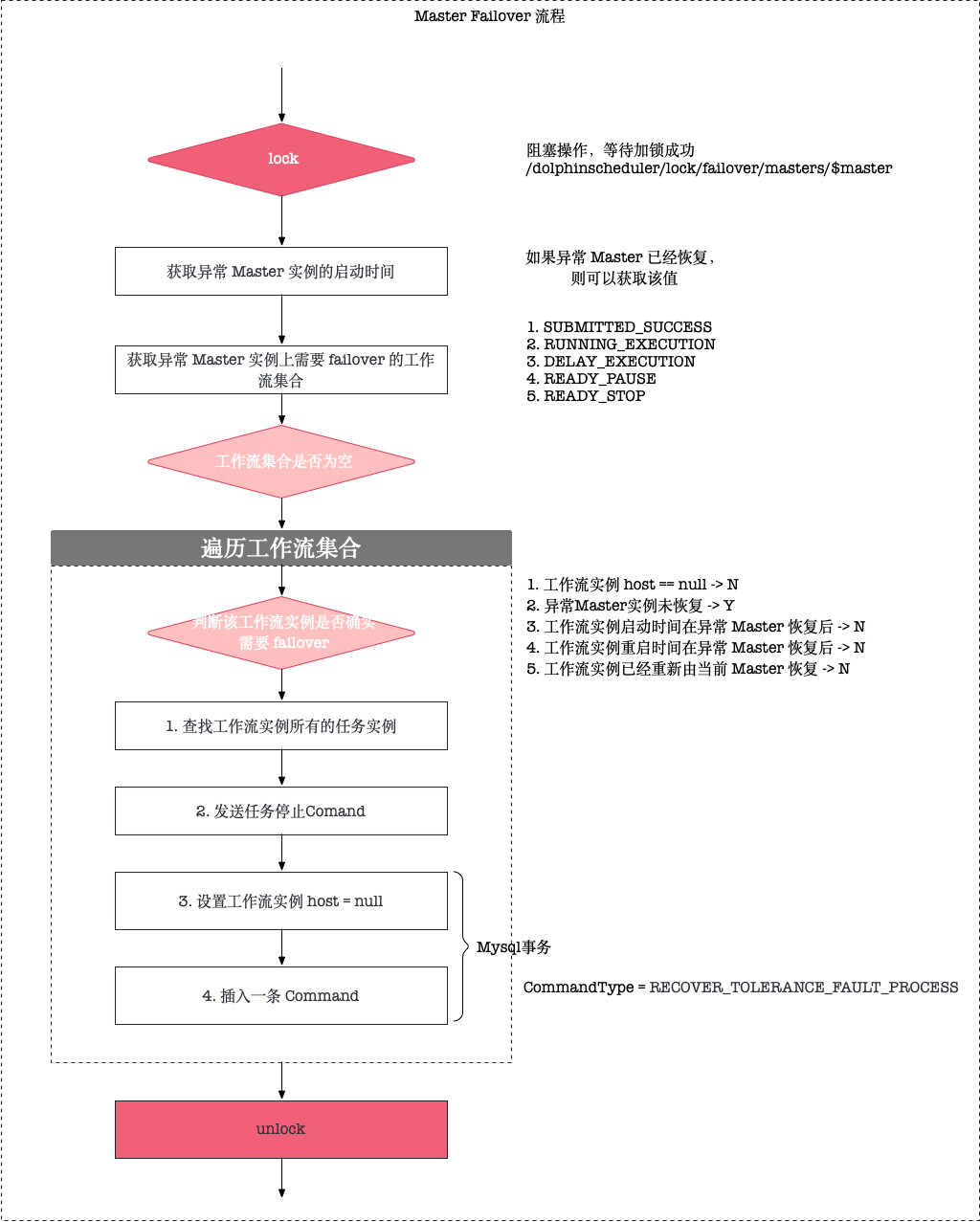
流程里的重点说明:
- 所有正常的 Master 都会抢锁
/dolphinscheduler/lock/failover/master/$masterPort,抢到锁后尝试 failover 该 master 的工作流实例 - recover 的工作流实例,设置 host = null 的同时会插入一条 command,这一步是通过事务完成的。确保了单个工作流实例只会 recover 一次。
- 如果 master 已经恢复,可能已经开始调度新的工作流实例,这部分新实例需要避免误 recover.
checkProcessInstanceNeedFailover方法里,234判断是连贯的,感觉5应该在2之前,代码逻辑上更好一些failoverTaskInstance会 kill 所有的 taskInstance,这点是比较暴力的,即 master failover,运行中的任务也会重新执行一遍。- 整个流程处理完成后,需要 failover 的 processInstance 会写入到 Command,经过正常流程由合适的 Master 实例选出。
failoverMaster入口,除了 zk watch 触发,还有一个定时线程FailoverExecuteThread,用于 master 重启后恢复自身之前的工作流实例。如果所有 master都在同一时刻宕机过,就依赖该线程触发而不是 zk REMOVE 事件了。
注:
- 定时 failover 也有风险,一旦判断逻辑有问题,正常的工作流就会不断被 failover.
- 一个优化项是 master failover 不停止运行中的任务,只是通知 worker 新的 master 地址。worker 转而向该地址汇报,当然额外要处理的 corner case 也会多一些。
3.4. watch Worker节点状态
Worker 实例的容错实现在WorkerFailoverService.failoverWorker,流程大同小异,就不再展开了。
注意这里会检查 TaskInstance 是否存在 Yarn applicationId,如果存在的话会发送 Kill 命令。对于 shell 任务,由于 processId 此时未回传,不会处理。也就是当 worker 重启时,shell 任务会成为 orphan process.
4. 总结
Coordination Service 是分布式系统的基础,ZooKeeper 是最常见的一种选型。Apache Curator 则在 zk-API 的基础上,进一步提供了 recipe 级别的易用性。
借助 zk 的服务发现、分布式锁等能力,DolphinScheduler 实现了容错处理,这也是 Master-Worker 架构下的典型处理方式,可以作为我们后续设计类似系统的参考。
但是可以看到无论是 Master 还是 Worker 的 failover,都需要重启任务。如果任务自身支持”断点续传”,容错时任务无感知的优化就很有意义了。