在编写复杂、耗时的应用程序时,我们经常会使用多线程以及并发来降低响应时间或者提高性能。可惜,传统的并发解决方案导致了一些问题,如线程安全、竞态条件、死锁、活锁以及不容易理解的、容易出错的代码。共享的可变性是罪魁祸首。 避免共享的可变性,便已经规避了许多问题。但是如何避免呢?这就是Actor模型发挥作用的地方。Actor帮助我们将共享的可变性转换为隔离的可变性(isolated mutability)。Actor是保证互斥访问的活动对象。没有两个线程会同时处理同一个Actor。由于这种天然的互斥行为,所有存储在Actor中的数据都自动是线程安全的——不需要任何显式的同步。 如果能将一个任务有意义地分解为几个子任务,即分而治之,就可以使用Actor模型来解决这个问题,设计良好又清晰,并且避免了通常的并发问题。
1. 顺序探索目录
这是一个顺序探索本地目录的例子,从一个指定的目录开始,如果目录下有文件,则增加对应的计数;如果是子目录,则继续探索子目录,循环往复。最后输出文件计数以及耗时。
import java.io.File
def getChildren(file: File) = {
val children = file.listFiles()
if (children != null) children toList else List()
} //> getChildren: (file: java.io.File)List[java.io.File]
val start = System.nanoTime //> start : Long = 56001752967194
val exploreFrom = new File("/Users/baidu/Documents")
//> exploreFrom : java.io.File = /Users/baidu/Documents
//两个可变变量
var count = 0L //> count : Long = 0
var filesToVisit = List(exploreFrom) //> filesToVisit : List[java.io.File] = List(/Users/baidu/Documents)
while (filesToVisit.nonEmpty) {
val head = filesToVisit.head
filesToVisit = filesToVisit.tail
val children = getChildren(head)
//println(s"$head : ${children.mkString}")
count = count + children.count{! _.isDirectory }
filesToVisit = filesToVisit ::: children.filter{ _.isDirectory }
}
val end = System.nanoTime //> end : Long = 56008302310770
println(s"Number of files found:$count") //> Number of files found:181893
println(s"Time taken: ${(end - start)/1.0e9} seconds")
//> Time taken: 6.549343576 seconds
这个例子可以正常工作,没有问题。唯一的问题可能是性能不足,在研究如何提高性能之前,先简单介绍下 Actor.
2. Actor例子-1
为了创建使用Actor的例子,我们需要先下载 akka 的包,从https://doc.akka.io/downloads/可以找到。
导入包后,介绍下第一个简单例子:
//akka
import akka.actor._
import scala.concurrent.Await
import scala.concurrent.duration.Duration
// 要创建一个 Actor,需要继承 Actor 特质并实现 receive() 方法
class HollywoodActor() extends Actor {
def receive: Receive = {
case message => println(s"$message - ${Thread.currentThread}")
}
}
// Akka的Actor托管在一个ActorSystem中,它管理了线程、消息队列以及Actor的生命周期。相对于使用传统的new关键字来创建实例,我们使用了一种特殊的actorOf工厂方法来创建Actor,并将其对应的ActorRef赋值给了名为depp/hanks的引用。
val system = ActorSystem("sample")
val depp = system.actorOf(Props[HollywoodActor])
val hanks = system.actorOf(Props[HollywoodActor])
// !方法给 actor 发送数据
depp ! "Wonka"
hanks ! "Gump"
Thread.sleep(100)
depp ! "Sparrow"
hanks ! "Phillips"
Thread.sleep(1000)
val terminateFuture = system.terminate()
Await.ready(terminateFuture, Duration.Inf)
程序输出:
Wonka - Thread[sample-akka.actor.default-dispatcher-2,5, main]
Gump - Thread[sample-akka.actor.default-dispatcher-3,5, main]
Calling from Thread[main,5, main]
Phillips - Thread[sample-akka.actor.default-dispatcher-3,5, main]
Sparrow - Thread[sample-akka.actor.default-dispatcher-2,5, main]
3. Actor例子-2
Actor一次最多只会处理一条消息,所以在Actor中保存的任何字段都是自动线程安全的。它是可变的,但却没有共享可变性。一个Actor的非final字段具备自动隔离的可变性。
我们通过一个增强版本的 HollywoodActor 来观察这点:
import scala.collection._
import scala.concurrent.duration._
import akka.pattern.ask
import akka.util.Timeout
import akka.actor._
case class Play(role: String)
case class ReportCount(role: String)
class NewHollywoodActor() extends Actor {
val messagesCount: mutable.Map[String, Int] = mutable.Map()
def receive: Receive = {
case Play(role) =>
val currentCount = messagesCount.getOrElse(role, 0)
messagesCount.update(role, currentCount + 1)
println(s"Playing $role")
case ReportCount(role) =>
sender ! messagesCount.getOrElse(role, 0)
}
}
如果接收到Play(role),那我们更新messagesCount对应的值。如果接收到ReportCount,则返回messagesCount的值,这个值也还是通过!方法发送,不同的是发送给 sender,也就是ReportCount的发送方。
接着创建 depp hanks 两个 actor,使用 !方法发送 Play(…):
val newSystem = ActorSystem("sample") //> newSystem : akka.actor.ActorSystem = akka://sample
val newDepp = newSystem.actorOf(Props[NewHollywoodActor])
//> newDepp : akka.actor.ActorRef = Actor[akka://sample/user/$a#-557464924]
val newHanks = newSystem.actorOf(Props[NewHollywoodActor])
//> newHanks : akka.actor.ActorRef = Actor[akka://sample/user/$b#192877015]
newDepp ! Play("Wonka")
newHanks ! Play("Gump")
newDepp ! Play("Wonka")
newDepp ! Play("Sparrow")
然后我们通过 ?方法发送 ReportCount 获取角色对应的计数(如果需要响应,则使用?方法):
implicit val timeout: Timeout = Timeout(2.seconds)
//> timeout : akka.util.Timeout = Timeout(2 seconds)
val wonkaFuture = newDepp ? ReportCount("Wonka")
//| wonkaFuture : scala.concurrent.Future[Any] = Future(<not completed>)
val sparrowFuture = newDepp ? ReportCount("Sparrow")
//> sparrowFuture : scala.concurrent.Future[Any] = Future(<not completed>)
val gumpFuture = newHanks ? ReportCount("Gump")
//> gumpFuture : scala.concurrent.Future[Any] = Future(<not completed>)
val wonkaCount = Await.result(wonkaFuture, timeout.duration)
//> wonkaCount : Any = 2
val sparrowCount = Await.result(sparrowFuture, timeout.duration)
//> sparrowCount : Any = 1
val gumpCount = Await.result(gumpFuture, timeout.duration)
//> gumpCount : Any = 1
println(s"wonkaCount: ${wonkaCount}") //> wonkaCount: 2
println(s"sparrowCount: ${sparrowCount}") //> sparrowCount: 1
println(s"gumpCount: ${gumpCount}") //> gumpCount: 1
val newTerminateFuture = newSystem.terminate()
//> newTerminateFuture : scala.concurrent.Future[akka.actor.Terminated] = Future(<not completed>)
Await.ready(newTerminateFuture, Duration.Inf)
//> res1: Actor.newTerminateFuture.type = Future(Success(Terminated(Actor[akka://sample/])))
不同于什么也不返回的!()方法,?()方法返回一个 Future.我们将三次调用返回的 Future,并将其分别保存在变量wonkaFuture、sparrowFuture、gumpFuture中,然后使用 Awwait 获取响应的 result。
4. 使用Actor模型探索目录
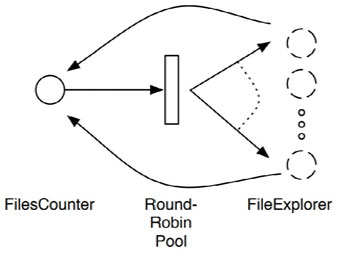
第一节里我们写的探索目录的例子,非常适合分而治之的解决方式。对于一个给定的起始目录,我们想要计算该目录层次结构之下的所有文件的数目。我们可以将该问题划分为查找给定目录下的每个子目录中的文件总数,然后再归并结果。反过来,这也告诉我们,我们有两个主要部分:一是探索文件,二是归并结果。
先创建一个无状态的 FileExplorer Actor,接受一个目录名dirName,对外返回两个数据:
- 该目录下所有的一级子目录
- 该目录下所有的以及文件数量
//文件查找
class FileExplorer extends Actor {
def receive: Receive = {
case dirName: String =>
val file = new File(dirName)
val children = file.listFiles()
var filesCount = 0
if (children != null) {
children.filter { _.isDirectory }.foreach{ sender ! _.getAbsolutePath }
filesCount = children.count { ! _.isDirectory }
}
sender ! filesCount
}
}
接着创建有状态的 FilesCounter,记录时间、文件数等。
import akka.routing._
class FilesCounter extends Actor {
val start: Long = System.nanoTime
var filesCount = 0L
var pending = 0
val fileExplorers: ActorRef =
context.actorOf(RoundRobinPool(100).props(Props[FileExplorer]))
def receive: Receive = {
case dirName: String =>
// println(s"dirName: ${dirName}")
pending = pending + 1
fileExplorers ! dirName
case count: Int =>
filesCount = filesCount + count
pending = pending - 1
// println(s"pending: ${pending}")
if (pending == 0) {
val end = System.nanoTime
println(s"Files count: $filesCount")
println(s"Time taken: ${(end - start)/1.0e9} seconds")
context.system.terminate()
}
}
}
fileExplorers 是 100 个 FileExplorer 的实例,使用 RoundRobin 路由。即发送给 fileExplorers 的消息将会按照该方式分配给具体的 FileExplorer.
其接收目录名,发送给 fileExplores 探索目录,后者则发送回子目录名及文件数。子目录名继续探索,文件数则被递增到 filesCount 这个变量。
最后,通过给 filesCounter 这个 actor 发送一个初始目录名开始统计:
val fileSystem = ActorSystem("sample") //> fileSystem : akka.actor.ActorSystem = akka://sample
val filesCounter = fileSystem.actorOf(Props[FilesCounter])
//> filesCounter : akka.actor.ActorRef = Actor[akka://sample/user/$a#-87288343
//| ]
filesCounter ! "/Users/baidu/Documents"
Thread.sleep(10000) //> Files count: 181893
//| Time taken: 4.18749764 seconds/
可以看到,相比第一节里的版本,速度上有提升。同时,代码量减少,也没有杂乱的线程创建和同步代码。