总结我对几篇 LLM 论文的理解,论文来源是在在读《大模型应用开发 动手做AI Agent》时,书里推荐的几篇。
这篇文章主要是 COT 和 REACT , 论文大多抽象,文章里尽量用代码实际验证来说明我的个人理解。
1. 思维链(Chain-of-Thought, CoT)
教会模型“一步一步想”。
1.1. 什么是 CoT?
思维链(Chain-of-Thought)是一种提示(Prompting)技术,它通过在提示中加入一些“逐步思考”的范例(Few-shot),来引导 LLM 在回答问题时,模仿范例,输出一个详细的、循序渐进的推理过程,并最终给出答案。
这个过程就像我们人类解决复杂问题时,会把问题分解成若干个小步骤,然后逐一解决。CoT 的核心思想就是将这种“思考过程”显式地展示出来。
详细论文参考:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
1.2. 为什么需要 CoT?
标准 LLM 在处理复杂问题,尤其是数学应用题、逻辑推理题时,很容易因为“一步到位”的思考模式而得出错误结论。它们往往只关注表面的关联,而缺乏深度的逻辑演绎。
CoT 的出现,恰好弥补了这一点。它强迫模型放慢脚步,关注过程而非仅仅是结果,从而显著提升了在推理任务上的准确性。
注意论文是在 2022年1月 发表的,之所以笔记标题叫做炒冷饭,原因也在于此。虽然只隔了三年时间,但是大模型的发展迅速,有些例子已经不适用。之前说“一日不见如隔三秋”,放在 AI 领域真是太合适不过,三年已过,如同上个世纪。
1.3. 实践
文章里的这个图现在引用已经非常广泛了:
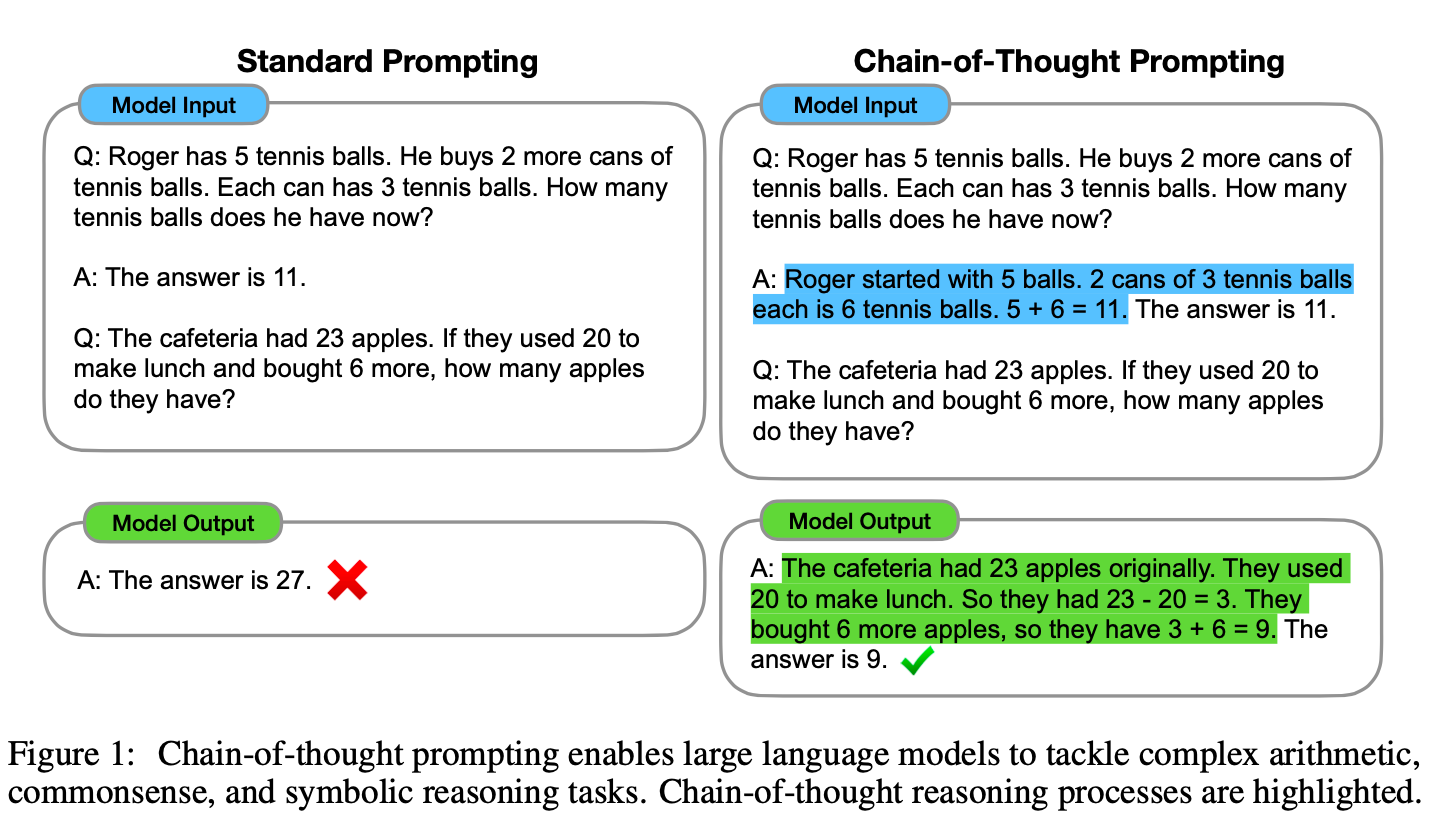
我使用代码实际测试了下:
def testCOT(llm: ChatOpenAI):
question = """Q: Roger has 5 tennis balls. He buys 2 more cans of
tennis balls. Each can has 3 tennis balls. How many
tennis balls does he have now?
A: The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to
make lunch and bought 6 more, how many apples
do they have?"""
print('-'*32 + ' not cot ' + '-'*32)
print(invokeLLM(llm, question))
question = """"Q: Roger has 5 tennis balls. He buys 2 more cans of
tennis balls. Each can has 3 tennis balls. How many
tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls
each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to
make lunch and bought 6 more, how many apples
do they have?"""
print('-'*32 + ' cot ' + '-'*32)
print(invokeLLM(llm, question))
这是用 doubaoseed1.6 某次输出的效果:
-------------------------------- not cot --------------------------------
The cafeteria starts with 23 apples. They use 20, so subtract 20: 23 - 20 = 3. Then they buy 6 more, so add 6: 3 + 6 = 9. The answer is 9.
-------------------------------- cot --------------------------------
A: The cafeteria started with 23 apples. They used 20 apples, so 23 - 20 = 3 apples left. Then they bought 6 more, so 3 + 6 = 9. The answer is 9.
doubao1.5visionlite 某次输出的效果:
-------------------------------- not cot --------------------------------
First, find out how many apples are left after using some:
The cafeteria had 23 apples and used 20, so the number of apples left is \(23 - 20= 3\).
Then, they bought 6 more apples. So the total number of apples now is \(3 + 6 = 9\).
The answer is 9.
-------------------------------- cot --------------------------------
The cafeteria started with 23 apples. They used 20 apples, so they had 23 - 20 = 3 apples left. Then they bought 6 more apples. 3 + 6 = 9. The answer is 9.
用 deepseek-r1 某次输出的效果:
-------------------------------- not cot --------------------------------
The cafeteria started with 23 apples.
They used 20 apples to make lunch, which means they have 23 - 20 = 3 apples left.
Then, they bought 6 more apples, so they have 3 + 6 = 9 apples now.
Alternatively, the net change is -20 (used) + 6 (bought) = -14, so 23 + (-14) = 9.
Regardless of the order of operations, the result is consistent: 23 - 20 + 6 = 9, or 23 + 6 - 20 = 9.
Thus, the cafeteria now has 9 apples.
\boxed{9}
-------------------------------- cot --------------------------------
The cafeteria started with 23 apples.
They used 20 apples for lunch, so they had 23 - 20 = 3 apples left.
Then they bought 6 more apples, so 3 + 6 = 9.
The answer is 9.
可以看到用现在的大模型,回答其实都是准确的。
我尝试多次调用,以及输入其他问题,例如:
- Mary’s father has five daughters: Nana, Nene, Nini, Nono. What is the name of the fifth daughter?(为了引导模型逐步推理,加入这一句”Let’s think step by step.”)
- Mike plays ping pong for 40 minutes. In the first 20 minutes, he scores 4 points. In the second 20 minutes, he scores 25% more points. How many total points did he score?
即使使用 Standard Prompting 而不是 Chain-of-Thought Prompting ,模型在输出时不仅展现了推理能力,而且也能够输出正确答案。
每次调用结果不同,如果在 Prompt 里尝试引导模型推理,符合预期的概率确实更大一些。
我的理解是大模型的效果就像是一个 V 字型,左边是训练生成模型,右边是查询模型,两边都会影响推理效果:
1. 现在的很多大模型,在左边就已经使用更精确的数据、调优解决了我测试的这些 query,因此即使不使用 COT ,效果也非常好了。
2. 为了更大概率的拿到想要的输出,还是应当尽量使用 COT
3. 相比后续出现的策略,COT 最为基础和直接。因为 COT 只使用了 Prompt 来提升效果,因此也是 Prompt Engine 的一种体现。(注:我查了下似乎提出 PE 只比 COT 早了半年)
4. COT 的本质是要引导大模型的推理过程,现在看其实已经是比较普遍的思想了。
现在想想也是合理的。就像我们自己计算错误后,会跟自己说“你再仔细想想”。“多想想,按照已知情况演绎/推理几遍,就会少犯错”,放在大模型这里用了一个新名词,即 COT.
相关代码放在 https://github.com/izualzhy/AI-Systems/blob/main/misc/read_paper_cot.py
2. ReAct
从“思考”到“行动”的进化。
2.1. 什么是 ReAct?
ReAct 范式可以看作是 CoT 的一个强大演进。它不仅包含了 CoT 的“推理”能力,更引入了“行动”(Acting)的概念。
ReAct 的核心机制是一个 Thought -> Action -> Observation 的循环:
- Thought (思考): 模型根据当前任务和已有信息,分析现状,并规划出下一步需要做什么。
- Action (行动): 模型决定执行一个具体的“行动”。这个行动通常是调用外部工具(API),例如进行网络搜索、查询数据库、执行代码等。
- Observation (观察): 模型获取“行动”返回的结果。这个结果会作为新的信息,融入到下一轮的“思考”中。
通过这个循环,LLM 能够与外部世界进行交互,获取实时、准确的信息,从而克服其自身知识库静态、可能过时的缺点。
详细论文参考:REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
2.2. 为什么需要 ReAct?
CoT 极大地增强了模型的推理能力,但它的推理过程是“封闭”的,完全依赖于模型内部的知识。如果遇到以下场景,CoT 就会力不从心:
- 知识过时: LLM 的知识截止于其训练日期。
- 需要精确计算: LLM 在数学计算上并不可靠。
- 需要与外部服务交互: 例如订票、发邮件等。
ReAct 通过引入“行动”,将 LLM 从一个“封闭大脑”变成了一个能够主动探索和获取信息的“智能代理”(Agent),极大地拓展了其应用边界。

这套“思考-行动-观察”的循环,就是 ReAct Agent 的基本工作模式。
2.3. 实践
那学术界的这个论文应该如何应用?
主要有两处:
- 设计 Prompt,以及解析大模型返回的结果
- 循环:调用工具、根据工具输出继续调用大模型,直到达到次数阈值
我们用 LangChain 实际测试看看:
def get_current_weather(location: str):
print(f"\n** [函数被调用] location = {location} **\n")
return f"{location} 今天天气晴,25°C."
tools = [
Tool.from_function(
func=get_current_weather,
name="get_current_weather",
description="获取城市当前天气",
handle_parsing_errors=True
)
]
# 初始化 Agent
# llm = getDoubaoSeed16()
llm = getDoubao15VisionLite()
# llm = getDeepSeekR1()
def v1():
# llm = getDeepSeekR1()
agent = initialize_agent(tools,
llm,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
# agent_type="openai-tools",
verbose=True,
temperature=0,
handle_parsing_errors=True)
def run():
print(agent.agent.llm_chain.prompt.template)
# 用户提问
result = agent.invoke("请问上海的天气怎么样?")
print(result)
run()
上述代码输出:
Answer the following questions as best you can. You have access to the following tools:
get_current_weather(location: str) - 获取城市当前天气
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [get_current_weather]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
> Entering new AgentExecutor chain...
Thought: 需要获取上海当前的天气信息,调用 get_current_weather 工具来实现
Action: get_current_weather
Action Input: 上海
** [函数被调用] location = 上海 **
Observation: 上海 今天天气晴,25°C.
Thought:I now know the final answer
Final Answer: 上海 今天天气晴,25°C.
> Finished chain.
可以看到函数被调用,且返回了预期的最终答案。
2.3.1. Prompt
print(agent.agent.llm_chain.prompt.template)可以获取内置的 Prompt:
Answer the following questions as best you can. You have access to the following tools:
get_current_weather(location: str) - 获取城市当前天气
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [get_current_weather]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
Question -> Thought -> Action -> ActionInput -> Observation -> Thought -> ... -> Final Answer引导大模型按照这个过程推理和输出,也是 REACT 的标准方式。
2.3.2. 循环
class AgentExecutor(Chain):
def _call(
self,
inputs: dict[str, str],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> dict[str, Any]:
"""Run text through and get agent response."""
# Construct a mapping of tool name to tool for easy lookup
name_to_tool_map = {tool.name: tool for tool in self.tools}
# We construct a mapping from each tool to a color, used for logging.
color_mapping = get_color_mapping(
[tool.name for tool in self.tools], excluded_colors=["green", "red"]
)
intermediate_steps: list[tuple[AgentAction, str]] = []
# Let's start tracking the number of iterations and time elapsed
iterations = 0
time_elapsed = 0.0
start_time = time.time()
# We now enter the agent loop (until it returns something).
while self._should_continue(iterations, time_elapsed):
next_step_output = self._take_next_step(
name_to_tool_map,
color_mapping,
inputs,
intermediate_steps,
run_manager=run_manager,
)
if isinstance(next_step_output, AgentFinish):
return self._return(
next_step_output, intermediate_steps, run_manager=run_manager
)
intermediate_steps.extend(next_step_output)
if len(next_step_output) == 1:
next_step_action = next_step_output[0]
# See if tool should return directly
tool_return = self._get_tool_return(next_step_action)
if tool_return is not None:
return self._return(
tool_return, intermediate_steps, run_manager=run_manager
)
iterations += 1
time_elapsed = time.time() - start_time
output = self._action_agent.return_stopped_response(
self.early_stopping_method, intermediate_steps, **inputs
)
return self._return(output, intermediate_steps, run_manager=run_manager)
循环的过程在上述代码里,遵循调用大模型 -> 解析大模型返回结果(action/final answer) -> 执行 -> 根据执行结果继续调用....
_should_continue里传入了迭代次数、消耗时间,避免陷入循环一直不返回。
解析返回结果:
class MRKLOutputParser(AgentOutputParser):
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
"""Parse the output from the agent into
an AgentAction or AgentFinish object.
Args:
text: The text to parse.
Returns:
An AgentAction or AgentFinish object.
Raises:
OutputParserException: If the output could not be parsed.
"""
includes_answer = FINAL_ANSWER_ACTION in text
regex = (
r"Action\s*\d*\s*:[\s]*(.*?)[\s]*Action\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)"
)
action_match = re.search(regex, text, re.DOTALL)
if action_match and includes_answer:
...
执行工具的调用栈:
AgentExecutor._take_next_step ->
AgentExecutor._iter_next_step ->
AgentExecutor._perform_agent_action ->
BaseTool.run ->
Tool._run ->
自定义函数
由于大模型的框架都在快速迭代(换句话说不成熟😄),就不深入开展了。这篇笔记的目的也是主要用来理解 REACT 的过程。
2.4. 我不理解的
实际上上述代码,我第一次花了几个小时都没有跑通(不得不吐槽搜到的很多文章,包括一些课程文章,基本都是复读机一样挑着 REACT 的概念在讲)。
直到我从 Doubao-Seed-1.6 DeepSeek-R1 换成了 Doubao-1.5-vision-lite 模型。使用前两者的话,返回结果上问题很多,比如:
- 既输出了 Final Answer,又输出了 Action,LangChain 不知道是否应该结束循环
- 没有调用我定义的 tool,反而输出了一堆自认为的关于上海天气的语句(训练中加入的?)
随着模型变高级,返回结果反而不遵守 Prompt 了?
我的理解是
1. 大模型靠概率输出下一个字符,本质上不能保证答案100%准确。而人们却希望获取100%准确的答案,怎么解决?答案就是引入工具。怎么让模型调用工具?答案就是 REACT.
2. 根据我不理解的那些内容,可以看到效果对 模型+Prompt 的依赖还是非常大的,换个模型就导致结果错乱。
3. 这让我想到接触 Agent 之后最初的疑问,我们现在通过 Prompt 控制大模型的返回,只是靠观察到这种现象得到的结论。像极了农场鸡舍的科学家。
4. REACT 引入工具的目的,最开始是为了获取更准确的答案。而推动工具发展的同时,我们想象力进一步放大,开始希望用 Agent 去做更多事情。
注:相关代码在 https://github.com/izualzhy/AI-Systems/blob/main/misc/read_paper_react.py
3. 总结:从思想到行动的演进
回顾这两篇论文,我们可以看到一条清晰的演进路径:
- Standard Prompting:直接问答,依赖模型自身知识。
- Chain-of-Thought (CoT):通过引导模型思考中间步骤,提升复杂推理的可靠性。这是内部思维的优化。
- ReAct:将 CoT 的“思考”与“行动”(使用工具)相结合,让模型能与外部世界交互。这是思维与实践的结合。
这个过程,是从一个封闭的“知识库”到一个能够进行“研究”和“实践”的初级 Agent 的演变。我在实践中遇到的问题,或许也是当前 Agent 开发领域正在努力解决的核心问题:如何在给予模型强大推理能力的同时,确保它能可靠、可控地遵循我们设计的流程和规则,在需要时放下“身段”,谦虚地使用工具