1. 微调
微调的代码和预训练几乎一样,区别在于数据如何准备。
例如目标要生成一个问答模型,准备的数据如下:
User: hi , how are you ?
AI: i am doing well , thank you . how about you ?
User: i am good , thanks for asking . what can you do ?
AI: i am an ai language model . i can help you answer questions .
User: what is the weather like today ?
AI: please check a weather website or application for the current conditions .
User: can you recommend a good book ?
AI: sure ! to kill a mockingbird by harper lee is a classic and highly recommended novel .
User: thank you ! i will check it out .
AI: you are welcome ! let me know if you need help with anything else .
那训练的数据则分别从 User AI 里提取,形如:
Input:
<sos> hi, how are you <eos>
Target:
<sos> I am doing well, thank you <eos>
之后也是根据 Input 训练出 Output,然后不断缩小与 Target 的差距。
不过从实际接触的其他资料看,书里的例子可能适合教学,更常见的做法是把对话作为一个完整序列,右移一位作为训练目标:
source:
User: hi, how are you?
AI: i am doing
target:
hi, how are you?
AI: i am doing well
这样模型学习的是”给定前文,预测下一个 token”,跟预训练的目标保持一致。
2. RLHF
Reinforcement Learning from Human Feedback 的几个步骤:
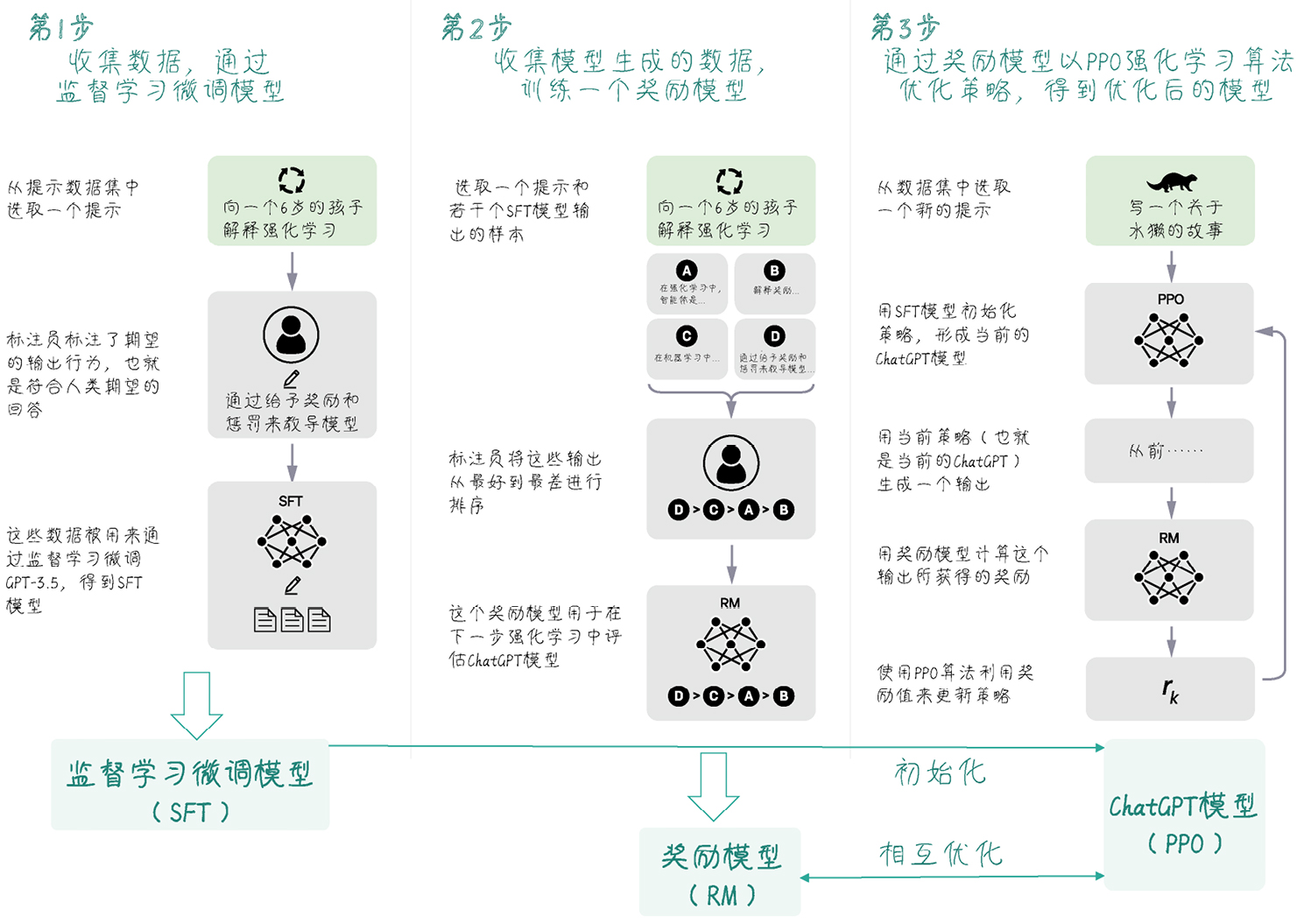
- 通过有标注的数据,在预训练模型上,训练出监督学习微调模型(Supervised Fine-Tune Model, SFT)(即第 1 节的产出)
- 在 1 的基础上,基于标注数据(带回答得分),训练一个奖励模型,该模型善于对于回答进行评价得分
- 在 1 的基础上,用 2 产出的奖励模型评价得分,该得分会加权到 loss,以不断改善该模型
书里的例子做了较大简化:数据里直接固定了 score,即(User, AI Answer) → 一个标量奖励,跳过了奖励模型的训练过程。真实的 RLHF 流程要复杂得多,但核心思想就是这三步:先用监督数据微调,教模型怎么说(例如 User:Question AI:Answer 的形式),再用人类偏好教模型”说得好”。
3. 总结
这本书从去年开始看,中间看到 Attention 那章因为不懂就放弃了,最近几个周末又狂啃了几顿,终于基本看懂。
新的过程主要还是借助了 ChatGPT,我把自己的理解,跟 AI 不断交流,直到至少理论上是自洽的,偶尔再拿 ds 做二次确认,以确保没有理解偏差。因为这类技术书籍,打不牢基础,看到后面也只能是沦为满嘴技术名词的附庸者而已。这个过程,也让我感触颇深。特别是这类自由度比较高的学习场景——无标准题目、无标准答案、理解程度全凭个人——AI 辅助学习的效率已经远超预期。以后教育的形式、人才的判断标准,大概都会改变。
回到书籍本身,从 N-Gram 的统计思想出发,一路走到 GPT,我对于这条脉络的理解也清晰了不少。
最早是概率的思想,N-Gram 刻画词序概率,NPLM 引入神经网络,LSTM 解决长距离依赖。然后基于翻译任务,Seq2Seq 架构将编码器-解码器带入序列任务,点积注意力让模型知道 token 间的关系。注意力机制继续进化,QKV 的参数化设计、多头注意力的子空间拆分、掩码对生成过程的约束。这些积累最终催生了 Transformer 架构,彻底抛弃 RNN,用位置编码和交叉注意力重新定义了序列建模。在此之上,编码器产生了 BERT,解码器则产生了 GPT。GPT 是纯 Decoder 结构,自回归生成:训练时右移一位学习”给定前文,预测下一个 token”,推理时逐 token 生成直到结束。最后,通过微调和 RLHF 让模型能更符合某个场景的偏好——先用监督数据教它对话的形式,再用人类偏好教它回答的质量。也就是本文所记录的内容,基于这些对话的数据训练出来的模型,就是平时我用的最多的 ChatXXX 的最初形态了。