之前介绍multi_index_container时,使用了 LRU Cache 作为一个简单测试的例子。本文介绍下 LRU Cache 的原理以及 leveldb 里的实现。
1. 原理
Cache 用于提供对数据更高速的访问,因此存储上也更昂贵,例如 mem ssd 等,其容量通常都是有限的,因此就需要一定的缓存淘汰策略。LRU(Least recently used)就是其中一种,一句话介绍的话,就是:
淘汰最不常用的数据
wiki上有一个比较直观的例子:
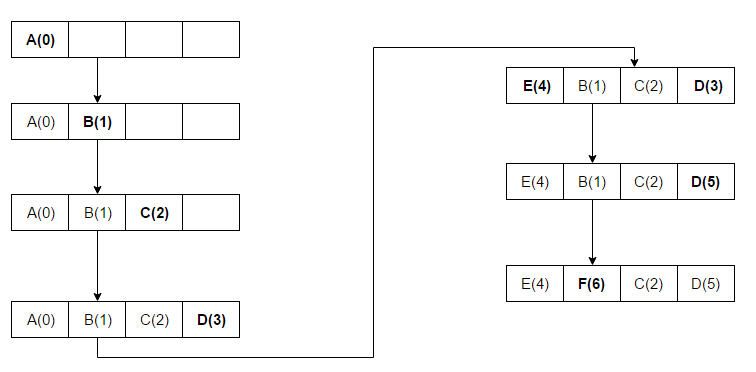
读取的顺序为 A B C D E D F,缓存大小为4,括号内的数字表示排序,数字越小,表示 Least recently.
按照箭头的方向,
读取 E 时,缓存已满,因此淘汰最开始的 A.
读取 D 时,更新 D 的排序为最大.
读取 F 时,缓存已满,因此淘汰最开始的 B.
2. 定义
从前面的文章已经可以了解到,LRU 的实现需要两个数据结构:
- HashTable: 用于实现O(1)的查找
- List: 存储 Least recently 排序,用于旧数据的淘汰
在 leveldb 的实现里也不例外,看下相关的所有类:
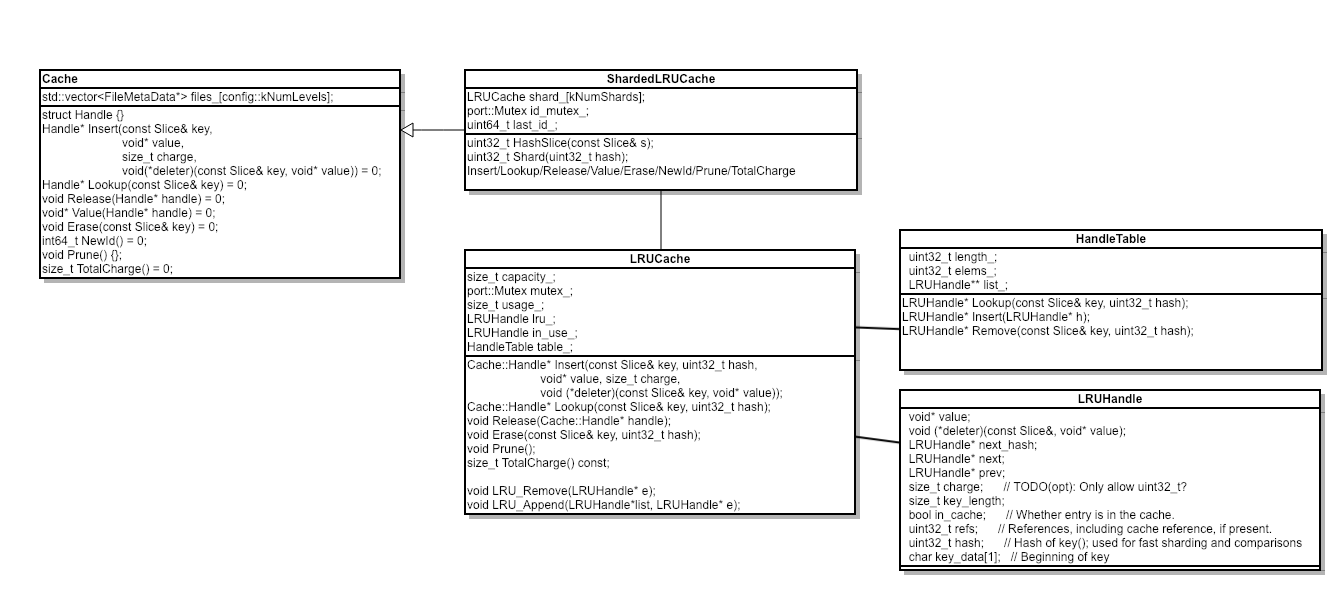
我们暂时可以只关注到LRUCache这个类,实现了 LRU 的所有功能。
HandleTable即 HashTable,提供了Lookup/Insert/Remove接口,实现数据的查询、更新、删除。
LRUCache.lru_用于节点淘汰。
底层的节点数据类型为LRUHandle,我更习惯的名称是 LRUNode 这种,HashTable 的冲突链表解决、 lru 链表都依赖于该数据结构的内部定义,因此源码解析我们先从这个类切入。
3. 源码解析
3.1. LRUHandle
LRUHandle这个类承载了很多功能,这大概是没有命名为LRUNode的原因:
- 存储 key:value 数据对
- lru 链表,按照顺序标记 least recently used.
- HashTable bucket 的链表
- 引用计数及清理
对应的代码
// An entry is a variable length heap-allocated structure. Entries
// are kept in a circular doubly linked list ordered by access time.
struct LRUHandle {
void* value;
void (*deleter)(const Slice&, void* value);//当refs降为0时的清理函数
LRUHandle* next_hash;//HandleTable hash冲突时指向下一个LRUHandle*
LRUHandle* next;//LRU链表双向指针
LRUHandle* prev;//LRU链表双向指针
// 用于计算LRUCache容量
size_t charge; // TODO(opt): Only allow uint32_t?
size_t key_length;// key长度
// 是否在LRUCache in_use_ 链表
bool in_cache; // Whether entry is in the cache.
// 引用计数,用于删除数据
uint32_t refs; // References, including cache reference, if present.
// key 对应的hash值
uint32_t hash; // Hash of key(); used for fast sharding and comparisons
// 占位符,结构体末尾,通过key_length获取真正的key
char key_data[1]; // Beginning of key
Slice key() const {
// next_ is only equal to this if the LRU handle is the list head of an
// empty list. List heads never have meaningful keys.
assert(next != this);
return Slice(key_data, key_length);
}
};
比较独特的是第4点,我们知道缓存里存储的是 value 对象的指针,而不是对象本身。什么时候调用deleter清理函数,就是通过控制引用计数refs来实现的,这个类似于shared_ptr,我也没有想清楚为什么作者要手动实现一版。
3.2. HandleTable
HandleTable即哈希表,leveldb 里手动实现了一版,根据注释介绍相比 g++ 原生的性能要高一些。
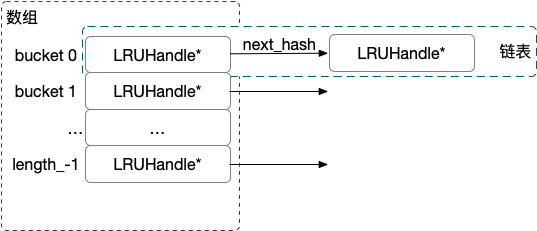
桶的个数初始化大小为4,随着元素增加动态修改,使用数组实现,同一个 bucket 里,使用链表存储全部的 LRUHandle*,最新插入的数据排在链表尾部。
核心函数是FindPointer,重点介绍下:
// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
// 如果某个LRUHandle*存在相同的hash&&key值,则返回该LRUHandle*的二级指针,即指向上一个LRUHandle*的next_hash的二级
指针.
// 如果不存在这样的LRUHandle*,则返回指向该bucket的最后一个LRUHandle*的next_hash的二级指针,其值为nullptr.
// 返回next_hash地址的作用是可以直接修改该值,因此起到修改链表的作用
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
//先查找处于哪个桶
LRUHandle** ptr = &list_[hash & (length_ - 1)];
//next_hash 查找该桶,直到满足以下条件之一:
//*ptr == nullptr
//某个LRUHandle* hash和key的值都与目标值相同
while (*ptr != nullptr &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
//返回符合条件的LRUHandle**
return ptr;
}
FindPointer的作用有两个:
- 返回适合 key&&hash 插入的合适位置,从前面的介绍可知,需要修改上一个LRUHandle*->next_hash的值
- 如果 key&&hash 存在,返回之前的LRUHandle*
因此,返回值类型定义为LRUHandle**,巧妙的同时支持了这两点。
3.3. LRUCache
介绍了LRUHandle和HandleTable,我们就可以介绍清楚LRUCache了。
通常,关于 Cache 的操作,返回值定义为
bool Insert(key, value);//缓存是否更新成功
void* Lookup(key);//返回key对应的value指针
但是,leveldb 为了更丰富的结果以及自动化的 value 清理,返回值统一定义为Cache::Handle*类型(实际类型为leveldb::(anonymous namespace)::LRUHandle*),需要手动调用Cache::Release(Cache::Handle*)清理函数。
全部变量如下:
// Initialized before use.
size_t capacity_;
// mutex_ protects the following state.
mutable port::Mutex mutex_;//Insert/Lookup等操作时都先加锁
size_t usage_ GUARDED_BY(mutex_);//用于跟capacity_比较,判断是否超过容量
// Dummy head of LRU list.
// lru.prev is newest entry, lru.next is oldest entry.
// Entries have refs==1 and in_cache==true.
LRUHandle lru_ GUARDED_BY(mutex_);
// Dummy head of in-use list.
// Entries are in use by clients, and have refs >= 2 and in_cache==true.
LRUHandle in_use_ GUARDED_BY(mutex_);
HandleTable table_ GUARDED_BY(mutex_);
缓存里的一个LRUHandle对象可能经历这么几种状态:
- 被手动从缓存删除/相同 key 新的 value 替换后原有的
LRUHandle*/容量满时淘汰,此时缓存不应该持有该对象,随着外部也不再持有后应当彻底删除该对象。 - 不满足1的条件,因此对象正常存在于缓存,同时被外部持有,此时即使容量满时,也不会淘汰。
- 不满足1的条件,因此对象正常存在于缓存,当时已经没有外部持有,此时当容量满,会被淘汰。
这3个状态,就分别对应了以下条件:
in_cache = falsein_cache = true && refs >= 2in_cache = true && refs = 1
其中满足条件3的节点存在于lru_,按照 least recently used 顺序存储,lru_.next是最老的节点,当容量满时会被淘汰。满足条件2的节点存在于in_use_,表示该 LRUHandle 节点还有外部调用方在使用。
注:关于状态2,可以理解为只要当外部不再使用该缓存后,才可能被执行缓存淘汰策略
成员变量table_则用于实现O(1)的查找,例如Lookup先查找table_,然后更新lru_ in_use链表:
Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) {
MutexLock l(&mutex_);
LRUHandle* e = table_.Lookup(key, hash);
if (e != nullptr) {
Ref(e);
}
return reinterpret_cast<Cache::Handle*>(e);
}
Insert首先是根据传入参数,申请LRUHandle内存并且初始化:
Cache::Handle* LRUCache::Insert(
const Slice& key, uint32_t hash, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
MutexLock l(&mutex_);
// 申请动态大小的LRUHandle内存,初始化该结构体
// refs = 2:
// 1. 返回的Cache::Handle*
// 2. in_use_链表里记录
LRUHandle* e = reinterpret_cast<LRUHandle*>(
malloc(sizeof(LRUHandle)-1 + key.size()));
e->value = value;
e->deleter = deleter;
e->charge = charge;
e->key_length = key.size();
e->hash = hash;
e->in_cache = false;
e->refs = 1; // for the returned handle.
memcpy(e->key_data, key.data(), key.size());
该LRUHandle对象指针会返回给调用方,因此refs此时为1。
然后添加到in_use_链表尾部,因此refs此时为2,同时更新in_cache = true以及使用量usage_.
if (capacity_ > 0) {
e->refs++; // for the cache's reference.
e->in_cache = true;
//添加到in_use_队列
LRU_Append(&in_use_, e);
usage_ += charge;
接着插入到table_,如果 key&&hash 之前存在,那么HandleTable::Insert会返回原来的LRUHandle*对象指针,调用FinishErase清理进入状态1。
// 如果是更新的,删除原有节点
FinishErase(table_.Insert(e));
如果容量超限,执行淘汰策略:
// 如果超过了容量限制,根据lru_按照lru策略淘汰
while (usage_ > capacity_ && lru_.next != &lru_) {
// lru_.next是最老的节点,首先淘汰
LRUHandle* old = lru_.next;
assert(old->refs == 1);
bool erased = FinishErase(table_.Remove(old->key(), old->hash));
if (!erased) { // to avoid unused variable when compiled NDEBUG
assert(erased);
}
}
为了保证refs值准确,无论Insert还是Lookup,都需要及时调用Release释放,使得节点能够进入lru_或者释放内存。
void LRUCache::Release(Cache::Handle* handle) {
MutexLock l(&mutex_);
Unref(reinterpret_cast<LRUHandle*>(handle));
}
3.4. ShardedLRUCache
LRUCache的接口都会加锁,为了更少的锁持有时间以及更高的缓存命中率,可以定义多个LRUCache,分别处理不同 hash 取模后的缓存处理。
ShardedLRUCache就是这个作用,管理16个LRUCache,外部调用接口都委托调用具体某个LRUCache。
static const int kNumShardBits = 4;
static const int kNumShards = 1 << kNumShardBits;//16,即16个分片,二进制定义的好处是取模时>>即可(参考ShardedLRUCache::Shard实现)
class ShardedLRUCache : public Cache {
private:
LRUCache shard_[kNumShards];
port::Mutex id_mutex_;
uint64_t last_id_;
static inline uint32_t HashSlice(const Slice& s) {
return Hash(s.data(), s.size(), 0);
}
static uint32_t Shard(uint32_t hash) {
return hash >> (32 - kNumShardBits);
}
public:
explicit ShardedLRUCache(size_t capacity)
: last_id_(0) {
const size_t per_shard = (capacity + (kNumShards - 1)) / kNumShards;
for (int s = 0; s < kNumShards; s++) {
shard_[s].SetCapacity(per_shard);
}
}
virtual ~ShardedLRUCache() { }
NewId会加锁,返回一个全局唯一的自增ID.
NewLRUCache的作用类似NewBloomFilterPolicy,这种手法在 leveldb 里用的很多。
实际就是返回一个 new 出来的 ShardedLRUCache 对象,需要手动 delete.
Cache* NewLRUCache(size_t capacity) {
return new ShardedLRUCache(capacity);
}
4. 例子
例子比较简单,放在cache_test.cpp了,不再赘述。如果对链表的操作仍然有疑问,可以通过 gdb 该例子进一步明确.