豆瓣笔记是指形如https://www.douban.com/note/699086917/这样链接样式的帖子,严格来讲,我没有搞清楚豆瓣对于这款产品的定位,话题广场、日记、豆列下的文章似乎都在其中。
想做这个事情,缘起于单纯想看看这个文艺网站下的青年们在关注什么。
另外一个是很久不爬东西了手痒,厂长经常说不忘初心,我的初心有一部分大概也是 spider.
断断续续爬了130w+的文章,用的 scrapy,代码就不介绍了,放到了TinyTools这里,这里贴下一些结论。
1. 200 vs 404
个人觉得判断豆瓣是否重视这个产品可以看下死链率,从 scrapy 运行日志可以很轻松的拿到,匹配Crawled (200)或者Crawled (404)即可。
其中 404 页面占比 6.7%,还是比较高的,感觉 note 系列应该不是很受重视。
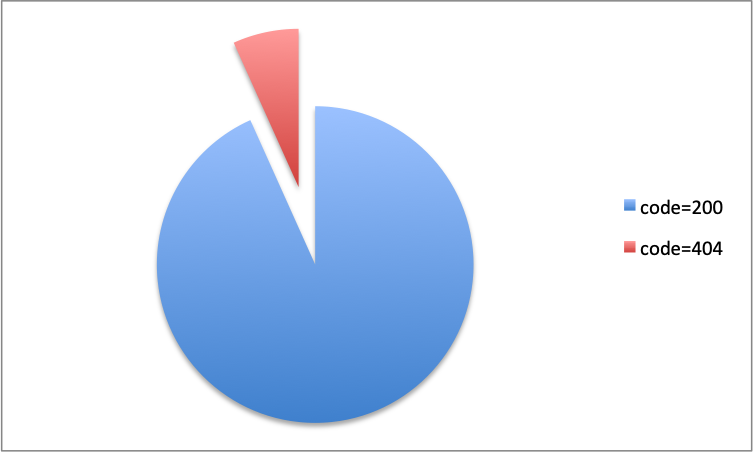
其中 404 大概是两种原因:
- 用户主动注销账号,例如https://www.douban.com/people/Redreaming/
- 用户删除了文章,但是主页还在,例如https://www.douban.com/people/3673971/notes,这里的文章实际上都已经不能访问了,但是摘要之类的还在。
2. 时间轴
按照年份来看,笔记数量有一个下降再上升的趋势,应该跟样本无关。
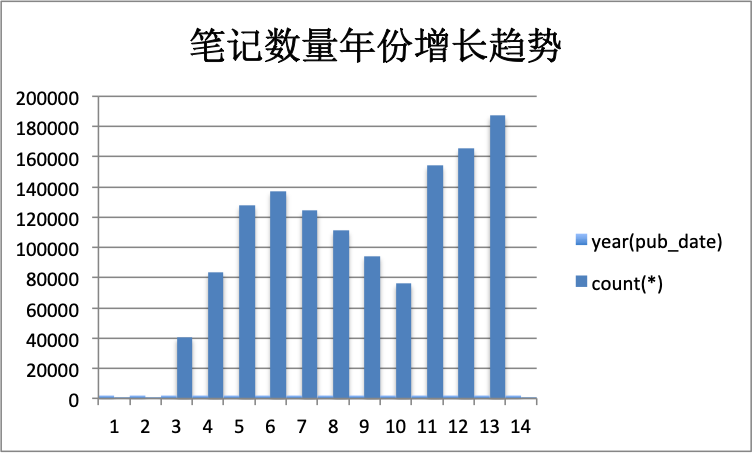
最早的一篇文章是在2006年,搜了下没找到这个产品上线的时间,应该是对的上的。
不过最早的一篇已经被删掉了,可能跟标题有关,我就不放出来了。
*************************** 1. row ***************************
url: https://www.douban.com/note/2137882/
author: aruni
comment_num: 44
pub_date: 2006-08-19 19:48:18
tags:
*************************** 2. row ***************************
url: https://www.douban.com/note/2137828/
title: 现在的中青年,对孔子生平的了解实在已经少得可怜。
author: aruni
snippet: 序:孔子是中华民族的大圣哲。他和他的门生们的故事能够千载不灭地流传下来,总应该是天经地义、情理之中,非如此不可的吧?但是果真如此吗?
comment_num: 1
pub_date: 2006-09-02 00:53:33
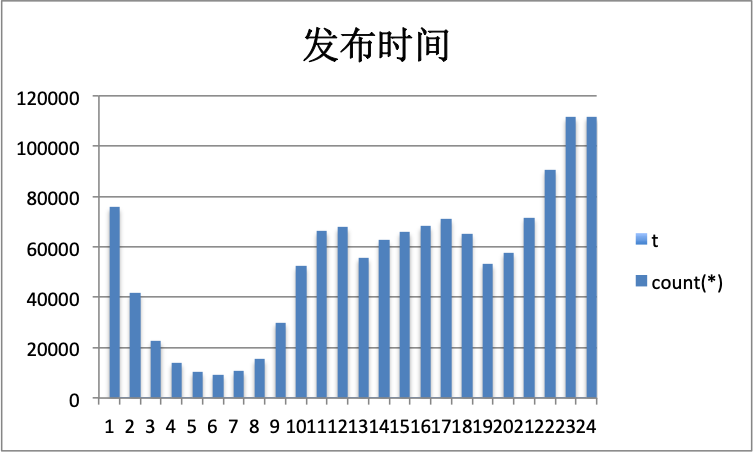
最新的一篇文章就在发表这篇笔记的下午,爬虫时效性还不错
url: https://www.douban.com/note/702307251/
title: 小事412
author: 月半月半弯
snippet: 假如生活欺骗了你。不要悲伤,不要心急……相信吧,快乐的日子将会来临。
comment_num: 0
pub_date: 2019-01-02 15:44:28
文艺青年喜欢在凌晨发布文章,这点挺符合我的认知,大概夜深人静的时候,思绪放飞的更远一些吧。
3. 作者
这1302975篇文章,一共由 129220 个作者完成,人数应该是很多了吧?虽然时间线(2006~2018)比较长。在现在内容为王的今天,这个内容生产者的数量也是相当高了,何况作者质量应该也比较高。
平均每个作者写了10篇文章,发表数最多的是这位用户https://www.douban.com/people/GloriaLaura/notes,数据库里显示3756篇,真实数据可能更高。
数据的分布很不均匀,有35807个作者只写了1篇文章。
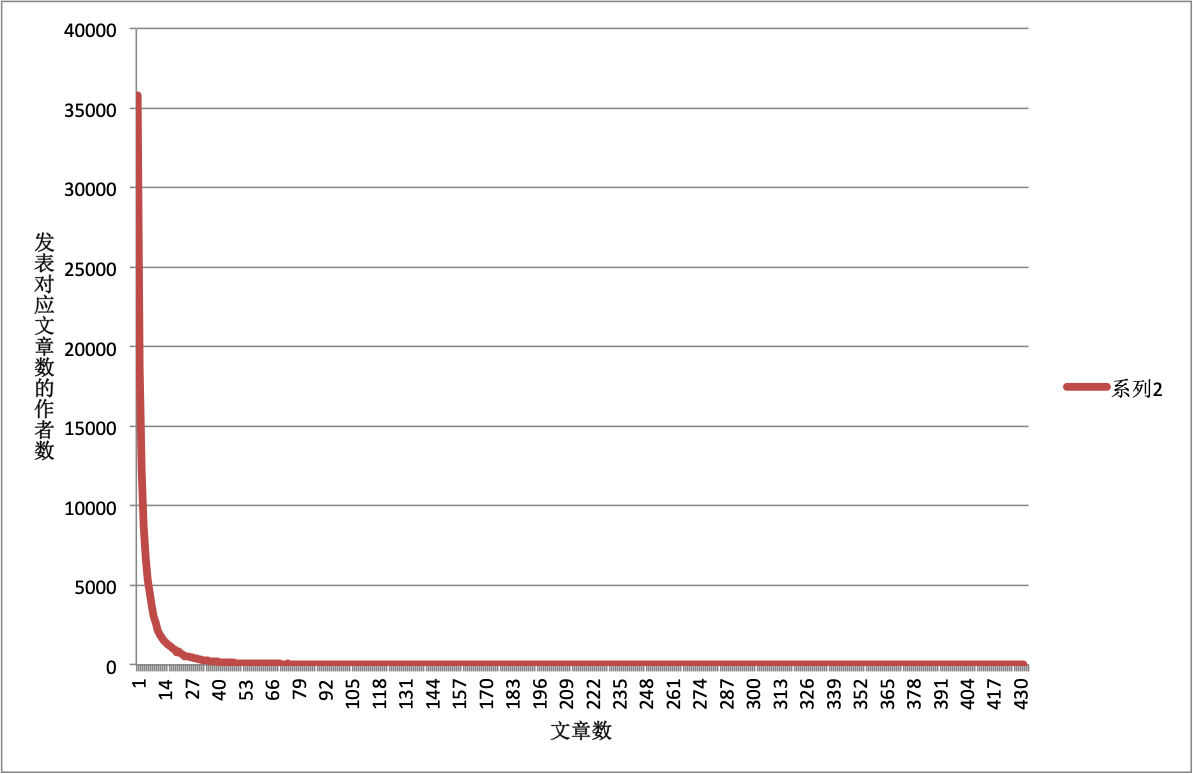
值得一提的是爬了 800w+ 豆瓣er的主页,其中大部分人都不产生内容。
4. tags
我在知识整理时,更倾向于使用 tags 而不是层级目录的形式,因为目录的形式太单一了,而且整理过程本身浪费很多时间,所以也比较关注大家都在用什么tags.
所有文章里,有 tag 的只占 17.2%。

最常见的tag有
情感 成长 读书 思想 人文 旅行 电影 自我管理 社会热点 美食
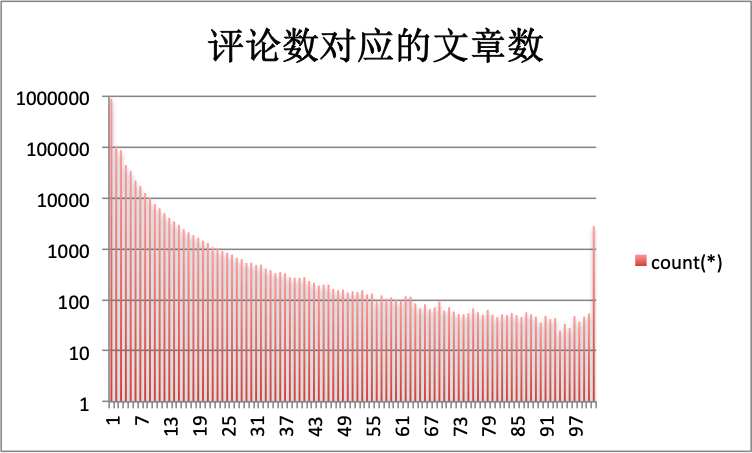
5. 评论
评论数上,最开始没有注意有翻页的功能,因此最大只记录了100个。
大部分文章还是没有评论的,一共909373篇。